 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Long-Short Temporal Attention Network for Unsupervised Video Object Segmentation
Sep 21, 2023
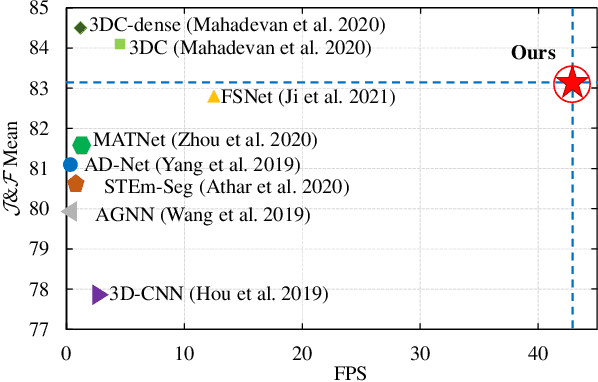
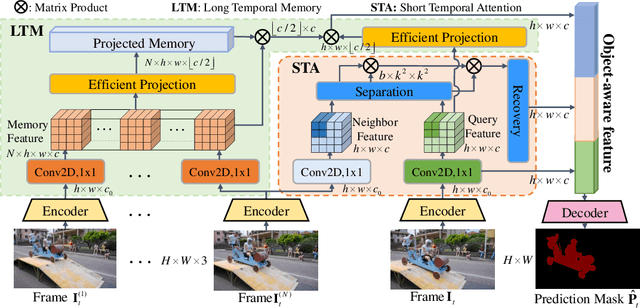
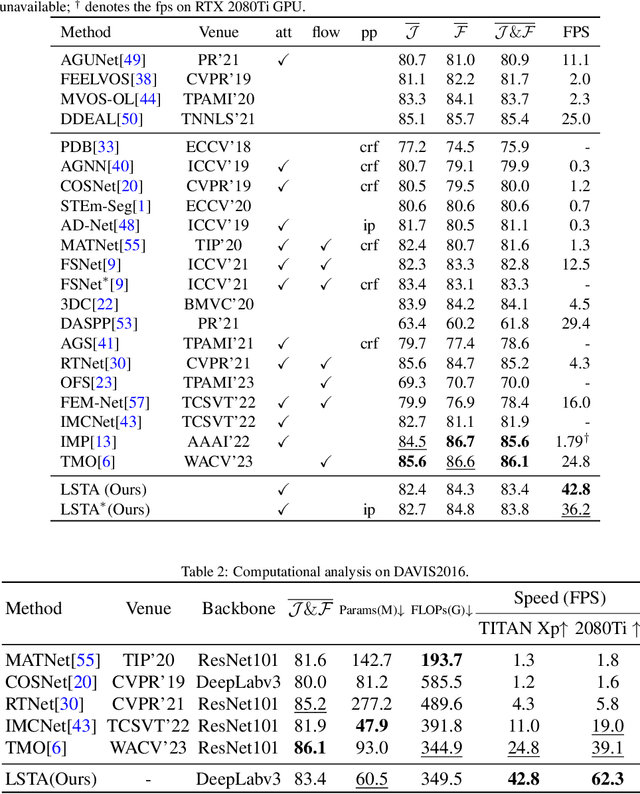
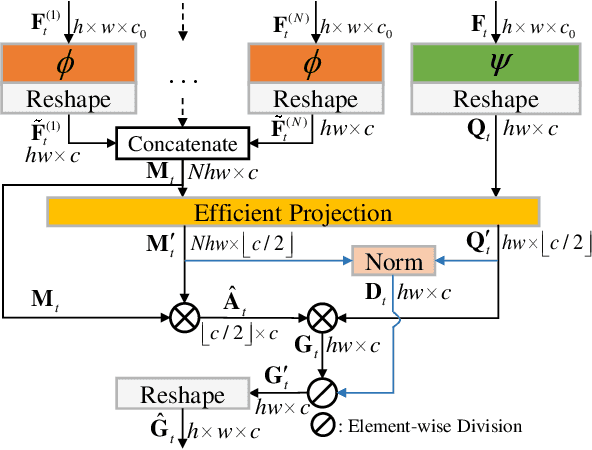
Unsupervised Video Object Segmentation (VOS) aims at identifying the contours of primary foreground objects in videos without any prior knowledge. However, previous methods do not fully use spatial-temporal context and fail to tackle this challenging task in real-time. This motivates us to develop an efficient Long-Short Temporal Attention network (termed LSTA) for unsupervised VOS task from a holistic view. Specifically, LSTA consists of two dominant modules, i.e., Long Temporal Memory and Short Temporal Attention. The former captures the long-term global pixel relations of the past frames and the current frame, which models constantly present objects by encoding appearance pattern. Meanwhile, the latter reveals the short-term local pixel relations of one nearby frame and the current frame, which models moving objects by encoding motion pattern. To speedup the inference, the efficient projection and the locality-based sliding window are adopted to achieve nearly linear time complexity for the two light modules, respectively. Extensive empirical studies on several benchmarks have demonstrated promising performances of the proposed method with high efficiency.
