 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning in Computational Biology: Advancements, Challenges, and Future Outlook
Oct 02, 2023
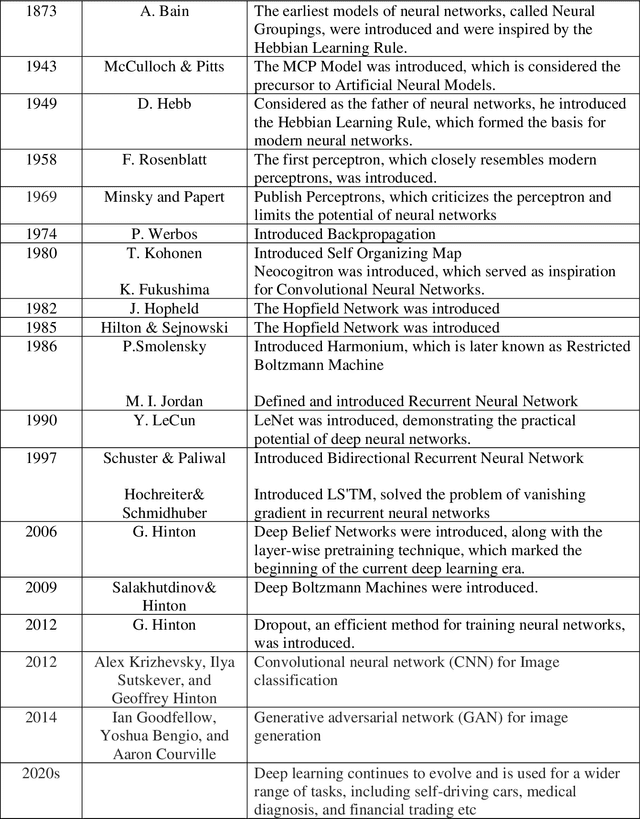
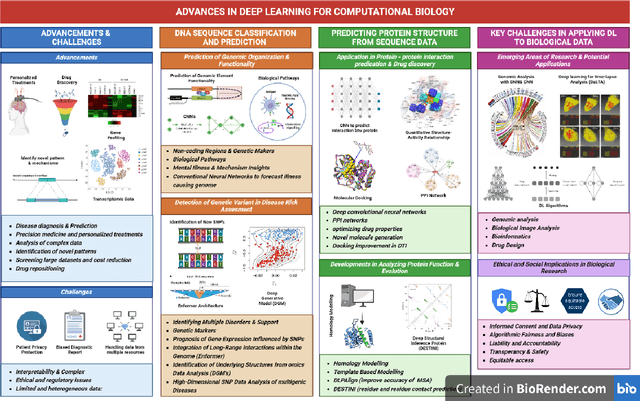
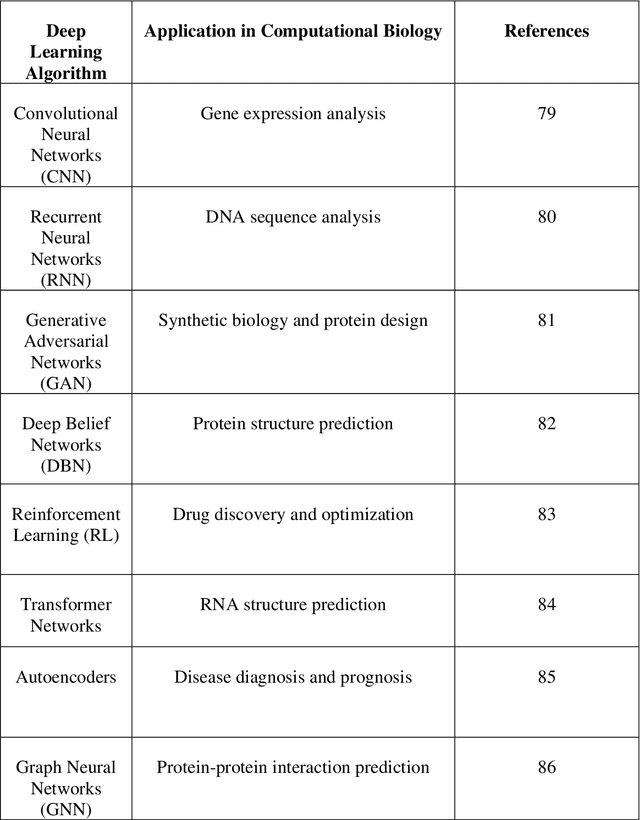
Deep learning has become a powerful tool in computational biology, revolutionising the analysis and interpretation of biological data over time. In our article review, we delve into various aspects of deep learning in computational biology. Specifically, we examine its history, advantages, and challenges. Our focus is on two primary applications: DNA sequence classification and prediction, as well as protein structure prediction from sequence data. Additionally, we provide insights into the outlook for this field. To fully harness the potential of deep learning in computational biology, it is crucial to address the challenges that come with it. These challenges include the requirement for large, labelled datasets and the interpretability of deep learning models. The use of deep learning in the analysis of DNA sequences has brought about a significant transformation in the detection of genomic variants and the analysis of gene expression. This has greatly contributed to the advancement of personalised medicine and drug discovery. Convolutional neural networks (CNNs) have been shown to be highly accurate in predicting genetic variations and gene expression levels. Deep learning techniques are used for analysing epigenetic data, including DNA methylation and histone modifications. This provides valuable insights into metabolic conditions and gene regulation. The field of protein structure prediction has been significantly impacted by deep learning, which has enabled accurate determination of the three-dimensional shape of proteins and prediction of their interactions. The future of deep learning in computational biology looks promising. With the development of advanced deep learning models and interpretation techniques, there is potential to overcome current challenges and further our understanding of biological systems.
LoCUS: Learning Multiscale 3D-consistent Features from Posed Images
Oct 02, 2023An important challenge for autonomous agents such as robots is to maintain a spatially and temporally consistent model of the world. It must be maintained through occlusions, previously-unseen views, and long time horizons (e.g., loop closure and re-identification). It is still an open question how to train such a versatile neural representation without supervision. We start from the idea that the training objective can be framed as a patch retrieval problem: given an image patch in one view of a scene, we would like to retrieve (with high precision and recall) all patches in other views that map to the same real-world location. One drawback is that this objective does not promote