 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Establishing a real-time traffic alarm in the city of Valencia with Deep Learning
Sep 05, 2023
Urban traffic emissions represent a significant concern due to their detrimental impacts on both public health and the environment. Consequently, decision-makers have flagged their reduction as a crucial goal. In this study, we first analyze the correlation between traffic flux and pollution in the city of Valencia, Spain. Our results demonstrate that traffic has a significant impact on the levels of certain pollutants (especially $\text{NO}_\text{x}$). Secondly, we develop an alarm system to predict if a street is likely to experience unusually high traffic in the next 30 minutes, using an independent three-tier level for each street. To make the predictions, we use traffic data updated every 10 minutes and Long Short-Term Memory (LSTM) neural networks. We trained the LSTM using traffic data from 2018, and tested it using traffic data from 2019.
Semi-Autoregressive Streaming ASR With Label Context
Sep 19, 2023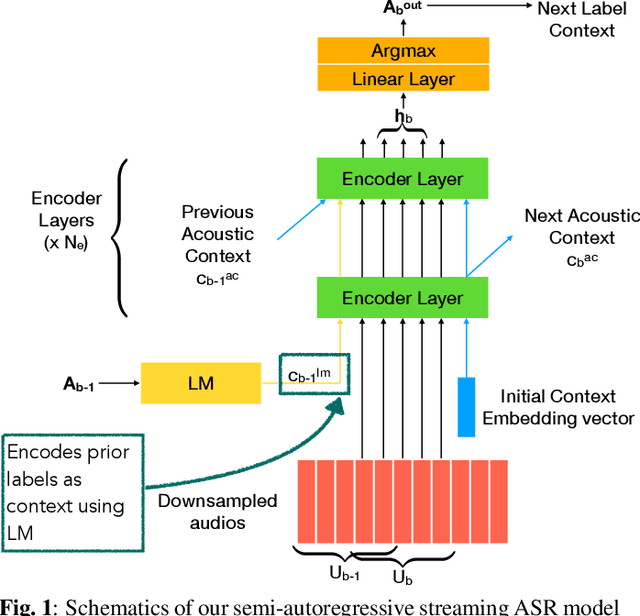
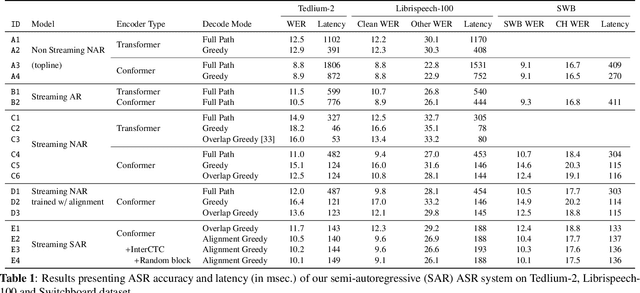

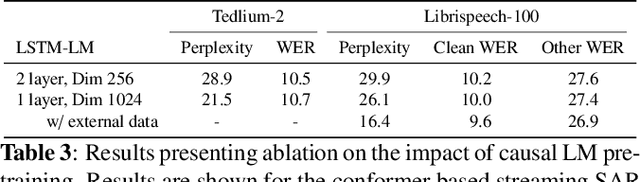
Non-autoregressive (NAR) modeling has gained significant interest in speech processing since these models achieve dramatically lower inference time than autoregressive (AR) models while also achieving good transcription accuracy. Since NAR automatic speech recognition (ASR) models must wait for the completion of the entire utterance before processing, some works explore streaming NAR models based on blockwise attention for low-latency applications. However, streaming NAR models significantly lag in accuracy compared to streaming AR and non-streaming NAR models. To address this, we propose a streaming "semi-autoregressive" ASR model that incorporates the labels emitted in previous blocks as additional context using a Language Model (LM) subnetwork. We also introduce a novel greedy decoding algorithm that addresses insertion and deletion errors near block boundaries while not significantly increasing the inference time. Experiments show that our method outperforms the existing streaming NAR model by 19% relative on Tedlium2, 16%/8% on Librispeech-100 clean/other test sets, and 19%/8% on the Switchboard(SWB) / Callhome(CH) test sets. It also reduced the accuracy gap with streaming AR and non-streaming NAR models while achieving 2.5x lower latency. We also demonstrate that our approach can effectively utilize external text data to pre-train the LM subnetwork to further improve streaming ASR accuracy.
