 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Causality-informed Rapid Post-hurricane Building Damage Detection in Large Scale from InSAR Imagery
Oct 02, 2023
Timely and accurate assessment of hurricane-induced building damage is crucial for effective post-hurricane response and recovery efforts. Recently, remote sensing technologies provide large-scale optical or Interferometric Synthetic Aperture Radar (InSAR) imagery data immediately after a disastrous event, which can be readily used to conduct rapid building damage assessment. Compared to optical satellite imageries, the Synthetic Aperture Radar can penetrate cloud cover and provide more complete spatial coverage of damaged zones in various weather conditions. However, these InSAR imageries often contain highly noisy and mixed signals induced by co-occurring or co-located building damage, flood, flood/wind-induced vegetation changes, as well as anthropogenic activities, making it challenging to extract accurate building damage information. In this paper, we introduced an approach for rapid post-hurricane building damage detection from InSAR imagery. This approach encoded complex causal dependencies among wind, flood, building damage, and InSAR imagery using a holistic causal Bayesian network. Based on the causal Bayesian network, we further jointly inferred the large-scale unobserved building damage by fusing the information from InSAR imagery with prior physical models of flood and wind, without the need for ground truth labels. Furthermore, we validated our estimation results in a real-world devastating hurricane -- the 2022 Hurricane Ian. We gathered and annotated building damage ground truth data in Lee County, Florida, and compared the introduced method's estimation results with the ground truth and benchmarked it against state-of-the-art models to assess the effectiveness of our proposed method. Results show that our method achieves rapid and accurate detection of building damage, with significantly reduced processing time compared to traditional manual inspection methods.
Making LLaMA SEE and Draw with SEED Tokenizer
Oct 02, 2023The great success of Large Language Models (LLMs) has expanded the potential of multimodality, contributing to the gradual evolution of General Artificial Intelligence (AGI). A true AGI agent should not only possess the capability to perform predefined multi-tasks but also exhibit emergent abilities in an open-world context. However, despite the considerable advancements made by recent multimodal LLMs, they still fall short in effectively unifying comprehension and generation tasks, let alone open-world emergent abilities. We contend that the key to overcoming the present impasse lies in enabling text and images to be represented and processed interchangeably within a unified autoregressive Transformer. To this end, we introduce SEED, an elaborate image tokenizer that empowers LLMs with the ability to SEE and Draw at the same time. We identify two crucial design principles: (1) Image tokens should be independent of 2D physical patch positions and instead be produced with a 1D causal dependency, exhibiting intrinsic interdependence that aligns with the left-to-right autoregressive prediction mechanism in LLMs. (2) Image tokens should capture high-level semantics consistent with the degree of semantic abstraction in words, and be optimized for both discriminativeness and reconstruction during the tokenizer training phase. With SEED tokens, LLM is able to perform scalable multimodal autoregression under its original training recipe, i.e., next-word prediction. SEED-LLaMA is therefore produced by large-scale pretraining and instruction tuning on the interleaved textual and visual data, demonstrating impressive performance on a broad range of multimodal comprehension and generation tasks. More importantly, SEED-LLaMA has exhibited compositional emergent abilities such as multi-turn in-context multimodal generation, acting like your AI assistant.