reusability of features: by being unique to a scene (achieving perfect precision/recall), a representation will not be useful in the context of other scenes. We find that it is possible to balance retrieval and reusability by constructing the retrieval set carefully, leaving out patches that map to far-away locations. Similarly, we can easily regulate the scale of the learned features (e.g., points, objects, or rooms) by adjusting the spatial tolerance for considering a retrieval to be positive. We optimize for (smooth) Average Precision (AP), in a single unified ranking-based objective. This objective also doubles as a criterion for choosing landmarks or keypoints, as patches with high AP. We show results creating sparse, multi-scale, semantic spatial maps composed of highly identifiable landmarks, with applications in landmark retrieval, localization, semantic segmentation and instance segmentation.
Faster and Accurate Neural Networks with Semantic Inference
Oct 03, 2023Deep neural networks (DNN) usually come with a significant computational burden. While approaches such as structured pruning and mobile-specific DNNs have been proposed, they incur drastic accuracy loss. In this paper we leverage the intrinsic redundancy in latent representations to reduce the computational load with limited loss in performance. We show that semantically similar inputs share many filters, especially in the earlier layers. Thus, semantically similar classes can be clustered to create cluster-specific subgraphs. To this end, we propose a new framework called Semantic Inference (SINF). In short, SINF (i) identifies the semantic cluster the object belongs to using a small additional classifier and (ii) executes the subgraph extracted from the base DNN related to that semantic cluster for inference. To extract each cluster-specific subgraph, we propose a new approach named Discriminative Capability Score (DCS) that finds the subgraph with the capability to discriminate among the members of a specific semantic cluster. DCS is independent from SINF and can be applied to any DNN. We benchmark the performance of DCS on the VGG16, VGG19, and ResNet50 DNNs trained on the CIFAR100 dataset against 6 state-of-the-art pruning approaches. Our results show that (i) SINF reduces the inference time of VGG19, VGG16, and ResNet50 respectively by up to 35%, 29% and 15% with only 0.17%, 3.75%, and 6.75% accuracy loss (ii) DCS achieves respectively up to 3.65%, 4.25%, and 2.36% better accuracy with VGG16, VGG19, and ResNet50 with respect to existing discriminative scores (iii) when used as a pruning criterion, DCS achieves up to 8.13% accuracy gain with 5.82% less parameters than the existing state of the art work published at ICLR 2023 (iv) when considering per-cluster accuracy, SINF performs on average 5.73%, 8.38% and 6.36% better than the base VGG16, VGG19, and ResNet50.
Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval
Sep 20, 2023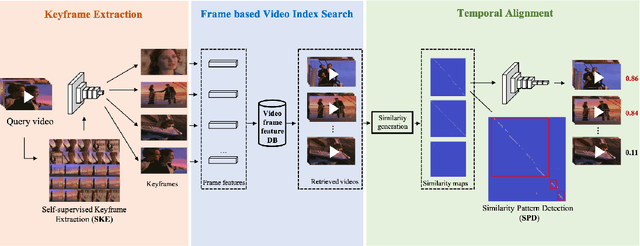
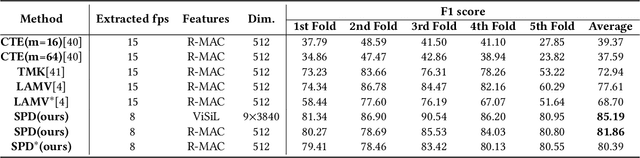
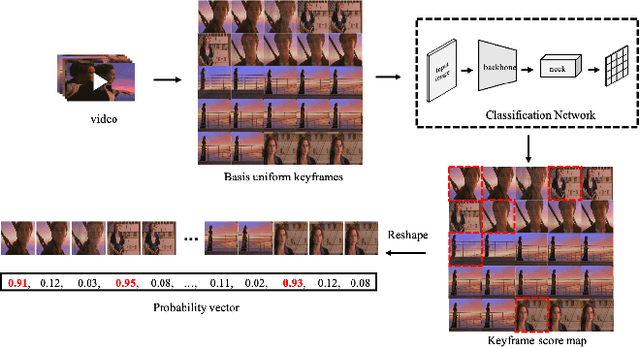
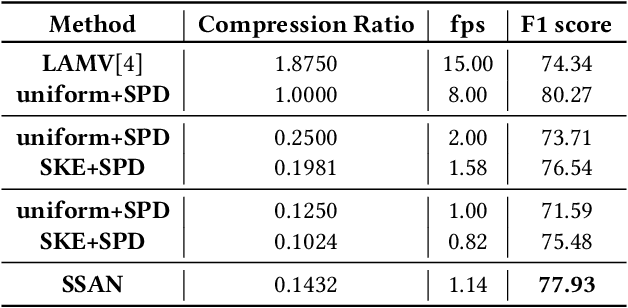
With the explosive growth of web videos in recent years, large-scale Content-Based Video Retrieval (CBVR) becomes increasingly essential in video filtering, recommendation, and copyright protection. Segment-level CBVR (S-CBVR) locates the start and end time of similar segments in finer granularity, which is beneficial for user browsing efficiency and infringement detection especially in long video scenarios. The challenge of S-CBVR task is how to achieve high temporal alignment accuracy with efficient computation and low storage consumption. In this paper, we propose a Segment Similarity and Alignment Network (SSAN) in dealing with the challenge which is firstly trained end-to-end in S-CBVR. SSAN is based on two newly proposed modules in video retrieval: (1) An efficient Self-supervised Keyframe Extraction (SKE) module to reduce redundant frame features, (2) A robust Similarity Pattern Detection (SPD) module for temporal alignment. In comparison with uniform frame extraction, SKE not only saves feature storage and search time, but also introduces comparable accuracy and limited extra computation time. In terms of temporal alignment, SPD localizes similar segments with higher accuracy and efficiency than existing deep learning methods. Furthermore, we jointly train SSAN with SKE and SPD and achieve an end-to-end improvement. Meanwhile, the two key modules SKE and SPD can also be effectively inserted into other video retrieval pipelines and gain considerable performance improvements. Experimental results on public datasets show that SSAN can obtain higher alignment accuracy while saving storage and online query computational cost compared to existing methods.
