 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Threshold KNN-Shapley: A Linear-Time and Privacy-Friendly Approach to Data Valuation
Aug 30, 2023
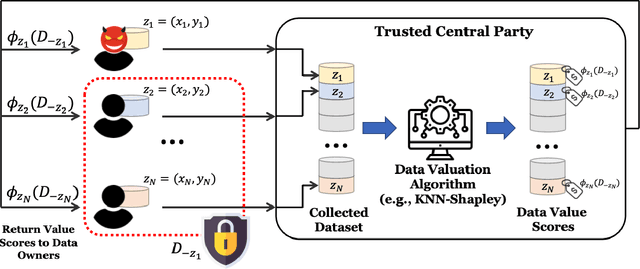
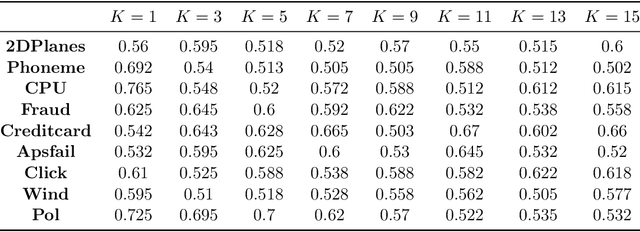
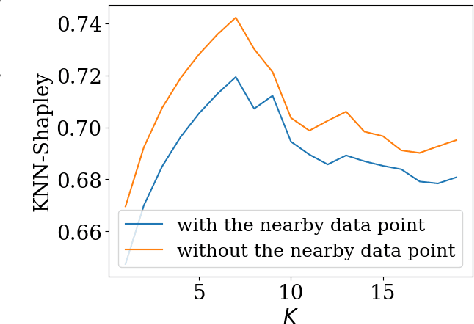
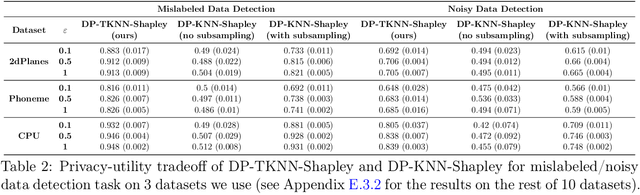
Data valuation, a critical aspect of data-centric ML research, aims to quantify the usefulness of individual data sources in training machine learning (ML) models. However, data valuation faces significant yet frequently overlooked privacy challenges despite its importance. This paper studies these challenges with a focus on KNN-Shapley, one of the most practical data valuation methods nowadays. We first emphasize the inherent privacy risks of KNN-Shapley, and demonstrate the significant technical difficulties in adapting KNN-Shapley to accommodate differential privacy (DP). To overcome these challenges, we introduce TKNN-Shapley, a refined variant of KNN-Shapley that is privacy-friendly, allowing for straightforward modifications to incorporate DP guarantee (DP-TKNN-Shapley). We show that DP-TKNN-Shapley has several advantages and offers a superior privacy-utility tradeoff compared to naively privatized KNN-Shapley in discerning data quality. Moreover, even non-private TKNN-Shapley achieves comparable performance as KNN-Shapley. Overall, our findings suggest that TKNN-Shapley is a promising alternative to KNN-Shapley, particularly for real-world applications involving sensitive data.
