 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Connecting Control to Perception: High-Performance Whole-Body Collision Avoidance Using Control-Compatible Obstacles
Sep 13, 2023
One of the most important aspects of autonomous systems is safety. This includes ensuring safe human-robot and safe robot-environment interaction when autonomously performing complex tasks or in collaborative scenarios. Although several methods have been introduced to tackle this, most are unsuitable for real-time applications and require carefully hand-crafted obstacle descriptions. In this work, we propose a method combining high-frequency and real-time self and environment collision avoidance of a robotic manipulator with low-frequency, multimodal, and high-resolution environmental perceptions accumulated in a digital twin system. Our method is based on geometric primitives, so-called primitive skeletons. These, in turn, are information-compressed and real-time compatible digital representations of the robot's body and environment, automatically generated from ultra-realistic virtual replicas of the real world provided by the digital twin. Our approach is a key enabler for closing the loop between environment perception and robot control by providing the millisecond real-time control stage with a current and accurate world description, empowering it to react to environmental changes. We evaluate our whole-body collision avoidance on a 9-DOFs robot system through five experiments, demonstrating the functionality and efficiency of our framework.
Development of a Deep Learning Method to Identify Acute Ischemic Stroke Lesions on Brain CT
Sep 29, 2023
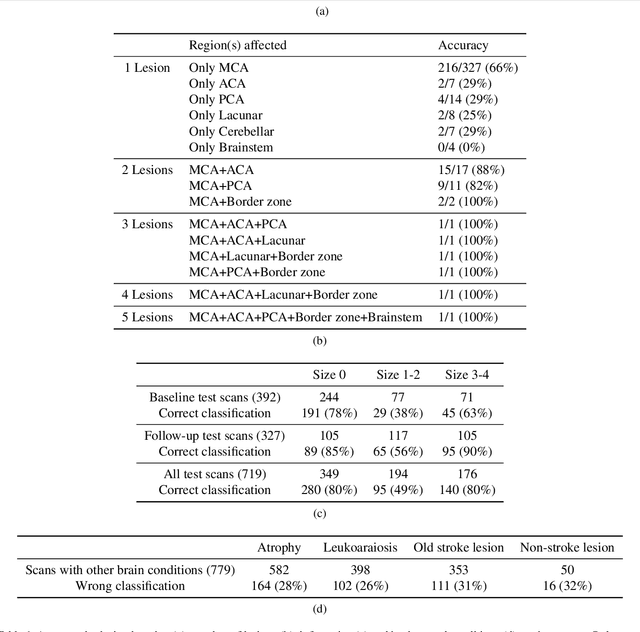
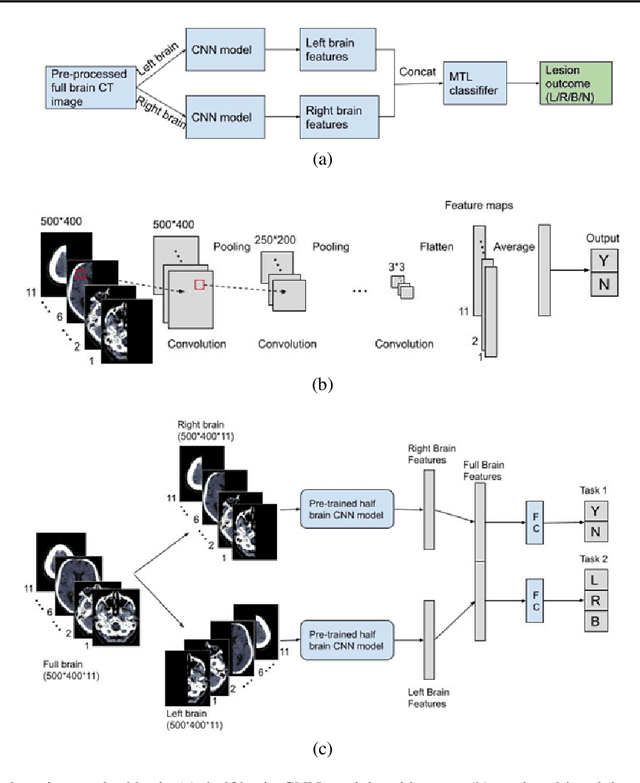
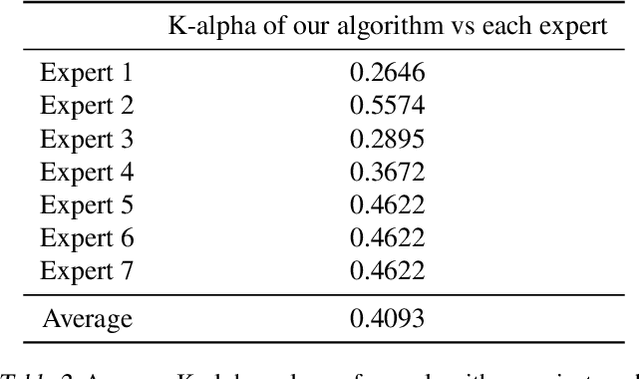
Computed Tomography (CT) is commonly used to image acute ischemic stroke (AIS) patients, but its interpretation by radiologists is time-consuming and subject to inter-observer variability. Deep learning (DL) techniques can provide automated CT brain scan assessment, but usually require annotated images. Aiming to develop a DL method for AIS using labelled but not annotated CT brain scans from patients with AIS, we designed a convolutional neural network-based DL algorithm using routinely-collected CT brain scans from the Third International Stroke Trial (IST-3), which were not acquired using strict research protocols. The DL model aimed to detect AIS lesions and classify the side of the brain affected. We explored the impact of AIS lesion features, background