 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Variance-Aware Regret Bounds for Stochastic Contextual Dueling Bandits
Oct 02, 2023
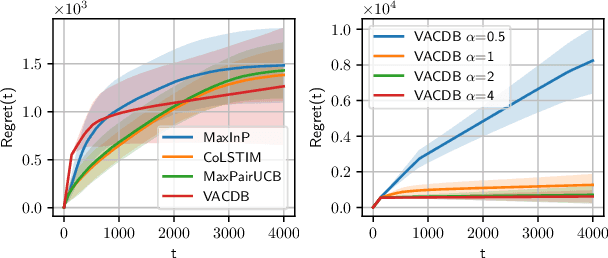
Dueling bandits is a prominent framework for decision-making involving preferential feedback, a valuable feature that fits various applications involving human interaction, such as ranking, information retrieval, and recommendation systems. While substantial efforts have been made to minimize the cumulative regret in dueling bandits, a notable gap in the current research is the absence of regret bounds that account for the inherent uncertainty in pairwise comparisons between the dueling arms. Intuitively, greater uncertainty suggests a higher level of difficulty in the problem. To bridge this gap, this paper studies the problem of contextual dueling bandits, where the binary comparison of dueling arms is generated from a generalized linear model (GLM). We propose a new SupLinUCB-type algorithm that enjoys computational efficiency and a variance-aware regret bound $\tilde O\big(d\sqrt{\sum_{t=1}^T\sigma_t^2} + d\big)$, where $\sigma_t$ is the variance of the pairwise comparison in round $t$, $d$ is the dimension of the context vectors, and $T$ is the time horizon. Our regret bound naturally aligns with the intuitive expectation in scenarios where the comparison is deterministic, the algorithm only suffers from an $\tilde O(d)$ regret. We perform empirical experiments on synthetic data to confirm the advantage of our method over previous variance-agnostic algorithms.
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Oct 02, 2023Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
CODA: Temporal Domain Generalization via Concept Drift Simulator
Oct 02, 2023In real-world applications, machine learning models often become obsolete due to shifts in the joint distribution arising from underlying temporal trends, a phenomenon known as the "concept drift". Existing works propose model-specific strategies to achieve temporal generalization in the near-future domain. However, the diverse characteristics of real-world datasets necessitate customized prediction model architectures. To this end, there is an urgent demand for a model-agnostic temporal domain generalization approach that maintains generality across diverse data modalities and architectures. In this work, we aim to address the concept drift problem from a data-centric perspective to bypass considering the interaction between data and model. Developing such a framework presents non-trivial challenges: (i) existing generative models struggle to generate out-of-distribution future data, and (ii) precisely capturing the temporal trends of joint distribution along chronological source domains is computationally infeasible. To tackle the challenges, we propose the COncept Drift simulAtor (CODA) framework incorporating a predicted feature correlation matrix to simulate future data for model training. Specifically, CODA leverages feature correlations to represent data characteristics at specific time points, thereby circumventing the daunting computational costs. Experimental results demonstrate that using CODA-generated data as training input effectively achieves temporal domain generalization across different model architectures.
Unsupervised motion segmentation in one go: Smooth long-term model over a video
Oct 02, 2023Human beings have the ability to continuously analyze a video and immediately extract the main motion components. Motion segmentation methods often proceed frame by frame. We want to go beyond this classical paradigm, and perform the motion segmentation over a video sequence in one go. It will be a prominent added value for downstream computer vision tasks, and could provide a pretext criterion for unsupervised video representation learning. In this perspective, we propose a novel long-term spatio-temporal model operating in a totally unsupervised way. It takes as input the volume of consecutive optical flow (OF) fields, and delivers a volume of segments of coherent motion over the video. More specifically, we have designed a transformer-based network, where we leverage a mathematically well-founded framework, the Evidence Lower Bound (ELBO), to infer the loss function. The loss function combines a flow reconstruction term involving spatio-temporal parametric motion models combining, in a novel way, polynomial (quadratic) motion models for the $(x,y)$-spatial dimensions and B-splines for the time dimension of the video sequence, and a regularization term enforcing temporal consistency on the masks. We report experiments on four VOS benchmarks with convincing quantitative results. We also highlight through visual results the key contributions on temporal consistency brought by our method.
