 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TrTr: A Versatile Pre-Trained Large Traffic Model based on Transformer for Capturing Trajectory Diversity in Vehicle Population
Sep 22, 2023
Understanding trajectory diversity is a fundamental aspect of addressing practical traffic tasks. However, capturing the diversity of trajectories presents challenges, particularly with traditional machine learning and recurrent neural networks due to the requirement of large-scale parameters. The emerging Transformer technology, renowned for its parallel computation capabilities enabling the utilization of models with hundreds of millions of parameters, offers a promising solution. In this study, we apply the Transformer architecture to traffic tasks, aiming to learn the diversity of trajectories within vehicle populations. We analyze the Transformer's attention mechanism and its adaptability to the goals of traffic tasks, and subsequently, design specific pre-training tasks. To achieve this, we create a data structure tailored to the attention mechanism and introduce a set of noises that correspond to spatio-temporal demands, which are incorporated into the structured data during the pre-training process. The designed pre-training model demonstrates excellent performance in capturing the spatial distribution of the vehicle population, with no instances of vehicle overlap and an RMSE of 0.6059 when compared to the ground truth values. In the context of time series prediction, approximately 95% of the predicted trajectories' speeds closely align with the true speeds, within a deviation of 7.5144m/s. Furthermore, in the stability test, the model exhibits robustness by continuously predicting a time series ten times longer than the input sequence, delivering smooth trajectories and showcasing diverse driving behaviors. The pre-trained model also provides a good basis for downstream fine-tuning tasks. The number of parameters of our model is over 50 million.
Development of a Deep Learning Method to Identify Acute Ischemic Stroke Lesions on Brain CT
Sep 29, 2023
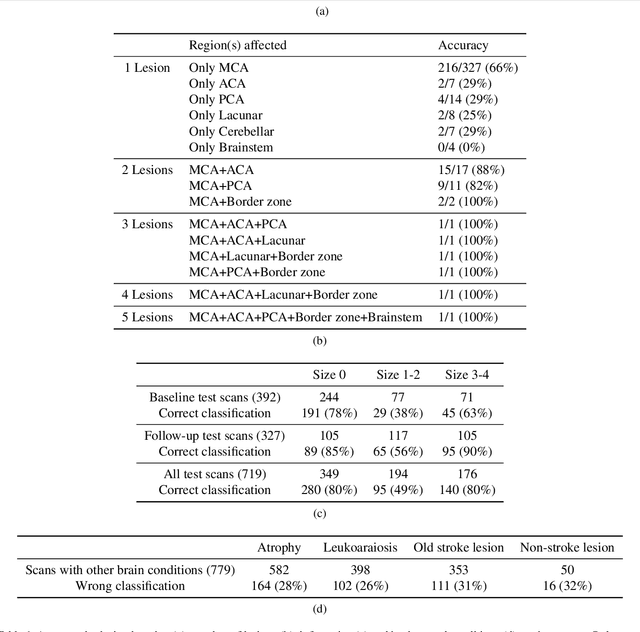
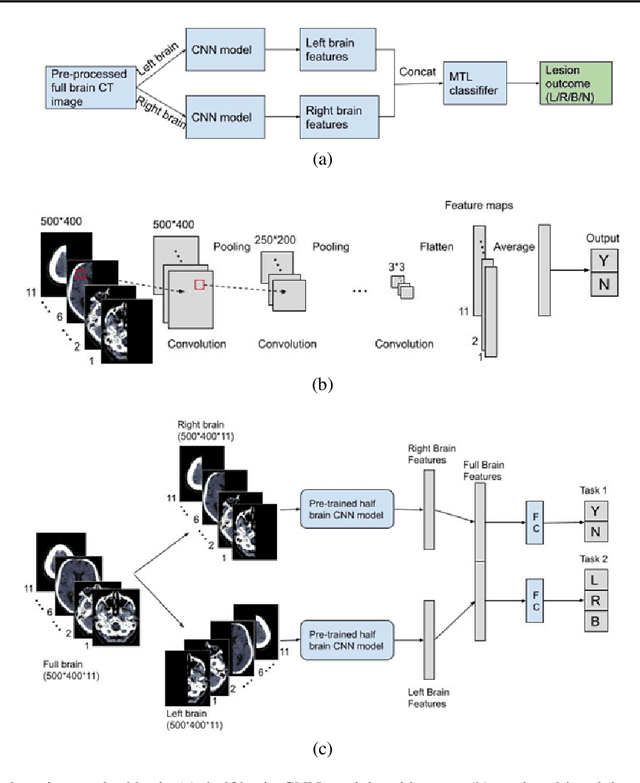
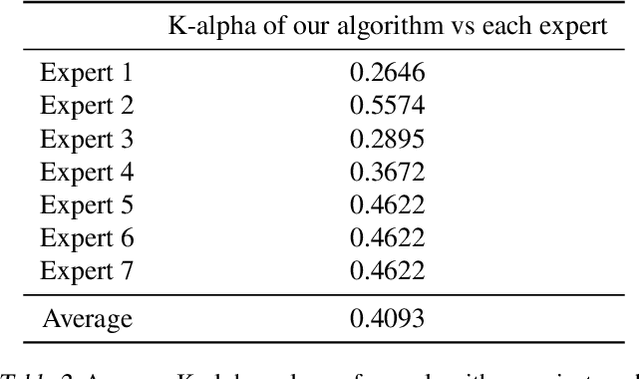
Computed Tomography (CT) is commonly used to image acute ischemic stroke (AIS) patients, but its interpretation by radiologists is time-consuming and subject to inter-observer variability. Deep learning (DL) techniques can provide automated CT brain scan assessment, but usually require annotated images. Aiming to develop a DL method for AIS using labelled but not annotated CT brain scans from patients with AIS, we designed a convolutional neural network-based DL algorithm using routinely-collected CT brain scans from the Third International Stroke