 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LUWA Dataset: Learning Lithic Use-Wear Analysis on Microscopic Images
Mar 27, 2024

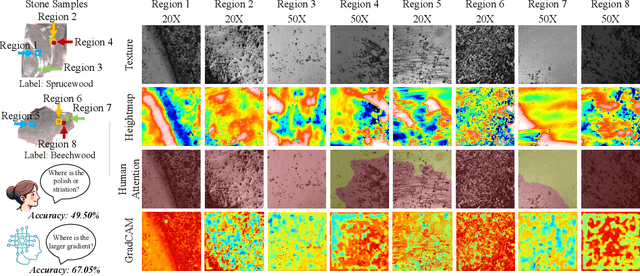
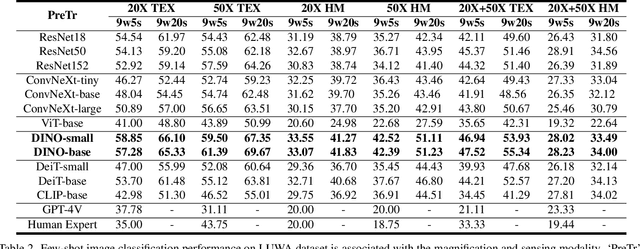
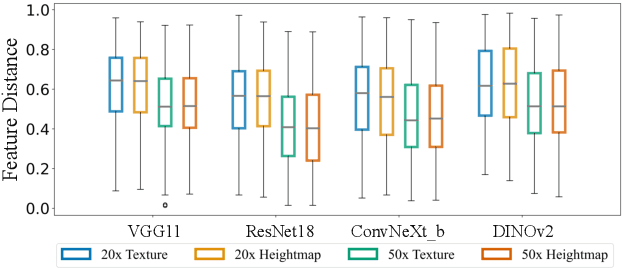
Lithic Use-Wear Analysis (LUWA) using microscopic images is an underexplored vision-for-science research area. It seeks to distinguish the worked material, which is critical for understanding archaeological artifacts, material interactions, tool functionalities, and dental records. However, this challenging task goes beyond the well-studied image classification problem for common objects. It is affected by many confounders owing to the complex wear mechanism and microscopic imaging, which makes it difficult even for human experts to identify the worked material successfully. In this paper, we investigate the following three questions on this unique vision task for the first time:(i) How well can state-of-the-art pre-trained models (like DINOv2) generalize to the rarely seen domain? (ii) How can few-shot learning be exploited for scarce microscopic images? (iii) How do the ambiguous magnification and sensing modality influence the classification accuracy? To study these, we collaborated with archaeologists and built the first open-source and the largest LUWA dataset containing 23,130 microscopic images with different magnifications and sensing modalities. Extensive experiments show that existing pre-trained models notably outperform human experts but still leave a large gap for improvements. Most importantly, the LUWA dataset provides an underexplored opportunity for vision and learning communities and complements existing image classification problems on common objects.
OrCo: Towards Better Generalization via Orthogonality and Contrast for Few-Shot Class-Incremental Learning
Mar 27, 2024Few-Shot Class-Incremental Learning (FSCIL) introduces a paradigm in which the problem space expands with limited data. FSCIL methods inherently face the challenge of catastrophic forgetting as data arrives incrementally, making models susceptible to overwriting previously acquired knowledge. Moreover, given the scarcity of labeled samples available at any given time, models may be prone to overfitting and find it challenging to strike a balance between extensive pretraining and the limited incremental data. To address these challenges, we propose the OrCo framework built on two core principles: features' orthogonality in the representation space, and contrastive learning. In particular, we improve the generalization of the embedding space by employing a combination of supervised and self-supervised contrastive losses during the pretraining phase. Additionally, we introduce OrCo loss to address challenges arising from data limitations during incremental sessions. Through feature space perturbations and orthogonality between classes, the OrCo loss maximizes margins and reserves space for the following incremental data. This, in turn, ensures the accommodation of incoming classes in the feature space without compromising previously acquired knowledge. Our experimental results showcase state-of-the-art performance across three benchmark datasets, including mini-ImageNet, CIFAR100, and CUB datasets. Code is available at https://github.com/noorahmedds/OrCo
Artifact Reduction in 3D and 4D Cone-beam Computed Tomography Images with Deep Learning -- A Review
Mar 27, 2024Deep learning based approaches have been used to improve image quality in cone-beam computed tomography (CBCT), a medical imaging technique often used in applications such as image-guided radiation therapy, implant dentistry or orthopaedics. In particular, while deep learning methods have been applied to reduce various types of CBCT image artifacts arising from motion, metal objects, or low-dose acquisition, a comprehensive review summarizing the successes and shortcomings of these approaches, with a primary focus on the type of artifacts rather than the architecture of neural networks, is lacking in the literature. In this review, the data generation and simulation pipelines, and artifact reduction techniques are specifically investigated for each type of artifact. We provide an overview of deep learning techniques that have successfully been shown to reduce artifacts in 3D, as well as in time-resolved (4D) CBCT through the use of projection- and/or volume-domain optimizations, or by introducing neural networks directly within the CBCT reconstruction algorithms. Research gaps are identified to suggest avenues for future exploration. One of the key findings of this work is an observed trend towards the use of generative models including GANs and score-based or diffusion models, accompanied with the need for more diverse and open training datasets and simulations.
