 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bridging the complexity gap in Tbps-achieving THz-band baseband processing
Sep 27, 2023
Recent advances in electronic and photonic technologies have allowed efficient signal generation and transmission at terahertz (THz) frequencies. However, as the gap in THz-operating devices narrows, the demand for terabit-per-second (Tbps)-achieving circuits is increasing. Translating the available hundreds of gigahertz (GHz) of bandwidth into a Tbps data rate requires processing thousands of information bits per clock cycle at state-of-the-art clock frequencies of digital baseband processing circuitry of a few GHz. This paper addresses these constraints and emphasizes the importance of parallelization in signal processing, particularly for channel code decoding. By leveraging structured sub-spaces of THz channels, we propose mapping bits to transmission resources using shorter code words, extending parallelizability across all baseband processing blocks. THz channels exhibit quasi-deterministic frequency, time, and space structures that enable efficient parallel bit mapping at the source and provide pseudo-soft bit reliability information for efficient detection and decoding at the receiver.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023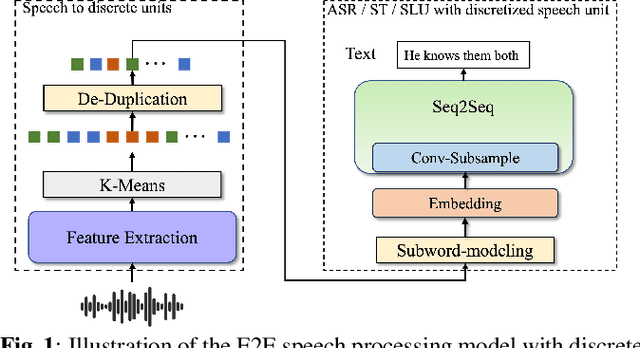
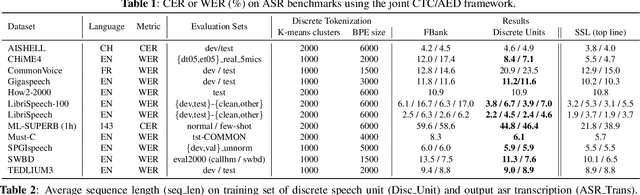
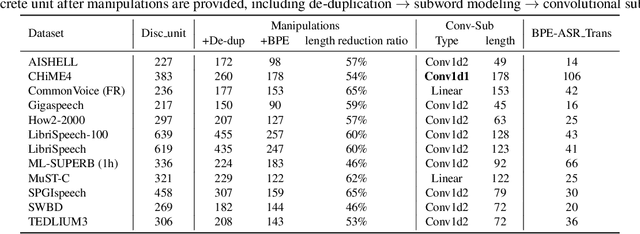
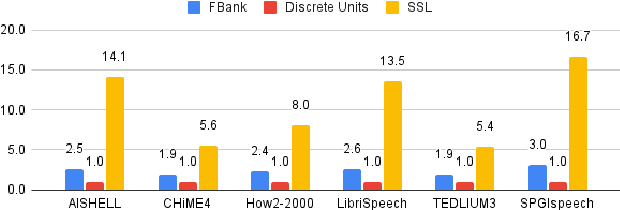
Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
Exciton-Polariton Condensates: A Fourier Neural Operator Approach
Sep 27, 2023
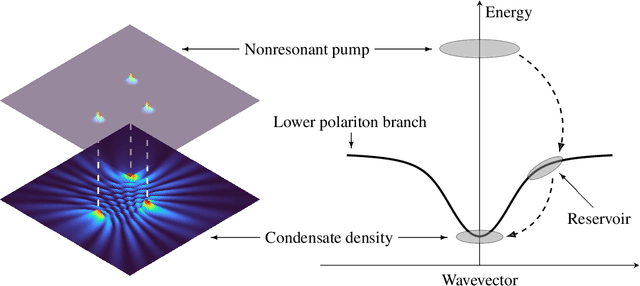
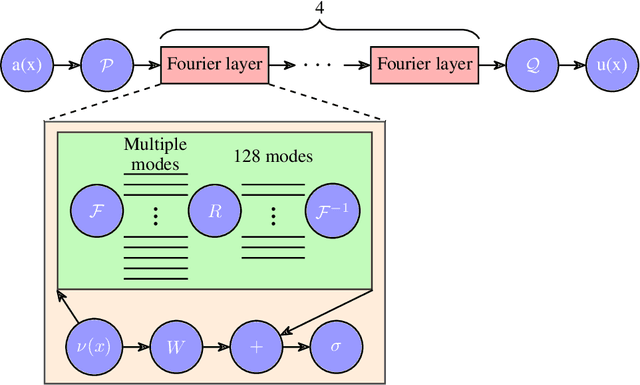
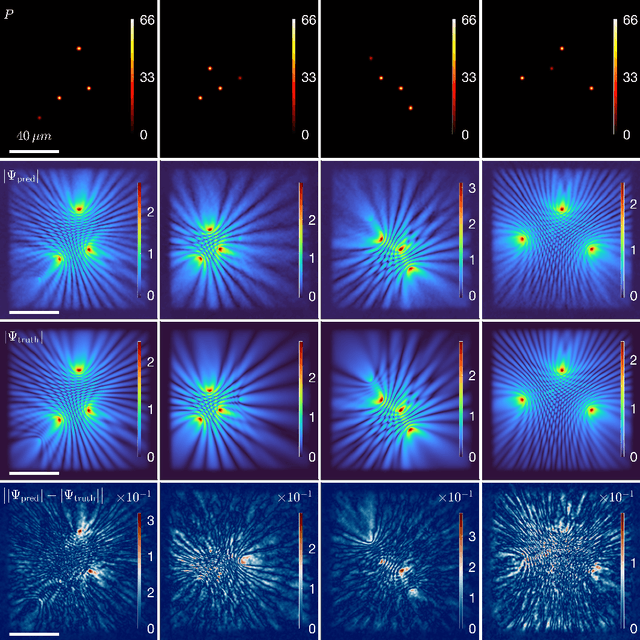