Causal Discovery and Prediction: Methods and Algorithms
Sep 18, 2023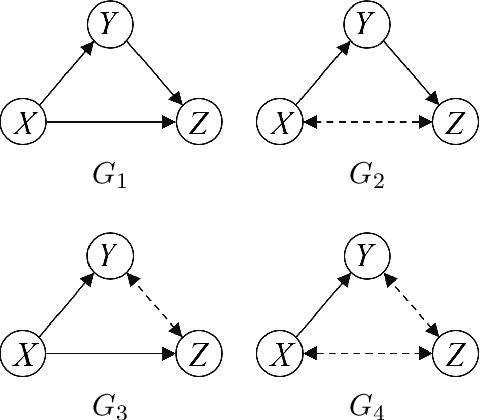
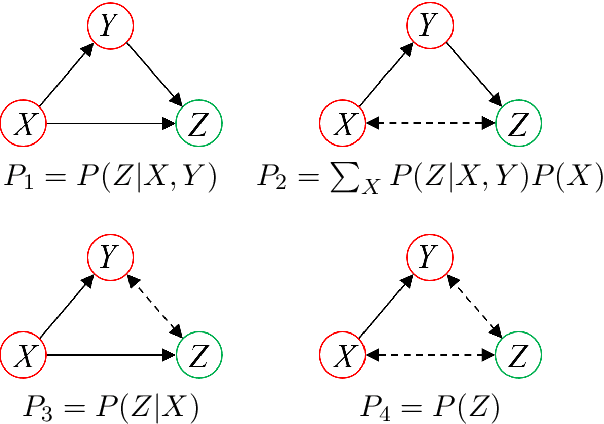
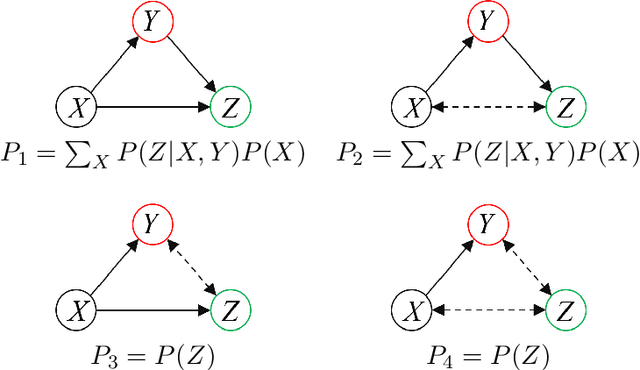
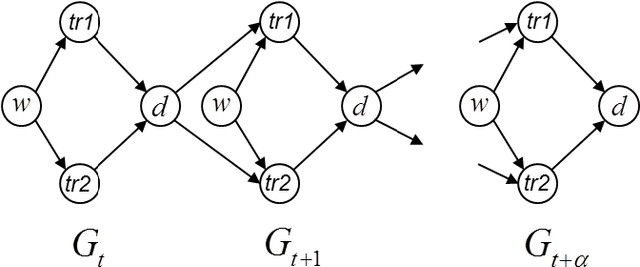
We are not only observers but also actors of reality. Our capability to intervene and alter the course of some events in the space and time surrounding us is an essential component of how we build our model of the world. In this doctoral thesis we introduce a generic a-priori assessment of each possible intervention, in order to select the most cost-effective interventions only, and avoid unnecessary systematic experimentation on the real world. Based on this a-priori assessment, we propose an active learning algorithm that identifies the causal relations in any given causal model, using a least cost sequence of interventions. There are several novel aspects introduced by our algorithm. It is, in most case scenarios, able to discard many causal model candidates using relatively inexpensive interventions that only test one value of the intervened variables. Also, the number of interventions performed by the algorithm can be bounded by the number of causal model candidates. Hence, fewer initial candidates (or equivalently, more prior knowledge) lead to fewer interventions for causal discovery. Causality is intimately related to time, as causes appear to precede their effects. Cyclical causal processes are a very interesting case of causality in relation to time. In this doctoral thesis we introduce a formal analysis of time cyclical causal settings by defining a causal analog to the purely observational Dynamic Bayesian Networks, and provide a sound and complete algorithm for the identification of causal effects in the cyclic setting. We introduce the existence of two types of hidden confounder variables in this framework, which affect in substantially different ways the identification procedures, a distinction with no analog in either Dynamic Bayesian Networks or standard causal graphs.
