 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Applications of Sequential Learning for Medical Image Classification
Sep 26, 2023
Purpose: The aim of this work is to develop a neural network training framework for continual training of small amounts of medical imaging data and create heuristics to assess training in the absence of a hold-out validation or test set. Materials and Methods: We formulated a retrospective sequential learning approach that would train and consistently update a model on mini-batches of medical images over time. We address problems that impede sequential learning such as overfitting, catastrophic forgetting, and concept drift through PyTorch convolutional neural networks (CNN) and publicly available Medical MNIST and NIH Chest X-Ray imaging datasets. We begin by comparing two methods for a sequentially trained CNN with and without base pre-training. We then transition to two methods of unique training and validation data recruitment to estimate full information extraction without overfitting. Lastly, we consider an example of real-life data that shows how our approach would see mainstream research implementation. Results: For the first experiment, both approaches successfully reach a ~95% accuracy threshold, although the short pre-training step enables sequential accuracy to plateau in fewer steps. The second experiment comparing two methods showed better performance with the second method which crosses the ~90% accuracy threshold much sooner. The final experiment showed a slight advantage with a pre-training step that allows the CNN to cross ~60% threshold much sooner than without pre-training. Conclusion: We have displayed sequential learning as a serviceable multi-classification technique statistically comparable to traditional CNNs that can acquire data in small increments feasible for clinically realistic scenarios.
Nuclear Morphometry using a Deep Learning-based Algorithm has Prognostic Relevance for Canine Cutaneous Mast Cell Tumors
Sep 26, 2023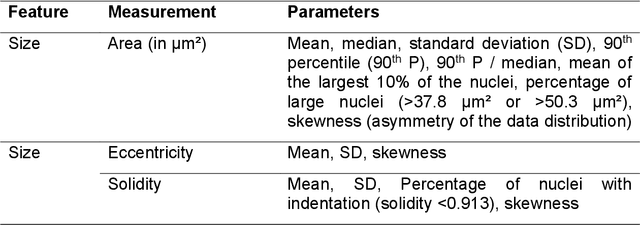
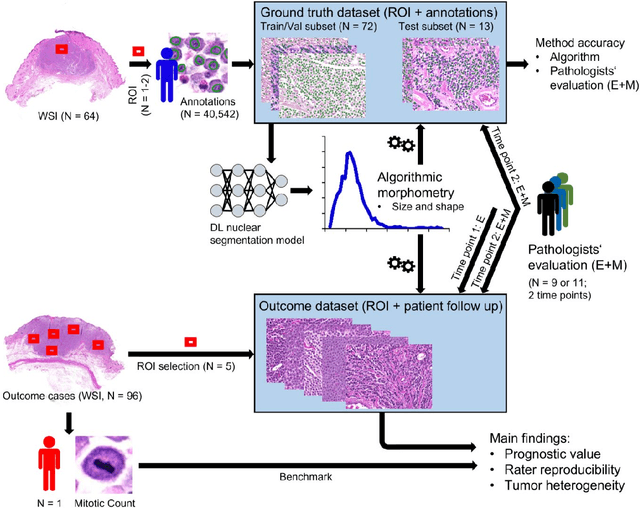
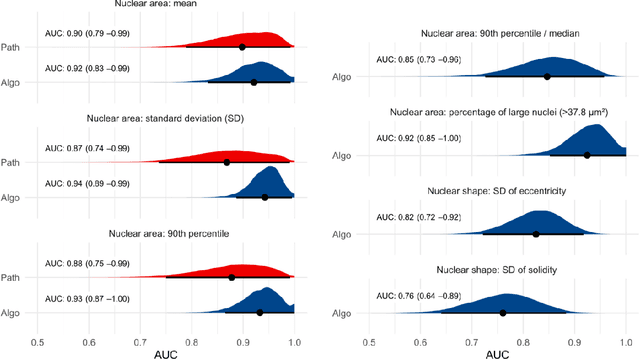