All by Myself: Learning Individualized Competitive Behaviour with a Contrastive Reinforcement Learning optimization
Oct 02, 2023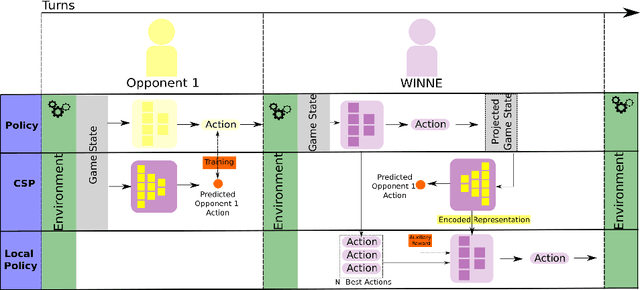
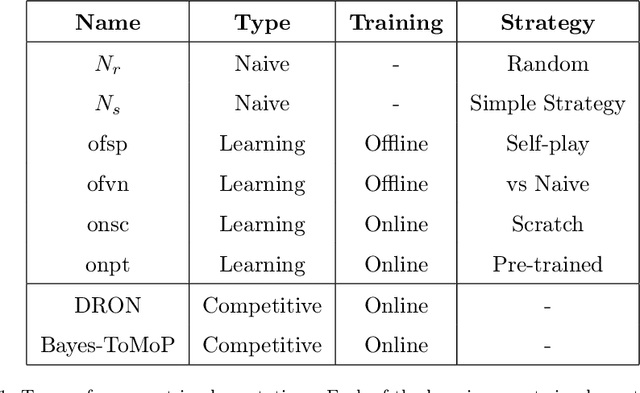
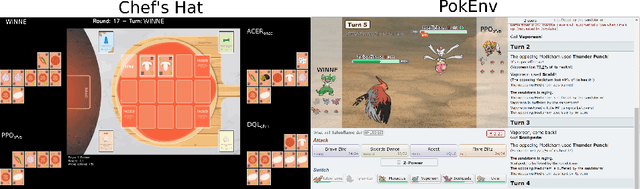
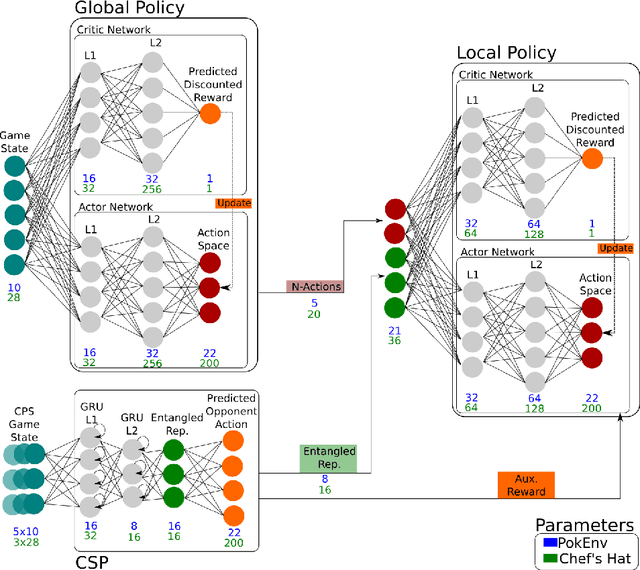
In a competitive game scenario, a set of agents have to learn decisions that maximize their goals and minimize their adversaries' goals at the same time. Besides dealing with the increased dynamics of the scenarios due to the opponents' actions, they usually have to understand how to overcome the opponent's strategies. Most of the common solutions, usually based on continual learning or centralized multi-agent experiences, however, do not allow the development of personalized strategies to face individual opponents. In this paper, we propose a novel model composed of three neural layers that learn a representation of a competitive game, learn how to map the strategy of specific opponents, and how to disrupt them. The entire model is trained online, using a composed loss based on a contrastive optimization, to learn competitive and multiplayer games. We evaluate our model on a pokemon duel scenario and the four-player competitive Chef's Hat card game. Our experiments demonstrate that our model achieves better performance when playing against offline, online, and competitive-specific models, in particular when playing against the same opponent multiple times. We also present a discussion on the impact of our model, in particular on how well it deals with on specific strategy learning for each of the two scenarios.