Advancements in semiconductor fabrication over the past decade have catalyzed extensive research into all-optical devices driven by exciton-polariton condensates. Preliminary validations of such devices, including transistors, have shown encouraging results even under ambient conditions. A significant challenge still remains for large scale application however: the lack of a robust solver that can be used to simulate complex nonlinear systems which require an extended period of time to stabilize. Addressing this need, we propose the application of a machine-learning-based Fourier Neural Operator approach to find the solution to the Gross-Pitaevskii equations coupled with extra exciton rate equations. This work marks the first direct application of Neural Operators to an exciton-polariton condensate system. Our findings show that the proposed method can predict final-state solutions to a high degree of accuracy almost 1000 times faster than CUDA-based GPU solvers. Moreover, this paves the way for potential all-optical chip design workflows by integrating experimental data.
Direct Models for Simultaneous Translation and Automatic Subtitling: FBK@IWSLT2023
Sep 27, 2023This paper describes the FBK's participation in the Simultaneous Translation and Automatic Subtitling tracks of the IWSLT 2023 Evaluation Campaign. Our submission focused on the use of direct architectures to perform both tasks: for the simultaneous one, we leveraged the knowledge already acquired by offline-trained models and directly applied a policy to obtain the real-time inference; for the subtitling one, we adapted the direct ST model to produce well-formed subtitles and exploited the same architecture to produce timestamps needed for the subtitle synchronization with audiovisual content. Our English-German SimulST system shows a reduced computational-aware latency compared to the one achieved by the top-ranked systems in the 2021 and 2022 rounds of the task, with gains of up to 3.5 BLEU. Our automatic subtitling system outperforms the only existing solution based on a direct system by 3.7 and 1.7 SubER in English-German and English-Spanish respectively.
