 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spectro-spatial hyperspectral image reconstruction from interferometric acquisitions
Oct 03, 2023
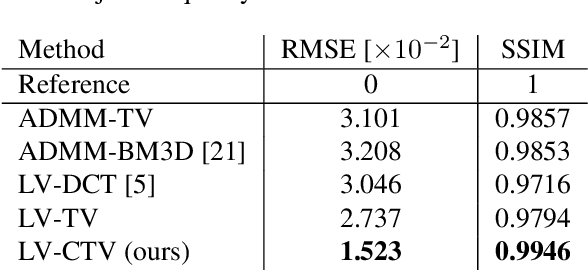

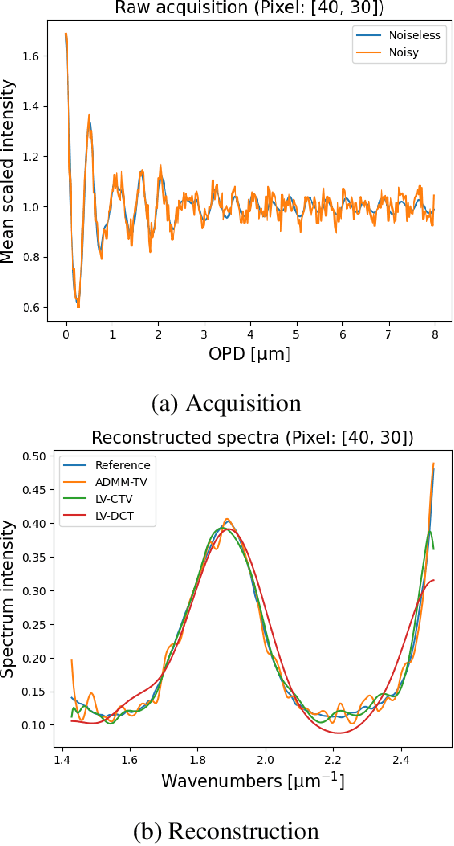
In the last decade, novel hyperspectral cameras have been developed with particularly desirable characteristics of compactness and short acquisition time, retaining their potential to obtain spectral/spatial resolution competitive with respect to traditional cameras. However, a computational effort is required to recover an interpretable data cube. In this work we focus our attention on imaging spectrometers based on interferometry, for which the raw acquisition is an image whose spectral component is expressed as an interferogram. Previous works have focused on the inversion of such acquisition on a pixel-by-pixel basis within a Bayesian framework, leaving behind critical information on the spatial structure of the image data cube. In this work, we address this problem by integrating a spatial regularization for image reconstruction, showing that the combination of spectral and spatial regularizers leads to enhanced performances with respect to the pixelwise case. We compare our results with Plug-and-Play techniques, as its strategy to inject a set of denoisers from the literature can be implemented seamlessly with our physics-based formulation of the optimization problem.
Swin-Tempo: Temporal-Aware Lung Nodule Detection in CT Scans as Video Sequences Using Swin Transformer-Enhanced UNet
Oct 05, 2023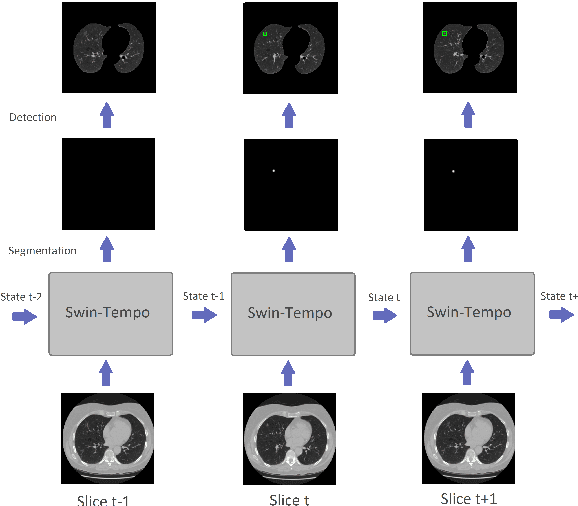

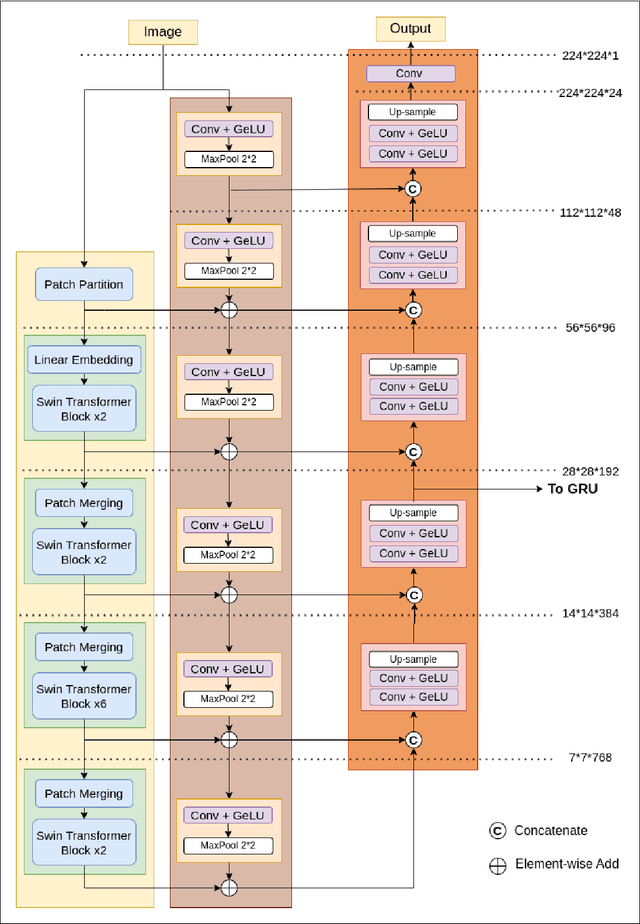