Trial (IST-3), which were not acquired using strict research protocols. The DL model aimed to detect AIS lesions and classify the side of the brain affected. We explored the impact of AIS lesion features, background brain appearances, and timing on DL performance. From 5772 unique CT scans of 2347 AIS patients (median age 82), 54% had visible AIS lesions according to expert labelling. Our best-performing DL method achieved 72% accuracy for lesion presence and side. Lesions that were larger (80% accuracy) or multiple (87% accuracy for two lesions, 100% for three or more), were better detected. Follow-up scans had 76% accuracy, while baseline scans 67% accuracy. Chronic brain conditions reduced accuracy, particularly non-stroke lesions and old stroke lesions (32% and 31% error rates respectively). DL methods can be designed for AIS lesion detection on CT using the vast quantities of routinely-collected CT brain scan data. Ultimately, this should lead to more robust and widely-applicable methods.
DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation
Sep 29, 2023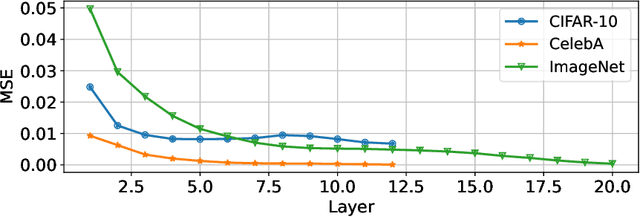
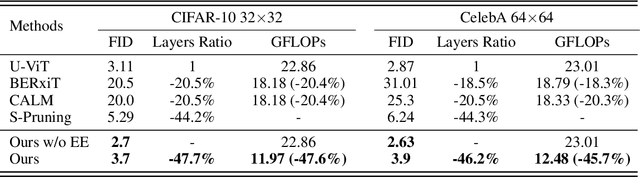
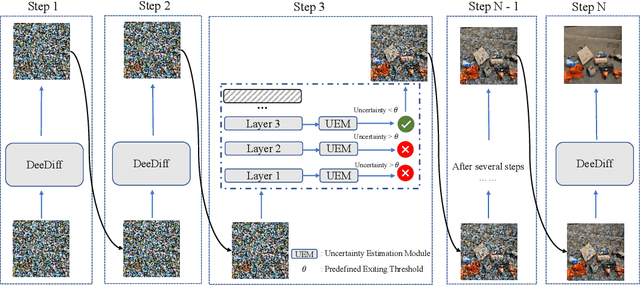
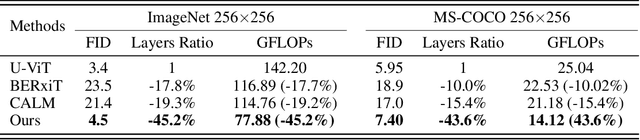
Diffusion models achieve great success in generating diverse and high-fidelity images. The performance improvements come with low generation speed per image, which hinders the application diffusion models in real-time scenarios. While some certain predictions benefit from the full computation of the model in each sample iteration, not every iteration requires the same amount of computation, potentially leading to computation waste. In this work, we propose DeeDiff, an early exiting framework that adaptively allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Specifically, we introduce a timestep-aware uncertainty estimation module (UEM) for diffusion models which is attached to each intermediate layer to estimate the prediction uncertainty of each layer. The uncertainty is regarded as the signal to decide if the inference terminates. Moreover, we propose uncertainty-aware layer-wise loss to fill the performance gap between full models and early-exited models. With such loss strategy, our model is able to obtain comparable results as full-layer models. Extensive experiments of class-conditional, unconditional, and text-guided generation on several datasets show that our method achieves state-of-the-art performance and efficiency trade-off compared with existing early exiting methods on diffusion models. More importantly, our method even brings extra benefits to baseline models and obtains better performance on CIFAR-10 and Celeb-A datasets. Full code and model are released for reproduction.
Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
Sep 20, 2023In the past years, YOLO-series models have emerged as the leading approaches in the area of real-time object detection. Many studies pushed up the baseline to a higher level by modifying the architecture, augmenting data and designing new losses. However, we find previous models still suffer from information fusion problem, although Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) have alleviated this. Therefore, this study provides an advanced Gatherand-Distribute mechanism (GD) mechanism, which is realized with convolution and self-attention operations. This new designed model named as Gold-YOLO, which boosts the multi-scale feature fusion capabilities and achieves an ideal balance between latency and accuracy across all model scales. Additionally, we implement MAE-style pretraining in the YOLO-series for the first time, allowing YOLOseries models could be to benefit from unsupervised pretraining. Gold-YOLO-N attains an outstanding 39.9% AP on the COCO val2017 datasets and 1030 FPS on a T4 GPU, which outperforms the previous SOTA model YOLOv6-3.0-N with similar FPS by +2.4%. The PyTorch code is available at https://github.com/huaweinoah/Efficient-Computing/Detection/Gold-YOLO, and the MindSpore code is available at https://gitee.com/mindspore/models/tree/master/research/cv/Gold_YOLO.
Fast Locality Sensitive Hashing with Theoretical Guarantee
Sep 27, 2023Locality-sensitive hashing (LSH) is an effective randomized technique widely used in many machine learning tasks. The cost of hashing is proportional to data dimensions, and thus often the performance bottleneck when dimensionality is high and the number of hash functions involved is large. Surprisingly, however, little work has been done to improve the efficiency of LSH computation. In this paper, we design a simple yet efficient LSH scheme, named FastLSH, under l2 norm. By combining random sampling and random projection, FastLSH reduces the time complexity from O(n) to O(m) (m<n), where n is the data dimensionality and m is the number of sampled dimensions. Moreover, FastLSH has provable LSH property, which distinguishes it from the non-LSH fast sketches. We conduct comprehensive experiments over a collection of real and synthetic datasets for the nearest neighbor search task. Experimental results demonstrate that FastLSH is on par with the state-of-the-arts in terms of answer quality, space occupation and query efficiency, while enjoying up to 80x speedup in hash function evaluation. We believe that FastLSH is a promising alternative to the classic LSH scheme.
