 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Implementing a new fully stepwise decomposition-based sampling technique for the hybrid water level forecasting model in real-world application
Sep 19, 2023
Various time variant non-stationary signals need to be pre-processed properly in hydrological time series forecasting in real world, for example, predictions of water level. Decomposition method is a good candidate and widely used in such a pre-processing problem. However, decomposition methods with an inappropriate sampling technique may introduce future data which is not available in practical applications, and result in incorrect decomposition-based forecasting models. In this work, a novel Fully Stepwise Decomposition-Based (FSDB) sampling technique is well designed for the decomposition-based forecasting model, strictly avoiding introducing future information. This sampling technique with decomposition methods, such as Variational Mode Decomposition (VMD) and Singular spectrum analysis (SSA), is applied to predict water level time series in three different stations of Guoyang and Chaohu basins in China. Results of VMD-based hybrid model using FSDB sampling technique show that Nash-Sutcliffe Efficiency (NSE) coefficient is increased by 6.4%, 28.8% and 7.0% in three stations respectively, compared with those obtained from the currently most advanced sampling technique. In the meantime, for series of SSA-based experiments, NSE is increased by 3.2%, 3.1% and 1.1% respectively. We conclude that the newly developed FSDB sampling technique can be used to enhance the performance of decomposition-based hybrid model in water level time series forecasting in real world.
Effective and Parameter-Efficient Reusing Fine-Tuned Models
Oct 04, 2023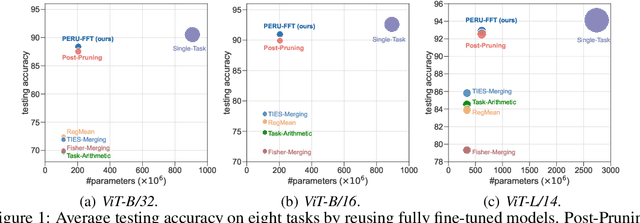
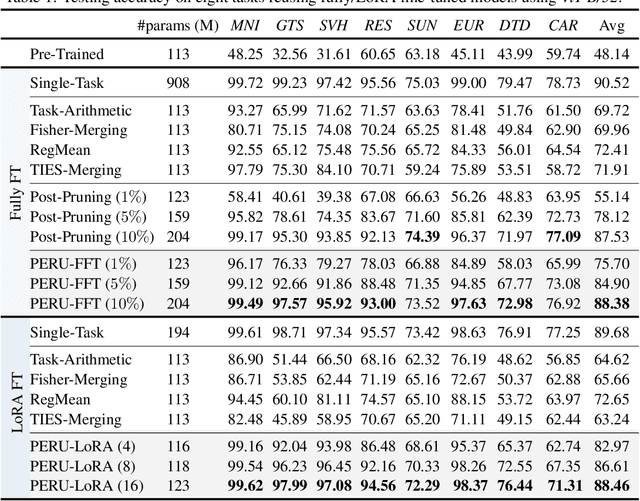
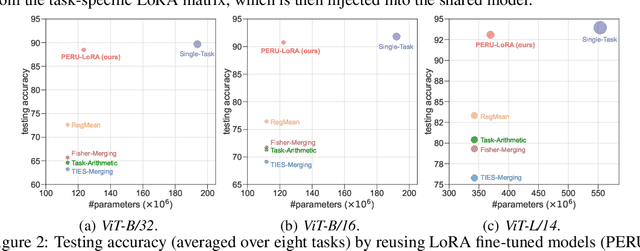
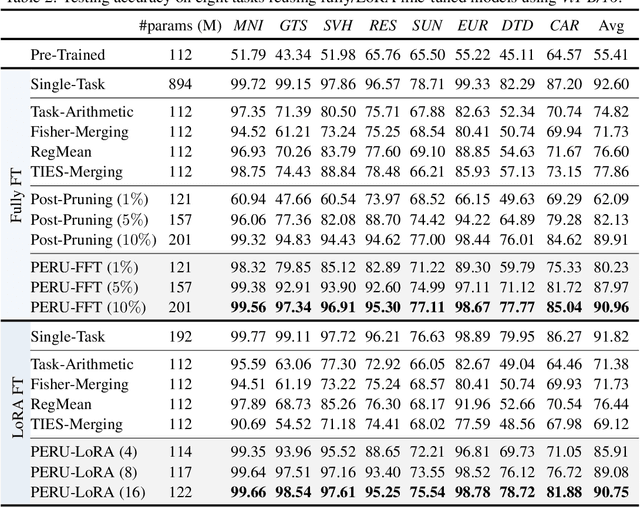
Many pre-trained large-scale models provided online have become highly effective in transferring to downstream tasks. At the same time, various task-specific models fine-tuned on these pre-trained models are available online for public use. In practice, as collecting task-specific data is labor-intensive and fine-tuning the large pre-trained models is computationally expensive, one can reuse task-specific finetuned models to deal with downstream tasks. However, using a model per task causes a heavy burden on storage and serving. Recently, many training-free and parameter-efficient methods have been proposed for reusing multiple fine-tuned task-specific models into a single multi-task model. However, these methods exhibit a large accuracy gap compared with using a fine-tuned model per task. In this paper, we propose Parameter-Efficient methods for ReUsing (PERU) fine-tuned models. For reusing Fully Fine-Tuned (FFT) models, we propose PERU-FFT by injecting a sparse task vector into a merged model by magnitude pruning. For reusing LoRA fine-tuned models, we propose PERU-LoRA use a lower-rank matrix to approximate the LoRA matrix by singular value decomposition. Both PERUFFT and PERU-LoRA are training-free. Extensive experiments conducted on computer vision and natural language process tasks demonstrate the effectiveness and parameter-efficiency of the proposed methods. The proposed PERU-FFT and PERU-LoRA outperform existing reusing model methods by a large margin and achieve comparable performance to using a fine-tuned model per task.
Investigating Alternative Feature Extraction Pipelines For Clinical Note Phenotyping