UniLVSeg: Unified Left Ventricular Segmentation with Sparsely Annotated Echocardiogram Videos through Self-Supervised Temporal Masking and Weakly Supervised Training
Sep 30, 2023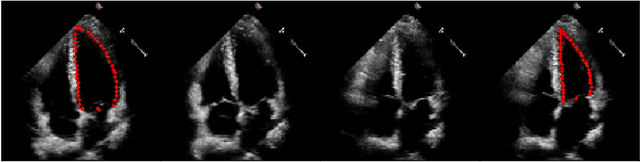
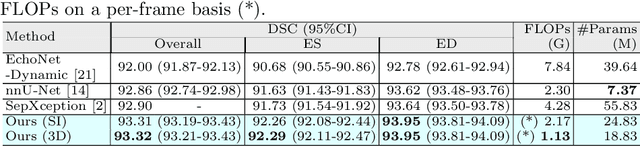
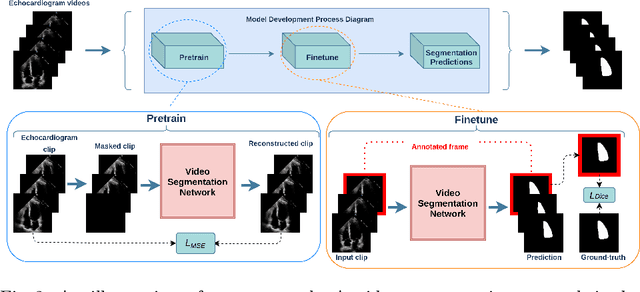
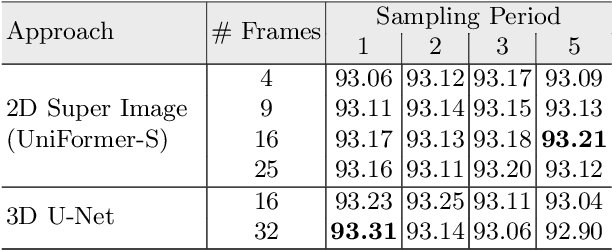
Echocardiography has become an indispensable clinical imaging modality for general heart health assessment. From calculating biomarkers such as ejection fraction to the probability of a patient's heart failure, accurate segmentation of the heart and its structures allows doctors to plan and execute treatments with greater precision and accuracy. However, achieving accurate and robust left ventricle segmentation is time-consuming and challenging due to different reasons. This work introduces a novel approach for consistent left ventricular (LV) segmentation from sparsely annotated echocardiogram videos. We achieve this through (1) self-supervised learning (SSL) using temporal masking followed by (2) weakly supervised training. We investigate two different segmentation approaches: 3D segmentation and a novel 2D superimage (SI). We demonstrate how our proposed method outperforms the state-of-the-art solutions by achieving a 93.32% (95%CI 93.21-93.43%) dice score on a large-scale dataset (EchoNet-Dynamic) while being more efficient. To show the effectiveness of our approach, we provide extensive ablation studies, including pre-training settings and various deep learning backbones. Additionally, we discuss how our proposed methodology achieves high data utility by incorporating unlabeled frames in the training process. To help support the AI in medicine community, the complete solution with the source code will be made publicly available upon acceptance.
