 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Linear Recurrent Units for Sequential Recommendation
Oct 03, 2023
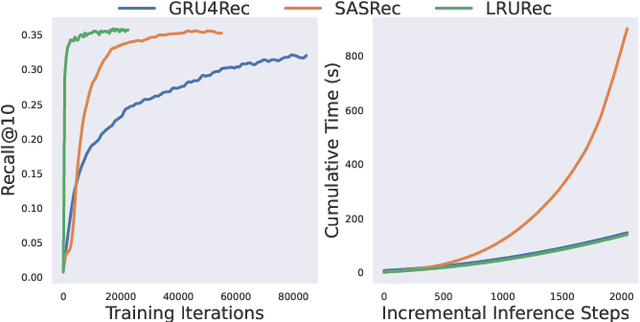
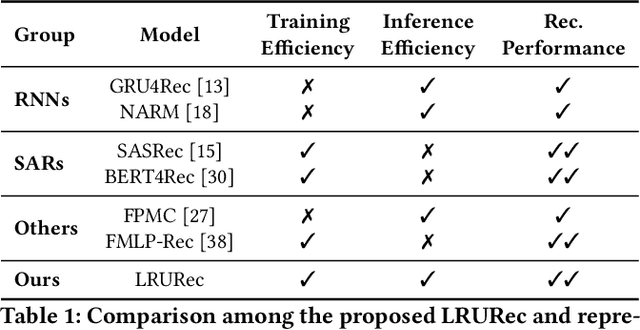
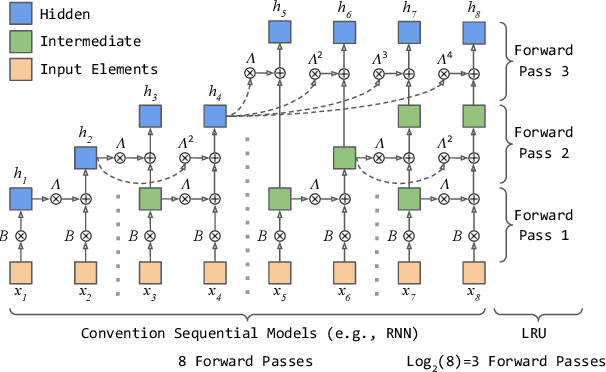
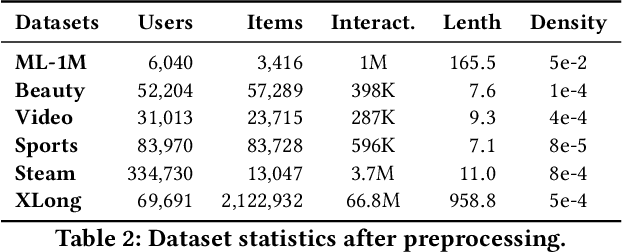
State-of-the-art sequential recommendation relies heavily on self-attention-based recommender models. Yet such models are computationally expensive and often too slow for real-time recommendation. Furthermore, the self-attention operation is performed at a sequence-level, thereby making low-cost incremental inference challenging. Inspired by recent advances in efficient language modeling, we propose linear recurrent units for sequential recommendation (LRURec). Similar to recurrent neural networks, LRURec offers rapid inference and can achieve incremental inference on sequential inputs. By decomposing the linear recurrence operation and designing recursive parallelization in our framework, LRURec provides the additional benefits of reduced model size and parallelizable training. Moreover, we optimize the architecture of LRURec by implementing a series of modifications to address the lack of non-linearity and improve training dynamics. To validate the effectiveness of our proposed LRURec, we conduct extensive experiments on multiple real-world datasets and compare its performance against state-of-the-art sequential recommenders. Experimental results demonstrate the effectiveness of LRURec, which consistently outperforms baselines by a significant margin. Results also highlight the efficiency of LRURec with our parallelized training paradigm and fast inference on long sequences, showing its potential to further enhance user experience in sequential recommendation.
Generalized Schrödinger Bridge Matching
Oct 03, 2023Modern distribution matching algorithms for training diffusion or flow models directly prescribe the time evolution of the marginal distributions between two boundary distributions. In this work, we consider a generalized distribution matching setup, where these marginals are only implicitly described as a solution to some task-specific objective function. The problem setup, known as the Generalized Schr\"odinger Bridge (GSB), appears prevalently in many scientific areas both within and without machine learning. We propose Generalized Schr\"odinger Bridge Matching (GSBM), a new matching algorithm inspired by recent advances, generalizing them beyond kinetic energy minimization and to account for task-specific state costs. We show that such a generalization can be cast as solving conditional stochastic optimal control, for which efficient variational approximations can be used, and further debiased with the aid of path integral theory. Compared to prior methods for solving GSB problems, our GSBM algorithm always preserves a feasible transport map between the boundary distributions throughout training, thereby enabling stable convergence and significantly improved scalability. We empirically validate our claims on an extensive suite of experimental setups, including crowd navigation, opinion depolarization, LiDAR manifolds, and image domain transfer. Our work brings new algorithmic opportunities for training diffusion models enhanced with task-specific optimality structures.