Oct 05, 2023A common practice in the medical industry is the use of clinical notes, which consist of detailed patient observations. However, electronic health record systems frequently do not contain these observations in a structured format, rendering patient information challenging to assess and evaluate automatically. Using computational systems for the extraction of medical attributes offers many applications, including longitudinal analysis of patients, risk assessment, and hospital evaluation. Recent work has constructed successful methods for phenotyping: extracting medical attributes from clinical notes. BERT-based models can be used to transform clinical notes into a series of representations, which are then condensed into a single document representation based on their CLS embeddings and passed into an LSTM (Mulyar et al., 2020). Though this pipeline yields a considerable performance improvement over previous results, it requires extensive convergence time. This method also does not allow for predicting attributes not yet identified in clinical notes. Considering the wide variety of medical attributes that may be present in a clinical note, we propose an alternative pipeline utilizing ScispaCy (Neumann et al., 2019) for the extraction of common diseases. We then train various supervised learning models to associate the presence of these conditions with patient attributes. Finally, we replicate a ClinicalBERT (Alsentzer et al., 2019) and LSTM-based approach for purposes of comparison. We find that alternative methods moderately underperform the replicated LSTM approach. Yet, considering a complex tradeoff between accuracy and runtime, in addition to the fact that the alternative approach also allows for the detection of medical conditions that are not already present in a clinical note, its usage may be considered as a supplement to established methods.
History Matching for Geological Carbon Storage using Data-Space Inversion with Spatio-Temporal Data Parameterization
Oct 05, 2023History matching based on monitoring data will enable uncertainty reduction, and thus improved aquifer management, in industrial-scale carbon storage operations. In traditional model-based data assimilation, geomodel parameters are modified to force agreement between flow simulation results and observations. In data-space inversion (DSI), history-matched quantities of interest, e.g., posterior pressure and saturation fields conditioned to observations, are inferred directly, without constructing posterior geomodels. This is accomplished efficiently using a set of O(1000) prior simulation results, data parameterization, and posterior sampling within a Bayesian setting. In this study, we develop and implement (in DSI) a deep-learning-based parameterization to represent spatio-temporal pressure and CO2 saturation fields at a set of time steps. The new parameterization uses an adversarial autoencoder (AAE) for dimension reduction and a convolutional long short-term memory (convLSTM) network to represent the spatial distribution and temporal evolution of the pressure and saturation fields. This parameterization is used with an ensemble smoother with multiple data assimilation (ESMDA) in the DSI framework to enable posterior predictions. A realistic 3D system characterized by prior geological realizations drawn from a range of geological scenarios is considered. A local grid refinement procedure is introduced to estimate the error covariance term that appears in the history matching formulation. Extensive history matching results are presented for various quantities, for multiple synthetic true models. Substantial uncertainty reduction in posterior pressure and saturation fields is achieved in all cases. The framework is applied to efficiently provide posterior predictions for a range of error covariance specifications. Such an assessment would be expensive using a model-based approach.
TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series
Aug 16, 2023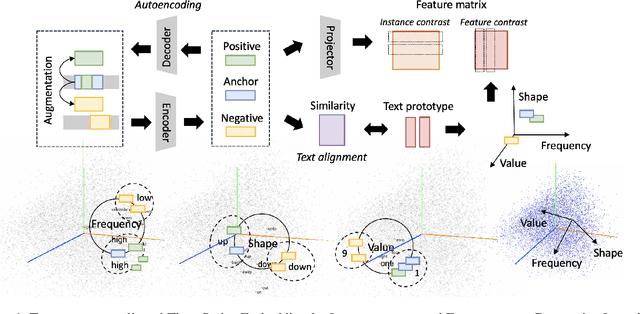
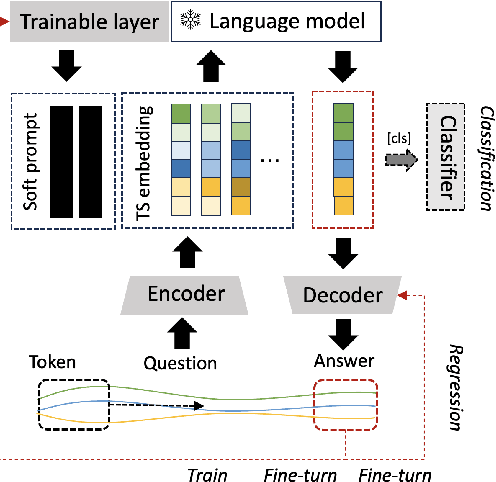
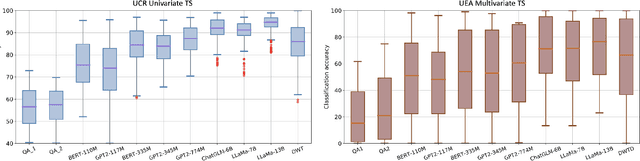
This work summarizes two strategies for completing time-series (TS) tasks using today's language model (LLM): LLM-for-TS, design and train a fundamental large model for TS data; TS-for-LLM, enable the pre-trained LLM to handle TS data. Considering the insufficient data accumulation, limited resources, and semantic context requirements, this work focuses on TS-for-LLM methods, where we aim to activate LLM's ability for TS data by designing a TS embedding method suitable for LLM. The proposed method is named TEST. It first tokenizes TS, builds an encoder to embed them by instance-wise, feature-wise, and text-prototype-aligned contrast, and then creates prompts to make LLM more open to embeddings, and finally implements TS tasks. Experiments are carried out on TS classification and forecasting tasks using 8 LLMs with different structures and sizes. Although its results cannot significantly outperform the current SOTA models customized for TS tasks, by treating LLM as the pattern machine, it can endow LLM's ability to process TS data without compromising the language ability. This paper is intended to serve as a foundational work that will inspire further research.
Task Graph offloading via Deep Reinforcement Learning in Mobile Edge Computing
Oct 02, 2023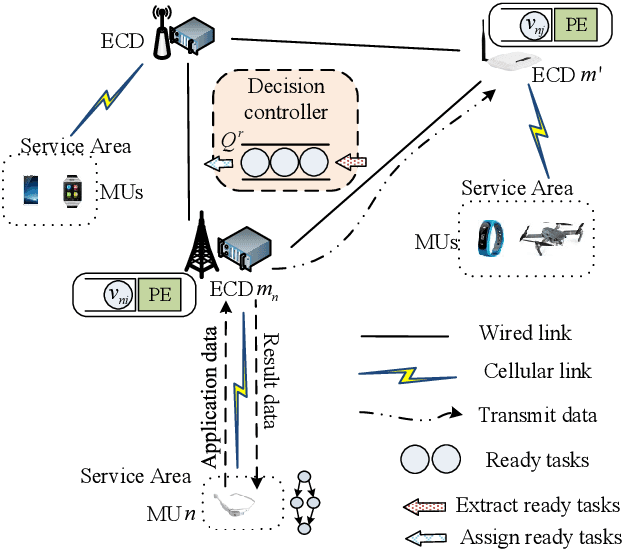
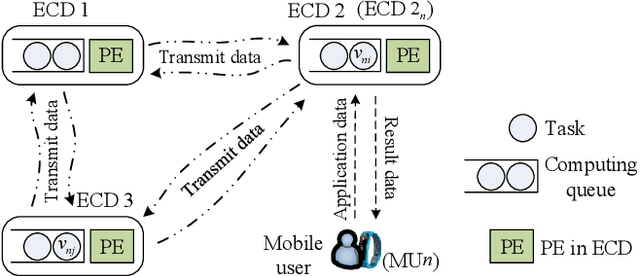
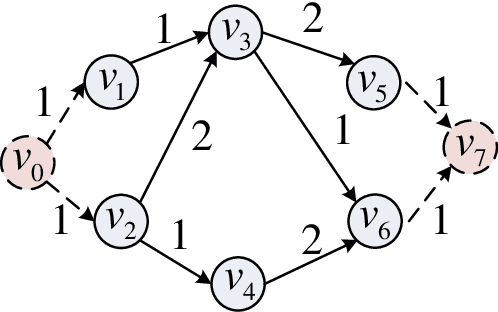
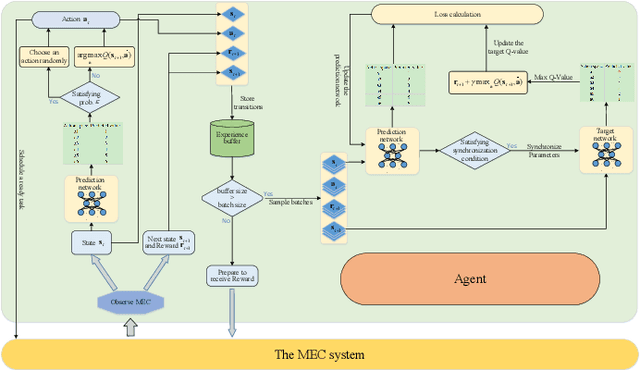
Various mobile applications that comprise dependent tasks are gaining widespread popularity and are increasingly complex. These applications often have low-latency requirements, resulting in a significant surge in demand for computing resources. With the emergence of mobile edge computing (MEC), it becomes the most significant issue to offload the application tasks onto small-scale devices deployed at the edge of the mobile network for obtaining a high-quality user experience. However, since the environment of MEC