 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Encountered-Type Haptic Display via Tracking Calibrated Robot
Sep 28, 2023
In the past decades, a variety of haptic devices have been developed to facilitate high-fidelity human-computer interaction (HCI) in virtual reality (VR). In particular, passive haptic feedback can create a compelling sensation based on real objects spatially overlapping with their virtual counterparts. However, these approaches require pre-deployment efforts, hindering their democratizing use in practice. We propose the Tracking Calibrated Robot (TCR), a novel and general haptic approach to free developers from deployment efforts, which can be potentially deployed in any scenario. Specifically, we augment the VR with a collaborative robot that renders haptic contact in the real world while the user touches a virtual object in the virtual world. The distance between the user's finger and the robot end-effector is controlled over time. The distance starts to smoothly reduce to zero when the user intends to touch the virtual object. A mock user study tested users' perception of three virtual objects, and the result shows that TCR is effective in terms of conveying discriminative shape information.
CaveSeg: Deep Semantic Segmentation and Scene Parsing for Autonomous Underwater Cave Exploration
Sep 28, 2023
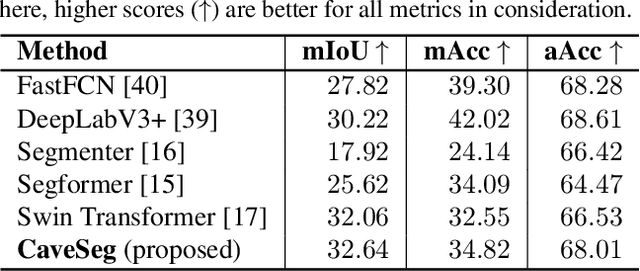

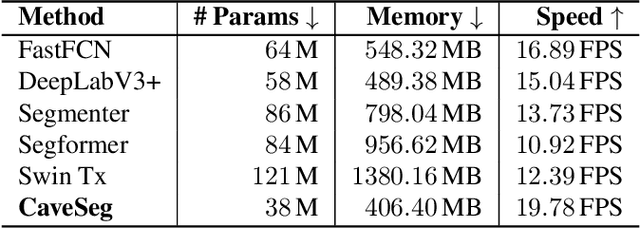
In this paper, we present CaveSeg - the first visual learning pipeline for semantic segmentation and scene parsing for AUV navigation inside underwater caves. We address the problem of scarce annotated training data by preparing a comprehensive dataset for semantic segmentation of underwater cave scenes. It contains pixel annotations for important navigation markers (e.g. caveline, arrows), obstacles (e.g. ground plain and overhead layers), scuba divers, and open areas for servoing. Through comprehensive benchmark analyses on cave systems in USA, Mexico, and Spain locations, we demonstrate that robust deep visual models can be developed based on CaveSeg for fast semantic scene parsing of underwater cave environments. In particular, we formulate a novel transformer-based model that is computationally light and offers near real-time execution in addition to achieving state-of-the-art performance. Finally, we explore the design choices and implications of semantic segmentation for visual servoing by AUVs inside underwater caves. The proposed model and benchmark dataset open up promising opportunities for future research in autonomous underwater cave exploration and mapping.
Adaptation of the super resolution SOTA for Art Restoration in camera capture images
Sep 28, 2023



Preserving cultural heritage is of paramount importance. In the domain of art restoration, developing a computer vision model capable of effectively restoring deteriorated images of art pieces was difficult, but now we have a good computer vision state-of-art. Traditional restoration methods are often time-consuming and require extensive expertise. The aim of this work is to design an automated solution based on computer vision models that can enhance and reconstruct degraded artworks, improving their visual quality while preserving