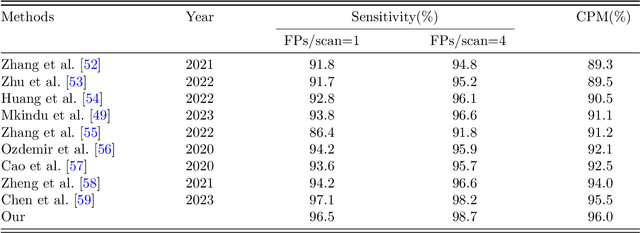
Lung cancer is highly lethal, emphasizing the critical need for early detection. However, identifying lung nodules poses significant challenges for radiologists, who rely heavily on their expertise and experience for accurate diagnosis. To address this issue, computer-aided diagnosis systems based on machine learning techniques have emerged to assist doctors in identifying lung nodules from computed tomography (CT) scans. Unfortunately, existing networks in this domain often suffer from computational complexity, leading to high rates of false negatives and false positives, limiting their effectiveness. To address these challenges, we present an innovative model that harnesses the strengths of both convolutional neural networks and vision transformers. Inspired by object detection in videos, we treat each 3D CT image as a video, individual slices as frames, and lung nodules as objects, enabling a time-series application. The primary objective of our work is to overcome hardware limitations during model training, allowing for efficient processing of 2D data while utilizing inter-slice information for accurate identification based on 3D image context. We validated the proposed network by applying a 10-fold cross-validation technique to the publicly available Lung Nodule Analysis 2016 dataset. Our proposed architecture achieves an average sensitivity criterion of 97.84% and a competition performance metrics (CPM) of 96.0% with few parameters. Comparative analysis with state-of-the-art advancements in lung nodule identification demonstrates the significant accuracy achieved by our proposed model.