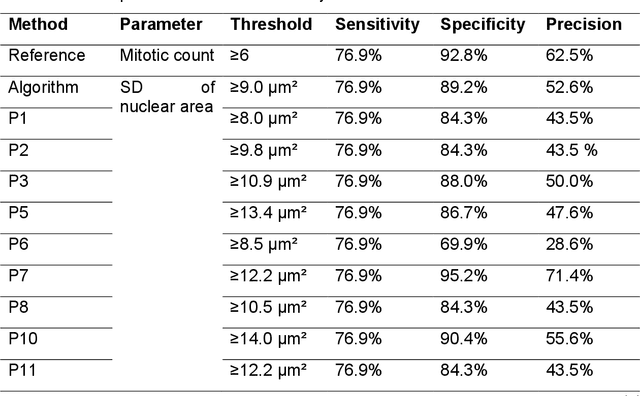
Variation in nuclear size and shape is an important criterion of malignancy for many tumor types; however, categorical estimates by pathologists have poor reproducibility. Measurements of nuclear characteristics (morphometry) can improve reproducibility, but manual methods are time consuming. In this study, we evaluated fully automated morphometry using a deep learning-based algorithm in 96 canine cutaneous mast cell tumors with information on patient survival. Algorithmic morphometry was compared with karyomegaly estimates by 11 pathologists, manual nuclear morphometry of 12 cells by 9 pathologists, and the mitotic count as a benchmark. The prognostic value of automated morphometry was high with an area under the ROC curve regarding the tumor-specific survival of 0.943 (95% CI: 0.889 - 0.996) for the standard deviation (SD) of nuclear area, which was higher than manual morphometry of all pathologists combined (0.868, 95% CI: 0.737 - 0.991) and the mitotic count (0.885, 95% CI: 0.765 - 1.00). At the proposed thresholds, the hazard ratio for algorithmic morphometry (SD of nuclear area $\geq 9.0 \mu m^2$) was 18.3 (95% CI: 5.0 - 67.1), for manual morphometry (SD of nuclear area $\geq 10.9 \mu m^2$) 9.0 (95% CI: 6.0 - 13.4), for karyomegaly estimates 7.6 (95% CI: 5.7 - 10.1), and for the mitotic count 30.5 (95% CI: 7.8 - 118.0). Inter-rater reproducibility for karyomegaly estimates was fair ($\kappa$ = 0.226) with highly variable sensitivity/specificity values for the individual pathologists. Reproducibility for manual morphometry (SD of nuclear area) was good (ICC = 0.654). This study supports the use of algorithmic morphometry as a prognostic test to overcome the limitations of estimates and manual measurements.
Interpretable and Efficient Beamforming-Based Deep Learning for Single Snapshot DOA Estimation
Sep 14, 2023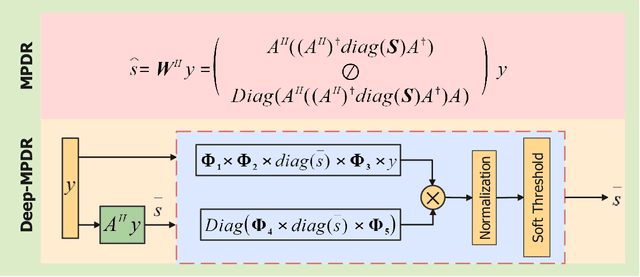
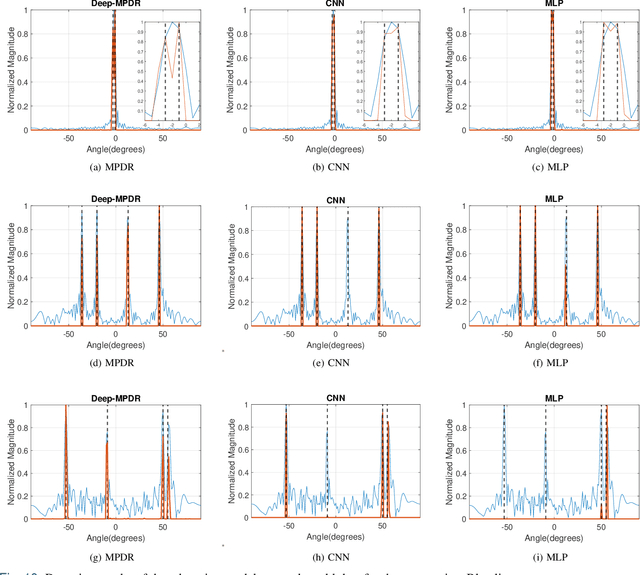
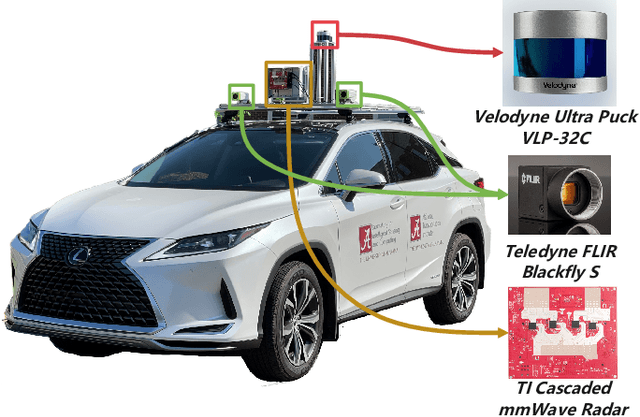
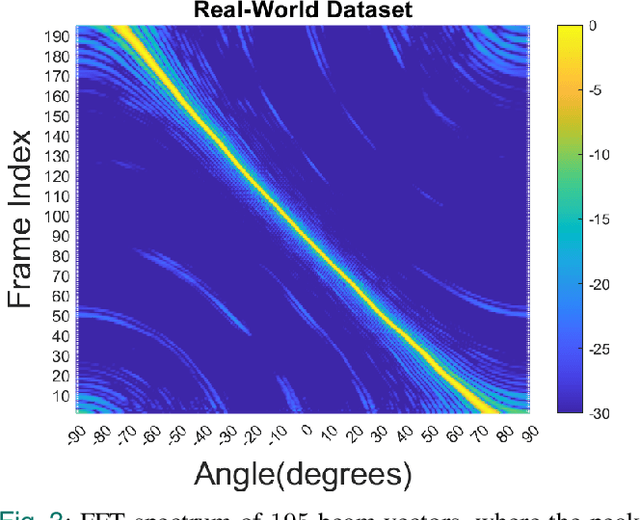