* Published at IWSTL 2023
NoSENSE: Learned unrolled cardiac MRI reconstruction without explicit sensitivity maps
Sep 27, 2023We present a novel learned image reconstruction method for accelerated cardiac MRI with multiple receiver coils based on deep convolutional neural networks (CNNs) and algorithm unrolling. In contrast to many existing learned MR image reconstruction techniques that necessitate coil-sensitivity map (CSM) estimation as a distinct network component, our proposed approach avoids explicit CSM estimation. Instead, it implicitly captures and learns to exploit the inter-coil relationships of the images. Our method consists of a series of novel learned image and k-space blocks with shared latent information and adaptation to the acquisition parameters by feature-wise modulation (FiLM), as well as coil-wise data-consistency (DC) blocks. Our method achieved PSNR values of 34.89 and 35.56 and SSIM values of 0.920 and 0.942 in the cine track and mapping track validation leaderboard of the MICCAI STACOM CMRxRecon Challenge, respectively, ranking 4th among different teams at the time of writing. Code will be made available at https://github.com/fzimmermann89/CMRxRecon
BASED: Bundle-Adjusting Surgical Endoscopic Dynamic Video Reconstruction using Neural Radiance Fields
Sep 27, 2023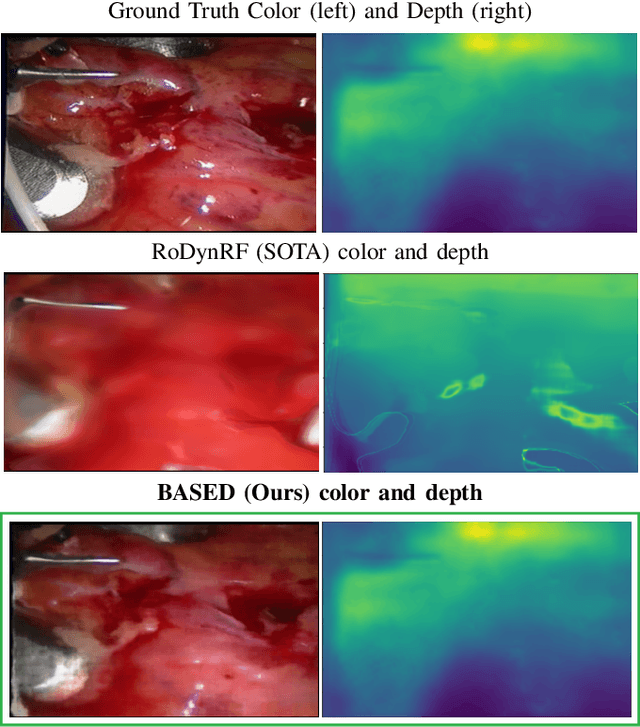
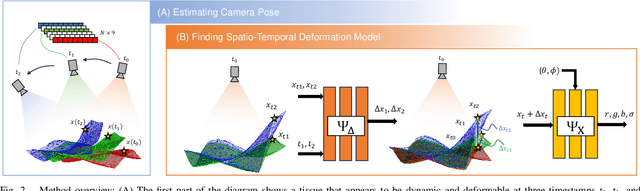
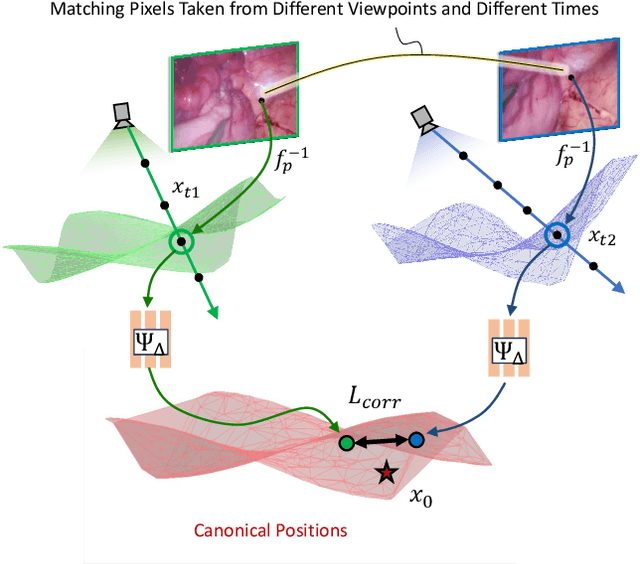
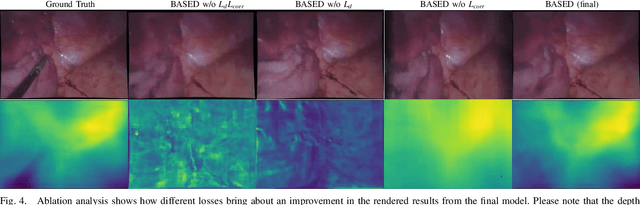
Reconstruction of deformable scenes from endoscopic videos is important for many applications such as intraoperative navigation, surgical visual perception, and robotic surgery. It is a foundational requirement for realizing autonomous robotic interventions for minimally invasive surgery. However, previous approaches in this domain have been limited by their modular nature and are confined to specific camera and scene settings. Our work adopts the Neural Radiance Fields (NeRF) approach to learning 3D implicit representations of scenes that are both dynamic and deformable over time, and furthermore with unknown camera poses. We demonstrate this approach on endoscopic surgical scenes from robotic surgery. This work removes the constraints of known camera poses and overcomes the drawbacks of the state-of-the-art unstructured dynamic scene reconstruction technique, which relies on the static part of the scene for accurate reconstruction. Through several experimental datasets, we demonstrate the versatility of our proposed model to adapt to diverse camera and scene settings, and show its promise for both current and future robotic surgical systems.