brain appearances, and timing on DL performance. From 5772 unique CT scans of 2347 AIS patients (median age 82), 54% had visible AIS lesions according to expert labelling. Our best-performing DL method achieved 72% accuracy for lesion presence and side. Lesions that were larger (80% accuracy) or multiple (87% accuracy for two lesions, 100% for three or more), were better detected. Follow-up scans had 76% accuracy, while baseline scans 67% accuracy. Chronic brain conditions reduced accuracy, particularly non-stroke lesions and old stroke lesions (32% and 31% error rates respectively). DL methods can be designed for AIS lesion detection on CT using the vast quantities of routinely-collected CT brain scan data. Ultimately, this should lead to more robust and widely-applicable methods.
DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation
Sep 29, 2023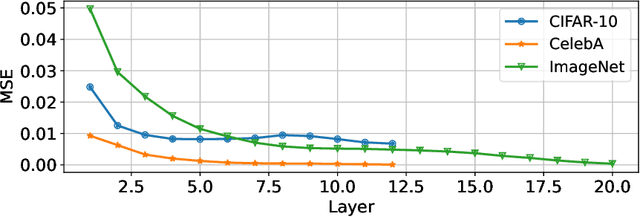
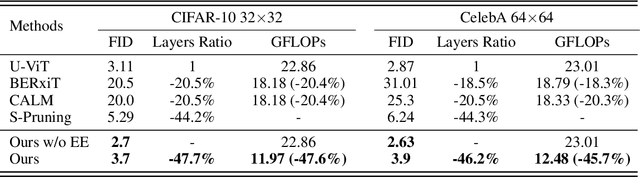
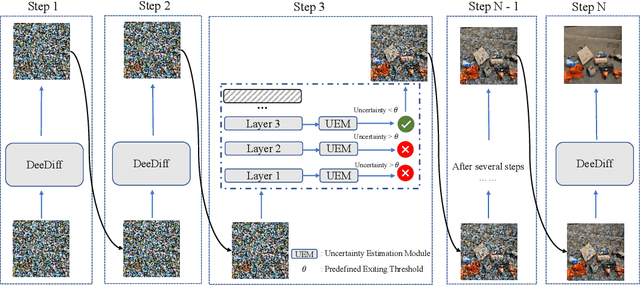
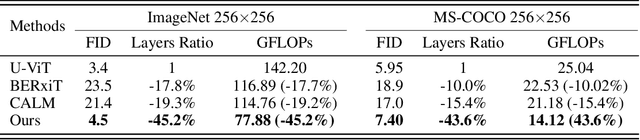
Diffusion models achieve great success in generating diverse and high-fidelity images. The performance improvements come with low generation speed per image, which hinders the application diffusion models in real-time scenarios. While some certain predictions benefit from the full computation of the model in each sample iteration, not every iteration requires the same amount of computation, potentially leading to computation waste. In this work, we propose DeeDiff, an early exiting framework that adaptively allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Specifically, we introduce a timestep-aware uncertainty estimation module (UEM) for diffusion models which is attached to each intermediate layer to estimate the prediction uncertainty of each layer. The uncertainty is regarded as the signal to decide if the inference terminates. Moreover, we propose uncertainty-aware layer-wise loss to fill the performance gap between full models and early-exited models. With such loss strategy, our model is able to obtain comparable results as full-layer models. Extensive experiments of class-conditional, unconditional, and text-guided generation on several datasets show that our method achieves state-of-the-art performance and efficiency trade-off compared with existing early exiting methods on diffusion models. More importantly, our method even brings extra benefits to baseline models and obtains better performance on CIFAR-10 and Celeb-A datasets. Full code and model are released for reproduction.