Drifter: Efficient Online Feature Monitoring for Improved Data Integrity in Large-Scale Recommendation Systems
Sep 21, 2023
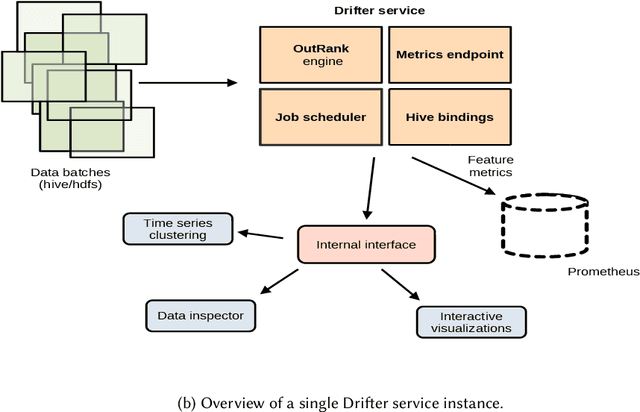
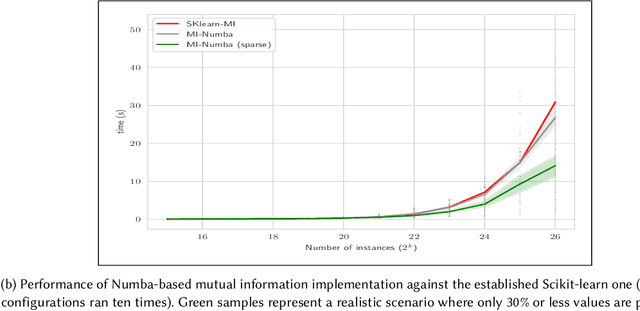
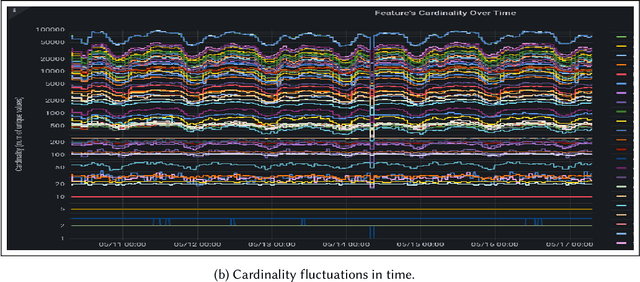
Real-world production systems often grapple with maintaining data quality in large-scale, dynamic streams. We introduce Drifter, an efficient and lightweight system for online feature monitoring and verification in recommendation use cases. Drifter addresses limitations of existing methods by delivering agile, responsive, and adaptable data quality monitoring, enabling real-time root cause analysis, drift detection and insights into problematic production events. Integrating state-of-the-art online feature ranking for sparse data and anomaly detection ideas, Drifter is highly scalable and resource-efficient, requiring only two threads and less than a gigabyte of RAM per production deployments that handle millions of instances per minute. Evaluation on real-world data sets demonstrates Drifter's effectiveness in alerting and mitigating data quality issues, substantially improving reliability and performance of real-time live recommender systems.
Generalized Time Warping Invariant Dictionary Learning for Time Series Classification and Clustering
Jun 30, 2023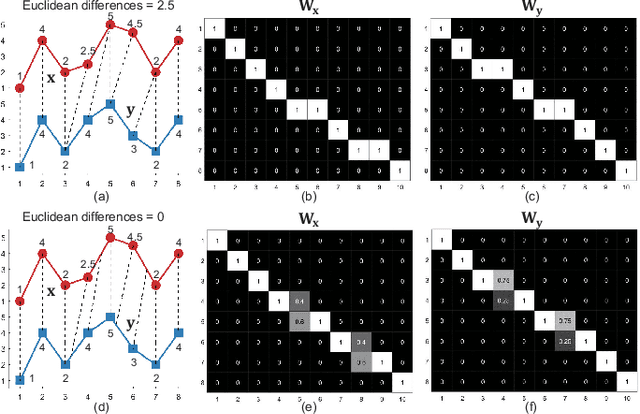
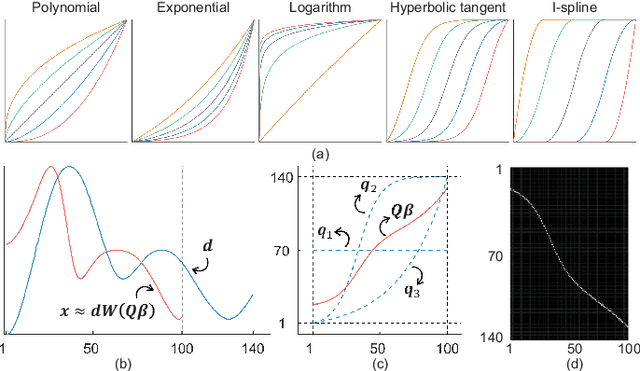
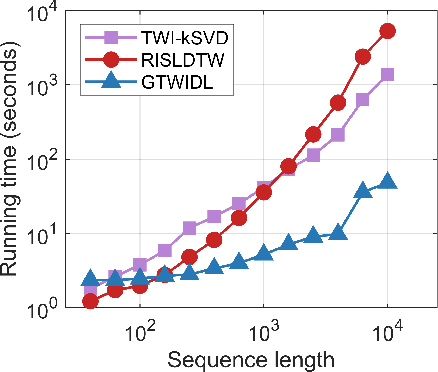
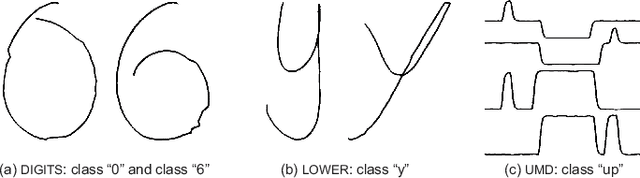
Dictionary learning is an effective tool for pattern recognition and classification of time series data. Among various dictionary learning techniques, the dynamic time warping (DTW) is commonly used for dealing with temporal delays, scaling, transformation, and many other kinds of temporal misalignments issues. However, the DTW suffers overfitting or information loss due to its discrete nature in aligning time series data. To