Deep Learning based Fast and Accurate Beamforming for Millimeter-Wave Systems
Sep 19, 2023The widespread proliferation of mmW devices has led to a surge of interest in antenna arrays. This interest in arrays is due to their ability to steer beams in desired directions, for the purpose of increasing signal-power and/or decreasing interference levels. To enable beamforming, array coefficients are typically stored in look-up tables (LUTs) for subsequent referencing. While LUTs enable fast sweep times, their limited memory size restricts the number of beams the array can produce. Consequently, a receiver is likely to be offset from the main beam, thus decreasing received power, and resulting in sub-optimal performance. In this letter, we present BeamShaper, a deep neural network (DNN) framework, which enables fast and accurate beamsteering in any desirable 3-D direction. Unlike traditional finite-memory LUTs which support a fixed set of beams, BeamShaper utilizes a trained NN model to generate the array coefficients for arbitrary directions in \textit{real-time}. Our simulations show that BeamShaper outperforms contemporary LUT based solutions in terms of cosine-similarity and central angle in time scales that are slightly higher than LUT based solutions. Additionally, we show that our DNN based approach has the added advantage of being more resilient to the effects of quantization noise generated while using digital phase-shifters.
Heuristic Search for Path Finding with Refuelling
Sep 19, 2023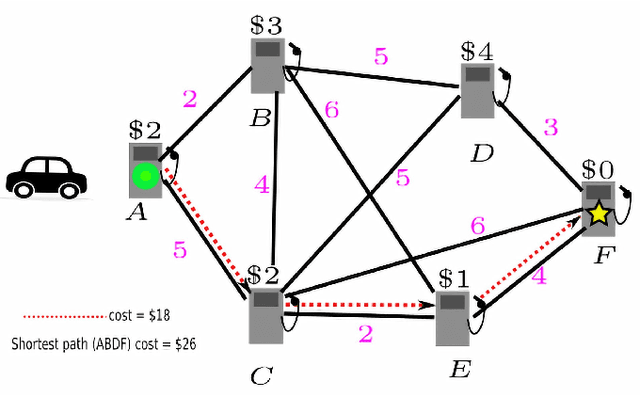
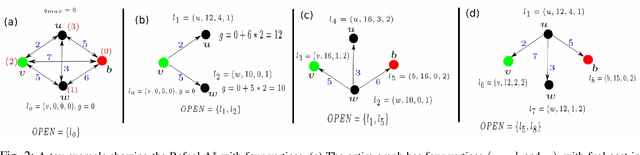
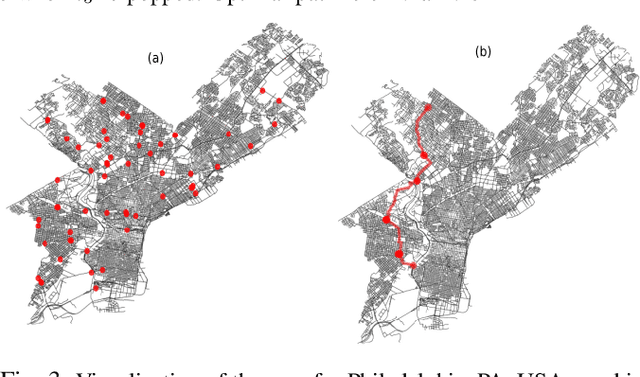
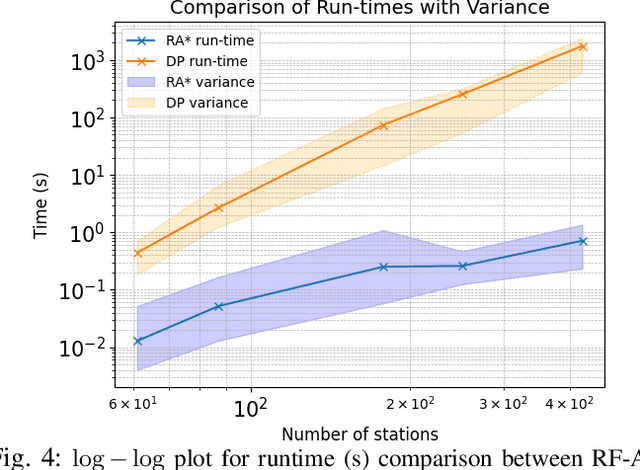
This paper considers a generalization of the Path Finding (PF) with refueling constraints referred to as the Refuelling Path Finding (RF-PF) problem. Just like PF, the RF-PF problem is defined over a graph, where vertices are gas stations with known fuel prices, and edge costs depend on the gas consumption between the corresponding vertices. RF-PF seeks a minimum-cost path from the start to the goal vertex for a robot with a limited gas tank and a limited number of refuelling stops. While RF-PF is polynomial-time solvable, it remains a challenge to quickly compute an optimal solution in practice since the robot needs to simultaneously determine the path, where to make the stops, and the amount to refuel at each stop. This paper develops a heuristic search algorithm called Refuel A* (RF-A* ) that iteratively constructs partial solution paths from the start to the goal guided by a heuristic function while leveraging dominance rules for state pruning during planning. RF-A* is guaranteed to find an optimal solution and runs more than an order of magnitude faster than the existing state of the art (a polynomial time algorithm) when tested in large city maps with hundreds of gas stations.
