 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GeNet: A Graph Neural Network-based Anti-noise Task-Oriented Semantic Communication Paradigm
Mar 27, 2024
Traditional approaches to semantic communication tasks rely on the knowledge of the signal-to-noise ratio (SNR) to mitigate channel noise. However, these methods necessitate training under specific SNR conditions, entailing considerable time and computational resources. In this paper, we propose GeNet, a Graph Neural Network (GNN)-based paradigm for semantic communication aimed at combating noise, thereby facilitating Task-Oriented Communication (TOC). We propose a novel approach where we first transform the input data image into graph structures. Then we leverage a GNN-based encoder to extract semantic information from the source data. This extracted semantic information is then transmitted through the channel. At the receiver's end, a GNN-based decoder is utilized to reconstruct the relevant semantic information from the source data for TOC. Through experimental evaluation, we show GeNet's effectiveness in anti-noise TOC while decoupling the SNR dependency. We further evaluate GeNet's performance by varying the number of nodes, revealing its versatility as a new paradigm for semantic communication. Additionally, we show GeNet's robustness to geometric transformations by testing it with different rotation angles, without resorting to data augmentation.
Breaking the Length Barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
Mar 28, 2024With the rise of large language models (LLMs), recent works have leveraged LLMs to improve the performance of click-through rate (CTR) prediction. However, we argue that a critical obstacle remains in deploying LLMs for practical use: the efficiency of LLMs when processing long textual user behaviors. As user sequences grow longer, the current efficiency of LLMs is inadequate for training on billions of users and items. To break through the efficiency barrier of LLMs, we propose Behavior Aggregated Hierarchical Encoding (BAHE) to enhance the efficiency of LLM-based CTR modeling. Specifically, BAHE proposes a novel hierarchical architecture that decouples the encoding of user behaviors from inter-behavior interactions. Firstly, to prevent computational redundancy from repeated encoding of identical user behaviors, BAHE employs the LLM's pre-trained shallow layers to extract embeddings of the most granular, atomic user behaviors from extensive user sequences and stores them in the offline database. Subsequently, the deeper, trainable layers of the LLM facilitate intricate inter-behavior interactions, thereby generating comprehensive user embeddings. This separation allows the learning of high-level user representations to be independent of low-level behavior encoding, significantly reducing computational complexity. Finally, these refined user embeddings, in conjunction with correspondingly processed item embeddings, are incorporated into the CTR model to compute the CTR scores. Extensive experimental results show that BAHE reduces training time and memory by five times for CTR models using LLMs, especially with longer user sequences. BAHE has been deployed in a real-world system, allowing for daily updates of 50 million CTR data on 8 A100 GPUs, making LLMs practical for industrial CTR prediction.
LLMSense: Harnessing LLMs for High-level Reasoning Over Spatiotemporal Sensor Traces
Mar 28, 2024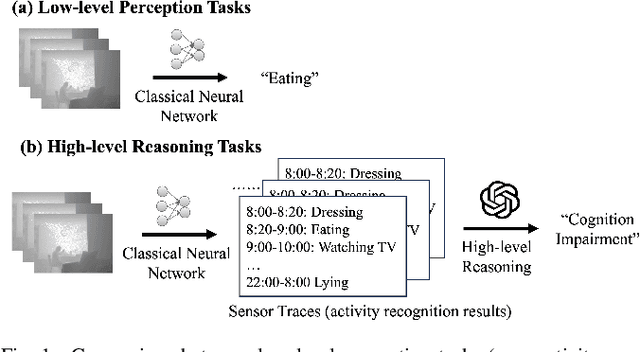

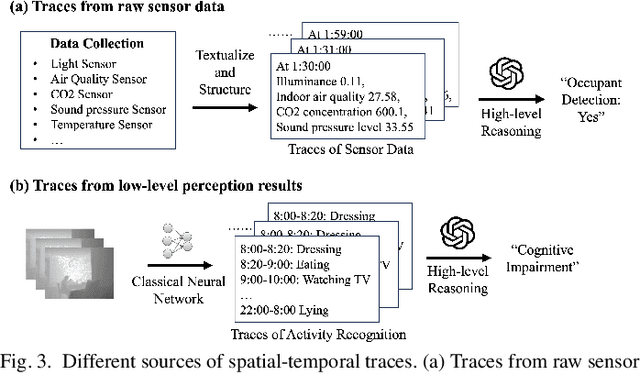

