 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Differentiable Machine Learning-Based Modeling for Directly-Modulated Lasers
Sep 27, 2023
End-to-end learning has become a popular method for joint transmitter and receiver optimization in optical communication systems. Such approach may require a differentiable channel model, thus hindering the optimization of links based on directly modulated lasers (DMLs). This is due to the DML behavior in the large-signal regime, for which no analytical solution is available. In this paper, this problem is addressed by developing and comparing differentiable machine learning-based surrogate models. The models are quantitatively assessed in terms of root mean square error and training/testing time. Once the models are trained, the surrogates are then tested in a numerical equalization setup, resembling a practical end-to-end scenario. Based on the numerical investigation conducted, the convolutional attention transformer is shown to outperform the other models considered.
Identifying Simulation Model Through Alternative Techniques for a Medical Device Assembly Process
Sep 26, 2023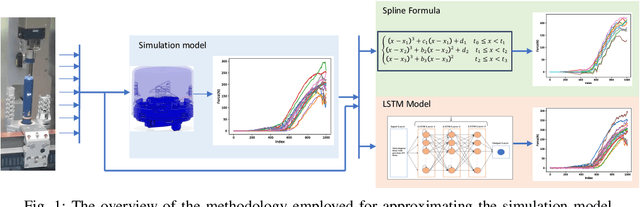
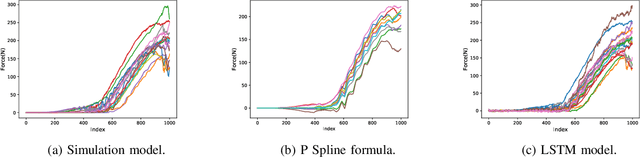
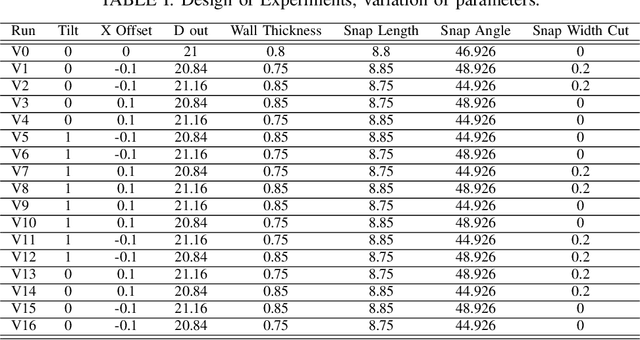

This scientific paper explores two distinct approaches for identifying and approximating the simulation model, particularly in the context of the snap process crucial to medical device assembly. Simulation models play a pivotal role in providing engineers with insights into industrial processes, enabling experimentation and troubleshooting before physical assembly. However, their complexity often results in time-consuming computations. To mitigate this complexity, we present two distinct methods for identifying simulation models: one utilizing Spline functions and the other harnessing Machine Learning (ML) models. Our goal is to create adaptable models that accurately represent the snap process and can accommodate diverse scenarios. Such models hold promise for enhancing process understanding and aiding in decision-making, especially when data availability is limited.
Smooth Nash Equilibria: Algorithms and Complexity
Sep 21, 2023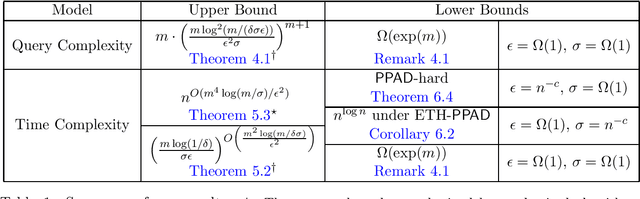
A fundamental shortcoming of the concept of Nash equilibrium is its computational intractability: approximating Nash equilibria in normal-form games is PPAD-hard. In this paper, inspired by the ideas of smoothed analysis, we introduce a relaxed variant of Nash equilibrium called $\sigma$-smooth Nash equilibrium, for a smoothness parameter $\sigma$. In a $\sigma$-smooth Nash equilibrium, players only need to achieve utility at least as high as their best deviation to a $\sigma$-smooth strategy, which is a distribution that does not put too much mass (as parametrized by $\sigma$) on any fixed action. We distinguish two variants of $\sigma$-smooth Nash equilibria: strong $\sigma$-smooth Nash equilibria, in which players are required to play $\sigma$-smooth strategies under equilibrium play, and weak $\sigma$-smooth Nash equilibria, where there is no such requirement. We show that both weak and strong $\sigma$-smooth Nash equilibria have superior computational properties to Nash equilibria: when $\sigma$ as well as an approximation parameter $\epsilon$ and the number of players are all constants, there is a constant-time randomized algorithm to find a weak $\epsilon$-approximate $\sigma$-smooth Nash equilibrium in normal-form games. In the same parameter regime, there is a polynomial-time deterministic algorithm to find a strong $\epsilon$-approximate $\sigma$-smooth Nash equilibrium in a normal-form game. These results stand in contrast to the optimal algorithm for computing $\epsilon$-approximate Nash equilibria, which cannot run in faster than quasipolynomial-time. We complement our upper bounds by showing that when either $\sigma$ or $\epsilon$ is an inverse polynomial, finding a weak $\epsilon$-approximate $\sigma$-smooth Nash equilibria becomes computationally intractable.