ChatGPT-4 with Code Interpreter can be used to solve introductory college-level vector calculus and electromagnetism problems
Sep 16, 2023We evaluated ChatGPT 3.5, 4, and 4 with Code Interpreter on a set of college-level engineering-math and electromagnetism problems, such as those often given to sophomore electrical engineering majors. We selected a set of 13 problems, and had ChatGPT solve them multiple times, using a fresh instance (chat) each time. We found that ChatGPT-4 with Code Interpreter was able to satisfactorily solve most problems we tested most of the time -- a major improvement over the performance of ChatGPT-4 (or 3.5) without Code Interpreter. The performance of ChatGPT was observed to be somewhat stochastic, and we found that solving the same problem N times in new ChatGPT instances and taking the most-common answer was an effective strategy. Based on our findings and observations, we provide some recommendations for instructors and students of classes at this level.
mdendro: An R package for extended agglomerative hierarchical clustering
Sep 23, 2023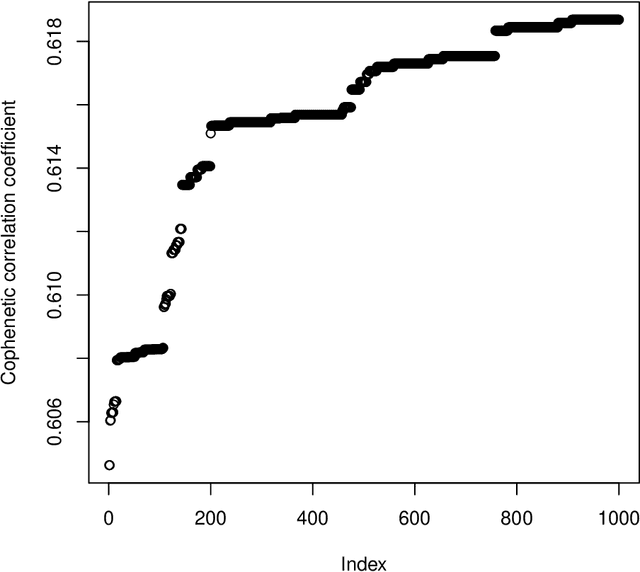

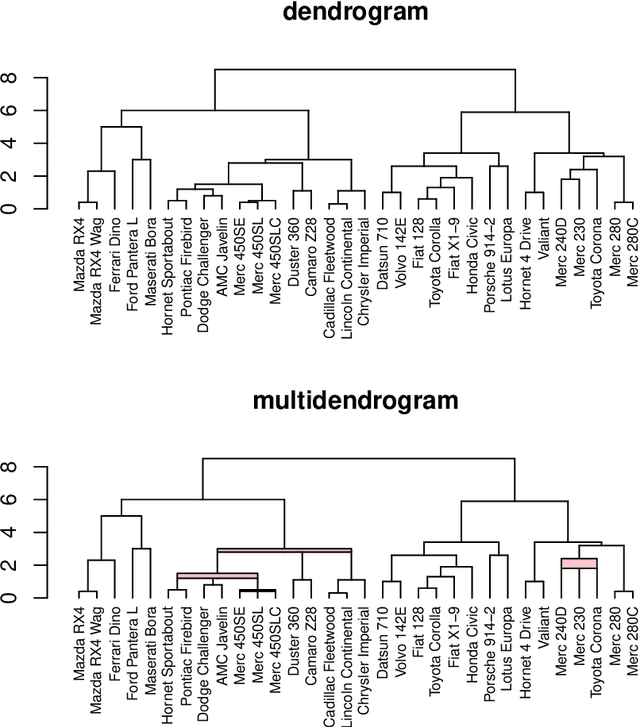

"mdendro" is an R package that provides a comprehensive collection of linkage methods for agglomerative hierarchical clustering on a matrix of proximity data (distances or similarities), returning a multifurcated dendrogram or multidendrogram. Multidendrograms can group more than two clusters at the same time, solving the nonuniqueness problem that arises when there are ties in the data. This problem causes that different binary dendrograms are possible depending both on the order of the input data and on the criterion used to break ties. Weighted and unweighted versions of the most common linkage methods are included in the package, which also implements two parametric linkage methods. In addition, package "mdendro" provides five descriptive measures to analyze the resulting dendrograms: cophenetic correlation coefficient, space distortion ratio, agglomerative coefficient, chaining coefficient and tree balance.