DynaCon: Dynamic Robot Planner with Contextual Awareness via LLMs
Sep 27, 2023Mobile robots often rely on pre-existing maps for effective path planning and navigation. However, when these maps are unavailable, particularly in unfamiliar environments, a different approach become essential. This paper introduces DynaCon, a novel system designed to provide mobile robots with contextual awareness and dynamic adaptability during navigation, eliminating the reliance of traditional maps. DynaCon integrates real-time feedback with an object server, prompt engineering, and navigation modules. By harnessing the capabilities of Large Language Models (LLMs), DynaCon not only understands patterns within given numeric series but also excels at categorizing objects into matched spaces. This facilitates dynamic path planner imbued with contextual awareness. We validated the effectiveness of DynaCon through an experiment where a robot successfully navigated to its goal using reasoning. Source code and experiment videos for this work can be found at: https://sites.google.com/view/dynacon.
DreamCom: Finetuning Text-guided Inpainting Model for Image Composition
Sep 27, 2023The goal of image composition is merging a foreground object into a background image to obtain a realistic composite image. Recently, generative composition methods are built on large pretrained diffusion models, due to their unprecedented image generation ability. They train a model on abundant pairs of foregrounds and backgrounds, so that it can be directly applied to a new pair of foreground and background at test time. However, the generated results often lose the foreground details