is dynamic, most existing works focusing on task graph offloading, which rely heavily on expert knowledge or accurate analytical models, fail to fully adapt to such environmental changes, resulting in the reduction of user experience. This paper investigates the task graph offloading in MEC, considering the time-varying computation capabilities of edge computing devices. To adapt to environmental changes, we model the task graph scheduling for computation offloading as a Markov Decision Process (MDP). Then, we design a deep reinforcement learning algorithm (SATA-DRL) to learn the task scheduling strategy from the interaction with the environment, to improve user experience. Extensive simulations validate that SATA-DRL is superior to existing strategies in terms of reducing average makespan and deadline violation.
Non-Exchangeable Conformal Risk Control
Oct 02, 2023Split conformal prediction has recently sparked great interest due to its ability to provide formally guaranteed uncertainty sets or intervals for predictions made by black-box neural models, ensuring a predefined probability of containing the actual ground truth. While the original formulation assumes data exchangeability, some extensions handle non-exchangeable data, which is often the case in many real-world scenarios. In parallel, some progress has been made in conformal methods that provide statistical guarantees for a broader range of objectives, such as bounding the best F1-score or minimizing the false negative rate in expectation. In this paper, we leverage and extend these two lines of work by proposing non-exchangeable conformal risk control, which allows controlling the expected value of any monotone loss function when the data is not exchangeable. Our framework is flexible, makes very few assumptions, and allows weighting the data based on its statistical similarity with the test examples; a careful choice of weights may result on tighter bounds, making our framework useful in the presence of change points, time series, or other forms of distribution drift. Experiments with both synthetic and real world data show the usefulness of our method.