Design Optimizer for Planar Soft-Growing Robot Manipulators
Oct 05, 2023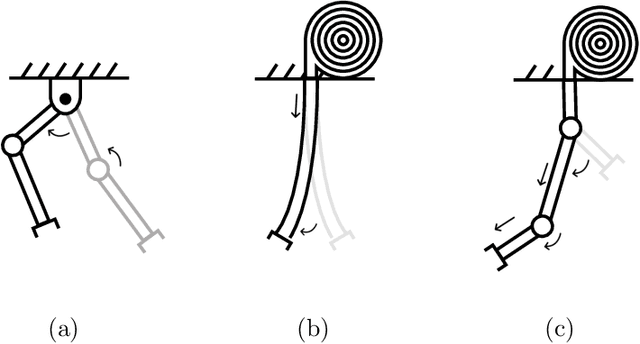
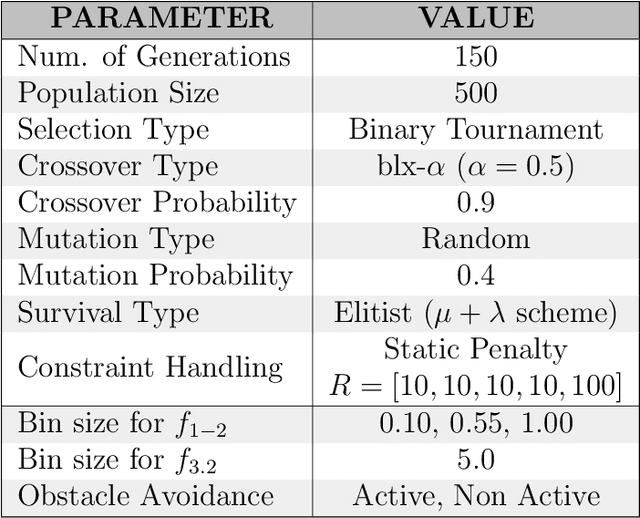
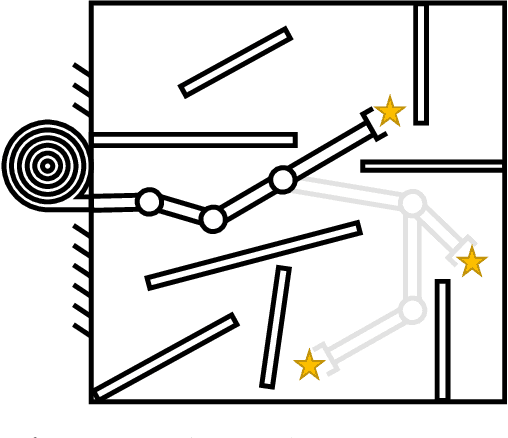
Soft-growing robots are innovative devices that feature plant-inspired growth to navigate environments. Thanks to their embodied intelligence of adapting to their surroundings and the latest innovation in actuation and manufacturing, it is possible to employ them for specific manipulation tasks. The applications of these devices include exploration of delicate/dangerous environments, manipulation of items, or assistance in domestic environments. This work presents a novel approach for design optimization of soft-growing robots, which will be used prior to manufacturing to suggest engineers -- or robot designer enthusiasts -- the optimal dimension of the robot to be built for solving a specific task. I modeled the design process as a multi-objective optimization problem, in which I optimize the kinematic chain of a soft manipulator to reach targets and avoid unnecessary overuse of material and resources. The method exploits the advantages of population-based optimization algorithms, in particular evolutionary algorithms, to transform the problem from multi-objective into a single-objective thanks to an efficient mathematical formulation, the novel rank-partitioning algorithm, and obstacle avoidance integrated within the optimizer operators. I tested the proposed method on different tasks to access its optimality, which showed significant performance in solving the problem. Finally, comparative experiments showed that the proposed method works better than the one existing in the literature in terms of precision, resource consumption, and run time.