address this issue, we propose a generalized time warping invariant dictionary learning algorithm in this paper. Our approach features a generalized time warping operator, which consists of linear combinations of continuous basis functions for facilitating continuous temporal warping. The integration of the proposed operator and the dictionary learning is formulated as an optimization problem, where the block coordinate descent method is employed to jointly optimize warping paths, dictionaries, and sparseness coefficients. The optimized results are then used as hyperspace distance measures to feed classification and clustering algorithms. The superiority of the proposed method in terms of dictionary learning, classification, and clustering is validated through ten sets of public datasets in comparing with various benchmark methods.
Event Blob Tracking: An Asynchronous Real-Time Algorithm
Jul 20, 2023
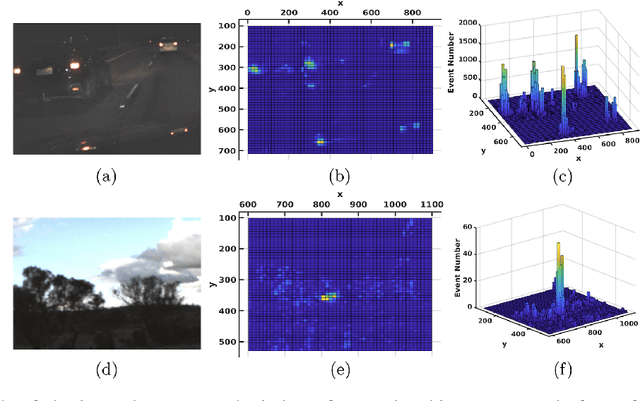
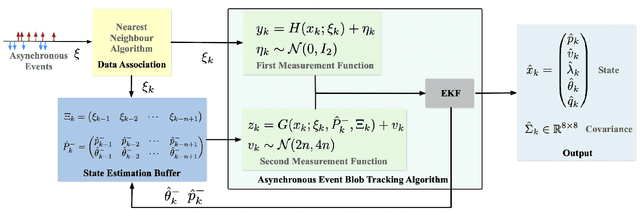
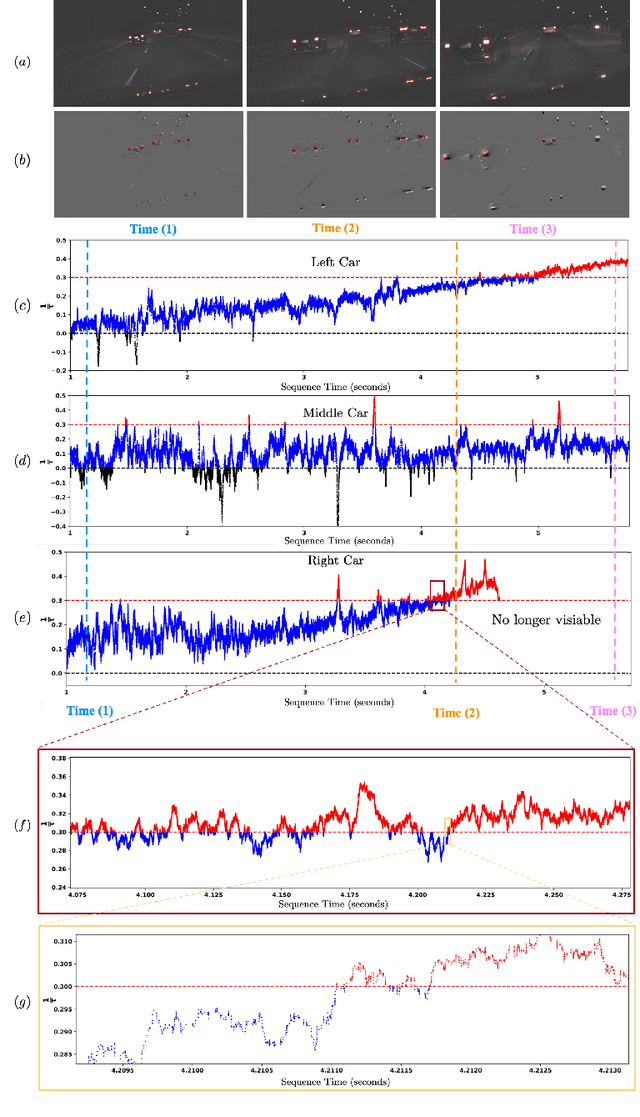
Event-based cameras have become increasingly popular for tracking fast-moving objects due to their high temporal resolution, low latency, and high dynamic range. In this paper, we propose a novel algorithm for tracking event blobs using raw events asynchronously in real time. We introduce the concept of an event blob as a spatio-temporal likelihood of event occurrence where the conditional spatial likelihood is blob-like. Many real-world objects generate event blob data, for example, flickering LEDs such as car headlights or any small foreground object moving against a static or slowly varying background. The proposed algorithm uses a nearest neighbour classifier with a dynamic threshold criteria for data association coupled with a Kalman filter to track the event blob state. Our algorithm achieves highly accurate tracking and event blob shape estimation even under