their original characteristics and artifacts. The model should handle a diverse range of deterioration types, including but not limited to noise, blur, scratches, fading, and other common forms of degradation. We adapt the current state-of-art for the image super-resolution based on the Diffusion Model (DM) and fine-tune it for Image art restoration. Our results show that instead of fine-tunning multiple different models for different kinds of degradation, fine-tuning one super-resolution. We train it on multiple datasets to make it robust. code link: https://github.com/Naagar/art_restoration_DM
Learning to Transform for Generalizable Instance-wise Invariance
Sep 28, 2023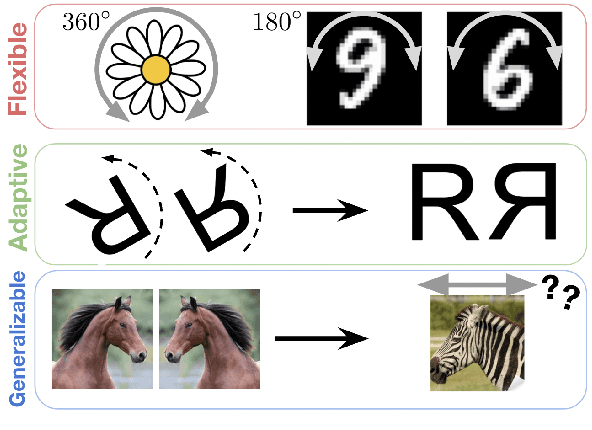
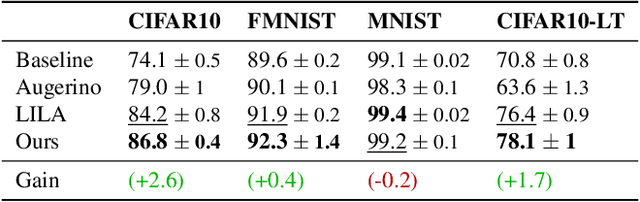
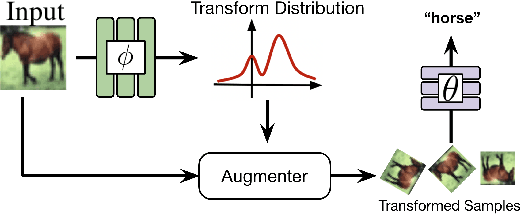

Computer vision research has long aimed to build systems that are robust to spatial transformations found in natural data. Traditionally, this is done using data augmentation or hard-coding invariances into the architecture. However, too much or too little invariance can hurt, and the correct amount is unknown a priori and dependent on the instance. Ideally, the appropriate invariance would be learned from data and inferred at test-time. We treat invariance as a prediction problem. Given any image, we use a normalizing flow to predict a distribution over transformations and average the predictions over them. Since this distribution only depends on the instance, we can align instances before classifying them and generalize invariance across classes. The same distribution can also be used to adapt to out-of-distribution poses. This normalizing flow is trained end-to-end and can learn a much larger range of transformations than Augerino and InstaAug. When used as data augmentation, our method shows accuracy and robustness gains on CIFAR 10, CIFAR10-LT, and TinyImageNet.
HIC-YOLOv5: Improved YOLOv5 For Small Object Detection
Sep 28, 2023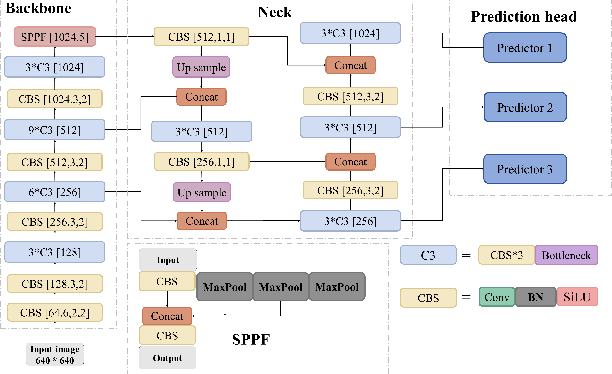
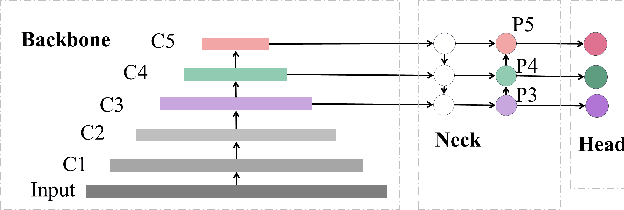
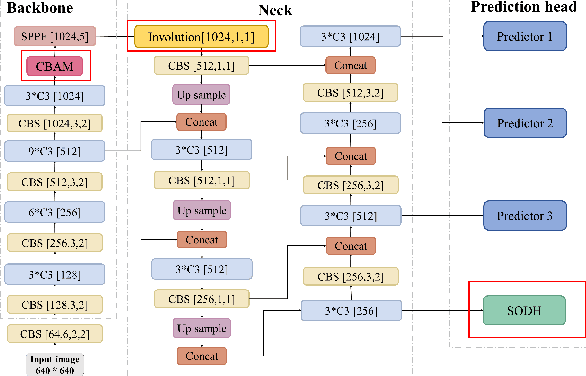
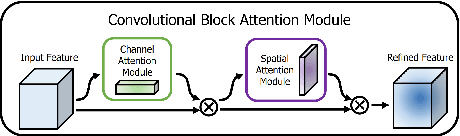
Small object detection has been a challenging problem in the field of object detection. There has been some works that proposes improvements for this task, such as adding several attention blocks or changing the whole structure of feature fusion networks. However, the computation cost of these models is large, which makes deploying a real-time object detection system unfeasible, while leaving room for improvement. To this end, an improved YOLOv5 model: HIC-YOLOv5 is proposed to address the aforementioned problems. Firstly, an additional prediction head specific to small objects is added to provide a higher-resolution feature map for better prediction. Secondly, an involution block is adopted between the backbone and neck to increase channel information of the feature map. Moreover, an attention mechanism named CBAM is applied at the end of the backbone, thus not only decreasing the computation cost compared with previous works but also emphasizing the important information in both channel and spatial domain. Our result shows that HIC-YOLOv5 has improved mAP@[.5:.95] by 6.42% and mAP@0.5 by 9.38% on VisDrone-2019-DET dataset.