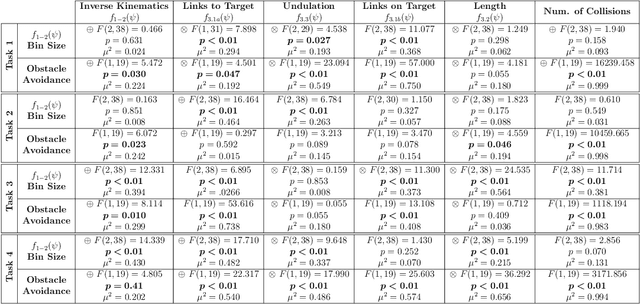
LightSeq: Sequence Level Parallelism for Distributed Training of Long Context Transformers
Oct 05, 2023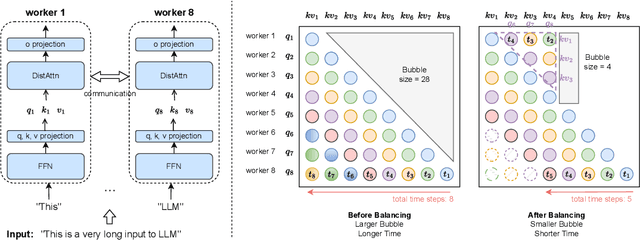
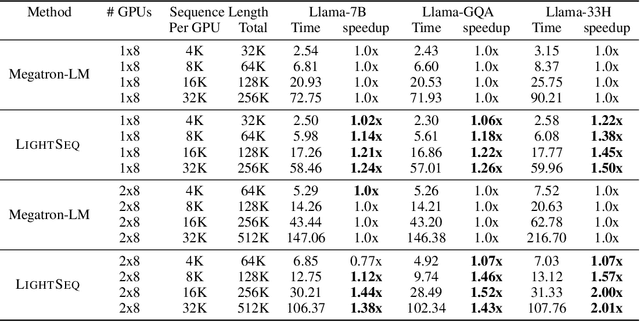


Increasing the context length of large language models (LLMs) unlocks fundamentally new capabilities, but also significantly increases the memory footprints of training. Previous model-parallel systems such as Megatron-LM partition and compute different attention heads in parallel, resulting in large communication volumes, so they cannot scale beyond the number of attention heads, thereby hindering its adoption. In this paper, we introduce a new approach, LightSeq, for long-context LLMs training. LightSeq has many notable advantages. First, LightSeq partitions over the sequence dimension, hence is agnostic to model architectures and readily applicable for models with varying numbers of attention heads, such as Multi-Head, Multi-Query and Grouped-Query attention. Second, LightSeq not only requires up to 4.7x less communication than Megatron-LM on popular LLMs but also overlaps the communication with computation. To further reduce the training time, LightSeq features a novel gradient checkpointing scheme to bypass an forward computation for memory-efficient attention. We evaluate LightSeq on Llama-7B and its variants with sequence lengths from 32K to 512K. Through comprehensive experiments on single and cross-node training, we show that LightSeq achieves up to 1.24-2.01x end-to-end speedup, and a 2-8x longer sequence length on models with fewer heads, compared to Megatron-LM. Codes will be available at https://github.com/RulinShao/LightSeq.
A New Dialogue Response Generation Agent for Large Language Models by Asking Questions to Detect User's Intentions
Oct 05, 2023Large Language Models (LLMs), such as ChatGPT, have recently been applied to various NLP tasks due to its open-domain generation capabilities. However, there are two issues with applying LLMs to dialogue tasks. 1. During the dialogue process, users may have implicit intentions that might be overlooked by LLMs. Consequently, generated responses couldn't align with the user's intentions. 2. It is unlikely for LLMs to encompass all fields comprehensively. In certain specific domains, their knowledge may be incomplete, and LLMs cannot update the latest knowledge in real-time. To tackle these issues, we propose a framework~\emph{using LLM to \textbf{E}nhance dialogue response generation by asking questions to \textbf{D}etect user's \textbf{I}mplicit in\textbf{T}entions} (\textbf{EDIT}). Firstly, EDIT generates open questions related to the dialogue context as the potential user's intention; Then, EDIT answers those questions by interacting with LLMs and searching in domain-specific knowledge bases respectively, and use LLMs to choose the proper answers to questions as extra knowledge; Finally, EDIT enhances response generation by explicitly integrating those extra knowledge. Besides, previous question generation works only focus on asking questions with answers in context. In order to ask open questions, we construct a Context-Open-Question (COQ) dataset. On two task-oriented dialogue tasks (Wizard of Wikipedia and Holl-E), EDIT outperformed other LLMs.
