 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Guided Distant Supervision for Multilingual Relation Extraction Data: Adapting to a New Language
Mar 27, 2024
Relation extraction is essential for extracting and understanding biographical information in the context of digital humanities and related subjects. There is a growing interest in the community to build datasets capable of training machine learning models to extract relationships. However, annotating such datasets can be expensive and time-consuming, in addition to being limited to English. This paper applies guided distant supervision to create a large biographical relationship extraction dataset for German. Our dataset, composed of more than 80,000 instances for nine relationship types, is the largest biographical German relationship extraction dataset. We also create a manually annotated dataset with 2000 instances to evaluate the models and release it together with the dataset compiled using guided distant supervision. We train several state-of-the-art machine learning models on the automatically created dataset and release them as well. Furthermore, we experiment with multilingual and cross-lingual experiments that could benefit many low-resource languages.
Semi-Supervised Learning for Deep Causal Generative Models
Mar 27, 2024Developing models that can answer questions of the form "How would $x$ change if $y$ had been $z$?" is fundamental for advancing medical image analysis. Training causal generative models that address such counterfactual questions, though, currently requires that all relevant variables have been observed and that corresponding labels are available in training data. However, clinical data may not have complete records for all patients and state of the art causal generative models are unable to take full advantage of this. We thus develop, for the first time, a semi-supervised deep causal generative model that exploits the causal relationships between variables to maximise the use of all available data. We explore this in the setting where each sample is either fully labelled or fully unlabelled, as well as the more clinically realistic case of having different labels missing for each sample. We leverage techniques from causal inference to infer missing values and subsequently generate realistic counterfactuals, even for samples with incomplete labels.
FTBC: Forward Temporal Bias Correction for Optimizing ANN-SNN Conversion
Mar 27, 2024Spiking Neural Networks (SNNs) offer a promising avenue for energy-efficient computing compared with Artificial Neural Networks (ANNs), closely mirroring biological neural processes. However, this potential comes with inherent challenges in directly training SNNs through spatio-temporal backpropagation -- stemming from the temporal dynamics of spiking neurons and their discrete signal processing -- which necessitates alternative ways of training, most notably through ANN-SNN conversion. In this work, we introduce a lightweight Forward Temporal Bias Correction (FTBC) technique, aimed at enhancing conversion accuracy without the computational overhead. We ground our method on provided theoretical findings that through proper temporal bias calibration the expected error of ANN-SNN conversion can be reduced to be zero after each time step. We further propose a heuristic algorithm for finding the temporal bias only in the forward pass, thus eliminating the computational burden of backpropagation and we evaluate our method on CIFAR-10/100 and ImageNet datasets, achieving a notable increase in accuracy on all datasets. Codes are released at a GitHub repository.
High Recall, Small Data: The Challenges of Within-System Evaluation in a Live Legal Search System
Mar 27, 2024This paper illustrates some challenges of common ranking evaluation methods for legal information retrieval (IR). We show these challenges with log data from a live legal search system and two user studies. We provide an overview of aspects of legal IR, and the implications of these aspects for the expected challenges of common evaluation methods: test collections based on explicit and implicit feedback, user surveys, and A/B testing. Next, we illustrate the challenges of common evaluation methods using data from a live, commercial, legal search engine. We specifically focus on methods for monitoring the effectiveness of (continuous) changes to document ranking by a single IR system over time. We show how the combination of characteristics in legal IR systems and limited user data can lead to challenges that cause the common evaluation methods discussed to be sub-optimal. In our future work we will therefore focus on less common evaluation methods, such as cost-based evaluation models.
Illicit object detection in X-ray images using Vision Transformers
Mar 27, 2024Illicit object detection is a critical task performed at various high-security locations, including airports, train stations, subways, and ports. The continuous and tedious work of examining thousands of X-ray images per hour can be mentally taxing. Thus, Deep Neural Networks (DNNs) can be used to automate the X-ray image analysis process, improve efficiency and alleviate the security officers' inspection burden. The neural architectures typically utilized in relevant literature are Convolutional Neural Networks (CNNs), with Vision Transformers (ViTs) rarely employed. In order to address this gap, this paper conducts a comprehensive evaluation of relevant ViT architectures on illicit item detection in X-ray images. This study utilizes both Transformer and hybrid backbones, such as SWIN and NextViT, and detectors, such as DINO and RT-DETR. The results demonstrate the remarkable accuracy of the DINO Transformer detector in the low-data regime, the impressive real-time performance of YOLOv8, and the effectiveness of the hybrid NextViT backbone.