A Novel Approach for Machine Learning-based Load Balancing in High-speed Train System using Nested Cross Validation
Oct 02, 2023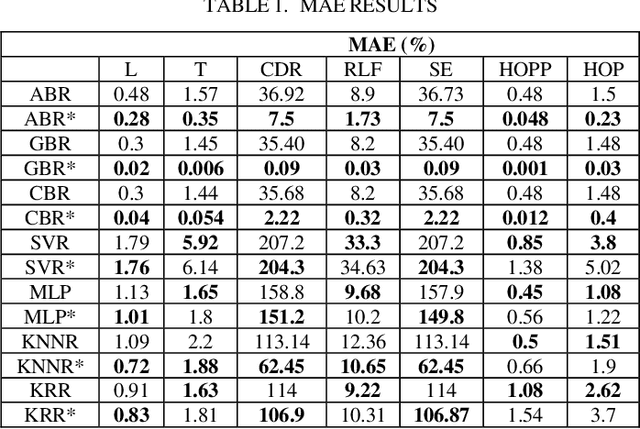
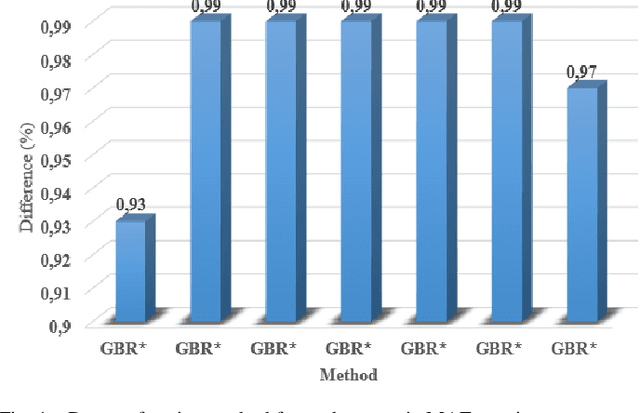
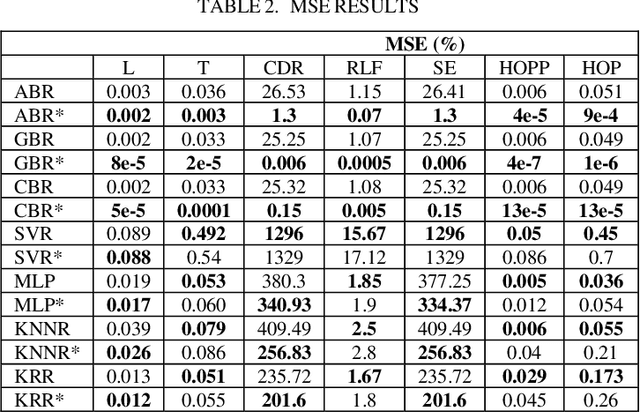
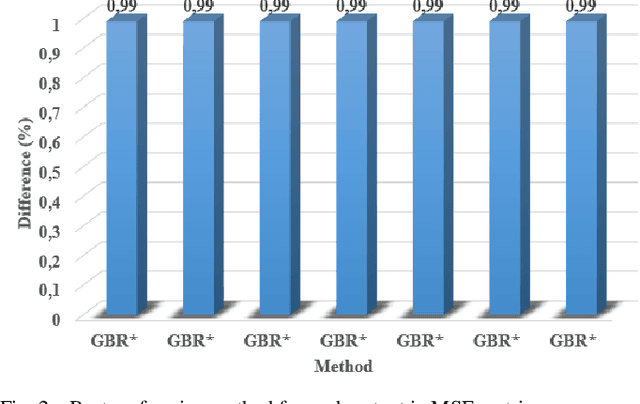
Fifth-generation (5G) mobile communication networks have recently emerged in various fields, including highspeed trains. However, the dense deployment of 5G millimeter wave (mmWave) base stations (BSs) and the high speed of moving trains lead to frequent handovers (HOs), which can adversely affect the Quality-of-Service (QoS) of mobile users. As a result, HO optimization and resource allocation are essential considerations for managing mobility in high-speed train systems. In this paper, we model system performance of a high-speed train system with a novel machine learning (ML) approach that is nested cross validation scheme that prevents information leakage from model evaluation into the model parameter tuning, thereby avoiding overfitting and resulting in better generalization error. To this end, we employ ML methods for the high-speed train system scenario. Handover Margin (HOM) and Time-to-Trigger (TTT) values are used as features, and several KPIs are used as outputs, and several ML methods including Gradient Boosting Regression (GBR), Adaptive Boosting (AdaBoost), CatBoost Regression (CBR), Artificial Neural Network (ANN), Kernel Ridge Regression (KRR), Support Vector Regression (SVR), and k-Nearest Neighbor Regression (KNNR) are employed for the problem. Finally, performance comparisons of the cross validation schemes with the methods are made in terms of mean absolute error (MAE) and mean square error (MSE) metrics are made. As per obtained results, boosting methods, ABR, CBR, GBR, with nested cross validation scheme superiorly outperforms conventional cross validation scheme results with the same methods. On the other hand, SVR, KNRR, KRR, ANN with the nested scheme produce promising results for prediction of some KPIs with respect to their conventional scheme employment.