Impact of Artificial Intelligence on Electrical and Electronics Engineering Productivity in the Construction Industry
Oct 05, 2023
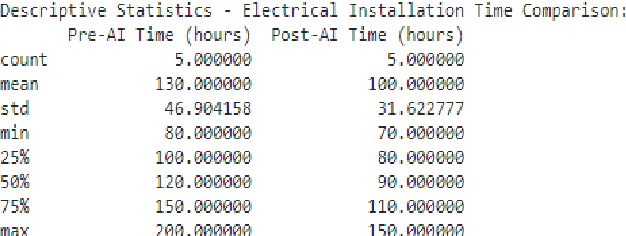
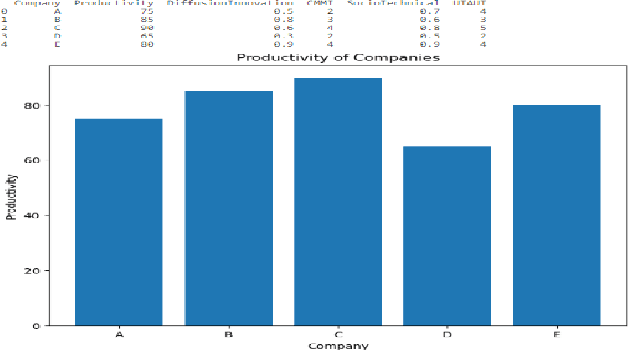
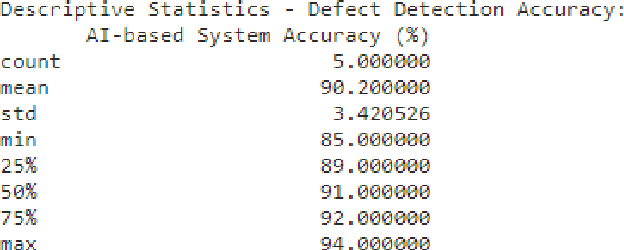
Artificial intelligence (AI) can revolutionize the development industry, primarily electrical and electronics engineering. By automating recurring duties, AI can grow productivity and efficiency in creating. For instance, AI can research constructing designs, discover capability troubles, and generate answers, reducing the effort and time required for manual analysis. AI also can be used to optimize electricity consumption in buildings, which is a critical difficulty in the construction enterprise. Via machines gaining knowledge of algorithms to investigate electricity usage patterns, AI can discover areas wherein power may be stored and offer guidelines for enhancements. This can result in significant value financial savings and reduced carbon emissions. Moreover, AI may be used to improve the protection of creation websites. By studying statistics from sensors and cameras, AI can locate capacity dangers and alert workers to take suitable action. This could help save you from injuries and accidents on production sites, lowering the chance for workers and enhancing overall safety in the enterprise. The impact of AI on electric and electronics engineering productivity inside the creation industry is enormous. AI can transform how we layout, build, and function buildings by automating ordinary duties, optimising electricity intake, and enhancing safety. However, ensuring that AI is used ethically and responsibly and that the advantages are shared fairly throughout the enterprise is essential.
Deep Model Predictive Optimization
Oct 06, 2023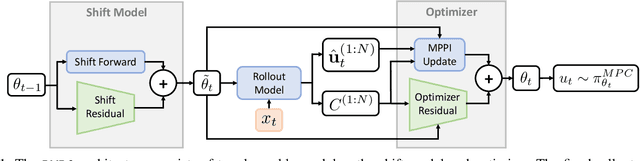
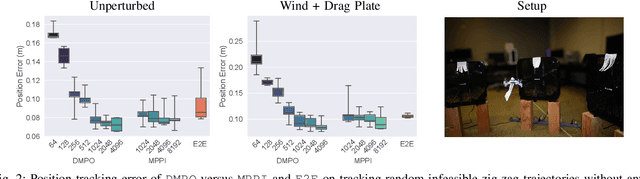

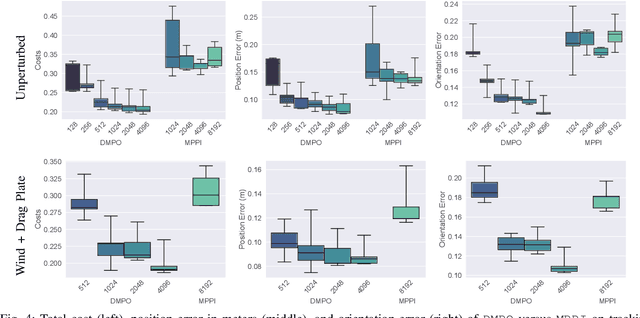
A major challenge in robotics is to design robust policies which enable complex and agile behaviors in the real world. On one end of the spectrum, we have model-free reinforcement learning (MFRL), which is incredibly flexible and general but often results in brittle policies. In contrast, model predictive control (MPC) continually re-plans at each time step to remain robust to perturbations and model inaccuracies. However, despite its real-world successes, MPC often under-performs the optimal strategy. This is due to model quality, myopic behavior from short planning horizons, and approximations due to computational constraints. And even with a perfect model and enough compute, MPC can get stuck in bad local optima, depending heavily on the quality of the optimization algorithm. To this end, we propose Deep Model Predictive Optimization (DMPO), which learns the inner-loop of an MPC optimization algorithm directly via experience, specifically tailored to the needs of the control problem. We evaluate DMPO on a real quadrotor agile trajectory tracking task, on which it improves performance over a baseline MPC algorithm for a given computational budget. It can outperform the best MPC algorithm by up to 27% with fewer samples and an end-to-end policy trained with MFRL by 19%. Moreover, because DMPO requires fewer samples, it can also achieve these benefits with 4.3X less memory. When we subject the quadrotor to turbulent wind fields with an attached drag plate, DMPO can adapt zero-shot while still outperforming all baselines. Additional results can be found at https://tinyurl.com/mr2ywmnw.