A Good Snowman is Hard to Plan
Oct 02, 2023
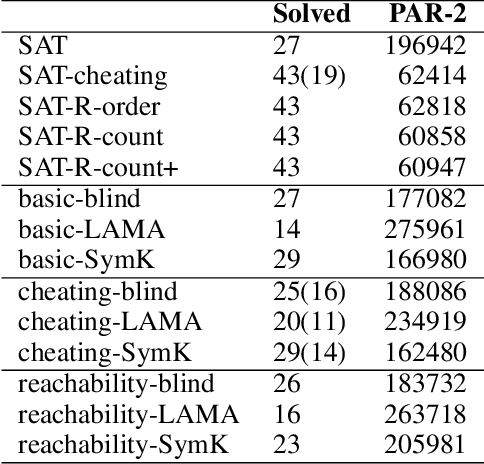
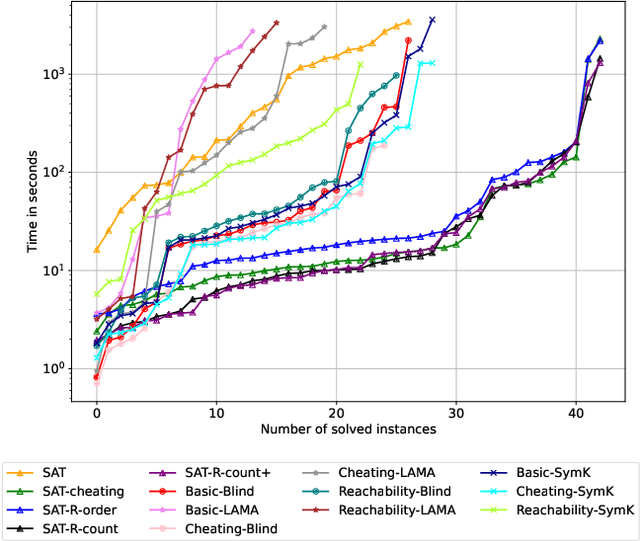
In this work we face a challenging puzzle video game: A Good Snowman is Hard to Build. The objective of the game is to build snowmen by moving and stacking snowballs on a discrete grid. For the sake of player engagement with the game, it is interesting to avoid that a player finds a much easier solution than the one the designer expected. Therefore, having tools that are able to certify the optimality of solutions is crucial. Although the game can be stated as a planning problem and can be naturally modelled in PDDL, we show that a direct translation to SAT clearly outperforms off-the-shelf state-of-the-art planners. As we show, this is mainly due to the fact that reachability properties can be easily modelled in SAT, allowing for shorter plans, whereas using axioms to express a reachability derived predicate in PDDL does not result in any significant reduction of solving time with the considered planners. We deal with a set of 51 levels, both original and crafted, solving 43 and with 8 challenging instances still remaining to be solved.
Color and Texture Dual Pipeline Lightweight Style Transfer
Oct 02, 2023Style transfer methods typically generate a single stylized output of color and texture coupling for reference styles, and color transfer schemes may introduce distortion or artifacts when processing reference images with duplicate textures. To solve the problem, we propose a Color and Texture Dual Pipeline Lightweight Style Transfer CTDP method, which employs a dual pipeline method to simultaneously output the results of color and texture transfer. Furthermore, we designed a masked total variation loss to suppress artifacts and small texture representations in color transfer results without affecting the semantic part of the content. More importantly, we are able to add texture structures with controllable intensity to color transfer results for the first time. Finally, we conducted feature visualization analysis on the texture generation mechanism of the framework and found that smoothing the input image can almost completely eliminate this texture structure. In comparative experiments, the color and texture transfer results generated by CTDP both achieve state-of-the-art performance. Additionally, the weight of the color transfer branch model size is as low as 20k, which is 100-1500 times smaller than that of other state-of-the-art models.
PASTA: PArallel Spatio-Temporal Attention with spatial auto-correlation gating for fine-grained crowd flow prediction
Oct 02, 2023Understanding the movement patterns of objects (e.g., humans and vehicles) in a city is essential for many applications, including city planning and management. This paper proposes a method for predicting future city-wide crowd flows by modeling the spatio-temporal patterns of historical crowd flows in fine-grained city-wide maps. We introduce a novel neural network named PArallel Spatio-Temporal Attention with spatial auto-correlation gating (PASTA) that effectively captures the irregular spatio-temporal patterns of fine-grained maps. The novel components in our approach include spatial auto-correlation gating, multi-scale residual block, and temporal attention gating module. The spatial auto-correlation gating employs the concept of spatial statistics to identify irregular spatial regions. The multi-scale residual block is responsible for handling multiple range spatial dependencies in the fine-grained map, and the temporal attention gating filters out irrelevant temporal information for the prediction. The experimental results demonstrate that our model outperforms other competing baselines, especially under challenging conditions that contain irregular spatial regions. We also provide a qualitative analysis to derive the critical time information where our model assigns high attention scores in prediction.