On Computational Entanglement and Its Interpretation in Adversarial Machine Learning
Sep 27, 2023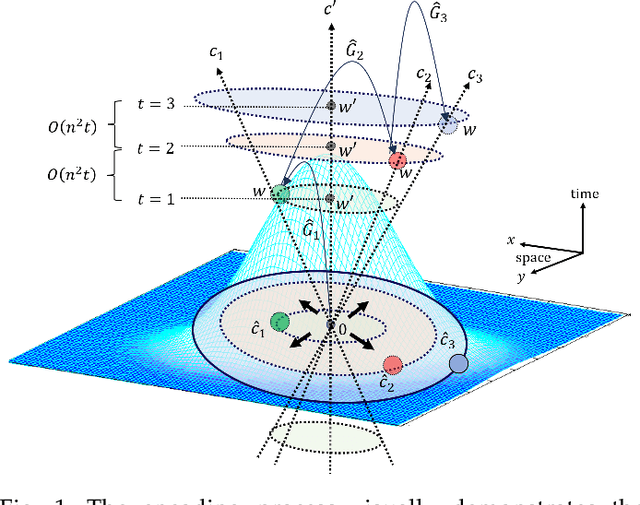
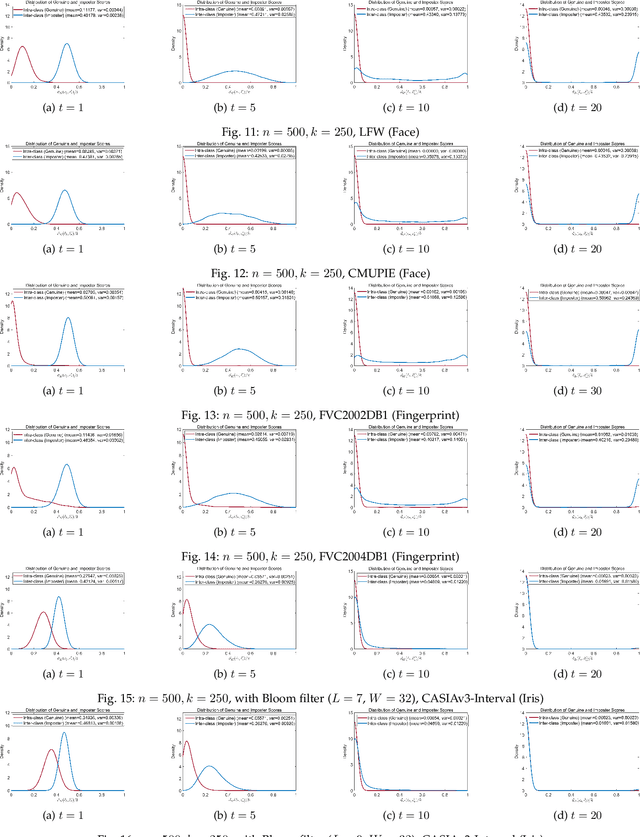
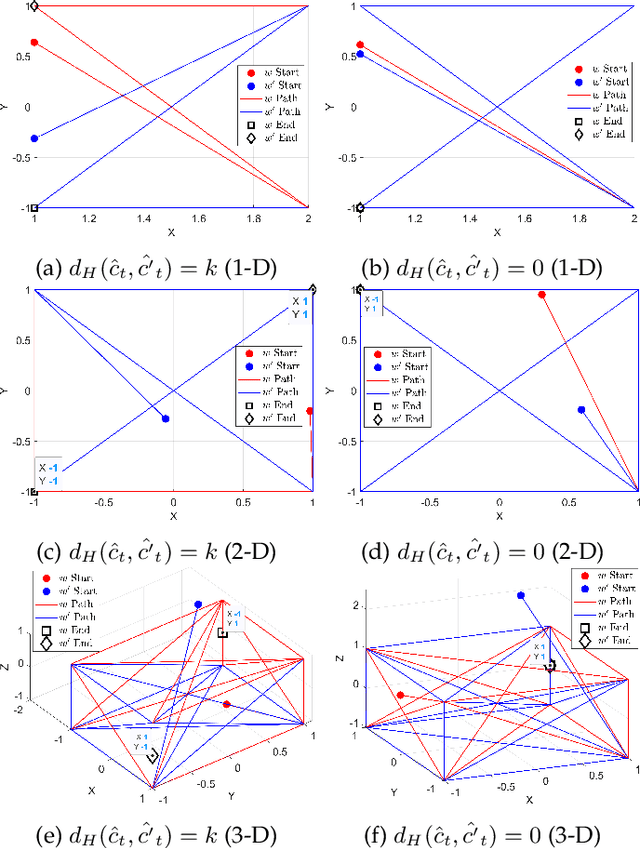
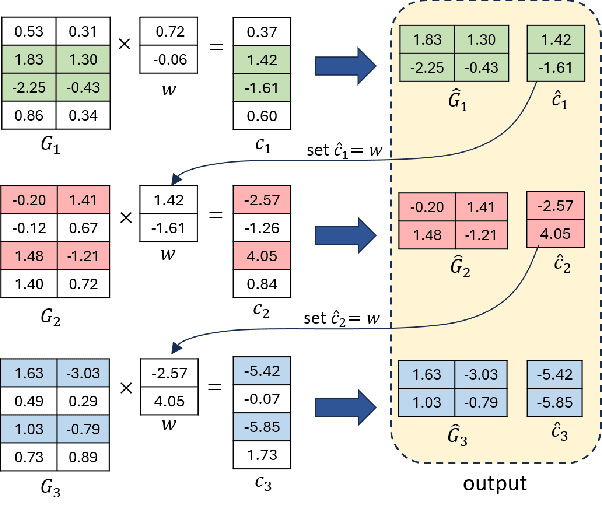
Adversarial examples in machine learning has emerged as a focal point of research due to their remarkable ability to deceive models with seemingly inconspicuous input perturbations, potentially resulting in severe consequences. In this study, we embark on a comprehensive exploration of adversarial machine learning models, shedding light on their intrinsic complexity and interpretability. Our investigation reveals intriguing links between machine learning model complexity and Einstein's theory of special relativity, through the concept of entanglement. More specific, we define entanglement computationally and demonstrate that distant feature samples can exhibit strong correlations, akin to entanglement in quantum realm. This revelation challenges conventional perspectives in describing the phenomenon of adversarial transferability observed in contemporary machine learning models. By drawing parallels with the relativistic effects of time dilation and length contraction during computation, we gain deeper insights into adversarial machine learning, paving the way for more robust and interpretable models in this rapidly evolving field.
An Exploration of Optimal Parameters for Efficient Blind Source Separation of EEG Recordings Using AMICA
Sep 27, 2023EEG continues to find a multitude of uses in both neuroscience research and medical practice, and independent component analysis (ICA) continues to be an important tool for analyzing EEG. A multitude of ICA algorithms for EEG decomposition exist, and in the past, their relative