Neural Lithography: Close the Design-to-Manufacturing Gap in Computational Optics with a 'Real2Sim' Learned Photolithography Simulator
Sep 29, 2023We introduce neural lithography to address the 'design-to-manufacturing' gap in computational optics. Computational optics with large design degrees of freedom enable advanced functionalities and performance beyond traditional optics. However, the existing design approaches often overlook the numerical modeling of the manufacturing process, which can result in significant performance deviation between the design and the fabricated optics. To bridge this gap, we, for the first time, propose a fully differentiable design framework that integrates a pre-trained photolithography simulator into the model-based optical design loop. Leveraging a blend of physics-informed modeling and data-driven training using experimentally collected datasets, our photolithography simulator serves as a regularizer on fabrication feasibility during design, compensating for structure discrepancies introduced in the lithography process. We demonstrate the effectiveness of our approach through two typical tasks in computational optics, where we design and fabricate a holographic optical element (HOE) and a multi-level diffractive lens (MDL) using a two-photon lithography system, showcasing improved optical performance on the task-specific metrics.
Double-Layer Power Control for Mobile Cell-Free XL-MIMO with Multi-Agent Reinforcement Learning
Sep 29, 2023Cell-free (CF) extremely large-scale multiple-input multiple-output (XL-MIMO) is regarded as a promising technology for enabling future wireless communication systems. Significant attention has been generated by its considerable advantages in augmenting degrees of freedom. In this paper, we first investigate a CF XL-MIMO system with base stations equipped with XL-MIMO panels under a dynamic environment. Then, we propose an innovative multi-agent reinforcement learning (MARL)-based power control algorithm that incorporates predictive management and distributed optimization architecture, which provides a dynamic strategy for addressing high-dimension signal processing problems. Specifically, we compare various MARL-based algorithms, which shows that the proposed MARL-based algorithm effectively strikes a balance between spectral efficiency (SE) performance and convergence time. Moreover, we consider a double-layer power control architecture based on the large-scale fading coefficients between antennas to suppress interference within dynamic systems. Compared to the single-layer architecture, the results obtained unveil that the proposed double-layer architecture has a nearly24% SE performance improvement, especially with massive antennas and smaller antenna spacing.