and exhibit noticeable artifacts. In this work, we propose an embarrassingly simple approach named DreamCom inspired by DreamBooth. Specifically, given a few reference images for a subject, we finetune text-guided inpainting diffusion model to associate this subject with a special token and inpaint this subject in the specified bounding box. We also construct a new dataset named MureCom well-tailored for this task.
CoMFLP: Correlation Measure based Fast Search on ASR Layer Pruning
Sep 21, 2023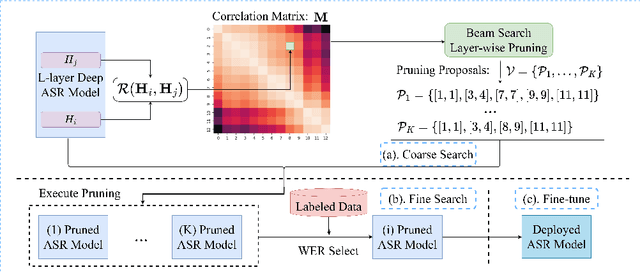
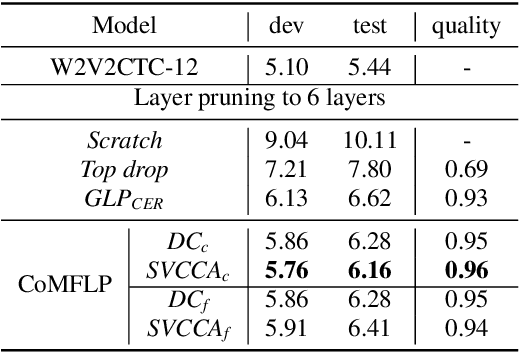
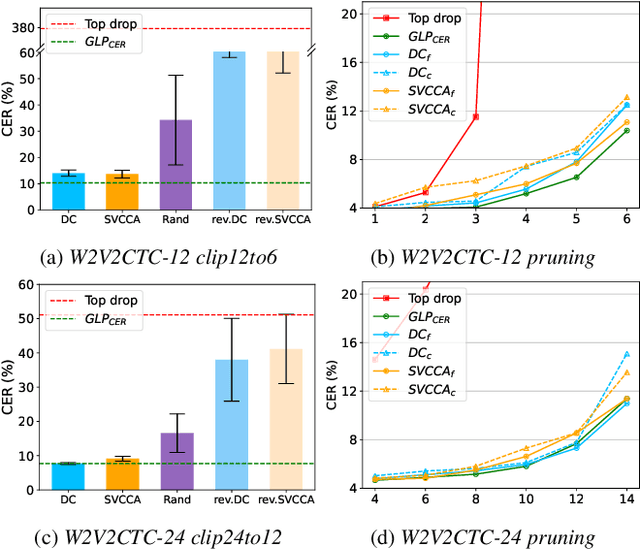
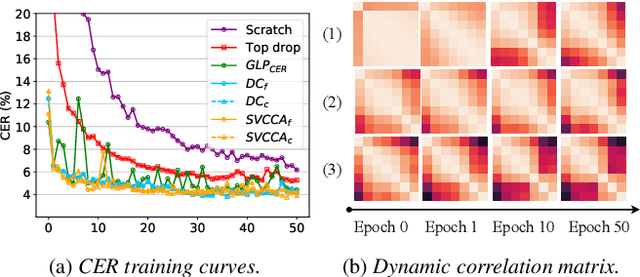
Transformer-based speech recognition (ASR) model with deep layers exhibited significant performance improvement. However, the model is inefficient for deployment on resource-constrained devices. Layer pruning (LP) is a commonly used compression method to remove redundant layers. Previous studies on LP usually identify the redundant layers according to a task-specific evaluation metric. They are time-consuming for models with a large number of layers, even in a greedy search manner. To address this problem, we propose CoMFLP, a fast search LP algorithm based on correlation measure. The correlation between layers is computed to generate a correlation matrix, which identifies the redundancy among layers. The search process is carried out in two steps: (1) coarse search: to determine top $K$ candidates by pruning the most redundant layers based on the correlation matrix; (2) fine search: to select the best pruning proposal among $K$ candidates using a task-specific evaluation metric. Experiments on an ASR task show that the pruning proposal determined by CoMFLP outperforms existing LP methods while only requiring constant time complexity. The code is publicly available at https://github.com/louislau1129/CoMFLP.