DISCO Might Not Be Funky: Random Intelligent Reflective Surface Configurations That Attack
Oct 01, 2023Emerging intelligent reflective surfaces (IRSs) significantly improve system performance, but also pose a signifcant risk for physical layer security (PLS). Unlike the extensive research on legitimate IRS-enhanced communications, in this article we present an adversarial IRS-based fully-passive jammer (FPJ). We describe typical application scenarios for Disco IRS (DIRS)-based FPJ, where an illegitimate IRS with random, time-varying reflection properties acts like a "disco ball" to randomly change the propagation environment. We introduce the principles of DIRS-based FPJ and overview existing investigations of the technology, including a design example employing one-bit phase shifters. The DIRS-based FPJ can be implemented without either jamming power or channel state information (CSI) for the legitimate users (LUs). It does not suffer from the energy constraints of traditional active jammers, nor does it require any knowledge of the LU channels. In addition to the proposed jamming attack, we also propose an anti-jamming strategy that requires only statistical rather than instantaneous CSI. Furthermore, we present a data frame structure that enables the legitimate access point (AP) to estimate the statistical CSI in the presence of the DIRS jamming. Typical cases are discussed to show the impact of the DIRS-based FPJ and the feasibility of the anti-jamming precoder. Moreover, we outline future research directions and challenges for the DIRS-based FPJ and its anti-jamming precoding to stimulate this line of research and pave the way for practical applications.
Character Time-series Matching For Robust License Plate Recognition
Jul 21, 2023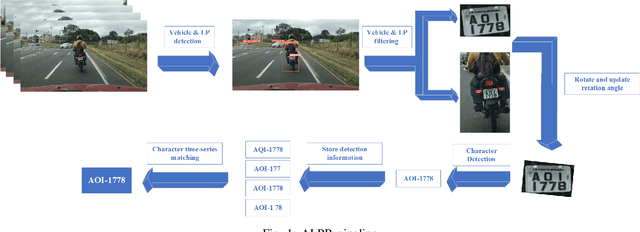
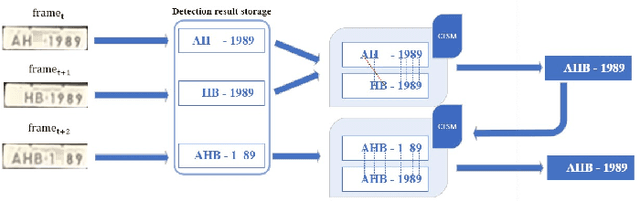
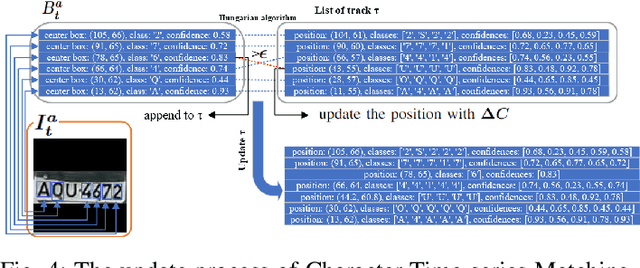

Automatic License Plate Recognition (ALPR) is becoming a popular study area and is applied in many fields such as transportation or smart city. However, there are still several limitations when applying many current methods to practical problems due to the variation in real-world situations such as light changes, unclear License Plate (LP) characters, and image quality. Almost recent ALPR algorithms process on a single frame, which reduces accuracy in case of worse image quality. This paper presents methods to improve license plate recognition accuracy by tracking the license plate in multiple frames. First, the Adaptive License Plate Rotation algorithm is applied to correctly align the detected license plate. Second, we propose a method called Character Time-series Matching to recognize license plate characters from many consequence frames. The proposed method archives high performance in the UFPR-ALPR dataset which is \boldmath$96.7\%$ accuracy in real-time on RTX A5000 GPU card. We also deploy the algorithm for the Vietnamese ALPR system. The accuracy for license plate detection and character recognition are 0.881 and 0.979 $mAP^{test}$@.5 respectively. The source code is available at https://github.com/chequanghuy/Character-Time-series-Matching.git