A Foundation Model for General Moving Object Segmentation in Medical Images
Sep 29, 2023
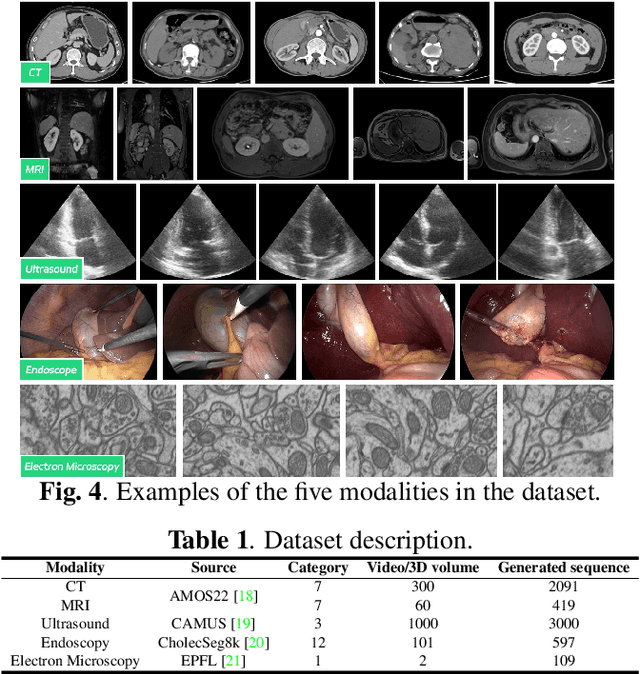
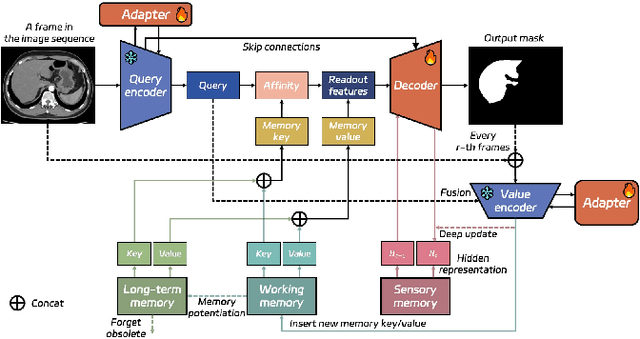
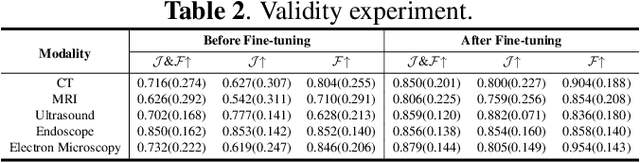
Medical image segmentation aims to delineate the anatomical or pathological structures of interest, playing a crucial role in clinical diagnosis. A substantial amount of high-quality annotated data is crucial for constructing high-precision deep segmentation models. However, medical annotation is highly cumbersome and time-consuming, especially for medical videos or 3D volumes, due to the huge labeling space and poor inter-frame consistency. Recently, a fundamental task named Moving Object Segmentation (MOS) has made significant advancements in natural images. Its objective is to delineate moving objects from the background within image sequences, requiring only minimal annotations. In this paper, we propose the first foundation model, named iMOS, for MOS in medical images. Extensive experiments on a large multi-modal medical dataset validate the effectiveness of the proposed iMOS. Specifically, with the annotation of only a small number of images in the sequence, iMOS can achieve satisfactory tracking and segmentation performance of moving objects throughout the entire sequence in bi-directions. We hope that the proposed iMOS can help accelerate the annotation speed of experts, and boost the development of medical foundation models.
Scalable Multi-Temporal Remote Sensing Change Data Generation via Simulating Stochastic Change Process
Sep 29, 2023Understanding the temporal dynamics of Earth's surface is a mission of multi-temporal remote sensing image analysis, significantly promoted by deep vision models with its fuel -- labeled multi-temporal images. However, collecting, preprocessing, and annotating multi-temporal remote sensing images at scale is non-trivial since it is expensive and knowledge-intensive. In this paper, we present a scalable multi-temporal remote sensing change data generator via generative modeling, which is cheap and automatic, alleviating these problems. Our main idea is to simulate a stochastic change process over time. We consider the stochastic change process as a probabilistic semantic state transition, namely generative probabilistic change model (GPCM), which decouples the complex simulation problem into two more trackable sub-problems, \ie, change event simulation and semantic change synthesis. To solve these two problems, we present the change generator (Changen), a GAN-based GPCM, enabling controllable object change data generation, including customizable object property, and change event. The extensive experiments suggest that our Changen has superior generation capability, and the change detectors with Changen pre-training exhibit excellent transferability to real-world change datasets.
Meta Reinforcement Learning for Fast Spectrum Sharing in Vehicular Networks
Sep 29, 2023In this paper, we investigate the problem of fast spectrum sharing in vehicle-to-everything communication. In order to improve the spectrum efficiency of the whole system, the spectrum of vehicle-to-infrastructure links is reused by vehicle-to-vehicle links. To this end, we model it as a problem of deep reinforcement learning and tackle it with proximal policy optimization. A considerable number of interactions are often required for training an agent with good performance, so simulation-based training is commonly used in communication networks. Nevertheless, severe performance degradation may occur when the agent is directly deployed in the real world, even though it can perform well on the simulator, due to the reality gap between the simulation and the real environments. To address this issue, we make preliminary efforts by proposing an algorithm based on meta reinforcement learning. This algorithm enables the agent to rapidly adapt to a new task with the knowledge extracted from similar tasks, leading to fewer interactions and less training time. Numerical results show that our method achieves near-optimal performance and exhibits rapid convergence.