effectiveness has been studied. AMICA is considered the benchmark against which to compare the performance of other ICA algorithms for EEG decomposition. AMICA exposes many parameters to the user to allow for precise control of the decomposition. However, several of the parameters currently tend to be set according to "rules of thumb" shared in the EEG community. Here, AMICA decompositions are run on data from a collection of subjects while varying certain key parameters. The running time and quality of decompositions are analyzed based on two metrics: Pairwise Mutual Information (PMI) and Mutual Information Reduction (MIR). Recommendations for selecting starting values for parameters are presented.
Diagnosis of Helicobacter pylori using AutoEncoders for the Detection of Anomalous Staining Patterns in Immunohistochemistry Images
Sep 27, 2023This work addresses the detection of Helicobacter pylori a bacterium classified since 1994 as class 1 carcinogen to humans. By its highest specificity and sensitivity, the preferred diagnosis technique is the analysis of histological images with immunohistochemical staining, a process in which certain stained antibodies bind to antigens of the biological element of interest. This analysis is a time demanding task, which is currently done by an expert pathologist that visually inspects the digitized samples. We propose to use autoencoders to learn latent patterns of healthy tissue and detect H. pylori as an anomaly in image staining. Unlike existing classification approaches, an autoencoder is able to learn patterns in an unsupervised manner (without the need of image annotations) with high performance. In particular, our model has an overall 91% of accuracy with 86\% sensitivity, 96% specificity and 0.97 AUC in the detection of H. pylori.