We introduce an interpretable deep learning approach for direction of arrival (DOA) estimation with a single snapshot. Classical subspace-based methods like MUSIC and ESPRIT use spatial smoothing on uniform linear arrays for single snapshot DOA estimation but face drawbacks in reduced array aperture and inapplicability to sparse arrays. Single-snapshot methods such as compressive sensing and iterative adaptation approach (IAA) encounter challenges with high computational costs and slow convergence, hampering real-time use. Recent deep learning DOA methods offer promising accuracy and speed. However, the practical deployment of deep networks is hindered by their black-box nature. To address this, we propose a deep-MPDR network translating minimum power distortionless response (MPDR)-type beamformer into deep learning, enhancing generalization and efficiency. Comprehensive experiments conducted using both simulated and real-world datasets substantiate its dominance in terms of inference time and accuracy in comparison to conventional methods. Moreover, it excels in terms of efficiency, generalizability, and interpretability when contrasted with other deep learning DOA estimation networks.
TEMPO: Efficient Multi-View Pose Estimation, Tracking, and Forecasting
Sep 14, 2023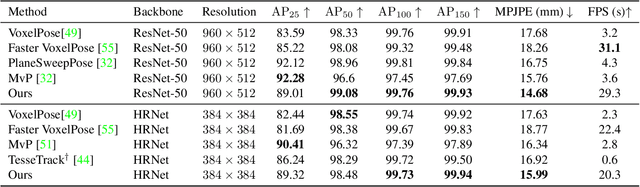
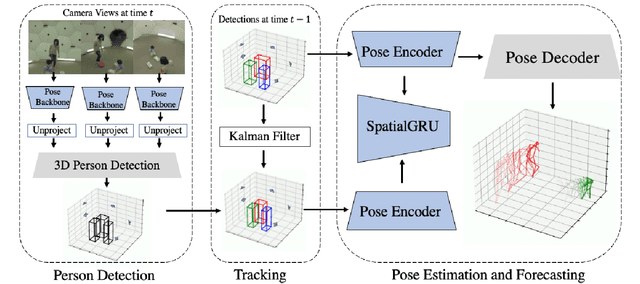
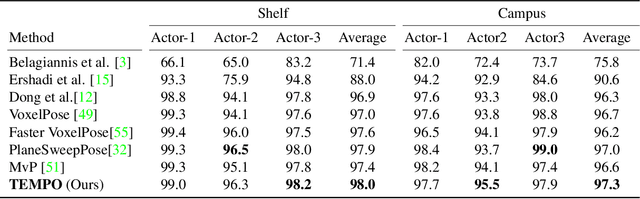
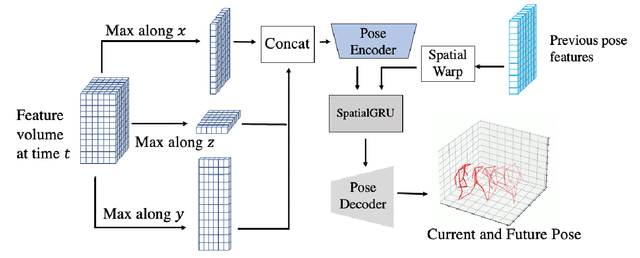
Existing volumetric methods for predicting 3D human pose estimation are accurate, but computationally expensive and optimized for single time-step prediction. We present TEMPO, an efficient multi-view pose estimation model that learns a robust spatiotemporal representation, improving pose accuracy while also tracking and forecasting human pose. We significantly reduce computation compared to the state-of-the-art by recurrently computing per-person 2D pose features, fusing both spatial and temporal information into a single representation. In doing so, our model is able to use spatiotemporal context to predict more accurate human poses without sacrificing efficiency. We further use this representation to track human poses over time as well as predict future poses. Finally, we demonstrate that our model is able to generalize across datasets without scene-specific fine-tuning. TEMPO achieves 10$\%$ better MPJPE with a 33$\times$ improvement in FPS compared to TesseTrack on the challenging CMU Panoptic Studio dataset.
Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond
Sep 13, 2023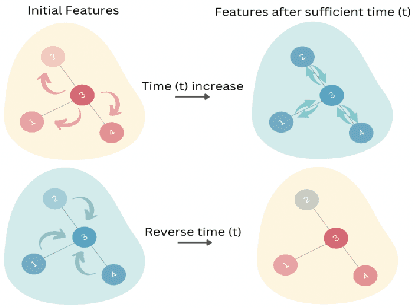
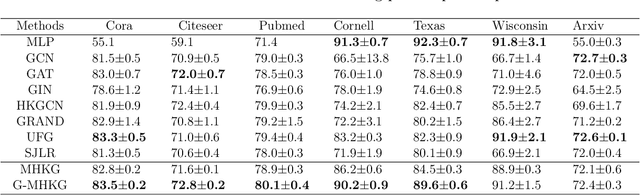
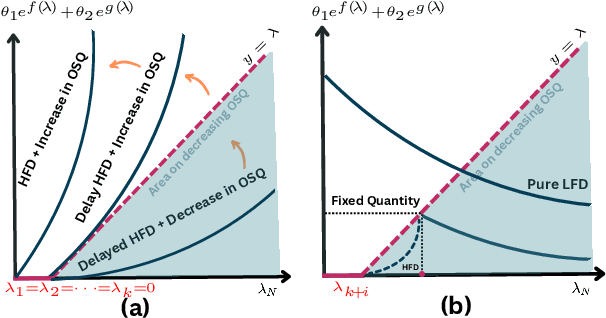
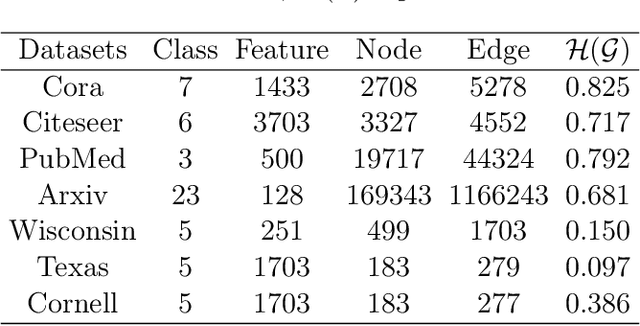
Graph Neural Networks (GNNs) have emerged as one of the leading approaches for machine learning on graph-structured data. Despite their great success, critical computational challenges such as over-smoothing, over-squashing, and limited expressive power continue to impact the performance of GNNs. In this study, inspired from the time-reversal principle commonly utilized in classical and quantum physics, we reverse the time direction of the graph heat equation. The resulted reversing process yields a class of high pass filtering functions that enhance the sharpness of graph node features. Leveraging this concept, we introduce the Multi-Scaled Heat Kernel based GNN (MHKG) by amalgamating diverse filtering functions' effects on node features. To explore more flexible filtering conditions, we further generalize MHKG into a model termed G-MHKG and thoroughly show the roles of each element in controlling over-smoothing, over-squashing and expressive power. Notably, we illustrate that all aforementioned issues can be characterized and analyzed via the properties of the filtering functions, and uncover a trade-off between over-smoothing and over-squashing: enhancing node feature sharpness will make model suffer more from over-squashing, and vice versa. Furthermore, we manipulate the time again to show how G-MHKG can handle both two issues under mild conditions. Our conclusive experiments highlight the effectiveness of proposed models. It surpasses several GNN baseline models in performance across graph datasets characterized by both homophily and heterophily.