MEM: Multi-Modal Elevation Mapping for Robotics and Learning
Sep 28, 2023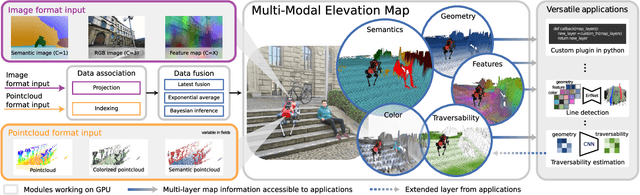
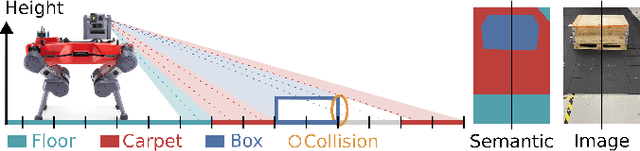
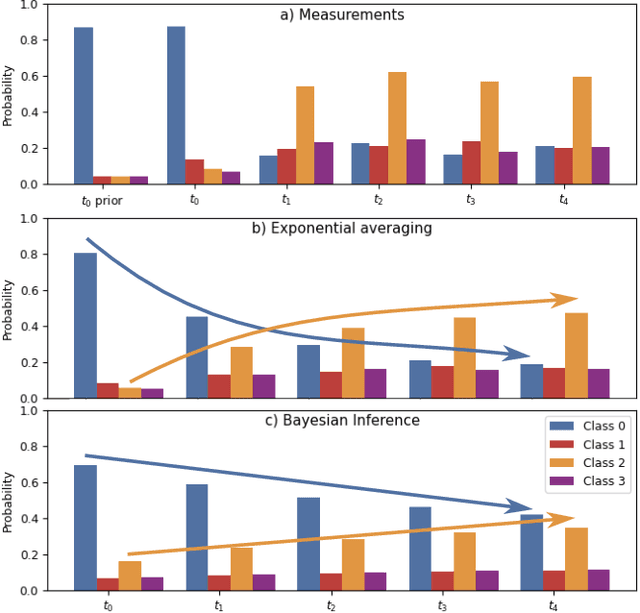
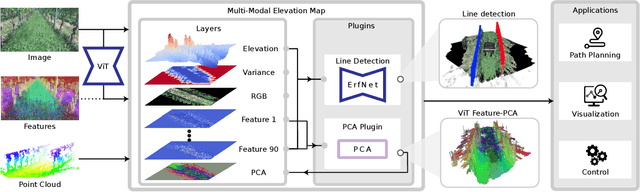
Elevation maps are commonly used to represent the environment of mobile robots and are instrumental for locomotion and navigation tasks. However, pure geometric information is insufficient for many field applications that require appearance or semantic information, which limits their applicability to other platforms or domains. In this work, we extend a 2.5D robot-centric elevation mapping framework by fusing multi-modal information from multiple sources into a popular map representation. The framework allows inputting data contained in point clouds or images in a unified manner. To manage the different nature of the data, we also present a set of fusion algorithms that can be selected based on the information type and user requirements. Our system is designed to run on the GPU, making it real-time capable for various robotic and learning tasks. We demonstrate the capabilities of our framework by deploying it on multiple robots with varying sensor configurations and showcasing a range of applications that utilize multi-modal layers, including line detection, human detection, and colorization.
Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis
Sep 28, 2023NeRFs have enabled highly realistic synthesis of human faces including complex appearance and reflectance effects of hair and skin. These methods typically require a large number of multi-view input images, making the process hardware intensive and cumbersome, limiting applicability to unconstrained settings. We propose a novel volumetric human face prior that enables the synthesis of ultra high-resolution novel views of subjects that are not part of the prior's training distribution. This prior model consists of an identity-conditioned NeRF, trained on a dataset of low-resolution multi-view images of diverse humans with known camera calibration. A simple sparse landmark-based 3D alignment of the training dataset allows our model to learn a smooth latent space of geometry and appearance despite a limited number of training identities. A high-quality volumetric representation of a novel subject can be obtained by model fitting to 2 or 3 camera views of arbitrary resolution. Importantly, our method requires as few as two views of casually captured images as input at inference time.
Deep Single Models vs. Ensembles: Insights for a Fast Deployment of Parking Monitoring Systems
Sep 28, 2023Searching for available parking spots in high-density urban centers is a stressful task for drivers that can be mitigated by systems that know in advance the nearest parking space available. To this end, image-based systems offer cost advantages over other sensor-based alternatives (e.g., ultrasonic sensors), requiring less physical infrastructure for installation and maintenance. Despite recent deep learning advances, deploying intelligent parking monitoring is still a challenge since most approaches involve collecting and labeling large amounts of data, which is laborious and time-consuming. Our study aims to uncover the challenges in creating a global framework, trained using publicly available labeled parking lot images, that performs accurately across diverse scenarios, enabling the parking space monitoring as a ready-to-use system to deploy in a new environment. Through exhaustive experiments involving different datasets and deep learning architectures, including fusion strategies and ensemble methods, we found that models trained on diverse datasets can achieve 95\% accuracy without the burden of data annotation and model training on the target parking lot
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis
Sep 30, 2023
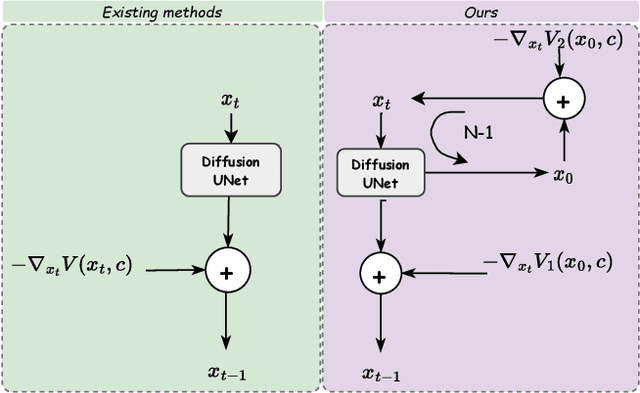
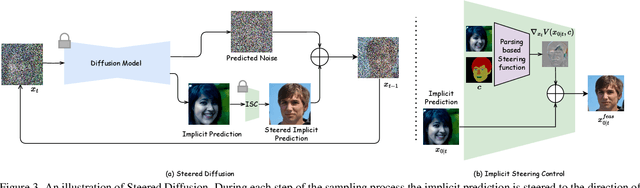
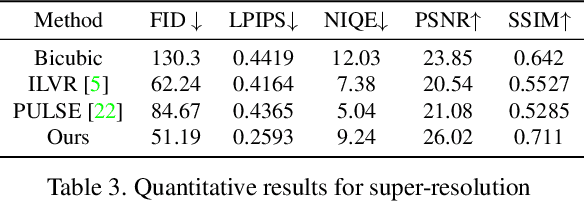
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.
An Investigation of Multi-feature Extraction and Super-resolution with Fast Microphone Arrays
Sep 30, 2023In this work, we use MEMS microphones as vibration sensors to simultaneously classify texture and estimate contact position and velocity. Vibration sensors are an important facet of both human and robotic tactile sensing, providing fast detection of contact and onset of slip. Microphones are an attractive option for implementing vibration sensing as they offer a fast response and can be sampled quickly, are affordable, and occupy a very small footprint. Our prototype sensor uses only a sparse array of distributed MEMS microphones (8-9 mm spacing) embedded under an elastomer. We use transformer-based architectures for data analysis, taking advantage of the microphones' high sampling rate to run our models on time-series data as opposed to individual snapshots. This approach allows us to obtain 77.3% average accuracy on 4-class texture classification (84.2% when excluding the slowest drag velocity), 1.5 mm median error on contact localization, and 4.5 mm/s median error on contact velocity. We show that the learned texture and localization models are robust to varying velocity and generalize to unseen velocities. We also report that our sensor provides fast contact detection, an important advantage of fast transducers. This investigation illustrates the capabilities one can achieve with a MEMS microphone array alone, leaving valuable sensor real estate available for integration with complementary tactile sensing modalities.