Efficient Long-Short Temporal Attention Network for Unsupervised Video Object Segmentation
Sep 21, 2023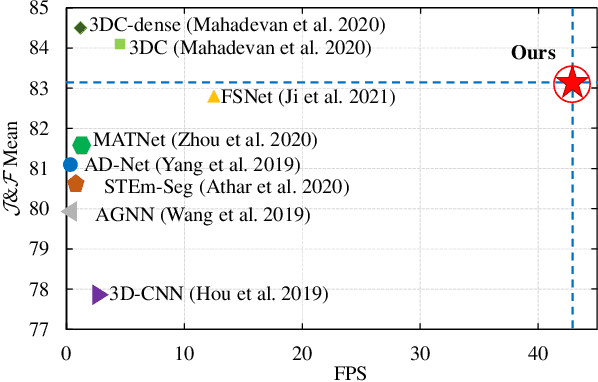
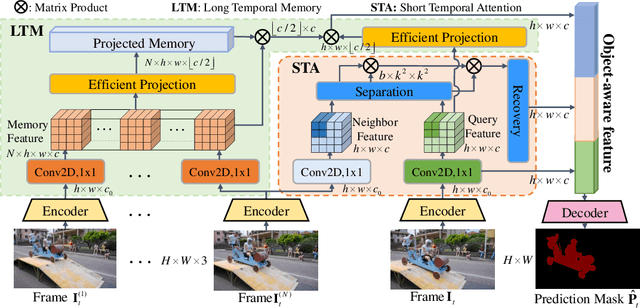
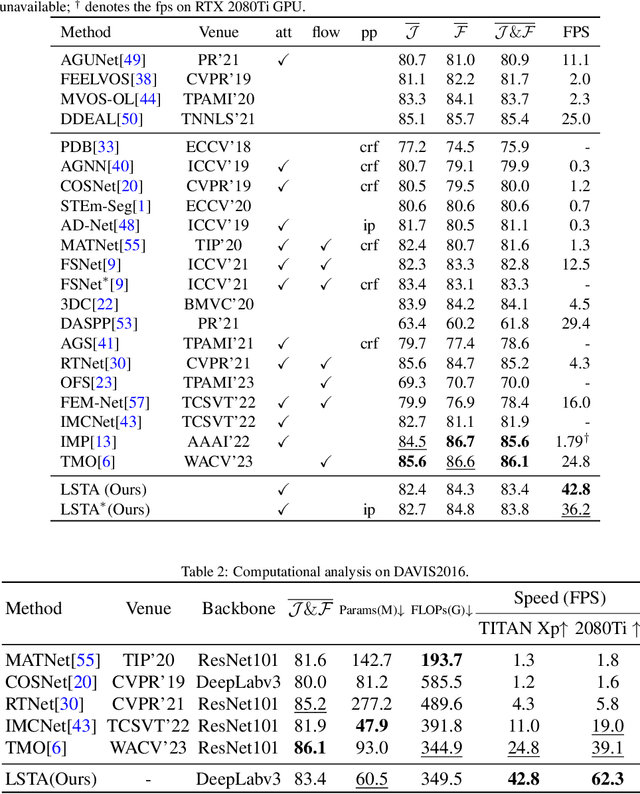
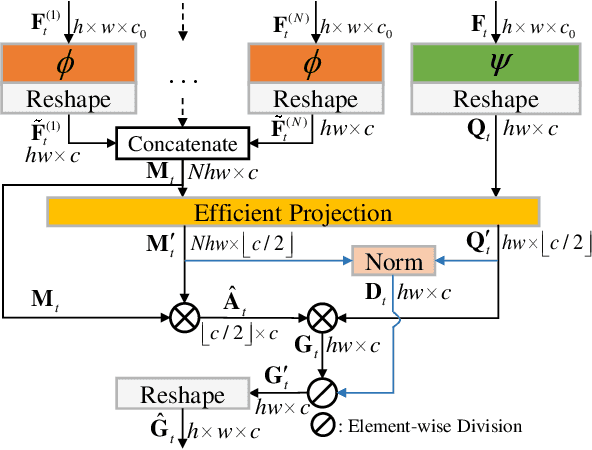
Unsupervised Video Object Segmentation (VOS) aims at identifying the contours of primary foreground objects in videos without any prior knowledge. However, previous methods do not fully use spatial-temporal context and fail to tackle this challenging task in real-time. This motivates us to develop an efficient Long-Short Temporal Attention network (termed LSTA) for unsupervised VOS task from a holistic view. Specifically, LSTA consists of two dominant modules, i.e., Long Temporal Memory and Short Temporal Attention. The former captures the long-term global pixel relations of the past frames and the current frame, which models constantly present objects by encoding appearance pattern. Meanwhile, the latter reveals the short-term local pixel relations of one nearby frame and the current frame, which models moving objects by encoding motion pattern. To speedup the inference, the efficient projection and the locality-based sliding window are adopted to achieve nearly linear time complexity for the two light modules, respectively. Extensive empirical studies on several benchmarks have demonstrated promising performances of the proposed method with high efficiency.