Treatment-aware Diffusion Probabilistic Model for Longitudinal MRI Generation and Diffuse Glioma Growth Prediction
Sep 14, 2023
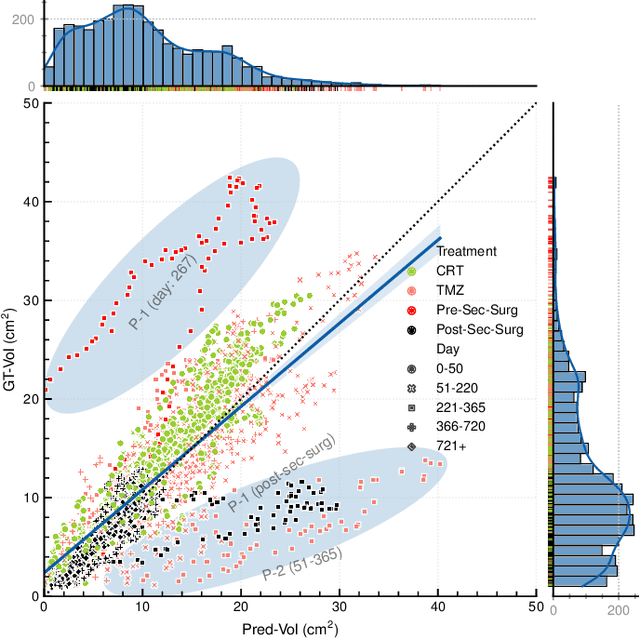
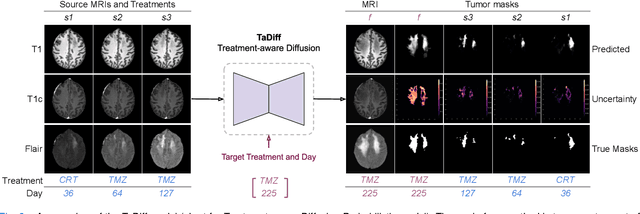
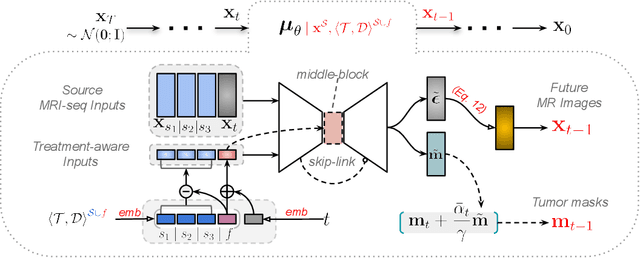
Diffuse gliomas are malignant brain tumors that grow widespread through the brain. The complex interactions between neoplastic cells and normal tissue, as well as the treatment-induced changes often encountered, make glioma tumor growth modeling challenging. In this paper, we present a novel end-to-end network capable of generating future tumor masks and realistic MRIs of how the tumor will look at any future time points for different treatment plans. Our approach is based on cutting-edge diffusion probabilistic models and deep-segmentation neural networks. We included sequential multi-parametric magnetic resonance images (MRI) and treatment information as conditioning inputs to guide the generative diffusion process. This allows for tumor growth estimates at any given time point. We trained the model using real-world postoperative longitudinal MRI data with glioma tumor growth trajectories represented as tumor segmentation maps over time. The model has demonstrated promising performance across a range of tasks, including the generation of high-quality synthetic MRIs with tumor masks, time-series tumor segmentations, and uncertainty estimates. Combined with the treatment-aware generated MRIs, the tumor growth predictions with uncertainty estimates can provide useful information for clinical decision-making.