Towards Free Data Selection with General-Purpose Models
Sep 29, 2023

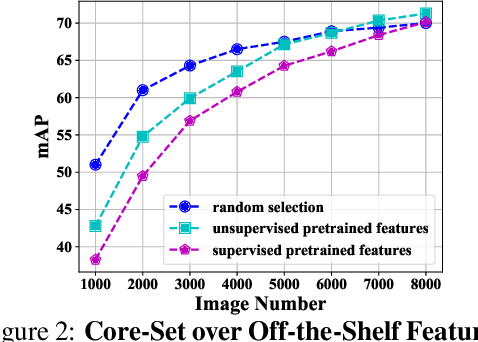
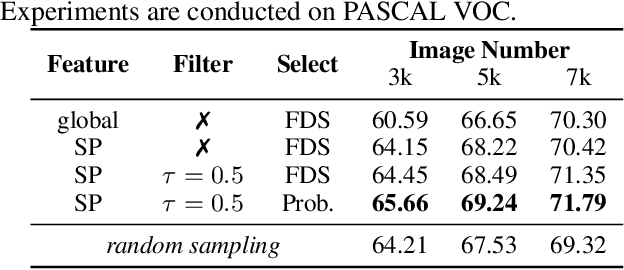
A desirable data selection algorithm can efficiently choose the most informative samples to maximize the utility of limited annotation budgets. However, current approaches, represented by active learning methods, typically follow a cumbersome pipeline that iterates the time-consuming model training and batch data selection repeatedly. In this paper, we challenge this status quo by designing a distinct data selection pipeline that utilizes existing general-purpose models to select data from various datasets with a single-pass inference without the need for additional training or supervision. A novel free data selection (FreeSel) method is proposed following this new pipeline. Specifically, we define semantic patterns extracted from inter-mediate features of the general-purpose model to capture subtle local information in each image. We then enable the selection of all data samples in a single pass through distance-based sampling at the fine-grained semantic pattern level. FreeSel bypasses the heavy batch selection process, achieving a significant improvement in efficiency and being 530x faster than existing active learning methods. Extensive experiments verify the effectiveness of FreeSel on various computer vision tasks. Our code is available at https://github.com/yichen928/FreeSel.
Multi-Objective Sparse Sensing with Ergodic Optimization
Sep 29, 2023We consider a search problem where a robot has one or more types of sensors, each suited to detecting different types of targets or target information. Often, information in the form of a distribution of possible target locations, or locations of interest, may be available to guide the search. When multiple types of information exist, then a distribution for each type of information must also exist, thereby making the search problem that uses these distributions to guide the search a multi-objective one. In this paper, we consider a multi-objective search problem when the cost to use a sensor is limited. To this end, we leverage the ergodic metric, which drives agents to spend time in regions proportional to the expected amount of information there. We define the multi-objective sparse sensing ergodic (MO-SS-E) metric in order to optimize when and where each sensor measurement should be taken while planning trajectories that balance the multiple objectives. We observe that our approach maintains coverage performance as the number of samples taken considerably degrades. Further empirical results on different multi-agent problem setups demonstrate the applicability of our approach for both homogeneous and heterogeneous multi-agent teams.