Combining Two Adversarial Attacks Against Person Re-Identification Systems
Sep 24, 2023The field of Person Re-Identification (Re-ID) has received much attention recently, driven by the progress of deep neural networks, especially for image classification. The problem of Re-ID consists in identifying individuals through images captured by surveillance cameras in different scenarios. Governments and companies are investing a lot of time and money in Re-ID systems for use in public safety and identifying missing persons. However, several challenges remain for successfully implementing Re-ID, such as occlusions and light reflections in people's images. In this work, we focus on adversarial attacks on Re-ID systems, which can be a critical threat to the performance of these systems. In particular, we explore the combination of adversarial attacks against Re-ID models, trying to strengthen the decrease in the classification results. We conduct our experiments on three datasets: DukeMTMC-ReID, Market-1501, and CUHK03. We combine the use of two types of adversarial attacks, P-FGSM and Deep Mis-Ranking, applied to two popular Re-ID models: IDE (ResNet-50) and AlignedReID. The best result demonstrates a decrease of 3.36% in the Rank-10 metric for AlignedReID applied to CUHK03. We also try to use Dropout during the inference as a defense method.
Crack-Net: Prediction of Crack Propagation in Composites
Sep 24, 2023Computational solid mechanics has become an indispensable approach in engineering, and numerical investigation of fracture in composites is essential as composites are widely used in structural applications. Crack evolution in composites is the bridge to elucidate the relationship between the microstructure and fracture performance, but crack-based finite element methods are computationally expensive and time-consuming, limiting their application in computation-intensive scenarios. Here we propose a deep learning framework called Crack-Net, which incorporates the relationship between crack evolution and stress response to predict the fracture process in composites. Trained on a high-precision fracture development dataset generated using the phase field method, Crack-Net demonstrates a remarkable capability to accurately forecast the long-term evolution of crack growth patterns and the stress-strain curve for a given composite design. The Crack-Net captures the essential principle of crack growth, which enables it to handle more complex microstructures such as binary co-continuous structures. Moreover, transfer learning is adopted to further improve the generalization ability of Crack-Net for composite materials with reinforcements of different strengths. The proposed Crack-Net holds great promise for practical applications in engineering and materials science, in which accurate and efficient fracture prediction is crucial for optimizing material performance and microstructural design.