Adaptive Multi-NeRF: Exploit Efficient Parallelism in Adaptive Multiple Scale Neural Radiance Field Rendering
Oct 03, 2023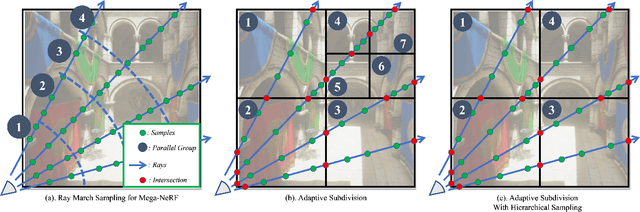

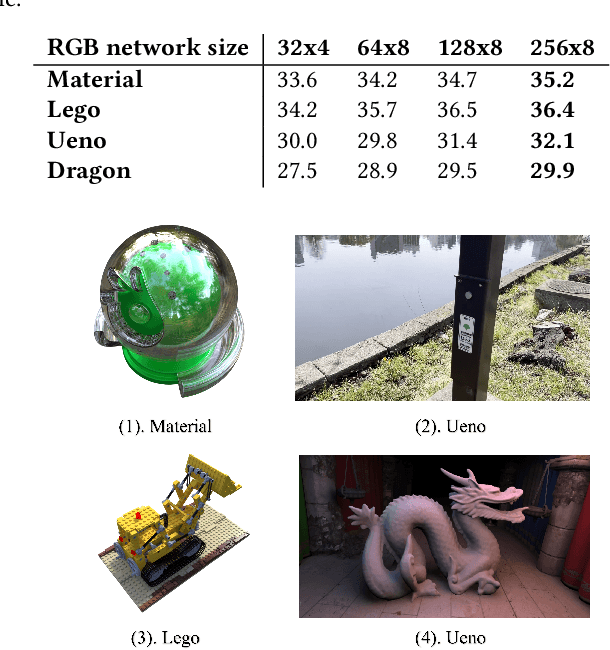
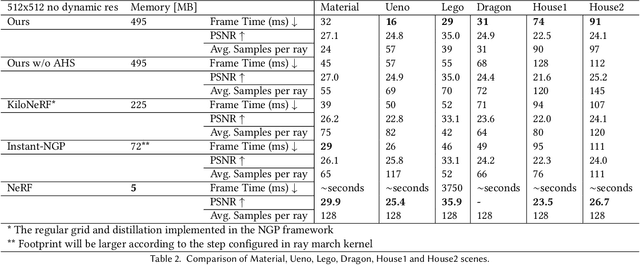
Recent advances in Neural Radiance Fields (NeRF) have demonstrated significant potential for representing 3D scene appearances as implicit neural networks, enabling the synthesis of high-fidelity novel views. However, the lengthy training and rendering process hinders the widespread adoption of this promising technique for real-time rendering applications. To address this issue, we present an effective adaptive multi-NeRF method designed to accelerate the neural rendering process for large scenes with unbalanced workloads due to varying scene complexities. Our method adaptively subdivides scenes into axis-aligned bounding boxes using a tree hierarchy approach, assigning smaller NeRFs to different-sized subspaces based on the complexity of each scene portion. This ensures the underlying neural representation is specific to a particular part of the scene. We optimize scene subdivision by employing a guidance density grid, which balances representation capability for each Multilayer Perceptron (MLP). Consequently, samples generated by each ray can be sorted and collected for parallel inference, achieving a balanced workload suitable for small MLPs with consistent dimensions for regular and GPU-friendly computations. We aosl demonstrated an efficient NeRF sampling strategy that intrinsically adapts to increase parallelism, utilization, and reduce kernel calls, thereby achieving much higher GPU utilization and accelerating the rendering process.