CrisisTransformers: Pre-trained language models and sentence encoders for crisis-related social media texts
Oct 01, 2023
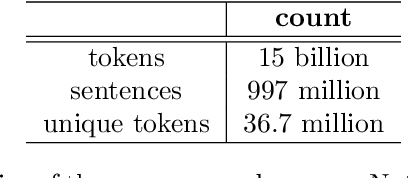
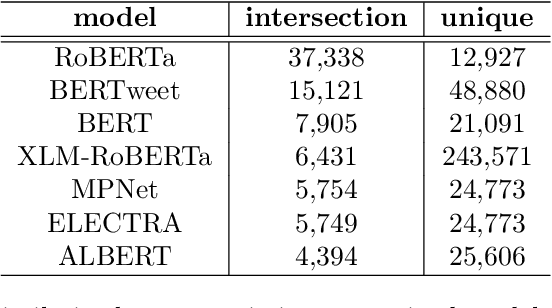
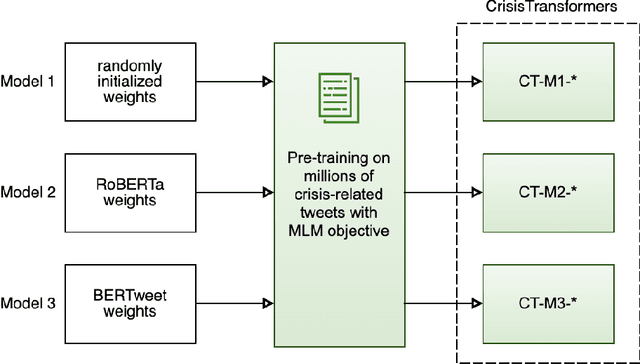
Social media platforms play an essential role in crisis communication, but analyzing crisis-related social media texts is challenging due to their informal nature. Transformer-based pre-trained models like BERT and RoBERTa have shown success in various NLP tasks, but they are not tailored for crisis-related texts. Furthermore, general-purpose sentence encoders are used to generate sentence embeddings, regardless of the textual complexities in crisis-related texts. Advances in applications like text classification, semantic search, and clustering contribute to effective processing of crisis-related texts, which is essential for emergency responders to gain a comprehensive view of a crisis event, whether historical or real-time. To address these gaps in crisis informatics literature, this study introduces CrisisTransformers, an ensemble of pre-trained language models and sentence encoders trained on an extensive corpus of over 15 billion word tokens from tweets associated with more than 30 crisis events, including disease outbreaks, natural disasters, conflicts, and other critical incidents. We evaluate existing models and CrisisTransformers on 18 crisis-specific public datasets. Our pre-trained models outperform strong baselines across all datasets in classification tasks, and our best-performing sentence encoder improves the state-of-the-art by 17.43% in sentence encoding tasks. Additionally, we investigate the impact of model initialization on convergence and evaluate the significance of domain-specific models in generating semantically meaningful sentence embeddings. All models are publicly released (https://huggingface.co/crisistransformers), with the anticipation that they will serve as a robust baseline for tasks involving the analysis of crisis-related social media texts.