Accelerating Deep Neural Networks via Semi-Structured Activation Sparsity
Sep 27, 2023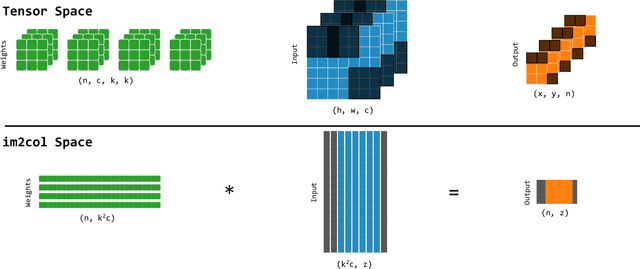
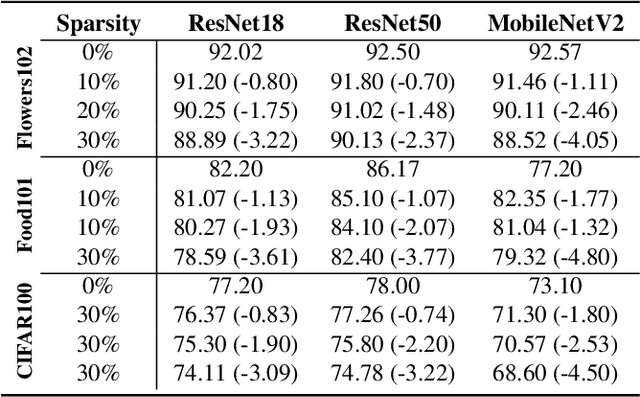
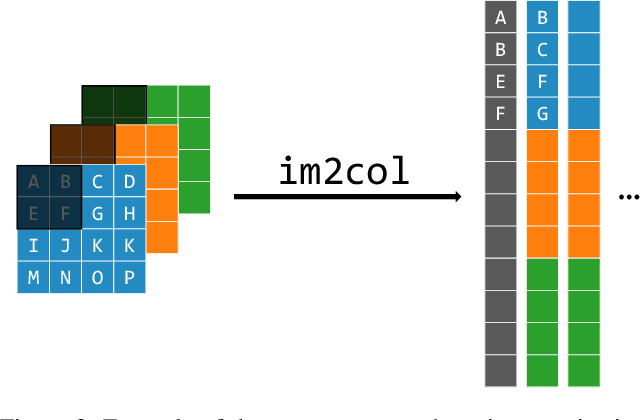
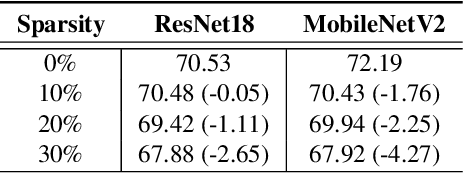
The demand for efficient processing of deep neural networks (DNNs) on embedded devices is a significant challenge limiting their deployment. Exploiting sparsity in the network's feature maps is one of the ways to reduce its inference latency. It is known that unstructured sparsity results in lower accuracy degradation with respect to structured sparsity but the former needs extensive inference engine changes to get latency benefits. To tackle this challenge, we propose a solution to induce semi-structured activation sparsity exploitable through minor runtime modifications. To attain high speedup levels at inference time, we design a sparse training procedure with awareness of the final position of the activations while computing the General Matrix Multiplication (GEMM). We extensively evaluate the proposed solution across various models for image classification and object detection tasks. Remarkably, our approach yields a speed improvement of $1.25 \times$ with a minimal accuracy drop of $1.1\%$ for the ResNet18 model on the ImageNet dataset. Furthermore, when combined with a state-of-the-art structured pruning method, the resulting models provide a good latency-accuracy trade-off, outperforming models that solely employ structured pruning techniques.
Unveiling Fairness Biases in Deep Learning-Based Brain MRI Reconstruction
Sep 25, 2023Deep learning (DL) reconstruction particularly of MRI has led to improvements in image fidelity and reduction of acquisition time. In neuroimaging, DL methods can reconstruct high-quality images from undersampled data. However, it is essential to consider fairness in DL algorithms, particularly in terms of demographic characteristics. This study presents the first fairness analysis in a DL-based brain MRI reconstruction model. The model utilises the U-Net architecture for image reconstruction and explores the presence and sources of unfairness by implementing baseline Empirical Risk Minimisation (ERM) and rebalancing strategies. Model performance is evaluated using image reconstruction metrics. Our findings reveal statistically significant performance biases between the gender and age subgroups. Surprisingly, data imbalance and training discrimination are not the main sources of bias. This analysis provides insights of fairness in DL-based image reconstruction and aims to improve equity in medical AI applications.