Exploiting Time-Frequency Conformers for Music Audio Enhancement
Aug 24, 2023
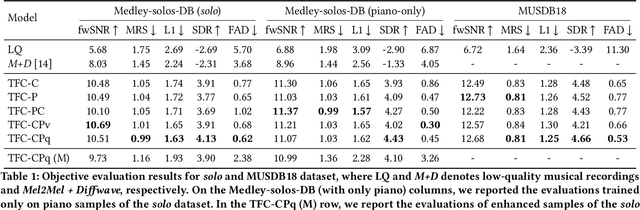
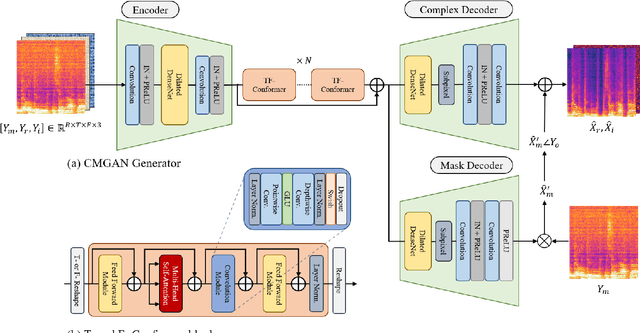
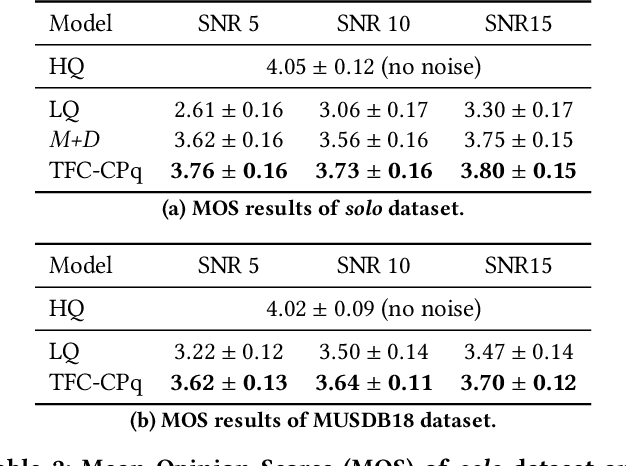
With the proliferation of video platforms on the internet, recording musical performances by mobile devices has become commonplace. However, these recordings often suffer from degradation such as noise and reverberation, which negatively impact the listening experience. Consequently, the necessity for music audio enhancement (referred to as music enhancement from this point onward), involving the transformation of degraded audio recordings into pristine high-quality music, has surged to augment the auditory experience. To address this issue, we propose a music enhancement system based on the Conformer architecture that has demonstrated outstanding performance in speech enhancement tasks. Our approach explores the attention mechanisms of the Conformer and examines their performance to discover the best approach for the music enhancement task. Our experimental results show that our proposed model achieves state-of-the-art performance on single-stem music enhancement. Furthermore, our system can perform general music enhancement with multi-track mixtures, which has not been examined in previous work.