On the performance of an integrated communication and localization system: an analytical framework
Sep 08, 2023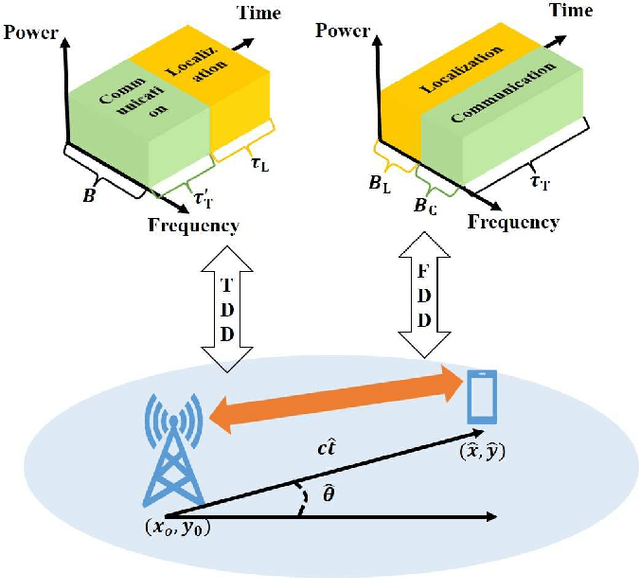
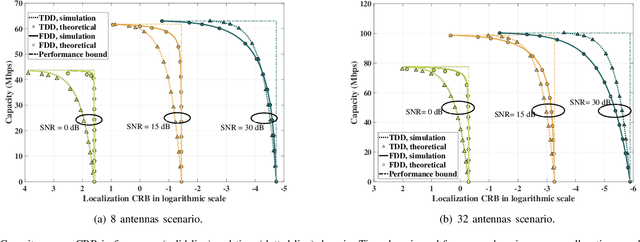
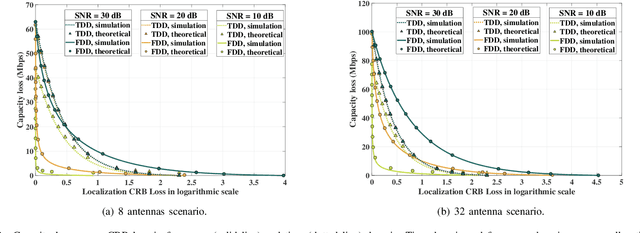
Quantifying the performance bound of an integrated localization and communication (ILAC) system and the trade-off between communication and localization performance is critical. In this letter, we consider an ILAC system that can perform communication and localization via time-domain or frequency-domain resource allocation. We develop an analytical framework to derive the closed-form expression of the capacity loss versus localization Cramer-Rao lower bound (CRB) loss via time-domain and frequency-domain resource allocation. Simulation results validate the analytical model and demonstrate that frequency-domain resource allocation is preferable in scenarios with a smaller number of antennas at the next generation nodeB (gNB) and a larger distance between user equipment (UE) and gNB, while time-domain resource allocation is preferable in scenarios with a larger number of antennas and smaller distance between UE and the gNB.
Class Attendance System in Education with Deep Learning Method
Sep 23, 2023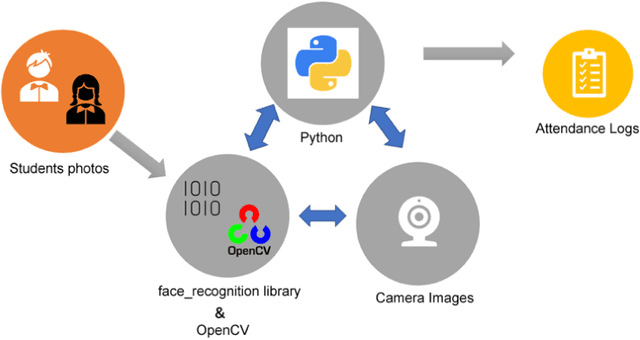
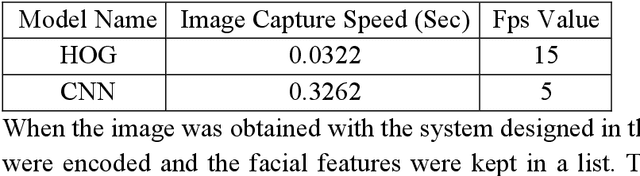

With the advancing technology, the hardware gain of computers and the increase in the processing capacity of processors have facilitated the processing of instantaneous and real-time images. Face recognition processes are also studies in the field of image processing. Facial recognition processes are frequently used in security applications and commercial applications. Especially in the last 20 years, the high performances of artificial intelligence (AI) studies have contributed to the spread of these studies in many different fields. Education is one of them. The potential and advantages of using AI in education; can be grouped under three headings: student, teacher, and institution. One of the institutional studies may be the security of educational environments and the contribution of automation to education and training processes. From this point of view, deep learning methods, one of the sub-branches of AI, were used in this study. For object detection from images, a pioneering study has been designed and successfully implemented to keep records of students' entrance to the educational institution and to perform class attendance with images taken from the camera using image processing algorithms. The application of the study to real-life problems will be carried out in a school determined in the 2022-2023 academic year.