* 16 pages, 4 figures, 1 Table, published in IEEE Access Journal
A Situation-aware Enhancer for Personalized Recommendation
Mar 27, 2024When users interact with Recommender Systems (RecSys), current situations, such as time, location, and environment, significantly influence their preferences. Situations serve as the background for interactions, where relationships between users and items evolve with situation changes. However, existing RecSys treat situations, users, and items on the same level. They can only model the relations between situations and users/items respectively, rather than the dynamic impact of situations on user-item associations (i.e., user preferences). In this paper, we provide a new perspective that takes situations as the preconditions for users' interactions. This perspective allows us to separate situations from user/item representations, and capture situations' influences over the user-item relationship, offering a more comprehensive understanding of situations. Based on it, we propose a novel Situation-Aware Recommender Enhancer (SARE), a pluggable module to integrate situations into various existing RecSys. Since users' perception of situations and situations' impact on preferences are both personalized, SARE includes a Personalized Situation Fusion (PSF) and a User-Conditioned Preference Encoder (UCPE) to model the perception and impact of situations, respectively. We conduct experiments of applying SARE on seven backbones in various settings on two real-world datasets. Experimental results indicate that SARE improves the recommendation performances significantly compared with backbones and SOTA situation-aware baselines.
CATS: Enhancing Multivariate Time Series Forecasting by Constructing Auxiliary Time Series as Exogenous Variables
Mar 04, 2024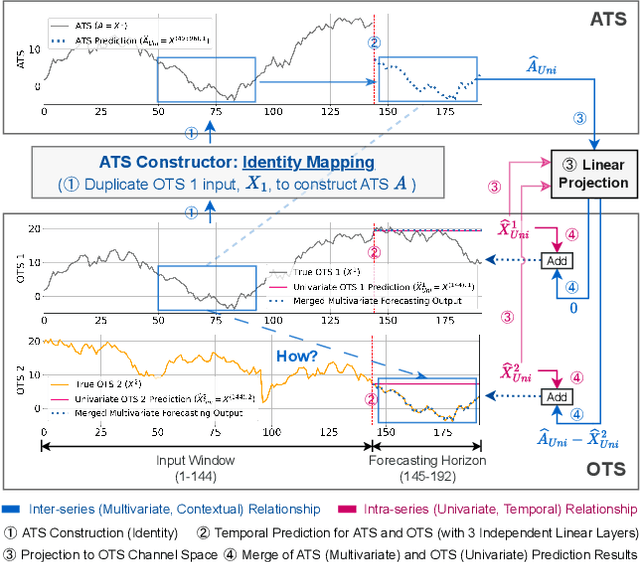
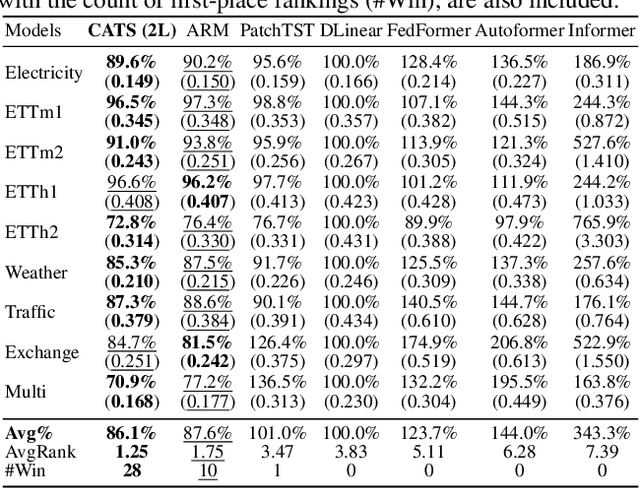
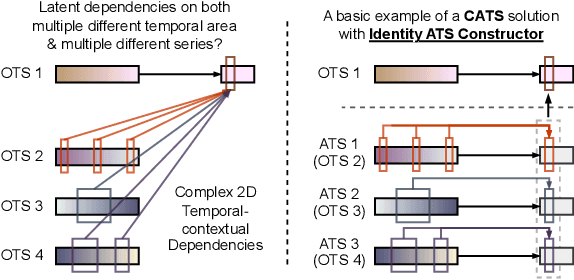
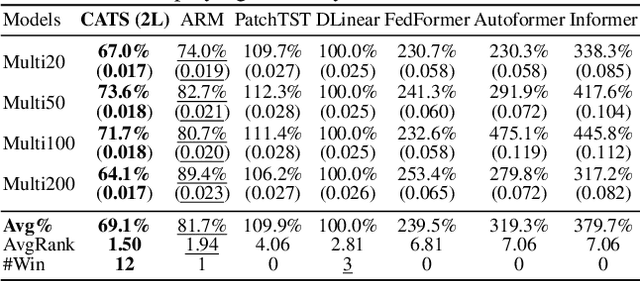