Diverse Data Augmentation with Diffusions for Effective Test-time Prompt Tuning
Aug 11, 2023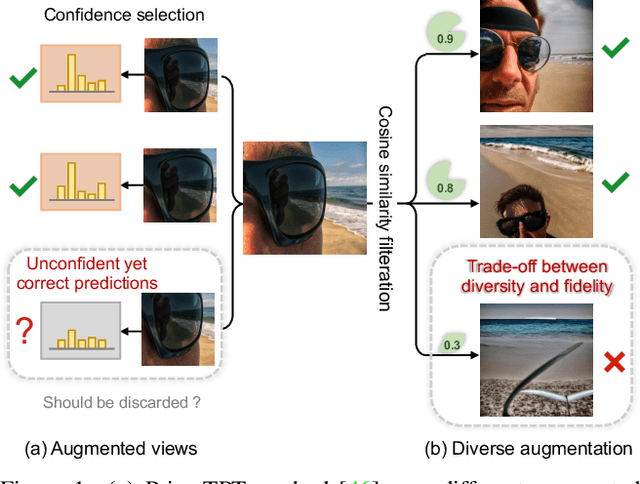
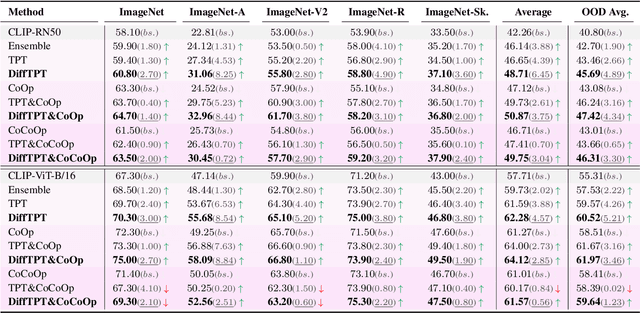
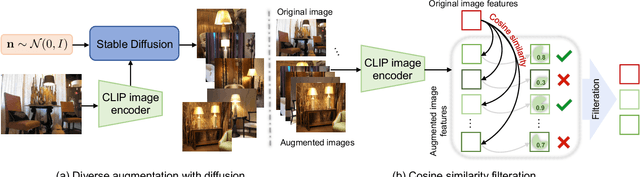
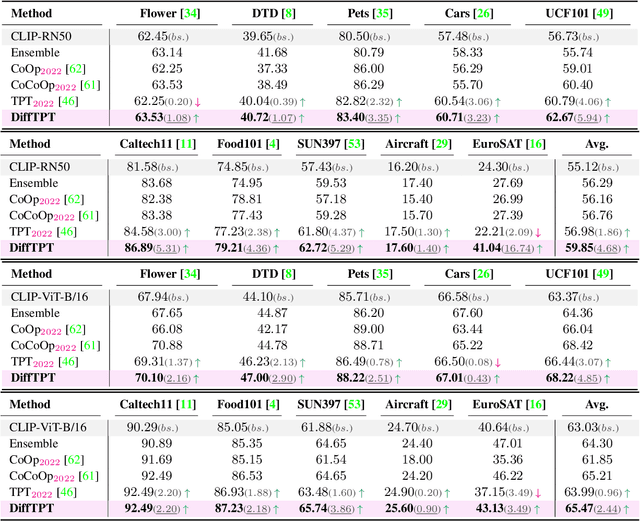
Benefiting from prompt tuning, recent years have witnessed the promising performance of pre-trained vision-language models, e.g., CLIP, on versatile downstream tasks. In this paper, we focus on a particular setting of learning adaptive prompts on the fly for each test sample from an unseen new domain, which is known as test-time prompt tuning (TPT). Existing TPT methods typically rely on data augmentation and confidence selection. However, conventional data augmentation techniques, e.g., random resized crops, suffers from the lack of data diversity, while entropy-based confidence selection alone is not sufficient to guarantee prediction fidelity. To address these issues, we propose a novel TPT method, named DiffTPT, which leverages pre-trained diffusion models to generate diverse and informative new data. Specifically, we incorporate augmented data by both conventional method and pre-trained stable diffusion to exploit their respective merits, improving the models ability to adapt to unknown new test data. Moreover, to ensure the prediction fidelity of generated data, we introduce a cosine similarity-based filtration technique to select the generated data with higher similarity to the single test sample. Our experiments on test datasets with distribution shifts and unseen categories demonstrate that DiffTPT improves the zero-shot accuracy by an average of 5.13\% compared to the state-of-the-art TPT method. Our code and models will be publicly released.