* International LET-IN 2022 Conference Proceedings Book, October 06-08, 2022, Ankara, T\"urkiye. ISBN: 978-605-71971-1-5
Detecting and Mitigating System-Level Anomalies of Vision-Based Controllers
Sep 23, 2023


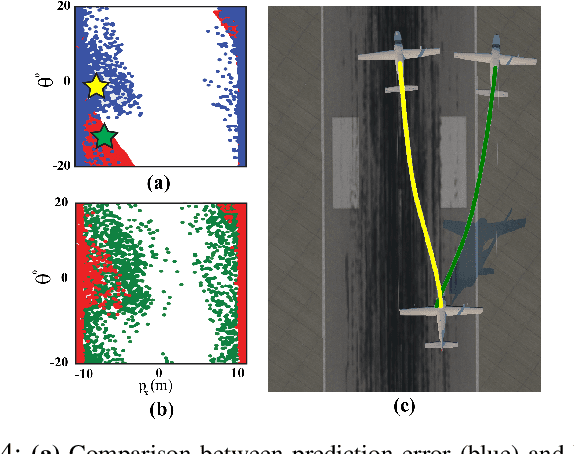
Autonomous systems, such as self-driving cars and drones, have made significant strides in recent years by leveraging visual inputs and machine learning for decision-making and control. Despite their impressive performance, these vision-based controllers can make erroneous predictions when faced with novel or out-of-distribution inputs. Such errors can cascade to catastrophic system failures and compromise system safety. In this work, we introduce a run-time anomaly monitor to detect and mitigate such closed-loop, system-level failures. Specifically, we leverage a reachability-based framework to stress-test the vision-based controller offline and mine its system-level failures. This data is then used to train a classifier that is leveraged online to flag inputs that might cause system breakdowns. The anomaly detector highlights issues that transcend individual modules and pertain to the safety of the overall system. We also design a fallback controller that robustly handles these detected anomalies to preserve system safety. We validate the proposed approach on an autonomous aircraft taxiing system that uses a vision-based controller for taxiing. Our results show the efficacy of the proposed approach in identifying and handling system-level anomalies, outperforming methods such as prediction error-based detection, and ensembling, thereby enhancing the overall safety and robustness of autonomous systems.
Edge Aware Learning for 3D Point Cloud
Sep 23, 2023
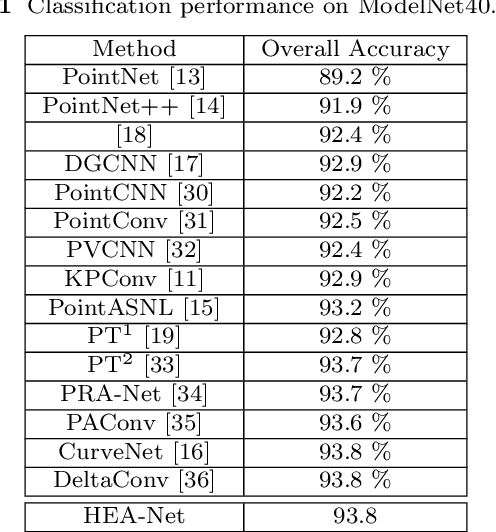
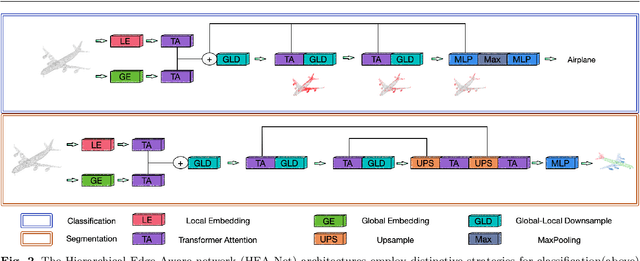
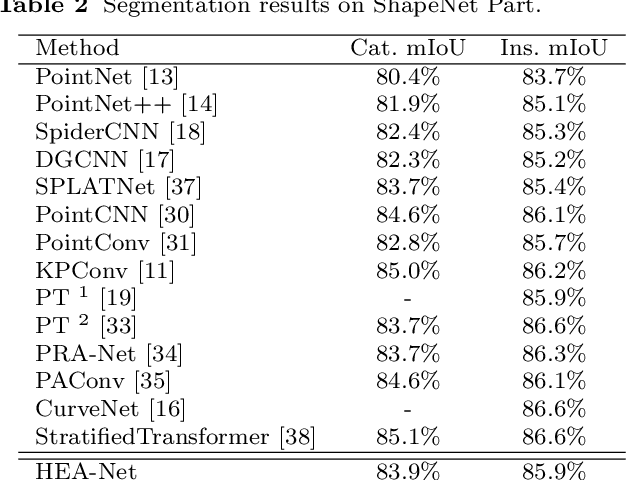
This paper proposes an innovative approach to Hierarchical Edge Aware 3D Point Cloud Learning (HEA-Net) that seeks to address the challenges of noise in point cloud data, and improve object recognition and segmentation by focusing on edge features. In this study, we present an innovative edge-aware learning methodology, specifically designed to enhance point cloud classification and segmentation. Drawing inspiration from the human visual system, the concept of edge-awareness has been incorporated into this methodology, contributing to improved object recognition while simultaneously reducing computational time. Our research has led to the development of an advanced 3D point cloud learning framework that effectively manages object classification and segmentation tasks. A unique fusion of local and global network learning paradigms has been employed, enriched by edge-focused local and global embeddings, thereby significantly augmenting the model's interpretative prowess. Further, we have applied a hierarchical transformer architecture to boost point cloud processing efficiency, thus providing nuanced insights into structural understanding. Our approach demonstrates significant promise in managing noisy point cloud data and highlights the potential of edge-aware strategies in 3D point cloud learning. The proposed approach is shown to outperform existing techniques in object classification and segmentation tasks, as demonstrated by experiments on ModelNet40 and ShapeNet datasets.