A Topological Perspective on Demystifying GNN-Based Link Prediction Performance
Oct 06, 2023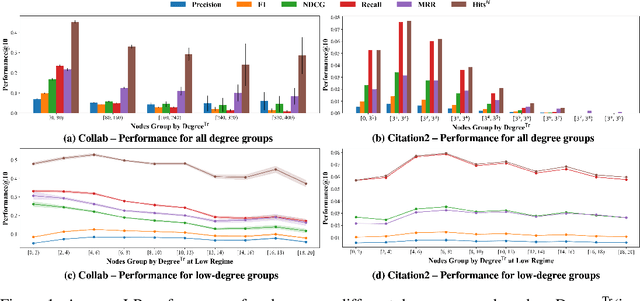
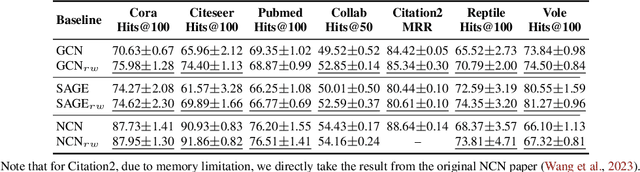
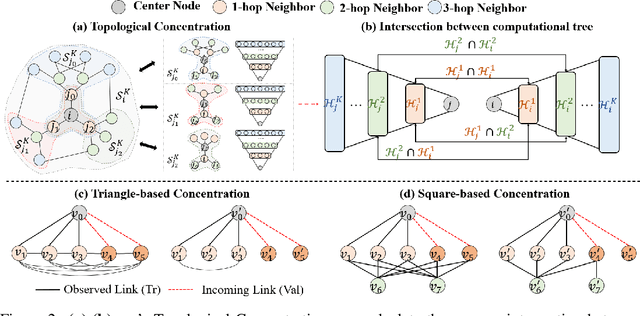
Graph Neural Networks (GNNs) have shown great promise in learning node embeddings for link prediction (LP). While numerous studies aim to improve the overall LP performance of GNNs, none have explored its varying performance across different nodes and its underlying reasons. To this end, we aim to demystify which nodes will perform better from the perspective of their local topology. Despite the widespread belief that low-degree nodes exhibit poorer LP performance, our empirical findings provide nuances to this viewpoint and prompt us to propose a better metric, Topological Concentration (TC), based on the intersection of the local subgraph of each node with the ones of its neighbors. We empirically demonstrate that TC has a higher correlation with LP performance than other node-level topological metrics like degree and subgraph density, offering a better way to identify low-performing nodes than using cold-start. With TC, we discover a novel topological distribution shift issue in which newly joined neighbors of a node tend to become less interactive with that node's existing neighbors, compromising the generalizability of node embeddings for LP at testing time. To make the computation of TC scalable, We further propose Approximated Topological Concentration (ATC) and theoretically/empirically justify its efficacy in approximating TC and reducing the computation complexity. Given the positive correlation between node TC and its LP performance, we explore the potential of boosting LP performance via enhancing TC by re-weighting edges in the message-passing and discuss its effectiveness with limitations. Our code is publicly available at https://github.com/YuWVandy/Topo_LP_GNN.