Skilog: A Smart Sensor System for Performance Analysis and Biofeedback in Ski Jumping
Sep 25, 2023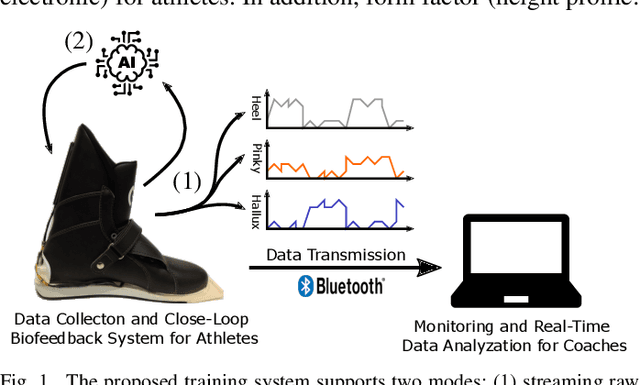
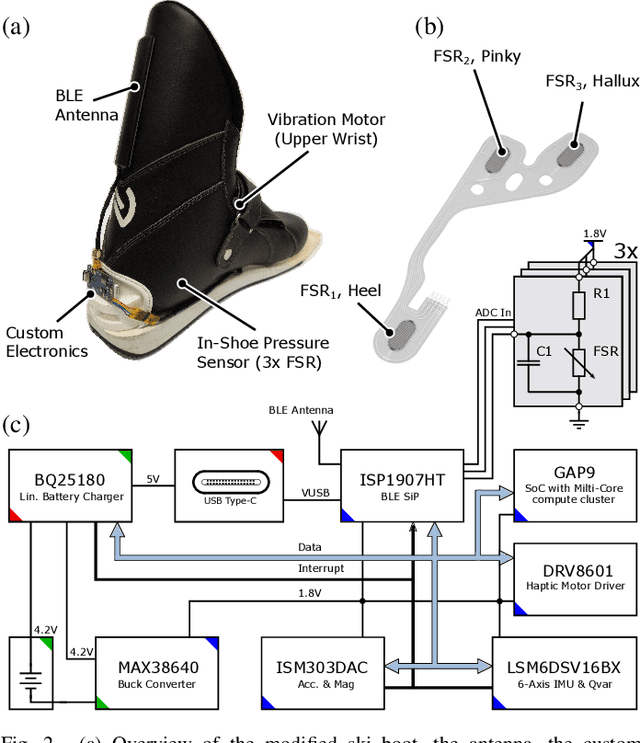
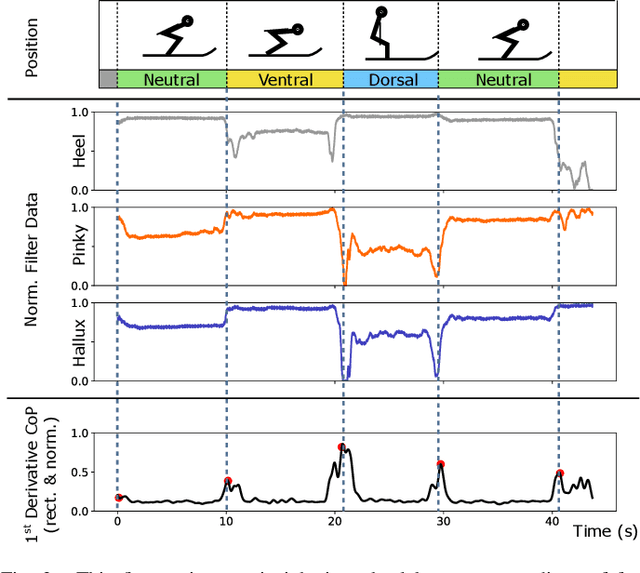
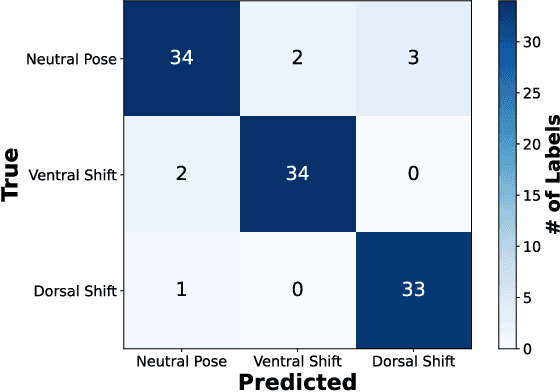
In ski jumping, low repetition rates of jumps limit the effectiveness of training. Thus, increasing learning rate within every single jump is key to success. A critical element of athlete training is motor learning, which has been shown to be accelerated by feedback methods. In particular, a fine-grained control of the center of gravity in the in-run is essential. This is because the actual takeoff occurs within a blink of an eye ($\sim$300ms), thus any unbalanced body posture during the in-run will affect flight. This paper presents a smart, compact, and energy-efficient wireless sensor system for real-time performance analysis and biofeedback during ski jumping. The system operates by gauging foot pressures at three distinct points on the insoles of the ski boot at 100Hz. Foot pressure data can either be directly sent to coaches to improve their feedback, or fed into a ML model to give athletes instantaneous in-action feedback using a vibration motor in the ski boot. In the biofeedback scenario, foot pressures act as input variables for an optimized XGBoost model. We achieve a high predictive accuracy of 92.7% for center of mass predictions (dorsal shift, neutral stand, ventral shift). Subsequently, we parallelized and fine-tuned our XGBoost model for a RISC-V based low power parallel processor (GAP9), based on the PULP architecture. We demonstrate real-time detection and feedback (0.0109ms/inference) using our on-chip deployment. The proposed smart system is unobtrusive with a slim form factor (13mm baseboard, 3.2mm antenna) and a lightweight build (26g). Power consumption analysis reveals that the system's energy-efficient design enables sustained operation over multiple days (up to 300 hours) without requiring recharge.