Grad DFT: a software library for machine learning enhanced density functional theory
Sep 23, 2023Density functional theory (DFT) stands as a cornerstone method in computational quantum chemistry and materials science due to its remarkable versatility and scalability. Yet, it suffers from limitations in accuracy, particularly when dealing with strongly correlated systems. To address these shortcomings, recent work has begun to explore how machine learning can expand the capabilities of DFT; an endeavor with many open questions and technical challenges. In this work, we present Grad DFT: a fully differentiable JAX-based DFT library, enabling quick prototyping and experimentation with machine learning-enhanced exchange-correlation energy functionals. Grad DFT employs a pioneering parametrization of exchange-correlation functionals constructed using a weighted sum of energy densities, where the weights are determined using neural networks. Moreover, Grad DFT encompasses a comprehensive suite of auxiliary functions, notably featuring a just-in-time compilable and fully differentiable self-consistent iterative procedure. To support training and benchmarking efforts, we additionally compile a curated dataset of experimental dissociation energies of dimers, half of which contain transition metal atoms characterized by strong electronic correlations. The software library is tested against experimental results to study the generalization capabilities of a neural functional across potential energy surfaces and atomic species, as well as the effect of training data noise on the resulting model accuracy.
Model-enhanced Vector Index
Sep 23, 2023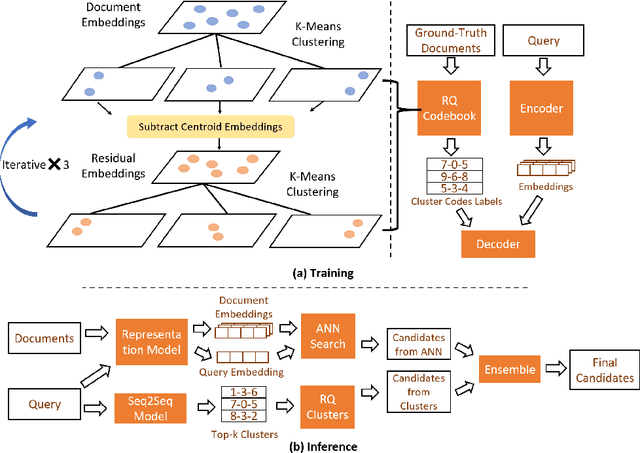

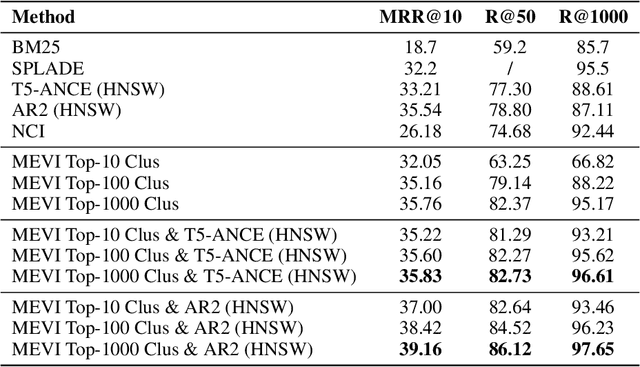
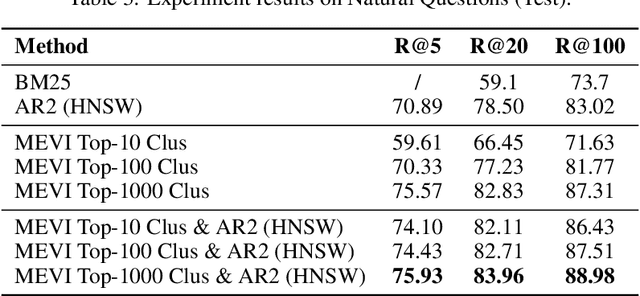
Embedding-based retrieval methods construct vector indices to search for document representations that are most similar to the query representations. They are widely used in document retrieval due to low latency and decent recall performance. Recent research indicates that deep retrieval solutions offer better model quality, but are hindered by unacceptable serving latency and the inability to support document updates. In this paper, we aim to enhance the vector index with end-to-end deep generative models, leveraging the differentiable advantages of deep retrieval models while maintaining desirable serving efficiency. We propose Model-enhanced Vector Index (MEVI), a differentiable model-enhanced index empowered by a twin-tower representation model. MEVI leverages a Residual Quantization (RQ) codebook to bridge the sequence-to-sequence deep retrieval and embedding-based models. To substantially reduce the inference time, instead of decoding the unique document ids in long sequential steps, we first generate some semantic virtual cluster ids of candidate documents in a small number of steps, and then leverage the well-adapted embedding vectors to further perform a fine-grained search for the relevant documents in the candidate virtual clusters. We empirically show that our model achieves better performance on the commonly used academic benchmarks MSMARCO Passage and Natural Questions, with comparable serving latency to dense retrieval solutions.
Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
Sep 23, 2023End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
Scene Separation & Data Selection: Temporal Segmentation Algorithm for Real-Time Video Stream Analysis
Aug 01, 2023
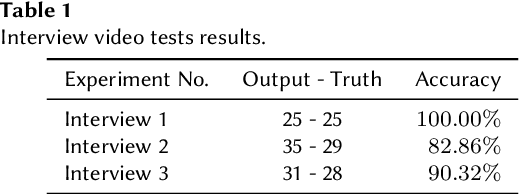
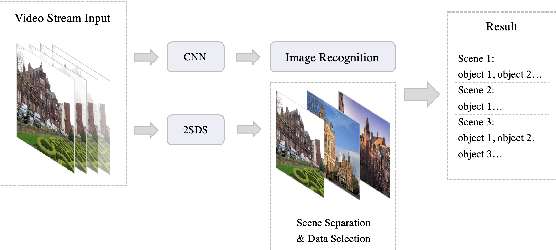
We present 2SDS (Scene Separation and Data Selection algorithm), a temporal segmentation algorithm used in real-time video stream interpretation. It complements CNN-based models to make use of temporal information in videos. 2SDS can detect the change between scenes in a video stream by com-paring the image difference between two frames. It separates a video into segments (scenes), and by combining itself with a CNN model, 2SDS can select the optimal result for each scene. In this paper, we will be discussing some basic methods and concepts behind 2SDS, as well as presenting some preliminary experiment results regarding 2SDS. During these experiments, 2SDS has achieved an overall accuracy of over 90%.
* 5 pages, 4 figures, at IJCAI-ECAI 2022 workshop, First International Workshop on Spatio-Temporal Reasoning and Learning, July 24, 2022, Vienna, Austria
Multivariate Time Series Early Classification Across Channel and Time Dimensions
Jun 26, 2023Nowadays, the deployment of deep learning models on edge devices for addressing real-world classification problems is becoming more prevalent. Moreover, there is a growing popularity in the approach of early classification, a technique that involves classifying the input data after observing only an early portion of it, aiming to achieve reduced communication and computation requirements, which are crucial parameters in edge intelligence environments. While early classification in the field of time series analysis has been broadly researched, existing solutions for multivariate time series problems primarily focus on early classification along the temporal dimension, treating the multiple input channels in a collective manner. In this study, we propose a more flexible early classification pipeline that offers a more granular consideration of input channels and extends the early classification paradigm to the channel dimension. To implement this method, we utilize reinforcement learning techniques and introduce constraints to ensure the feasibility and practicality of our objective. To validate its effectiveness, we conduct experiments using synthetic data and we also evaluate its performance on real datasets. The comprehensive results from our experiments demonstrate that, for multiple datasets, our method can enhance the early classification paradigm by achieving improved accuracy for equal input utilization.