Sequential Multi-Dimensional Self-Supervised Learning for Clinical Time Series
Jul 20, 2023

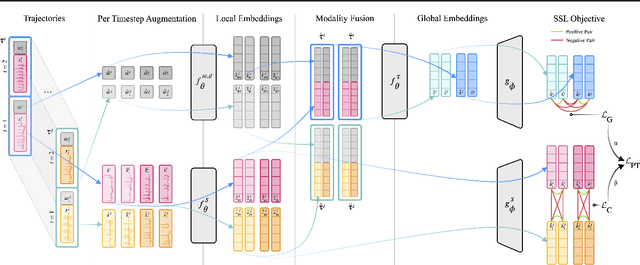
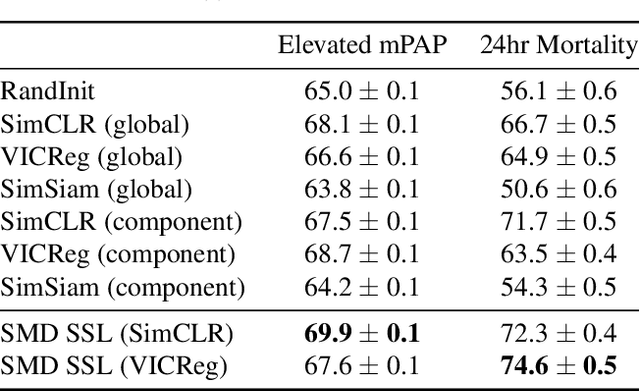
Self-supervised learning (SSL) for clinical time series data has received significant attention in recent literature, since these data are highly rich and provide important information about a patient's physiological state. However, most existing SSL methods for clinical time series are limited in that they are designed for unimodal time series, such as a sequence of structured features (e.g., lab values and vitals signs) or an individual high-dimensional physiological signal (e.g., an electrocardiogram). These existing methods cannot be readily extended to model time series that exhibit multimodality, with structured features and high-dimensional data being recorded at each timestep in the sequence. In this work, we address this gap and propose a new SSL method -- Sequential Multi-Dimensional SSL -- where a SSL loss is applied both at the level of the entire sequence and at the level of the individual high-dimensional data points in the sequence in order to better capture information at both scales. Our strategy is agnostic to the specific form of loss function used at each level -- it can be contrastive, as in SimCLR, or non-contrastive, as in VICReg. We evaluate our method on two real-world clinical datasets, where the time series contains sequences of (1) high-frequency electrocardiograms and (2) structured data from lab values and vitals signs. Our experimental results indicate that pre-training with our method and then fine-tuning on downstream tasks improves performance over baselines on both datasets, and in several settings, can lead to improvements across different self-supervised loss functions.
Anomaly Detection in Power Generation Plants with Generative Adversarial Networks
Sep 30, 2023Anomaly detection is a critical task that involves the identification of data points that deviate from a predefined pattern, useful for fraud detection and related activities. Various techniques are employed for anomaly detection, but recent research indicates that deep learning methods, with their ability to discern intricate data patterns, are well-suited for this task. This study explores the use of Generative Adversarial Networks (GANs) for anomaly detection in power generation plants. The dataset used in this investigation comprises fuel consumption records obtained from power generation plants operated by a telecommunications company. The data was initially collected in response to observed irregularities in the fuel consumption patterns of the generating sets situated at the company's base stations. The dataset was divided into anomalous and normal data points based on specific variables, with 64.88% classified as normal and 35.12% as anomalous. An analysis of feature importance, employing the random forest classifier, revealed that Running Time Per Day exhibited the highest relative importance. A GANs model was trained and fine-tuned both with and without data augmentation, with the goal of increasing the dataset size to enhance performance. The generator model consisted of five dense layers using the tanh activation function, while the discriminator comprised six dense layers, each integrated with a dropout layer to prevent overfitting. Following data augmentation, the model achieved an accuracy rate of 98.99%, compared to 66.45% before augmentation. This demonstrates that the model nearly perfectly classified data points into normal and anomalous categories, with the augmented data significantly enhancing the GANs' performance in anomaly detection. Consequently, this study recommends the use of GANs, particularly when using large datasets, for effective anomaly detection.