Anomaly Detection in Power Generation Plants with Generative Adversarial Networks
Sep 30, 2023Anomaly detection is a critical task that involves the identification of data points that deviate from a predefined pattern, useful for fraud detection and related activities. Various techniques are employed for anomaly detection, but recent research indicates that deep learning methods, with their ability to discern intricate data patterns, are well-suited for this task. This study explores the use of Generative Adversarial Networks (GANs) for anomaly detection in power generation plants. The dataset used in this investigation comprises fuel consumption records obtained from power generation plants operated by a telecommunications company. The data was initially collected in response to observed irregularities in the fuel consumption patterns of the generating sets situated at the company's base stations. The dataset was divided into anomalous and normal data points based on specific variables, with 64.88% classified as normal and 35.12% as anomalous. An analysis of feature importance, employing the random forest classifier, revealed that Running Time Per Day exhibited the highest relative importance. A GANs model was trained and fine-tuned both with and without data augmentation, with the goal of increasing the dataset size to enhance performance. The generator model consisted of five dense layers using the tanh activation function, while the discriminator comprised six dense layers, each integrated with a dropout layer to prevent overfitting. Following data augmentation, the model achieved an accuracy rate of 98.99%, compared to 66.45% before augmentation. This demonstrates that the model nearly perfectly classified data points into normal and anomalous categories, with the augmented data significantly enhancing the GANs' performance in anomaly detection. Consequently, this study recommends the use of GANs, particularly when using large datasets, for effective anomaly detection.
Pick Planning Strategies for Large-Scale Package Manipulation
Sep 23, 2023
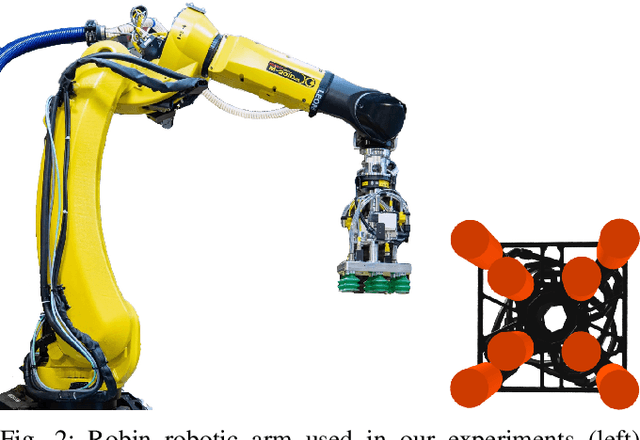

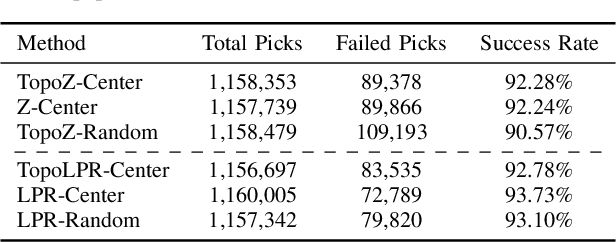
Automating warehouse operations can reduce logistics overhead costs, ultimately driving down the final price for consumers, increasing the speed of delivery, and enhancing the resiliency to market fluctuations. This extended abstract showcases a large-scale package manipulation from unstructured piles in Amazon Robotics' Robot Induction (Robin) fleet, which is used for picking and singulating up to 6 million packages per day and so far has manipulated over 2 billion packages. It describes the various heuristic methods developed over time and their successor, which utilizes a pick success predictor trained on real production data. To the best of the authors' knowledge, this work is the first large-scale deployment of learned pick quality estimation methods in a real production system.
Monitoring Machine Learning Models: Online Detection of Relevant Deviations
Sep 26, 2023Machine learning models are essential tools in various domains, but their performance can degrade over time due to changes in data distribution or other factors. On one hand, detecting and addressing such degradations is crucial for maintaining the models' reliability. On the other hand, given enough data, any arbitrary small change of quality can be detected. As interventions, such as model re-training or replacement, can be expensive, we argue that they should only be carried out when changes exceed a given threshold. We propose a sequential monitoring scheme to detect these relevant changes. The proposed method reduces unnecessary alerts and overcomes the multiple testing problem by accounting for temporal dependence of the measured model quality. Conditions for consistency and specified asymptotic levels are provided. Empirical validation using simulated and real data demonstrates the superiority of our approach in detecting relevant changes in model quality compared to benchmark methods. Our research contributes a practical solution for distinguishing between minor fluctuations and meaningful degradations in machine learning model performance, ensuring their reliability in dynamic environments.