Enriching Word Usage Graphs with Cluster Definitions
Mar 26, 2024We present a dataset of word usage graphs (WUGs), where the existing WUGs for multiple languages are enriched with cluster labels functioning as sense definitions. They are generated from scratch by fine-tuned encoder-decoder language models. The conducted human evaluation has shown that these definitions match the existing clusters in WUGs better than the definitions chosen from WordNet by two baseline systems. At the same time, the method is straightforward to use and easy to extend to new languages. The resulting enriched datasets can be extremely helpful for moving on to explainable semantic change modeling.
Speeding Up Path Planning via Reinforcement Learning in MCTS for Automated Parking
Mar 25, 2024In this paper, we address a method that integrates reinforcement learning into the Monte Carlo tree search to boost online path planning under fully observable environments for automated parking tasks. Sampling-based planning methods under high-dimensional space can be computationally expensive and time-consuming. State evaluation methods are useful by leveraging the prior knowledge into the search steps, making the process faster in a real-time system. Given the fact that automated parking tasks are often executed under complex environments, a solid but lightweight heuristic guidance is challenging to compose in a traditional analytical way. To overcome this limitation, we propose a reinforcement learning pipeline with a Monte Carlo tree search under the path planning framework. By iteratively learning the value of a state and the best action among samples from its previous cycle's outcomes, we are able to model a value estimator and a policy generator for given states. By doing that, we build up a balancing mechanism between exploration and exploitation, speeding up the path planning process while maintaining its quality without using human expert driver data.
Spike-NeRF: Neural Radiance Field Based On Spike Camera
Mar 25, 2024As a neuromorphic sensor with high temporal resolution, spike cameras offer notable advantages over traditional cameras in high-speed vision applications such as high-speed optical estimation, depth estimation, and object tracking. Inspired by the success of the spike camera, we proposed Spike-NeRF, the first Neural Radiance Field derived from spike data, to achieve 3D reconstruction and novel viewpoint synthesis of high-speed scenes. Instead of the multi-view images at the same time of NeRF, the inputs of Spike-NeRF are continuous spike streams captured by a moving spike camera in a very short time. To reconstruct a correct and stable 3D scene from high-frequency but unstable spike data, we devised spike masks along with a distinctive loss function. We evaluate our method qualitatively and numerically on several challenging synthetic scenes generated by blender with the spike camera simulator. Our results demonstrate that Spike-NeRF produces more visually appealing results than the existing methods and the baseline we proposed in high-speed scenes. Our code and data will be released soon.