challenging lighting conditions and high-speed motions. The microsecond time resolution achieved means that the filter output can be used to derive secondary information such as time-to-contact or range estimation, that will enable applications to real-world problems such as collision avoidance in autonomous driving.
CenTime: Event-Conditional Modelling of Censoring in Survival Analysis
Sep 15, 2023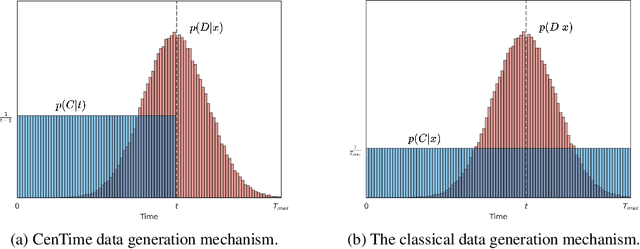
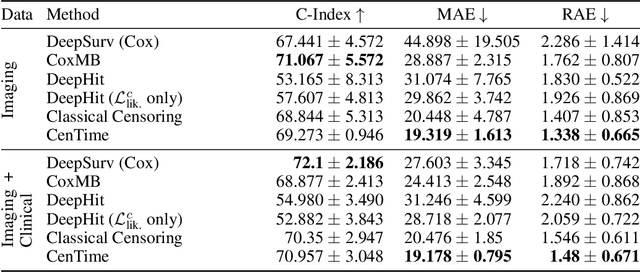
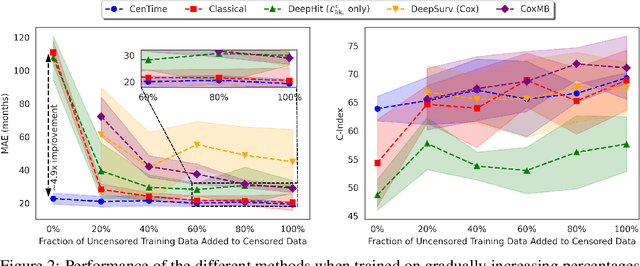
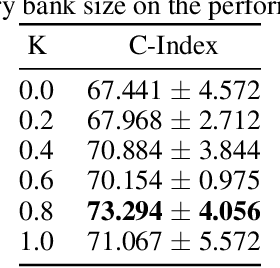
Survival analysis is a valuable tool for estimating the time until specific events, such as death or cancer recurrence, based on baseline observations. This is particularly useful in healthcare to prognostically predict clinically important events based on patient data. However, existing approaches often have limitations; some focus only on ranking patients by survivability, neglecting to estimate the actual event time, while others treat the problem as a classification task, ignoring the inherent time-ordered structure of the events. Furthermore, the effective utilization of censored samples - training data points where the exact event time is unknown - is essential for improving the predictive accuracy of the model. In this paper, we introduce CenTime, a novel approach to survival analysis that directly estimates the time to event. Our method features an innovative event-conditional censoring mechanism that performs robustly even when uncensored data is scarce. We demonstrate that our approach forms a consistent estimator for the event model parameters, even in the absence of uncensored data. Furthermore, CenTime is easily integrated with deep learning models with no restrictions on batch size or the number of uncensored samples. We compare our approach with standard survival analysis methods, including the Cox proportional-hazard model and DeepHit. Our results indicate that CenTime offers state-of-the-art performance in predicting time-to-death while maintaining comparable ranking performance. Our implementation is publicly available at https://github.com/ahmedhshahin/CenTime.
