 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sequential Multi-Dimensional Self-Supervised Learning for Clinical Time Series
Jul 20, 2023


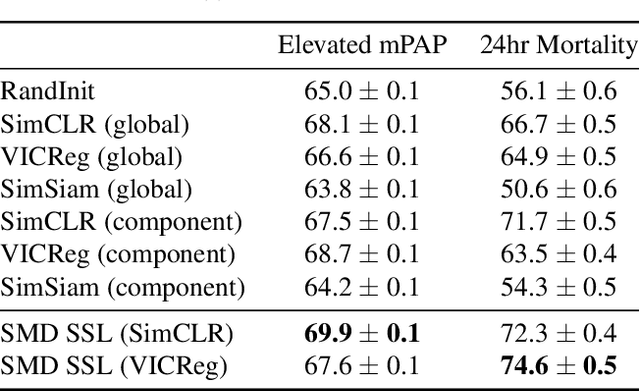
Self-supervised learning (SSL) for clinical time series data has received significant attention in recent literature, since these data are highly rich and provide important information about a patient's physiological state. However, most existing SSL methods for clinical time series are limited in that they are designed for unimodal time series, such as a sequence of structured features (e.g., lab values and vitals signs) or an individual high-dimensional physiological signal (e.g., an electrocardiogram). These existing methods cannot be readily extended to model time series that exhibit multimodality, with structured features and high-dimensional data being recorded at each timestep in the sequence. In this work, we address this gap and propose a new SSL method -- Sequential Multi-Dimensional SSL -- where a SSL loss is applied both at the level of the entire sequence and at the level of the individual high-dimensional data points in the sequence in order to better capture information at both scales. Our strategy is agnostic to the specific form of loss function used at each level -- it can be contrastive, as in SimCLR, or non-contrastive, as in VICReg. We evaluate our method on two real-world clinical datasets, where the time series contains sequences of (1) high-frequency electrocardiograms and (2) structured data from lab values and vitals signs. Our experimental results indicate that pre-training with our method and then fine-tuning on downstream tasks improves performance over baselines on both datasets, and in several settings, can lead to improvements across different self-supervised loss functions.
Noise-Robust DSP-Assisted Neural Pitch Estimation with Very Low Complexity
Sep 25, 2023Pitch estimation is an essential step of many speech processing algorithms, including speech coding, synthesis, and enhancement. Recently, pitch estimators based on deep neural networks (DNNs) have have been outperforming well-established DSP-based techniques. Unfortunately, these new estimators can be impractical to deploy in real-time systems, both because of their relatively high complexity, and the fact that some require significant lookahead. We show that a hybrid estimator using a small deep neural network (DNN) with traditional DSP-based features can match or exceed the performance of pure DNN-based models, with a complexity and algorithmic delay comparable to traditional DSP-based algorithms. We further demonstrate that this hybrid approach can provide benefits for a neural vocoding task.
Human-Assisted Continual Robot Learning with Foundation Models
Sep 25, 2023Large Language Models (LLMs) have been shown to act like planners that can decompose high-level instructions into a sequence of executable instructions. However, current LLM-based planners are only able to operate with a fixed set of skills. We overcome this critical limitation and present a method for using LLM-based planners to query new skills and teach robots these skills in a data and time-efficient manner for rigid object manipulation. Our system can re-use newly acquired skills for future tasks, demonstrating the potential of open world and lifelong learning. We evaluate the proposed framework on multiple tasks in simulation and the real world. Videos are available at: https://sites.google.com/mit.edu/halp-robot-learning.
Updated Corpora and Benchmarks for Long-Form Speech Recognition
Sep 26, 2023The vast majority of ASR research uses corpora in which both the training and test data have been pre-segmented into utterances. In most real-word ASR use-cases, however, test audio is not segmented, leading to a mismatch between inference-time conditions and models trained on segmented utterances. In this paper, we re-release three standard ASR corpora - TED-LIUM 3, Gigapeech, and VoxPopuli-en - with updated transcription and alignments to enable their use for long-form ASR research. We use these reconstituted corpora to study the train-test mismatch problem for transducers and attention-based encoder-decoders (AEDs), confirming that AEDs are more susceptible to this issue. Finally, we benchmark a simple long-form training for these models, showing its efficacy for model robustness under this domain shift.