ScaleNet: An Unsupervised Representation Learning Method for Limited Information
Oct 03, 2023Although large-scale labeled data are essential for deep convolutional neural networks (ConvNets) to learn high-level semantic visual representations, it is time-consuming and impractical to collect and annotate large-scale datasets. A simple and efficient unsupervised representation learning method named ScaleNet based on multi-scale images is proposed in this study to enhance the performance of ConvNets when limited information is available. The input images are first resized to a smaller size and fed to the ConvNet to recognize the rotation degree. Next, the ConvNet learns the rotation-prediction task for the original size images based on the parameters transferred from the previous model. The CIFAR-10 and ImageNet datasets are examined on different architectures such as AlexNet and ResNet50 in this study. The current study demonstrates that specific image features, such as Harris corner information, play a critical role in the efficiency of the rotation-prediction task. The ScaleNet supersedes the RotNet by ~7% in the limited CIFAR-10 dataset. The transferred parameters from a ScaleNet model with limited data improve the ImageNet Classification task by about 6% compared to the RotNet model. This study shows the capability of the ScaleNet method to improve other cutting-edge models such as SimCLR by learning effective features for classification tasks.
Benchmarking and Improving Generator-Validator Consistency of Language Models
Oct 03, 2023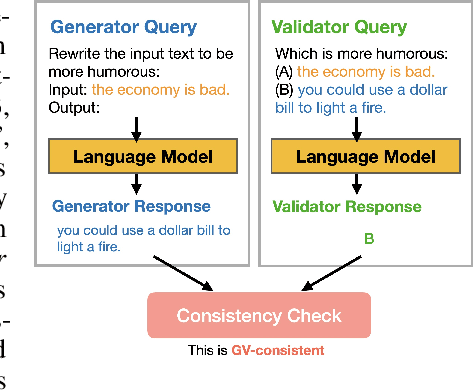

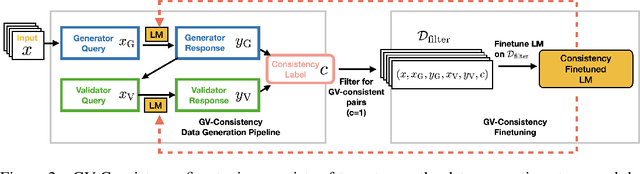

As of September 2023, ChatGPT correctly answers "what is 7+8" with 15, but when asked "7+8=15, True or False" it responds with "False". This inconsistency between generating and validating an answer is prevalent in language models (LMs) and erodes trust. In this paper, we propose a framework for measuring the consistency between generation and validation (which we call generator-validator consistency, or GV-consistency), finding that even GPT-4, a state-of-the-art LM, is GV-consistent only 76% of the time. To improve the consistency of LMs, we propose to finetune on the filtered generator and validator responses that are GV-consistent, and call this approach consistency fine-tuning. We find that this approach improves GV-consistency of Alpaca-30B from 60% to 93%, and the improvement extrapolates to unseen tasks and domains (e.g., GV-consistency for positive style transfers extrapolates to unseen styles like humor). In addition to improving consistency, consistency fine-tuning improves both generator quality and validator accuracy without using any labeled data. Evaluated across 6 tasks, including math questions, knowledge-intensive QA, and instruction following, our method improves the generator quality by 16% and the validator accuracy by 6.3% across all tasks.
Mixture of Quantized Experts (MoQE): Complementary Effect of Low-bit Quantization and Robustness
Oct 03, 2023Large Mixture of Experts (MoE) models could achieve state-of-the-art quality on various language tasks, including machine translation task, thanks to the efficient model scaling capability with expert parallelism. However, it has brought a fundamental issue of larger memory consumption and increased memory bandwidth bottleneck at deployment time. In this paper, we propose Mixture of Quantized Experts (MoQE) which is a simple weight-only quantization method applying ultra low-bit down to 2-bit quantizations only to expert weights for mitigating the increased memory and latency issues of MoE models. We show that low-bit quantization together with the MoE architecture delivers a reliable model performance while reducing the memory size significantly even without any additional training in most cases. In particular, expert layers in MoE models are much more robust to the quantization than conventional feedforward networks (FFN) layers. In our comprehensive analysis, we show that MoE models with 2-bit expert weights can deliver better model performance than the dense model trained on the same dataset. As a result of low-bit quantization, we show the model size can be reduced by 79.6% of the original half precision floating point (fp16) MoE model. Combined with an optimized GPU runtime implementation, it also achieves 1.24X speed-up on A100 GPUs.