Gradient and Uncertainty Enhanced Sequential Sampling for Global Fit
Sep 29, 2023Surrogate models based on machine learning methods have become an important part of modern engineering to replace costly computer simulations. The data used for creating a surrogate model are essential for the model accuracy and often restricted due to cost and time constraints. Adaptive sampling strategies have been shown to reduce the number of samples needed to create an accurate model. This paper proposes a new sampling strategy for global fit called Gradient and Uncertainty Enhanced Sequential Sampling (GUESS). The acquisition function uses two terms: the predictive posterior uncertainty of the surrogate model for exploration of unseen regions and a weighted approximation of the second and higher-order Taylor expansion values for exploitation. Although various sampling strategies have been proposed so far, the selection of a suitable method is not trivial. Therefore, we compared our proposed strategy to 9 adaptive sampling strategies for global surrogate modeling, based on 26 different 1 to 8-dimensional deterministic benchmarks functions. Results show that GUESS achieved on average the highest sample efficiency compared to other surrogate-based strategies on the tested examples. An ablation study considering the behavior of GUESS in higher dimensions and the importance of surrogate choice is also presented.
On the Power of the Weisfeiler-Leman Test for Graph Motif Parameters
Oct 02, 2023Seminal research in the field of graph neural networks (GNNs) has revealed a direct correspondence between the expressive capabilities of GNNs and the $k$-dimensional Weisfeiler-Leman ($k$WL) test, a widely-recognized method for verifying graph isomorphism. This connection has reignited interest in comprehending the specific graph properties effectively distinguishable by the $k$WL test. A central focus of research in this field revolves around determining the least dimensionality $k$, for which $k$WL can discern graphs with different number of occurrences of a pattern graph $P$. We refer to such a least $k$ as the WL-dimension of this pattern counting problem. This inquiry traditionally delves into two distinct counting problems related to patterns: subgraph counting and induced subgraph counting. Intriguingly, despite their initial appearance as separate challenges with seemingly divergent approaches, both of these problems are interconnected components of a more comprehensive problem: "graph motif parameters". In this paper, we provide a precise characterization of the WL-dimension of labeled graph motif parameters. As specific instances of this result, we obtain characterizations of the WL-dimension of the subgraph counting and induced subgraph counting problem for every labeled pattern $P$. We additionally demonstrate that in cases where the $k$WL test distinguishes between graphs with varying occurrences of a pattern $P$, the exact number of occurrences of $P$ can be computed uniformly using only local information of the last layer of a corresponding GNN. We finally delve into the challenge of recognizing the WL-dimension of various graph parameters. We give a polynomial time algorithm for determining the WL-dimension of the subgraph counting problem for given pattern $P$, answering an open question from previous work.
Causality-informed Rapid Post-hurricane Building Damage Detection in Large Scale from InSAR Imagery
Oct 02, 2023Timely and accurate assessment of hurricane-induced building damage is crucial for effective post-hurricane response and recovery efforts. Recently, remote sensing technologies provide large-scale optical or Interferometric Synthetic Aperture Radar (InSAR) imagery data immediately after a disastrous event, which can be readily used to conduct rapid building damage assessment. Compared to optical satellite imageries, the Synthetic Aperture Radar can penetrate cloud cover and provide more complete spatial coverage of damaged zones in various weather conditions. However, these InSAR imageries often contain highly noisy and mixed signals induced by co-occurring or co-located building damage, flood, flood/wind-induced vegetation changes, as well as anthropogenic activities, making it challenging to extract accurate building damage information. In this paper, we introduced an approach for rapid post-hurricane building damage detection from InSAR imagery. This approach encoded complex causal dependencies among wind, flood, building damage, and InSAR imagery using a holistic causal Bayesian network. Based on the causal Bayesian network, we further jointly inferred the large-scale unobserved building damage by fusing the information from InSAR imagery with prior physical models of flood and wind, without the need for ground truth labels. Furthermore, we validated our estimation results in a real-world devastating hurricane -- the 2022 Hurricane Ian. We gathered and annotated building damage ground truth data in Lee County, Florida, and compared the introduced method's estimation results with the ground truth and benchmarked it against state-of-the-art models to assess the effectiveness of our proposed method. Results show that our method achieves rapid and accurate detection of building damage, with significantly reduced processing time compared to traditional manual inspection methods.