Bridging Offline-Online Evaluation with a Time-dependent and Popularity Bias-free Offline Metric for Recommenders
Aug 14, 2023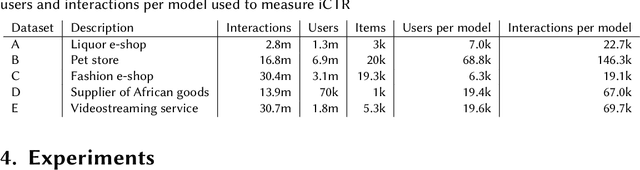
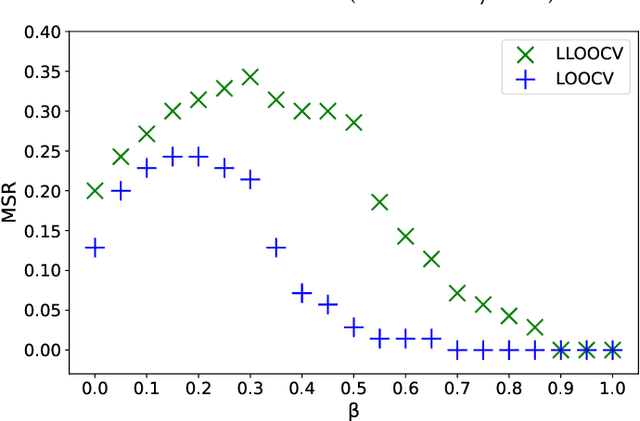
The evaluation of recommendation systems is a complex task. The offline and online evaluation metrics for recommender systems are ambiguous in their true objectives. The majority of recently published papers benchmark their methods using ill-posed offline evaluation methodology that often fails to predict true online performance. Because of this, the impact that academic research has on the industry is reduced. The aim of our research is to investigate and compare the online performance of offline evaluation metrics. We show that penalizing popular items and considering the time of transactions during the evaluation significantly improves our ability to choose the best recommendation model for a live recommender system. Our results, averaged over five large-size real-world live data procured from recommenders, aim to help the academic community to understand better offline evaluation and optimization criteria that are more relevant for real applications of recommender systems.
Gastro-Intestinal Tract Segmentation Using an Explainable 3D Unet
Sep 25, 2023In treating gastrointestinal cancer using radiotherapy, the role of the radiation oncologist is to administer high doses of radiation, through x-ray beams, toward the tumor while avoiding the stomach and intestines. With the advent of precise radiation treatment technology such as the MR-Linac, oncologists can visualize the daily positions of the tumors and intestines, which may vary day to day. Before delivering radiation, radio oncologists must manually outline the position of the gastrointestinal organs in order to determine position and direction of the x-ray beam. This is a time consuming and labor intensive process that may substantially prolong a patient's treatment. A deep learning (DL) method can automate and expedite the process. However, many deep neural networks approaches currently in use are black-boxes which lack interpretability which render them untrustworthy and impractical in a healthcare setting. To address this, an emergent field of AI known as Explainable AI (XAI) may be incorporated to improve the transparency and viability of a model. This paper proposes a deep learning pipeline that incorporates XAI to address the challenges of organ segmentation.
SuPerPM: A Large Deformation-Robust Surgical Perception Framework Based on Deep Point Matching Learned from Physical Constrained Simulation Data
Sep 25, 2023Manipulation of tissue with surgical tools often results in large deformations that current methods in tracking and reconstructing algorithms have not effectively addressed. A major source of tracking errors during large deformations stems from wrong data association between observed sensor measurements with previously tracked scene. To mitigate this issue, we present a surgical perception framework, SuPerPM, that leverages learning-based non-rigid point cloud matching for data association, thus accommodating larger deformations. The learning models typically require training data with ground truth point cloud correspondences, which is challenging or even impractical to collect in surgical environments. Thus, for tuning the learning model, we gather endoscopic data of soft tissue being manipulated by a surgical robot and then establish correspondences between point clouds at different time points to serve as ground truth. This was achieved by employing a position-based dynamics (PBD) simulation to ensure that the correspondences adhered to physical constraints. The proposed framework is demonstrated on several challenging surgical datasets that are characterized by large deformations, achieving superior performance over state-of-the-art surgical scene tracking algorithms.