Most studies on machine learning in sensing systems focus on low-level perception tasks that process raw sensory data within a short time window. However, many practical applications, such as human routine modeling and occupancy tracking, require high-level reasoning abilities to comprehend concepts and make inferences based on long-term sensor traces. Existing machine learning-based approaches for handling such complex tasks struggle to generalize due to the limited training samples and the high dimensionality of sensor traces, necessitating the integration of human knowledge for designing first-principle models or logic reasoning methods. We pose a fundamental question: Can we harness the reasoning capabilities and world knowledge of Large Language Models (LLMs) to recognize complex events from long-term spatiotemporal sensor traces? To answer this question, we design an effective prompting framework for LLMs on high-level reasoning tasks, which can handle traces from the raw sensor data as well as the low-level perception results. We also design two strategies to enhance performance with long sensor traces, including summarization before reasoning and selective inclusion of historical traces. Our framework can be implemented in an edge-cloud setup, running small LLMs on the edge for data summarization and performing high-level reasoning on the cloud for privacy preservation. The results show that LLMSense can achieve over 80\% accuracy on two high-level reasoning tasks such as dementia diagnosis with behavior traces and occupancy tracking with environmental sensor traces. This paper provides a few insights and guidelines for leveraging LLM for high-level reasoning on sensor traces and highlights several directions for future work.
Policy-Space Search: Equivalences, Improvements, and Compression
Mar 28, 2024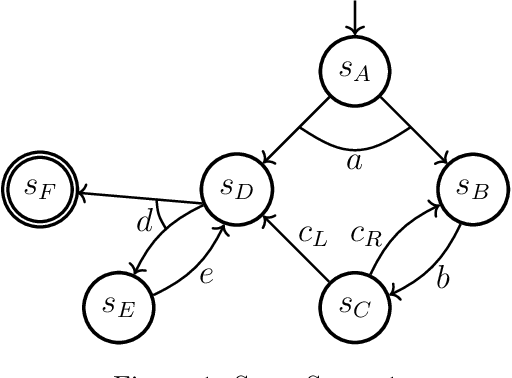

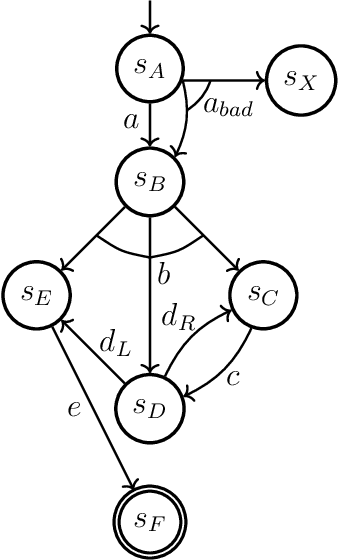
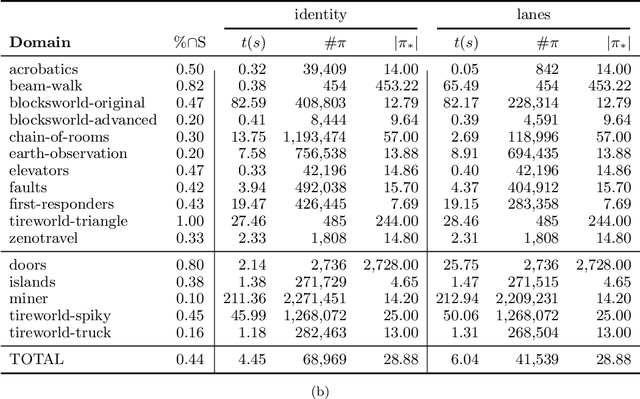
Fully-observable non-deterministic (FOND) planning is at the core of artificial intelligence planning with uncertainty. It models uncertainty through actions with non-deterministic effects. A* with Non-Determinism (AND*) (Messa and Pereira, 2023) is a FOND planner that generalizes A* (Hart et al., 1968) for FOND planning. It searches for a solution policy by performing an explicit heuristic search on the policy space of the FOND task. In this paper, we study and improve the performance of the policy-space search performed by AND*. We present a polynomial-time procedure that constructs a solution policy given just the set of states that should be mapped. This procedure, together with a better understanding of the structure of FOND policies, allows us to present three concepts of equivalences between policies. We use policy equivalences to prune part of the policy search space, making AND* substantially more effective in solving FOND tasks. We also study the impact of taking into account structural state-space symmetries to strengthen the detection of equivalence policies and the impact of performing the search with satisficing techniques. We apply a recent technique from the group theory literature to better compute structural state-space symmetries. Finally, we present a solution compressor that, given a policy defined over complete states, finds a policy that unambiguously represents it using the minimum number of partial states. AND* with the introduced techniques generates, on average, two orders of magnitude fewer policies to solve FOND tasks. These techniques allow explicit policy-space search to be competitive in terms of both coverage and solution compactness with other state-of-the-art FOND planners.