DSLOT-NN: Digit-Serial Left-to-Right Neural Network Accelerator
Sep 22, 2023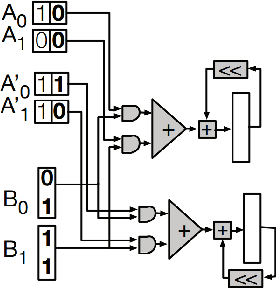
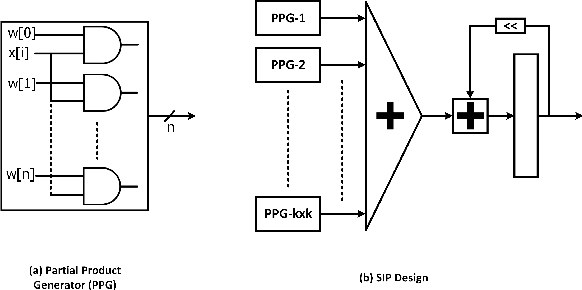
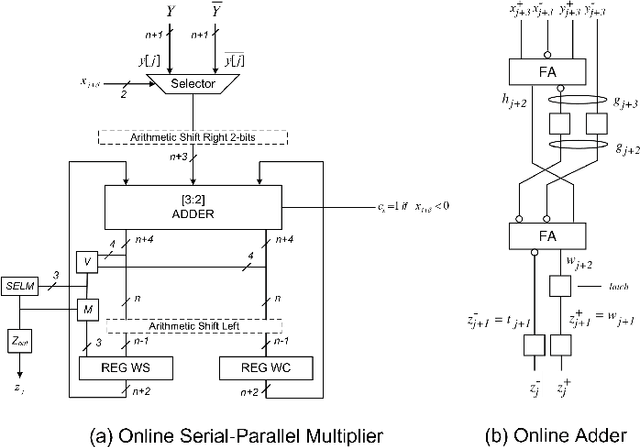
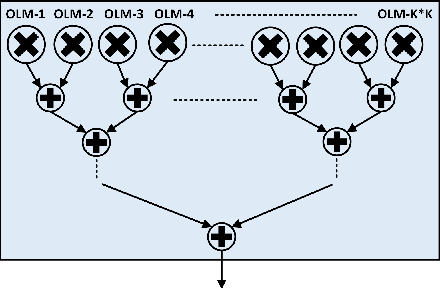
We propose a Digit-Serial Left-tO-righT (DSLOT) arithmetic based processing technique called DSLOT-NN with aim to accelerate inference of the convolution operation in the deep neural networks (DNNs). The proposed work has the ability to assess and terminate the ineffective convolutions which results in massive power and energy savings. The processing engine is comprised of low-latency most-significant-digit-first (MSDF) (also called online) multipliers and adders that processes data from left-to-right, allowing the execution of subsequent operations in digit-pipelined manner. Use of online operators eliminates the need for the development of complex mechanism of identifying the negative activation, as the output with highest weight value is generated first, and the sign of the result can be identified as soon as first non-zero digit is generated. The precision of the online operators can be tuned at run-time, making them extremely useful in situations where accuracy can be compromised for power and energy savings. The proposed design has been implemented on Xilinx Virtex-7 FPGA and is compared with state-of-the-art Stripes on various performance metrics. The results show the proposed design presents power savings, has shorter cycle time, and approximately 50% higher OPS per watt.