For Multivariate Time Series Forecasting (MTSF), recent deep learning applications show that univariate models frequently outperform multivariate ones. To address the difficiency in multivariate models, we introduce a method to Construct Auxiliary Time Series (CATS) that functions like a 2D temporal-contextual attention mechanism, which generates Auxiliary Time Series (ATS) from Original Time Series (OTS) to effectively represent and incorporate inter-series relationships for forecasting. Key principles of ATS - continuity, sparsity, and variability - are identified and implemented through different modules. Even with a basic 2-layer MLP as core predictor, CATS achieves state-of-the-art, significantly reducing complexity and parameters compared to previous multivariate models, marking it an efficient and transferable MTSF solution.
M^3RS: Multi-robot, Multi-objective, and Multi-mode Routing and Scheduling
Mar 24, 2024In this paper, we present a novel problem coined multi-robot, multi-objective, and multi-mode routing and scheduling (M^3RS). The formulation for M^3RS is introduced for time-bound multi-robot, multi-objective routing and scheduling missions where each task has multiple execution modes. Different execution modes have distinct resource consumption, associated execution time, and quality. M^3RS assigns the optimal sequence of tasks and the execution modes to each agent. The routes and associated modes depend on user preferences for different objective criteria. The need for M^3RS comes from multi-robot applications in which a trade-off between multiple criteria arises from different task execution modes. We use M^3RS for the application of multi-robot disinfection in public locations. The objectives considered for disinfection application are disinfection quality and number of tasks completed. A mixed-integer linear programming model is proposed for M^3RS. Then, a time-efficient column generation scheme is presented to tackle the issue of computation times for larger problem instances. The advantage of using multiple modes over fixed execution mode is demonstrated using experiments on synthetic data. The results suggest that M^3RS provides flexibility to the user in terms of available solutions and performs well in joint performance metrics. The application of the proposed problem is shown for a team of disinfection robots.} The videos for the experiments are available on the project website: https://sites.google.com/view/g-robot/m3rs/ .