Topology-Agnostic Detection of Temporal Money Laundering Flows in Billion-Scale Transactions
Sep 24, 2023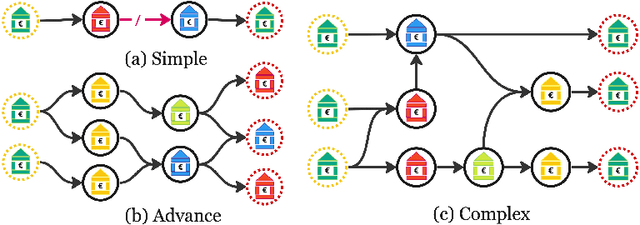

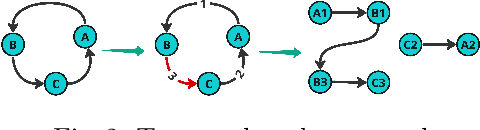
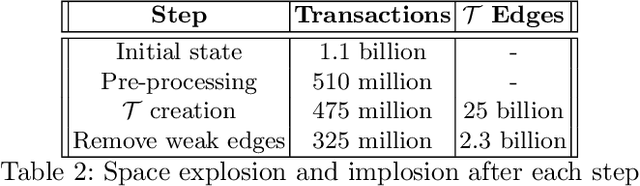
Money launderers exploit the weaknesses in detection systems by purposefully placing their ill-gotten money into multiple accounts, at different banks. That money is then layered and moved around among mule accounts to obscure the origin and the flow of transactions. Consequently, the money is integrated into the financial system without raising suspicion. Path finding algorithms that aim at tracking suspicious flows of money usually struggle with scale and complexity. Existing community detection techniques also fail to properly capture the time-dependent relationships. This is particularly evident when performing analytics over massive transaction graphs. We propose a framework (called FaSTMAN), adapted for domain-specific constraints, to efficiently construct a temporal graph of sequential transactions. The framework includes a weighting method, using 2nd order graph representation, to quantify the significance of the edges. This method enables us to distribute complex queries on smaller and densely connected networks of flows. Finally, based on those queries, we can effectively identify networks of suspicious flows. We extensively evaluate the scalability and the effectiveness of our framework against two state-of-the-art solutions for detecting suspicious flows of transactions. For a dataset of over 1 Billion transactions from multiple large European banks, the results show a clear superiority of our framework both in efficiency and usefulness.
Reinforcement Learning Under Probabilistic Spatio-Temporal Constraints with Time Windows
Jul 29, 2023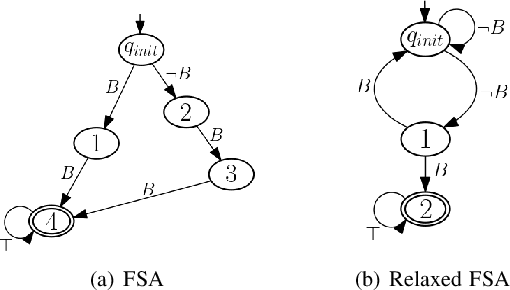
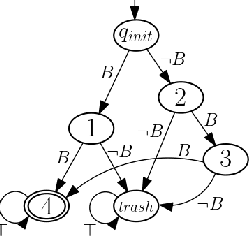
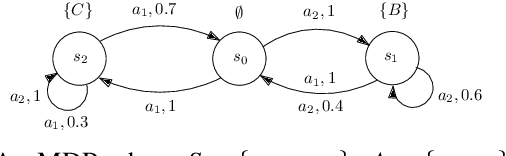
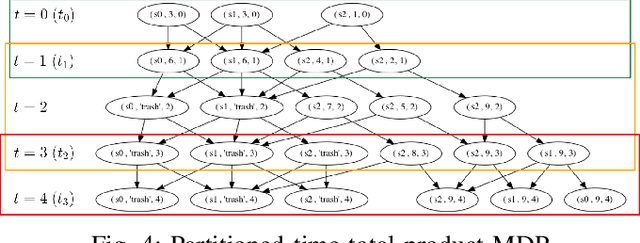
We propose an automata-theoretic approach for reinforcement learning (RL) under complex spatio-temporal constraints with time windows. The problem is formulated using a Markov decision process under a bounded temporal logic constraint. Different from existing RL methods that can eventually learn optimal policies satisfying such constraints, our proposed approach enforces a desired probability of constraint satisfaction throughout learning. This is achieved by translating the bounded temporal logic constraint into a total automaton and avoiding "unsafe" actions based on the available prior information regarding the transition probabilities, i.e., a pair of upper and lower bounds for each transition probability. We provide theoretical guarantees on the resulting probability of constraint satisfaction. We also provide numerical results in a scenario where a robot explores the environment to discover high-reward regions while fulfilling some periodic pick-up and delivery tasks that are encoded as temporal logic constraints.