A Ground Segmentation Method Based on Point Cloud Map for Unstructured Roads
Sep 15, 2023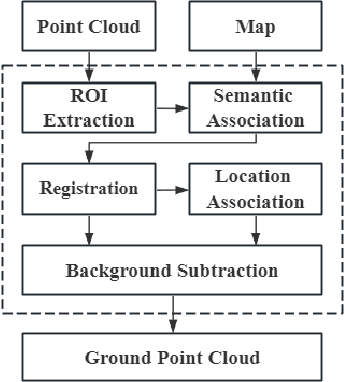
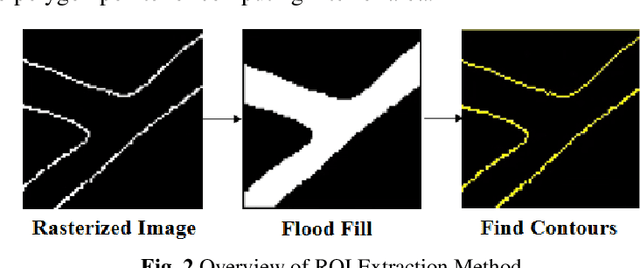
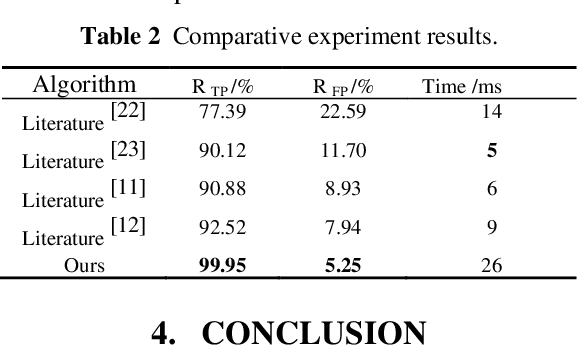

Ground segmentation, as the basic task of unmanned intelligent perception, provides an important support for the target detection task. Unstructured road scenes represented by open-pit mines have irregular boundary lines and uneven road surfaces, which lead to segmentation errors in current ground segmentation methods. To solve this problem, a ground segmentation method based on point cloud map is proposed, which involves three parts: region of interest extraction, point cloud registration and background subtraction. Firstly, establishing boundary semantic associations to obtain regions of interest in unstructured roads. Secondly, establishing the location association between point cloud map and the real-time point cloud of region of interest by semantics information. Thirdly, establishing a background model based on Gaussian distribution according to location association, and segments the ground in real-time point cloud by the background substraction method. Experimental results show that the correct segmentation rate of ground points is 99.95%, and the running time is 26ms. Compared with state of the art ground segmentation algorithm Patchwork++, the average accuracy of ground point segmentation is increased by 7.43%, and the running time is increased by 17ms. Furthermore, the proposed method is practically applied to unstructured road scenarios represented by open pit mines.
Noise-Robust DSP-Assisted Neural Pitch Estimation with Very Low Complexity
Sep 25, 2023Pitch estimation is an essential step of many speech processing algorithms, including speech coding, synthesis, and enhancement. Recently, pitch estimators based on deep neural networks (DNNs) have have been outperforming well-established DSP-based techniques. Unfortunately, these new estimators can be impractical to deploy in real-time systems, both because of their relatively high complexity, and the fact that some require significant lookahead. We show that a hybrid estimator using a small deep neural network (DNN) with traditional DSP-based features can match or exceed the performance of pure DNN-based models, with a complexity and algorithmic delay comparable to traditional DSP-based algorithms. We further demonstrate that this hybrid approach can provide benefits for a neural vocoding task.