CATS: Enhancing Multivariate Time Series Forecasting by Constructing Auxiliary Time Series as Exogenous Variables
Mar 04, 2024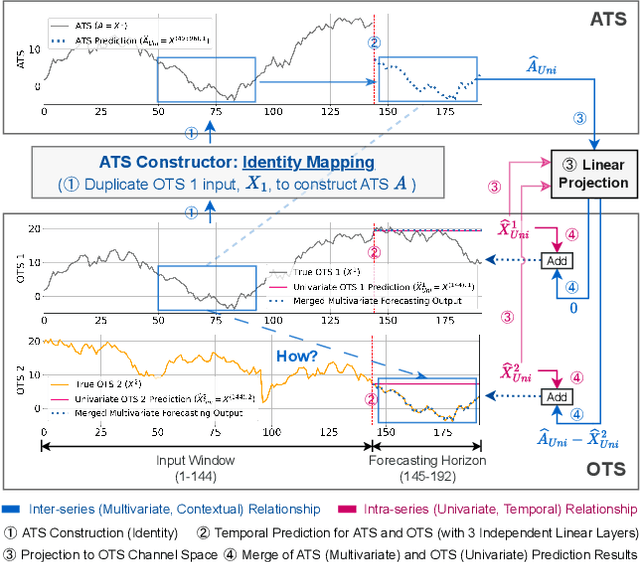
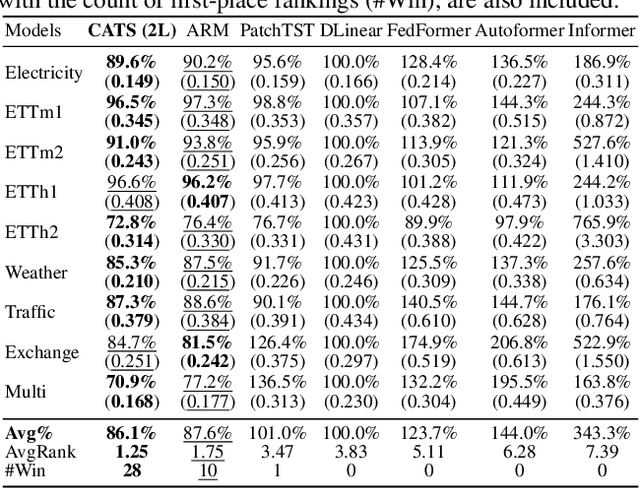
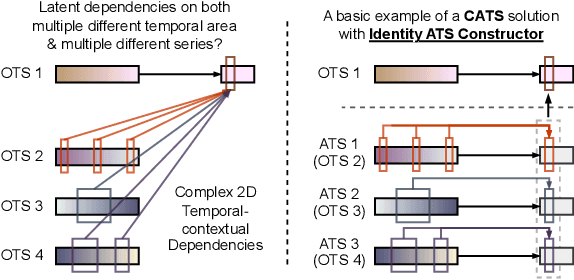
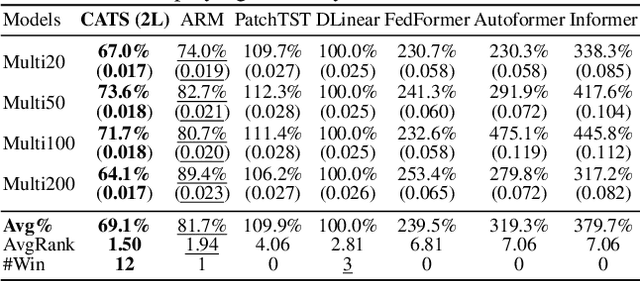
For Multivariate Time Series Forecasting (MTSF), recent deep learning applications show that univariate models frequently outperform multivariate ones. To address the difficiency in multivariate models, we introduce a method to Construct Auxiliary Time Series (CATS) that functions like a 2D temporal-contextual attention mechanism, which generates Auxiliary Time Series (ATS) from Original Time Series (OTS) to effectively represent and incorporate inter-series relationships for forecasting. Key principles of ATS - continuity, sparsity, and variability - are identified and implemented through different modules. Even with a basic 2-layer MLP as core predictor, CATS achieves state-of-the-art, significantly reducing complexity and parameters compared to previous multivariate models, marking it an efficient and transferable MTSF solution.
Artificial Intelligence (AI) Based Prediction of Mortality, for COVID-19 Patients
Mar 28, 2024For severely affected COVID-19 patients, it is crucial to identify high-risk patients and predict survival and need for intensive care (ICU). Most of the proposed models are not well reported making them less reproducible and prone to high risk of bias particularly in presence of imbalance data/class. In this study, the performances of nine machine and deep learning algorithms in combination with two widely used feature selection methods were investigated to predict last status representing mortality, ICU requirement, and ventilation days. Fivefold cross-validation was used for training and validation purposes. To minimize bias, the training and testing sets were split maintaining similar distributions. Only 10 out of 122 features were found to be useful in prediction modelling with Acute kidney injury during hospitalization feature being the most important one. The algorithms performances depend on feature numbers and data pre-processing techniques. LSTM performs the best in predicting last status and ICU requirement with 90%, 92%, 86% and 95% accuracy, sensitivity, specificity, and AUC respectively. DNN performs the best in predicting Ventilation days with 88% accuracy. Considering all the factors and limitations including absence of exact time point of clinical onset, LSTM with carefully selected features can accurately predict last status and ICU requirement. DNN performs the best in predicting Ventilation days. Appropriate machine learning algorithm with carefully selected features and balance data can accurately predict mortality, ICU requirement and ventilation support. Such model can be very useful in emergency and pandemic where prompt and precise