Hybrid Genetic Search for Dynamic Vehicle Routing with Time Windows
Jul 26, 2023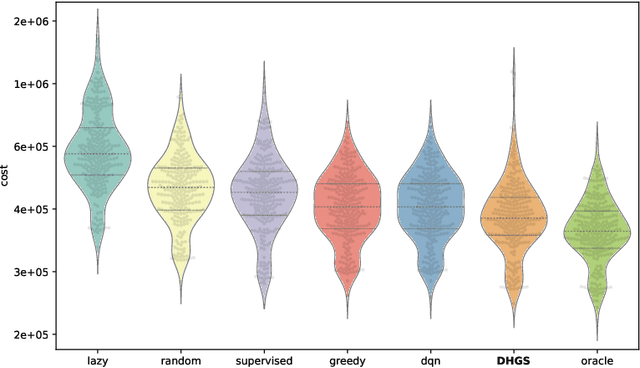
The dynamic vehicle routing problem with time windows (DVRPTW) is a generalization of the classical VRPTW to an online setting, where customer data arrives in batches and real-time routing solutions are required. In this paper we adapt the Hybrid Genetic Search (HGS) algorithm, a successful heuristic for VRPTW, to the dynamic variant. We discuss the affected components of the HGS algorithm including giant-tour representation, cost computation, initial population, crossover, and local search. Our approach modifies these components for DVRPTW, attempting to balance solution quality and constraints on future customer arrivals. To this end, we devise methods for comparing different-sized solutions, normalizing costs, and accounting for future epochs that do not require any prior training. Despite this limitation, computational results on data from the EURO meets NeurIPS Vehicle Routing Competition 2022 demonstrate significantly improved solution quality over the best-performing baseline algorithm.
Encountered-Type Haptic Display via Tracking Calibrated Robot
Sep 28, 2023In the past decades, a variety of haptic devices have been developed to facilitate high-fidelity human-computer interaction (HCI) in virtual reality (VR). In particular, passive haptic feedback can create a compelling sensation based on real objects spatially overlapping with their virtual counterparts. However, these approaches require pre-deployment efforts, hindering their democratizing use in practice. We propose the Tracking Calibrated Robot (TCR), a novel and general haptic approach to free developers from deployment efforts, which can be potentially deployed in any scenario. Specifically, we augment the VR with a collaborative robot that renders haptic contact in the real world while the user touches a virtual object in the virtual world. The distance between the user's finger and the robot end-effector is controlled over time. The distance starts to smoothly reduce to zero when the user intends to touch the virtual object. A mock user study tested users' perception of three virtual objects, and the result shows that TCR is effective in terms of conveying discriminative shape information.
Stackelberg Game-Theoretic Trajectory Guidance for Multi-Robot Systems with Koopman Operator
Sep 28, 2023Guided trajectory planning involves a leader robotic agent strategically directing a follower robotic agent to collaboratively reach a designated destination. However, this task becomes notably challenging when the leader lacks complete knowledge of the follower's decision-making model. There is a need for learning-based methods to effectively design the cooperative plan. To this end, we develop a Stackelberg game-theoretic approach based on Koopman operator to address the challenge. We first formulate the guided trajectory planning problem through the lens of a dynamic Stackelberg game. We then leverage Koopman operator theory to acquire a learning-based linear system model that approximates the follower's feedback dynamics. Based on this learned model, the leader devises a collision-free trajectory to guide the follower, employing receding horizon planning. We use simulations to elaborate the effectiveness of our approach in generating learning models that accurately predict the follower's multi-step behavior when compared to alternative learning techniques. Moreover, our approach successfully accomplishes the guidance task and notably reduces the leader's planning time to nearly half when contrasted with the model-based baseline method.
CaveSeg: Deep Semantic Segmentation and Scene Parsing for Autonomous Underwater Cave Exploration
Sep 28, 2023
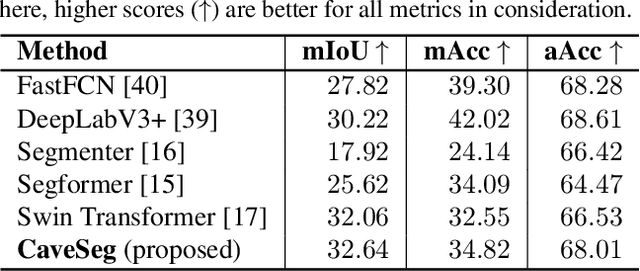

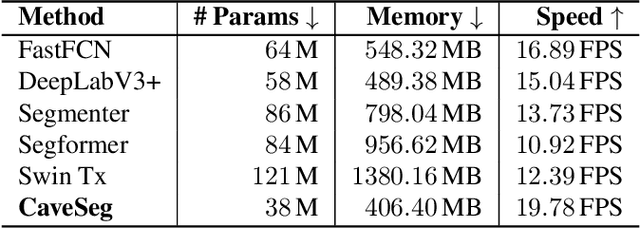
In this paper, we present CaveSeg - the first visual learning pipeline for semantic segmentation and scene parsing for AUV navigation inside underwater caves. We address the problem of scarce annotated training data by preparing a comprehensive dataset for semantic segmentation of underwater cave scenes. It contains pixel annotations for important navigation markers (e.g. caveline, arrows), obstacles (e.g. ground plain and overhead layers), scuba divers, and open areas for servoing. Through comprehensive benchmark analyses on cave systems in USA, Mexico, and Spain locations, we demonstrate that robust deep visual models can be developed based on CaveSeg for fast semantic scene parsing of underwater cave environments. In particular, we formulate a novel transformer-based model that is computationally light and offers near real-time execution in addition to achieving state-of-the-art performance. Finally, we explore the design choices and implications of semantic segmentation for visual servoing by AUVs inside underwater caves. The proposed model and benchmark dataset open up promising opportunities for future research in autonomous underwater cave exploration and mapping.