Play to Your Strengths: Collaborative Intelligence of Conventional Recommender Models and Large Language Models
Mar 25, 2024The rise of large language models (LLMs) has opened new opportunities in Recommender Systems (RSs) by enhancing user behavior modeling and content understanding. However, current approaches that integrate LLMs into RSs solely utilize either LLM or conventional recommender model (CRM) to generate final recommendations, without considering which data segments LLM or CRM excel in. To fill in this gap, we conduct experiments on MovieLens-1M and Amazon-Books datasets, and compare the performance of a representative CRM (DCNv2) and an LLM (LLaMA2-7B) on various groups of data samples. Our findings reveal that LLMs excel in data segments where CRMs exhibit lower confidence and precision, while samples where CRM excels are relatively challenging for LLM, requiring substantial training data and a long training time for comparable performance. This suggests potential synergies in the combination between LLM and CRM. Motivated by these insights, we propose Collaborative Recommendation with conventional Recommender and Large Language Model (dubbed \textit{CoReLLa}). In this framework, we first jointly train LLM and CRM and address the issue of decision boundary shifts through alignment loss. Then, the resource-efficient CRM, with a shorter inference time, handles simple and moderate samples, while LLM processes the small subset of challenging samples for CRM. Our experimental results demonstrate that CoReLLa outperforms state-of-the-art CRM and LLM methods significantly, underscoring its effectiveness in recommendation tasks.
Engagement Measurement Based on Facial Landmarks and Spatial-Temporal Graph Convolutional Networks
Mar 25, 2024Engagement in virtual learning is crucial for a variety of factors including learner satisfaction, performance, and compliance with learning programs, but measuring it is a challenging task. There is therefore considerable interest in utilizing artificial intelligence and affective computing to measure engagement in natural settings as well as on a large scale. This paper introduces a novel, privacy-preserving method for engagement measurement from videos. It uses facial landmarks, which carry no personally identifiable information, extracted from videos via the MediaPipe deep learning solution. The extracted facial landmarks are fed to a Spatial-Temporal Graph Convolutional Network (ST-GCN) to output the engagement level of the learner in the video. To integrate the ordinal nature of the engagement variable into the training process, ST-GCNs undergo training in a novel ordinal learning framework based on transfer learning. Experimental results on two video student engagement measurement datasets show the superiority of the proposed method compared to previous methods with improved state-of-the-art on the EngageNet dataset with a %3.1 improvement in four-class engagement level classification accuracy and on the Online Student Engagement dataset with a %1.5 improvement in binary engagement classification accuracy. The relatively lightweight ST-GCN and its integration with the real-time MediaPipe deep learning solution make the proposed approach capable of being deployed on virtual learning platforms and measuring engagement in real time.
Single-Carrier Delay-Doppler Domain Equalization
Mar 25, 2024For doubly-selective channels, delay-Doppler (DD) modulation, mostly known as orthogonal time frequency space (OTFS) modulation, enables simultaneous compensation of delay and Doppler shifts. However, OTFS modulated signal has high peak-to-average power ratio (PAPR) because of its precoding operation performed over the DD domain. In order to deal with this problem, we propose a single-carrier transmission with delay-Doppler domain equalization (SC-DDE). In this system, the discretized time-domain SC signal is converted to the DD domain by discrete Zak transform (DZT) at the receiver side, followed by delay-Doppler domain equalization (DDE). Since equalization is performed in the DD domain, the SC-DDE receiver should acquire the channel delay-Doppler response. To this end, we introduce an embedded pilot-aided channel estimation scheme designed for SC-DDE, which does not affect the peak power property of transmitted signals. Through computer simulation, distribution of PAPR and bit error rate (BER) performance of the proposed system are compared with those of the conventional OTFS and SC with frequency-domain equalization (SC-FDE). As a result, our proposed SC-DDE significantly outperforms SC-FDE in terms of BER at the expense of additional computational complexity at the receiver. Furthermore, SC-DDE shows much lower PAPR than OTFS even though they achieve comparable coded BER performance.
FastCAR: Fast Classification And Regression Multi-Task Learning via Task Consolidation for Modelling a Continuous Property Variable of Object Classes
Mar 26, 2024FastCAR is a novel task consolidation approach in Multi-Task Learning (MTL) for a classification and a regression task, despite task heterogeneity with only subtle correlation. It addresses object classification and continuous property variable regression, a crucial use case in science and engineering. FastCAR involves a labeling transformation approach that can be used with a single-task regression network architecture. FastCAR outperforms traditional MTL model families, parametrized in the landscape of architecture and loss weighting schemes, when learning of both tasks are collectively considered (classification accuracy of 99.54%, regression mean absolute percentage error of 2.3%). The experiments performed used an Advanced Steel Property dataset contributed by us. The dataset comprises 4536 images of 224x224 pixels, annotated with object classes and hardness properties that take continuous values. With the labeling transformation and single-task regression network architecture, FastCAR achieves reduced latency and time efficiency.