Networked Inequality: Preferential Attachment Bias in Graph Neural Network Link Prediction
Sep 29, 2023Graph neural network (GNN) link prediction is increasingly deployed in citation, collaboration, and online social networks to recommend academic literature, collaborators, and friends. While prior research has investigated the dyadic fairness of GNN link prediction, the within-group fairness and ``rich get richer'' dynamics of link prediction remain underexplored. However, these aspects have significant consequences for degree and power imbalances in networks. In this paper, we shed light on how degree bias in networks affects Graph Convolutional Network (GCN) link prediction. In particular, we theoretically uncover that GCNs with a symmetric normalized graph filter have a within-group preferential attachment bias. We validate our theoretical analysis on real-world citation, collaboration, and online social networks. We further bridge GCN's preferential attachment bias with unfairness in link prediction and propose a new within-group fairness metric. This metric quantifies disparities in link prediction scores between social groups, towards combating the amplification of degree and power disparities. Finally, we propose a simple training-time strategy to alleviate within-group unfairness, and we show that it is effective on citation, online social, and credit networks.
Reinforcement Learning for Node Selection in Branch-and-Bound
Sep 29, 2023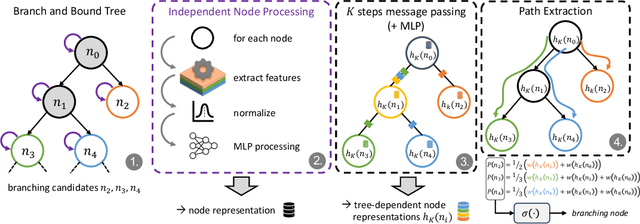


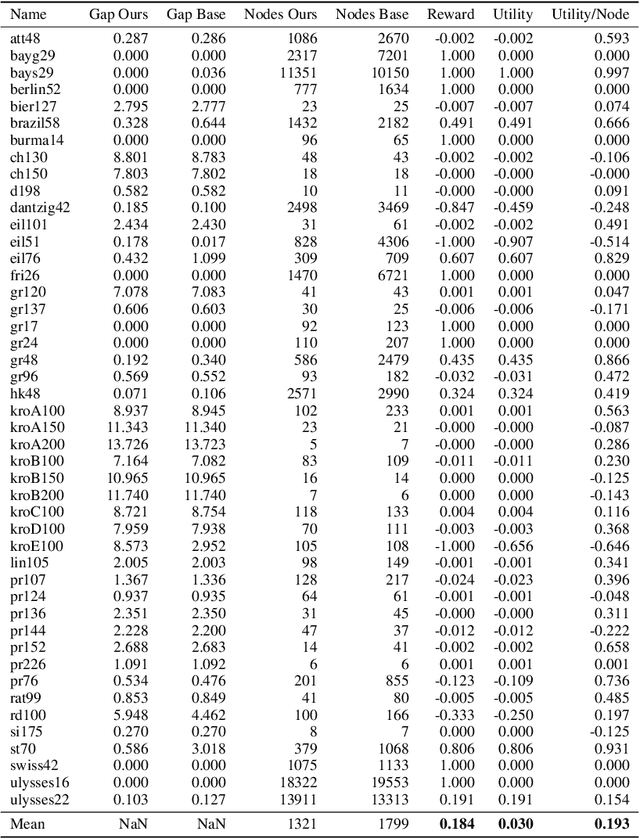
A big challenge in branch and bound lies in identifying the optimal node within the search tree from which to proceed. Current state-of-the-art selectors utilize either hand-crafted ensembles that automatically switch between naive sub-node selectors, or learned node selectors that rely on individual node data. We propose a novel bi-simulation technique that uses reinforcement learning (RL) while considering the entire tree state, rather than just isolated nodes. To achieve this, we train a graph neural network that produces a probability distribution based on the path from the model's root to its ``to-be-selected'' leaves. Modelling node-selection as a probability distribution allows us to train the model using state-of-the-art RL techniques that capture both intrinsic node-quality and node-evaluation costs. Our method induces a high quality node selection policy on a set of varied and complex problem sets, despite only being trained on specially designed, synthetic TSP instances. Experiments on several benchmarks show significant improvements in optimality gap reductions and per-node efficiency under strict time constraints.