Adaptation of the super resolution SOTA for Art Restoration in camera capture images
Sep 28, 2023



Preserving cultural heritage is of paramount importance. In the domain of art restoration, developing a computer vision model capable of effectively restoring deteriorated images of art pieces was difficult, but now we have a good computer vision state-of-art. Traditional restoration methods are often time-consuming and require extensive expertise. The aim of this work is to design an automated solution based on computer vision models that can enhance and reconstruct degraded artworks, improving their visual quality while preserving their original characteristics and artifacts. The model should handle a diverse range of deterioration types, including but not limited to noise, blur, scratches, fading, and other common forms of degradation. We adapt the current state-of-art for the image super-resolution based on the Diffusion Model (DM) and fine-tune it for Image art restoration. Our results show that instead of fine-tunning multiple different models for different kinds of degradation, fine-tuning one super-resolution. We train it on multiple datasets to make it robust. code link: https://github.com/Naagar/art_restoration_DM
MEM: Multi-Modal Elevation Mapping for Robotics and Learning
Sep 28, 2023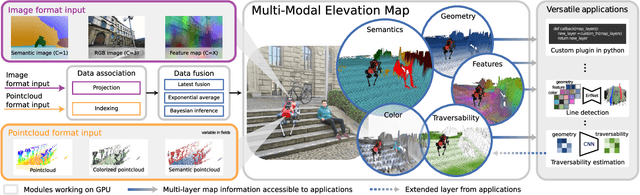
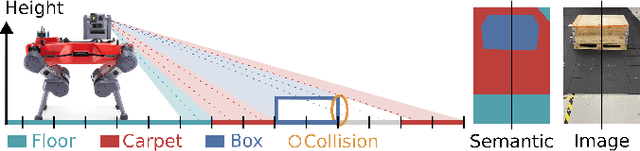
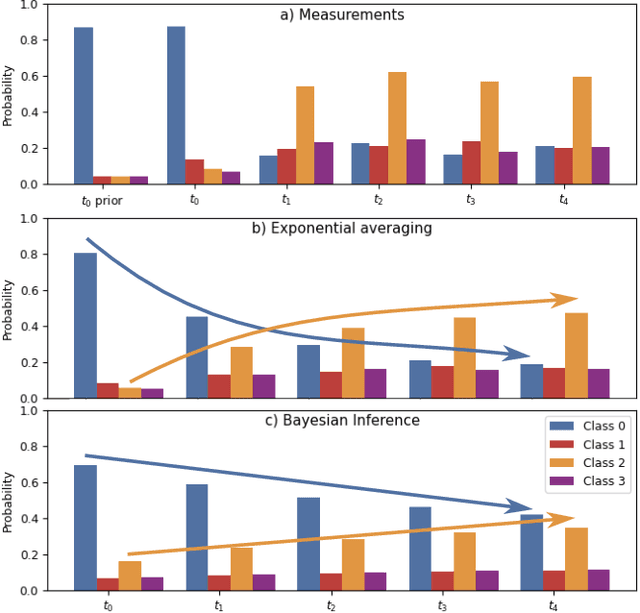
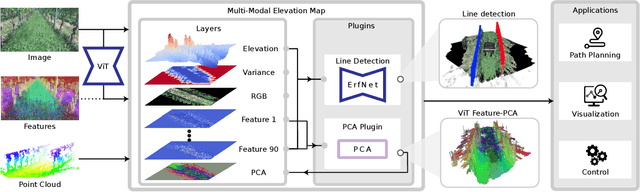
Elevation maps are commonly used to represent the environment of mobile robots and are instrumental for locomotion and navigation tasks. However, pure geometric information is insufficient for many field applications that require appearance or semantic information, which limits their applicability to other platforms or domains. In this work, we extend a 2.5D robot-centric elevation mapping framework by fusing multi-modal information from multiple sources into a popular map representation. The framework allows inputting data contained in point clouds or images in a unified manner. To manage the different nature of the data, we also present a set of fusion algorithms that can be selected based on the information type and user requirements. Our system is designed to run on the GPU, making it real-time capable for various robotic and learning tasks. We demonstrate the capabilities of our framework by deploying it on multiple robots with varying sensor configurations and showcasing a range of applications that utilize multi-modal layers, including line detection, human detection, and colorization.