Hybrid Genetic Search for Dynamic Vehicle Routing with Time Windows
Jul 26, 2023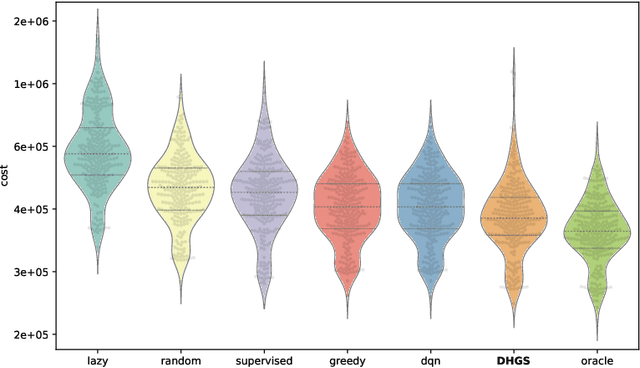
The dynamic vehicle routing problem with time windows (DVRPTW) is a generalization of the classical VRPTW to an online setting, where customer data arrives in batches and real-time routing solutions are required. In this paper we adapt the Hybrid Genetic Search (HGS) algorithm, a successful heuristic for VRPTW, to the dynamic variant. We discuss the affected components of the HGS algorithm including giant-tour representation, cost computation, initial population, crossover, and local search. Our approach modifies these components for DVRPTW, attempting to balance solution quality and constraints on future customer arrivals. To this end, we devise methods for comparing different-sized solutions, normalizing costs, and accounting for future epochs that do not require any prior training. Despite this limitation, computational results on data from the EURO meets NeurIPS Vehicle Routing Competition 2022 demonstrate significantly improved solution quality over the best-performing baseline algorithm.
Exploring IoT for real-time CO2 monitoring and analysis
Aug 02, 2023As a part of this project, we have developed an IoT-based instrument utilizing the NODE MCU-ESP8266 module, MQ135 gas sensor, and DHT-11 sensor for measuring CO$_2$ levels in parts per million (ppm), temperature, and humidity. The escalating CO$_2$ levels worldwide necessitate constant monitoring and analysis to comprehend the implications for human health, safety, energy efficiency, and environmental well-being. Thus, an efficient and cost-effective solution is imperative to measure and transmit data for statistical analysis and storage. The instrument offers real-time monitoring, enabling a comprehensive understanding of indoor environmental conditions. By providing valuable insights, it facilitates the implementation of measures to ensure health and safety, optimize energy efficiency, and promote effective environmental monitoring. This scientific endeavor aims to contribute to the growing body of knowledge surrounding CO$_2$ levels, temperature, and humidity, fostering sustainable practices and informed decision-making
Music Source Separation Based on a Lightweight Deep Learning Framework (DTTNET: DUAL-PATH TFC-TDF UNET)
Sep 15, 2023Music source separation (MSS) aims to extract 'vocals', 'drums', 'bass' and 'other' tracks from a piece of mixed music. While deep learning methods have shown impressive results, there is a trend toward larger models. In our paper, we introduce a novel and lightweight architecture called DTTNet, which is based on Dual-Path Module and Time-Frequency Convolutions Time-Distributed Fully-connected UNet (TFC-TDF UNet). DTTNet achieves 10.12 dB cSDR on 'vocals' compared to 10.01 dB reported for Bandsplit RNN (BSRNN) but with 86.7% fewer parameters. We also assess pattern-specific performance and model generalization for intricate audio patterns.
Fast Locality Sensitive Hashing with Theoretical Guarantee
Sep 27, 2023Locality-sensitive hashing (LSH) is an effective randomized technique widely used in many machine learning tasks. The cost of hashing is proportional to data dimensions, and thus often the performance bottleneck when dimensionality is high and the number of hash functions involved is large. Surprisingly, however, little work has been done to improve the efficiency of LSH computation. In this paper, we design a simple yet efficient LSH scheme, named FastLSH, under l2 norm. By combining random sampling and random projection, FastLSH reduces the time complexity from O(n) to O(m) (m<n), where n is the data dimensionality and m is the number of sampled dimensions. Moreover, FastLSH has provable LSH property, which distinguishes it from the non-LSH fast sketches. We conduct comprehensive experiments over a collection of real and synthetic datasets for the nearest neighbor search task. Experimental results demonstrate that FastLSH is on par with the state-of-the-arts in terms of answer quality, space occupation and query efficiency, while enjoying up to 80x speedup in hash function evaluation. We believe that FastLSH is a promising alternative to the classic LSH scheme.