Disentangle then Parse:Night-time Semantic Segmentation with Illumination Disentanglement
Jul 19, 2023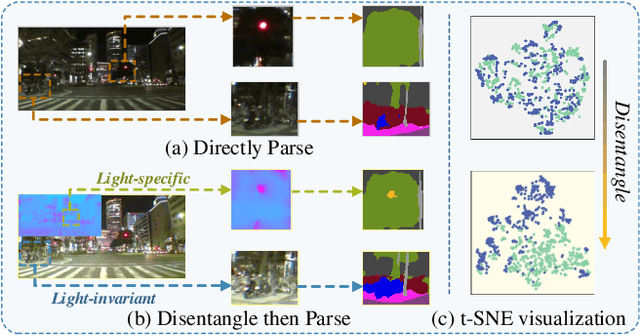
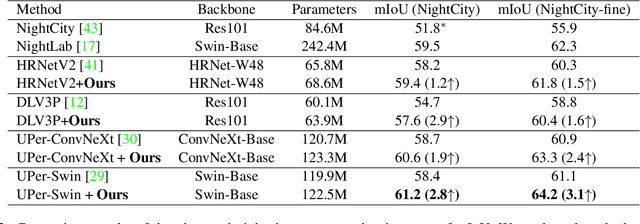
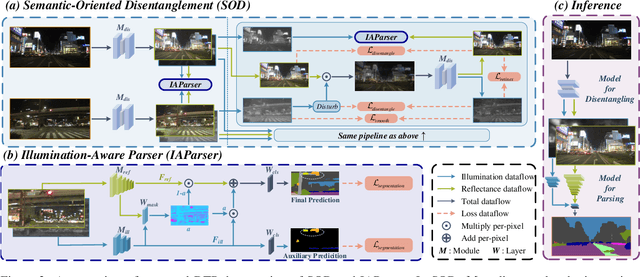
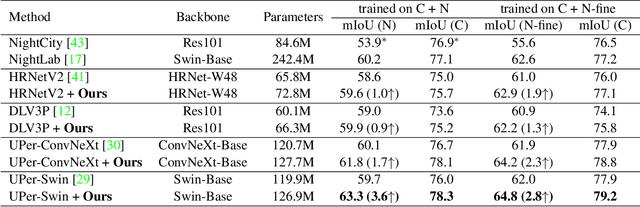
Most prior semantic segmentation methods have been developed for day-time scenes, while typically underperforming in night-time scenes due to insufficient and complicated lighting conditions. In this work, we tackle this challenge by proposing a novel night-time semantic segmentation paradigm, i.e., disentangle then parse (DTP). DTP explicitly disentangles night-time images into light-invariant reflectance and light-specific illumination components and then recognizes semantics based on their adaptive fusion. Concretely, the proposed DTP comprises two key components: 1) Instead of processing lighting-entangled features as in prior works, our Semantic-Oriented Disentanglement (SOD) framework enables the extraction of reflectance component without being impeded by lighting, allowing the network to consistently recognize the semantics under cover of varying and complicated lighting conditions. 2) Based on the observation that the illumination component can serve as a cue for some semantically confused regions, we further introduce an Illumination-Aware Parser (IAParser) to explicitly learn the correlation between semantics and lighting, and aggregate the illumination features to yield more precise predictions. Extensive experiments on the night-time segmentation task with various settings demonstrate that DTP significantly outperforms state-of-the-art methods. Furthermore, with negligible additional parameters, DTP can be directly used to benefit existing day-time methods for night-time segmentation.
Leveraging Cutting Edge Deep Learning Based Image Matching for Reconstructing a Large Scene from Sparse Images
Oct 02, 2023We present the top ranked solution for the AISG-SLA Visual Localisation Challenge benchmark (IJCAI 2023), where the task is to estimate relative motion between images taken in sequence by a camera mounted on a car driving through an urban scene. For matching images we use our recent deep learning based matcher RoMa. Matching image pairs sequentially and estimating relative motion from point correspondences sampled by RoMa already gives very competitive results -- third rank on the challenge benchmark. To improve the estimations we extract keypoints in the images, match them using RoMa, and perform structure from motion reconstruction using COLMAP. We choose our recent DeDoDe keypoints for their high repeatability. Further, we address time jumps in the image sequence by matching specific non-consecutive image pairs based on image retrieval with DINOv2. These improvements yield a solution beating all competitors. We further present a loose upper bound on the accuracy obtainable by the image retrieval approach by also matching hand-picked non-consecutive pairs.