Movable-Antenna Position Optimization: A Graph-based Approach
Mar 25, 2024Fluid antennas (FAs) and movable antennas (MAs) have emerged as promising technologies in wireless communications, which offer the flexibility to improve channel conditions by adjusting transmit/receive antenna positions within a spatial region. In this letter, we focus on an MA-enhanced multiple-input single-output (MISO) communication system, aiming to optimize the positions of multiple transmit MAs to maximize the received signal power. Unlike the prior works on continuously searching for the optimal MA positions, we propose to sample the transmit region into discrete points, such that the continuous antenna position optimization problem is transformed to a discrete sampling point selection problem based on the point-wise channel information. However, such a point selection problem is combinatory and challenging to be optimally solved. To tackle this challenge, we ingeniously recast it as an equivalent fixed-hop shortest path problem in graph theory and propose a customized algorithm to solve it optimally in polynomial time. To further reduce the complexity, a linear-time sequential update algorithm is also proposed to obtain a high-quality suboptimal solution. Numerical results demonstrate that the proposed algorithms can yield considerable performance gains over the conventional fixed-position antennas with/without antenna selection.
Adaptive TTD Configurations for Near-Field Communications: An Unsupervised Transformer Approach
Mar 26, 2024True-time delayers (TTDs) are popular analog devices for facilitating near-field wideband beamforming subject to the spatial-wideband effect. In this paper, an adaptive TTD configuration is proposed for short-range TTDs. Compared to the existing TTD configurations, the proposed one can effectively combat the spatial-widebandd effect for arbitrary user locations and array shapes with the aid of a switch network. A novel end-to-end deep neural network is proposed to optimize the hybrid beamforming with adaptive TTDs for maximizing spectral efficiency. 1) First, based on the U-Net architecture, a near-field channel learning module (NFC-LM) is proposed for adaptive beamformer design through extracting the latent channel response features of various users across different frequencies. In the NFC-LM, an improved cross attention (CA) is introduced to further optimize beamformer design by enhancing the latent feature connection between near-field channel and different beamformers. 2) Second, a switch multi-user transformer (S-MT) is proposed to adaptively control the connection between TTDs and phase shifters (PSs). In the S-MT, an improved multi-head attention, namely multi-user attention (MSA), is introduced to optimize the switch network through exploring the latent channel relations among various users. 3) Third, a multi feature cross attention (MCA) is introduced to simultaneously optimize the NFC-LM and S-MT by enhancing the latent feature correlation between beamformers and switch network. Numerical simulation results show that 1) the proposed adaptive TTD configuration effectively eliminates the spatial-wideband effect under uniform linear array (ULA) and uniform circular array (UCA) architectures, and 2) the proposed deep neural network can provide near optimal spectral efficiency, and solve the multi-user bemformer design and dynamical connection problem in real-time.