Performance Analysis of OTSM under Hardware Impairments in Millimeter-Wave Vehicular Communication Networks
Sep 08, 2023
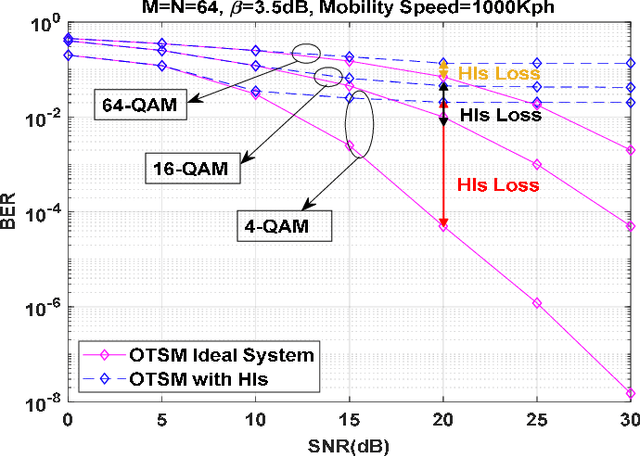
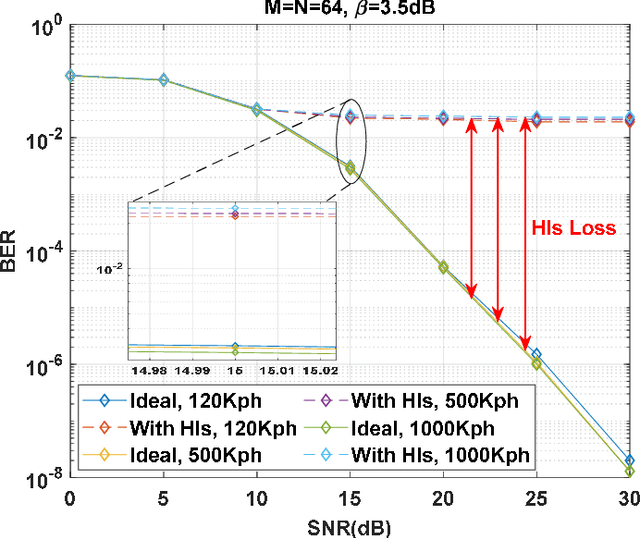
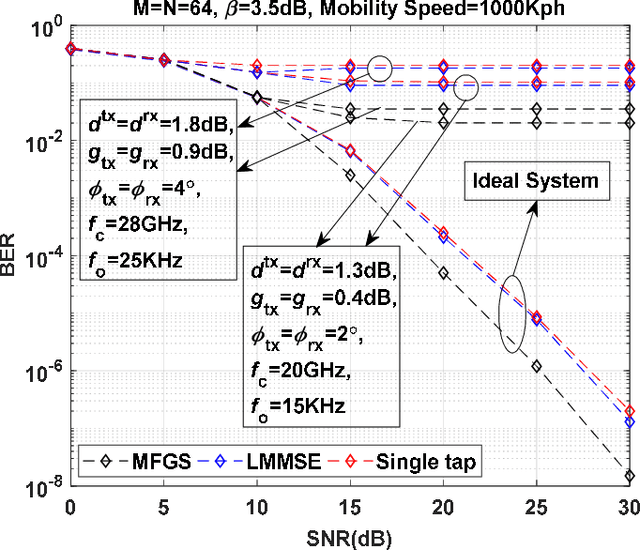
Orthogonal time sequency multiplexing (OTSM) has been recently proposed as a single-carrier (SC) waveform offering similar bit error rate (BER) to multi-carrier orthogonal time frequency space (OTFS) modulation in doubly-spread channels under high mobilities; however, with much lower complexity making OTSM a promising candidate for low-power millimeter-wave (mmWave) vehicular communications in 6G wireless networks. In this paper, the performance of OTSM-based homodyne transceiver is explored under hardware impairments (HIs) including in-phase and quadrature imbalance (IQI), direct current offset (DCO), phase noise, power amplifier non-linearity, carrier frequency offset, and synchronization timing offset. First, the discrete-time baseband signal model is obtained in vector form under the mentioned HIs. Then, the system input-output relations are derived in time, delay-time, and delay-sequency (DS) domains in which the parameters of HIs are incorporated. Analytical studies demonstrate that noise stays white Gaussian and effective channel matrix is sparse in the DS domain under HIs. Also, DCO appears as a DC signal at receiver interfering with only the zero sequency over all delay taps in the DS domain; however, IQI redounds to self-conjugated fully-overlapping sequency interference. Simulation results reveal the fact that with no HI compensation (HIC), not only OTSM outperforms plain SC waveform but it performs close to uncompensated OTFS system; however, HIC is essentially needed for OTSM systems operating in mmWave and beyond frequency bands.