ProtoNER: Few shot Incremental Learning for Named Entity Recognition using Prototypical Networks
Oct 03, 2023

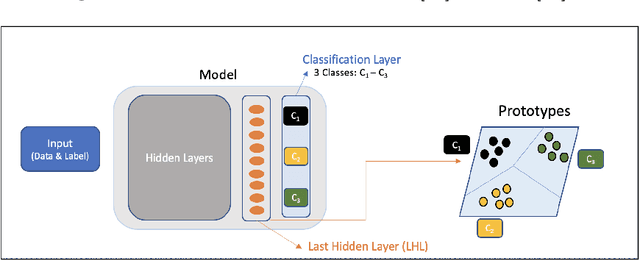
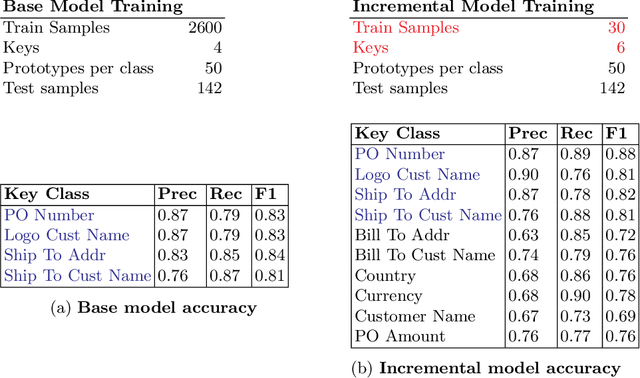
Key value pair (KVP) extraction or Named Entity Recognition(NER) from visually rich documents has been an active area of research in document understanding and data extraction domain. Several transformer based models such as LayoutLMv2, LayoutLMv3, and LiLT have emerged achieving state of the art results. However, addition of even a single new class to the existing model requires (a) re-annotation of entire training dataset to include this new class and (b) retraining the model again. Both of these issues really slow down the deployment of updated model. \\ We present \textbf{ProtoNER}: Prototypical Network based end-to-end KVP extraction model that allows addition of new classes to an existing model while requiring minimal number of newly annotated training samples. The key contributions of our model are: (1) No dependency on dataset used for initial training of the model, which alleviates the need to retain original training dataset for longer duration as well as data re-annotation which is very time consuming task, (2) No intermediate synthetic data generation which tends to add noise and results in model's performance degradation, and (3) Hybrid loss function which allows model to retain knowledge about older classes as well as learn about newly added classes.\\ Experimental results show that ProtoNER finetuned with just 30 samples is able to achieve similar results for the newly added classes as that of regular model finetuned with 2600 samples.