Causal Discovery and Prediction: Methods and Algorithms
Sep 18, 2023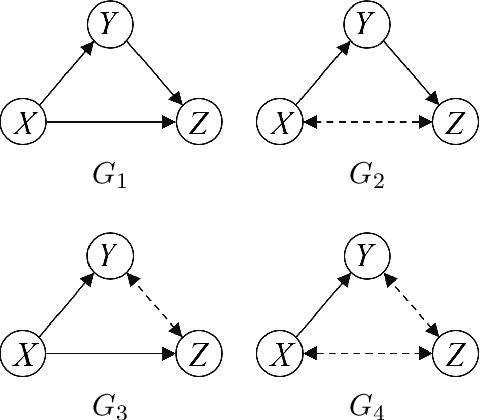
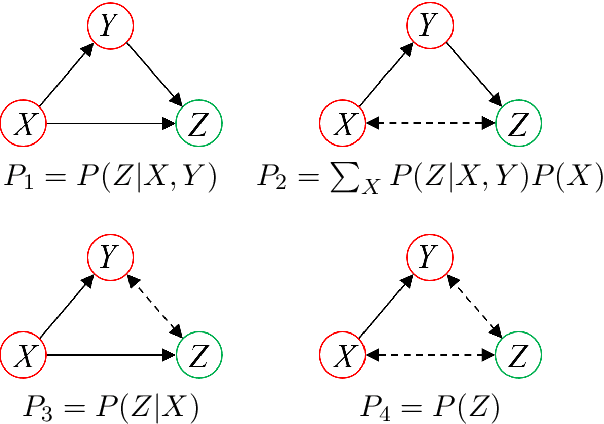
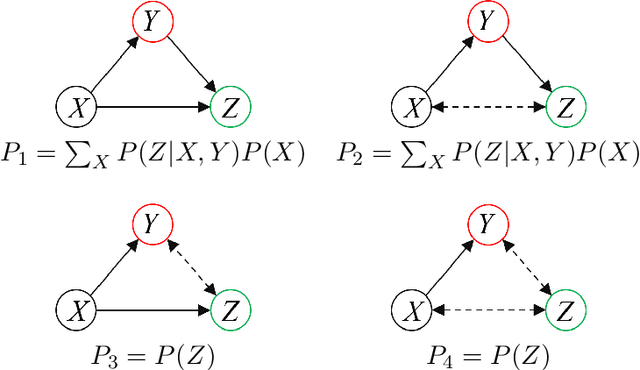
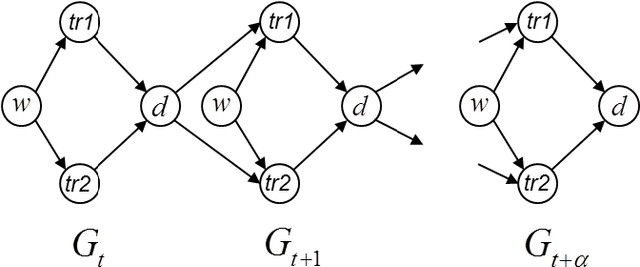
We are not only observers but also actors of reality. Our capability to intervene and alter the course of some events in the space and time surrounding us is an essential component of how we build our model of the world. In this doctoral thesis we introduce a generic a-priori assessment of each possible intervention, in order to select the most cost-effective interventions only, and avoid unnecessary systematic experimentation on the real world. Based on this a-priori assessment, we propose an active learning algorithm that identifies the causal relations in any given causal model, using a least cost sequence of interventions. There are several novel aspects introduced by our algorithm. It is, in most case scenarios, able to discard many causal model candidates using relatively inexpensive interventions that only test one value of the intervened variables. Also, the number of interventions performed by the algorithm can be bounded by the number of causal model candidates. Hence, fewer initial candidates (or equivalently, more prior knowledge) lead to fewer interventions for causal discovery. Causality is intimately related to time, as causes appear to precede their effects. Cyclical causal processes are a very interesting case of causality in relation to time. In this doctoral thesis we introduce a formal analysis of time cyclical causal settings by defining a causal analog to the purely observational Dynamic Bayesian Networks, and provide a sound and complete algorithm for the identification of causal effects in the cyclic setting. We introduce the existence of two types of hidden confounder variables in this framework, which affect in substantially different ways the identification procedures, a distinction with no analog in either Dynamic Bayesian Networks or standard causal graphs.
Virtual Reality as a Tool for Studying Diversity and Inclusion in Human-Robot Interaction: Advantages and Challenges
Sep 26, 2023This paper investigates the potential of Virtual Reality (VR) as a research tool for studying diversity and inclusion characteristics in the context of human-robot interactions (HRI). Some exclusive advantages of using VR in HRI are discussed, such as a controllable environment, the possibility to manipulate the variables related to the robot and the human-robot interaction, flexibility in the design of the robot and the environment, and advanced measurement methods related e.g. to eye tracking and physiological data. At the same time, the challenges of researching diversity and inclusion in HRI are described, especially in accessibility, cyber sickness and bias when developing VR-environments. Furthermore, solutions to these challenges are being discussed to fully harness the benefits of VR for the studying of diversity and inclusion.