Fast algorithm for centralized multi-agent maze exploration
Oct 03, 2023Recent advancements in robotics have paved the way for robots to replace humans in perilous situations, such as searching for victims in blazing buildings, earthquake-damaged structures, uncharted caves, traversing minefields, or patrolling crime-ridden streets. These challenges can be generalized as problems where agents need to explore unknown mazes. Although various algorithms for single-agent maze exploration exist, extending them to multi-agent systems poses complexities. We propose a solution: a cooperative multi-agent system of automated mobile agents for exploring unknown mazes and locating stationary targets. Our algorithm employs a potential field governing maze exploration, integrating cooperative agent behaviors like collision avoidance, coverage coordination, and path planning. This approach builds upon the Heat Equation Driven Area Coverage (HEDAC) method by Ivi\'c, Crnkovi\'c, and Mezi\'c. Unlike previous continuous domain applications, we adapt HEDAC for discrete domains, specifically mazes divided into nodes. Our algorithm is versatile, easily modified for anti-collision requirements, and adaptable to expanding mazes and numerical meshes over time. Comparative evaluations against alternative maze-solving methods illustrate our algorithm's superiority. The results highlight significant enhancements, showcasing its applicability across diverse mazes. Numerical simulations affirm its robustness, adaptability, scalability, and simplicity, enabling centralized parallel computation in autonomous systems of basic agents/robots.
STAMP: Differentiable Task and Motion Planning via Stein Variational Gradient Descent
Oct 03, 2023Planning for many manipulation tasks, such as using tools or assembling parts, often requires both symbolic and geometric reasoning. Task and Motion Planning (TAMP) algorithms typically solve these problems by conducting a tree search over high-level task sequences while checking for kinematic and dynamic feasibility. While performant, most existing algorithms are highly inefficient as their time complexity grows exponentially with the number of possible actions and objects. Additionally, they only find a single solution to problems in which many feasible plans may exist. To address these limitations, we propose a novel algorithm called Stein Task and Motion Planning (STAMP) that leverages parallelization and differentiable simulation to efficiently search for multiple diverse plans. STAMP relaxes discrete-and-continuous TAMP problems into continuous optimization problems that can be solved using variational inference. Our algorithm builds upon Stein Variational Gradient Descent, a gradient-based variational inference algorithm, and parallelized differentiable physics simulators on the GPU to efficiently obtain gradients for inference. Further, we employ imitation learning to introduce action abstractions that reduce the inference problem to lower dimensions. We demonstrate our method on two TAMP problems and empirically show that STAMP is able to: 1) produce multiple diverse plans in parallel; and 2) search for plans more efficiently compared to existing TAMP baselines.
Investigating Large Language Models' Perception of Emotion Using Appraisal Theory
Oct 03, 2023Large Language Models (LLM) like ChatGPT have significantly advanced in recent years and are now being used by the general public. As more people interact with these systems, improving our understanding of these black box models is crucial, especially regarding their understanding of human psychological aspects. In this work, we investigate their emotion perception through the lens of appraisal and coping theory using the Stress and Coping Process Questionaire (SCPQ). SCPQ is a validated clinical instrument consisting of multiple stories that evolve over time and differ in key appraisal variables such as controllability and changeability. We applied SCPQ to three recent LLMs from OpenAI, davinci-003, ChatGPT, and GPT-4 and compared the results with predictions from the appraisal theory and human data. The results show that LLMs' responses are similar to humans in terms of dynamics of appraisal and coping, but their responses did not differ along key appraisal dimensions as predicted by the theory and data. The magnitude of their responses is also quite different from humans in several variables. We also found that GPTs can be quite sensitive to instruction and how questions are asked. This work adds to the growing literature evaluating the psychological aspects of LLMs and helps enrich our understanding of the current models.
Treating Motion as Option with Output Selection for Unsupervised Video Object Segmentation
Sep 26, 2023Unsupervised video object segmentation (VOS) is a task that aims to detect the most salient object in a video without external guidance about the object. To leverage the property that salient objects usually have distinctive movements compared to the background, recent methods collaboratively use motion cues extracted from optical flow maps with appearance cues extracted from RGB images. However, as optical flow maps are usually very relevant to segmentation masks, the network is easy to be learned overly dependent on the motion cues during network training. As a result, such two-stream approaches are vulnerable to confusing motion cues, making their prediction unstable. To relieve this issue, we design a novel motion-as-option network by treating motion cues as optional. During network training, RGB images are randomly provided to the motion encoder instead of optical flow maps, to implicitly reduce motion dependency of the network. As the learned motion encoder can deal with both RGB images and optical flow maps, two different predictions can be generated depending on which source information is used as motion input. In order to fully exploit this property, we also propose an adaptive output selection algorithm to adopt optimal prediction result at test time. Our proposed approach affords state-of-the-art performance on all public benchmark datasets, even maintaining real-time inference speed.