A Two-Phase Recall-and-Select Framework for Fast Model Selection
Mar 28, 2024As the ubiquity of deep learning in various machine learning applications has amplified, a proliferation of neural network models has been trained and shared on public model repositories. In the context of a targeted machine learning assignment, utilizing an apt source model as a starting point typically outperforms the strategy of training from scratch, particularly with limited training data. Despite the investigation and development of numerous model selection strategies in prior work, the process remains time-consuming, especially given the ever-increasing scale of model repositories. In this paper, we propose a two-phase (coarse-recall and fine-selection) model selection framework, aiming to enhance the efficiency of selecting a robust model by leveraging the models' training performances on benchmark datasets. Specifically, the coarse-recall phase clusters models showcasing similar training performances on benchmark datasets in an offline manner. A light-weight proxy score is subsequently computed between this model cluster and the target dataset, which serves to recall a significantly smaller subset of potential candidate models in a swift manner. In the following fine-selection phase, the final model is chosen by fine-tuning the recalled models on the target dataset with successive halving. To accelerate the process, the final fine-tuning performance of each potential model is predicted by mining the model's convergence trend on the benchmark datasets, which aids in filtering lower performance models more earlier during fine-tuning. Through extensive experimentation on tasks covering natural language processing and computer vision, it has been demonstrated that the proposed methodology facilitates the selection of a high-performing model at a rate about 3x times faster than conventional baseline methods. Our code is available at https://github.com/plasware/two-phase-selection.
Do High-Performance Image-to-Image Translation Networks Enable the Discovery of Radiomic Features? Application to MRI Synthesis from Ultrasound in Prostate Cancer
Mar 27, 2024This study investigates the foundational characteristics of image-to-image translation networks, specifically examining their suitability and transferability within the context of routine clinical environments, despite achieving high levels of performance, as indicated by a Structural Similarity Index (SSIM) exceeding 0.95. The evaluation study was conducted using data from 794 patients diagnosed with Prostate cancer. To synthesize MRI from Ultrasound images, we employed five widely recognized image to image translation networks in medical imaging: 2DPix2Pix, 2DCycleGAN, 3DCycleGAN, 3DUNET, and 3DAutoEncoder. For quantitative assessment, we report four prevalent evaluation metrics Mean Absolute Error, Mean Square Error, Structural Similarity Index (SSIM), and Peak Signal to Noise Ratio. Moreover, a complementary analysis employing Radiomic features (RF) via Spearman correlation coefficient was conducted to investigate, for the first time, whether networks achieving high performance, SSIM greater than 0.9, could identify low-level RFs. The RF analysis showed 76 features out of 186 RFs were discovered via just 2DPix2Pix algorithm while half of RFs were lost in the translation process. Finally, a detailed qualitative assessment by five medical doctors indicated a lack of low level feature discovery in image to image translation tasks.
MA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification
Mar 27, 2024The objective of search result diversification (SRD) is to ensure that selected documents cover as many different subtopics as possible. Existing methods primarily utilize a paradigm of "greedy selection", i.e., selecting one document with the highest diversity score at a time. These approaches tend to be inefficient and are easily trapped in a suboptimal state. In addition, some other methods aim to approximately optimize the diversity metric, such as $\alpha$-NDCG, but the results still remain suboptimal. To address these challenges, we introduce Multi-Agent reinforcement learning (MARL) for search result DIVersity, which called MA4DIV. In this approach, each document is an agent and the search result diversification is modeled as a cooperative task among multiple agents. This approach allows for directly optimizing the diversity metrics, such as $\alpha$-NDCG, while achieving high training efficiency. We conducted preliminary experiments on public TREC datasets to demonstrate the effectiveness and potential of MA4DIV. Considering the limited number of queries in public TREC datasets, we construct a large-scale dataset from industry sources and show that MA4DIV achieves substantial improvements in both effectiveness and efficiency than existing baselines on a industrial scale dataset.
Learning Inclusion Matching for Animation Paint Bucket Colorization
Mar 27, 2024Colorizing line art is a pivotal task in the production of hand-drawn cel animation. This typically involves digital painters using a paint bucket tool to manually color each segment enclosed by lines, based on RGB values predetermined by a color designer. This frame-by-frame process is both arduous and time-intensive. Current automated methods mainly focus on segment matching. This technique migrates colors from a reference to the target frame by aligning features within line-enclosed segments across frames. However, issues like occlusion and wrinkles in animations often disrupt these direct correspondences, leading to mismatches. In this work, we introduce a new learning-based inclusion matching pipeline, which directs the network to comprehend the inclusion relationships between segments rather than relying solely on direct visual correspondences. Our method features a two-stage pipeline that integrates a coarse color warping module with an inclusion matching module, enabling more nuanced and accurate colorization. To facilitate the training of our network, we also develope a unique dataset, referred to as PaintBucket-Character. This dataset includes rendered line arts alongside their colorized counterparts, featuring various 3D characters. Extensive experiments demonstrate the effectiveness and superiority of our method over existing techniques.