Parameter-Efficient Tuning Helps Language Model Alignment
Oct 01, 2023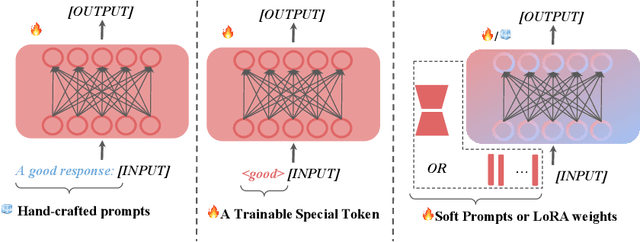
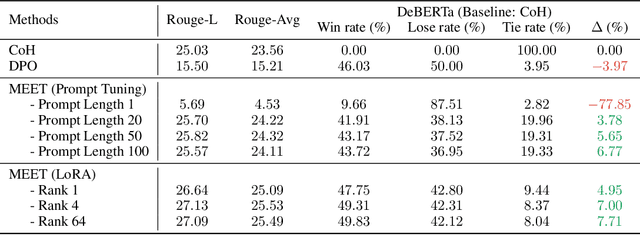
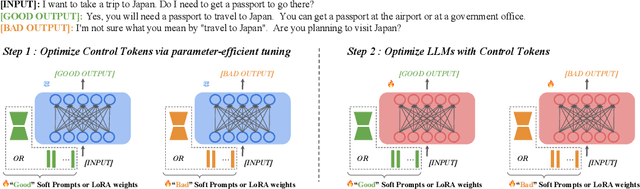
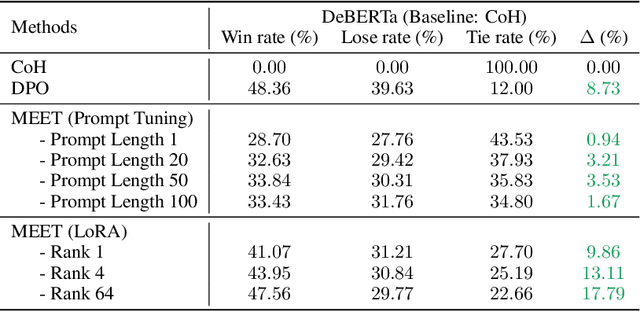
Aligning large language models (LLMs) with human preferences is essential for safe and useful LLMs. Previous works mainly adopt reinforcement learning (RLHF) and direct preference optimization (DPO) with human feedback for alignment. Nevertheless, they have certain drawbacks. One such limitation is that they can only align models with one preference at the training time (e.g., they cannot learn to generate concise responses when the preference data prefers detailed responses), or have certain constraints for the data format (e.g., DPO only supports pairwise preference data). To this end, prior works incorporate controllable generations for alignment to make language models learn multiple preferences and provide outputs with different preferences during inference if asked. Controllable generation also offers more flexibility with regard to data format (e.g., it supports pointwise preference data). Specifically, it uses different control tokens for different preferences during training and inference, making LLMs behave differently when required. Current controllable generation methods either use a special token or hand-crafted prompts as control tokens, and optimize them together with LLMs. As control tokens are typically much lighter than LLMs, this optimization strategy may not effectively optimize control tokens. To this end, we first use parameter-efficient tuning (e.g., prompting tuning and low-rank adaptation) to optimize control tokens and then fine-tune models for controllable generations, similar to prior works. Our approach, alignMEnt with parameter-Efficient Tuning (MEET), improves the quality of control tokens, thus improving controllable generation quality consistently by an apparent margin on two well-recognized datasets compared with prior works.
Refining DNN-based Mask Estimation using CGMM-based EM Algorithm for Multi-channel Noise Reduction
Sep 18, 2023In this paper, we present a method that allows to further improve speech enhancement obtained with recently introduced Deep Neural Network (DNN) models. We propose a multi-channel refinement method of time-frequency masks obtained with single-channel DNNs, which consists of an iterative Complex Gaussian Mixture Model (CGMM) based algorithm, followed by optimum spatial filtration. We validate our approach on time-frequency masks estimated with three recent deep learning models, namely DCUnet, DCCRN, and FullSubNet. We show that our method with the proposed mask refinement procedure allows to improve the accuracy of estimated masks, in terms of the Area Under the ROC Curve (AUC) measure, and as a consequence the overall speech quality of the enhanced speech signal, as measured by PESQ improvement, and that the improvement is consistent across all three DNN models.