 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
Oct 03, 2023
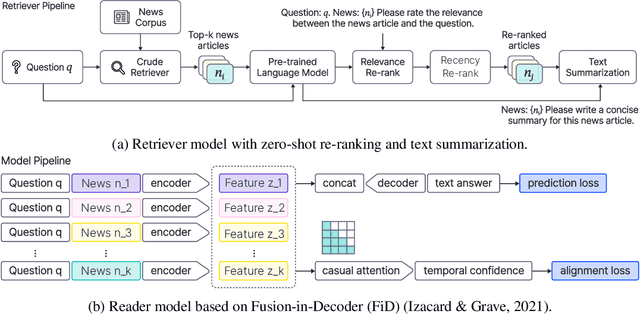
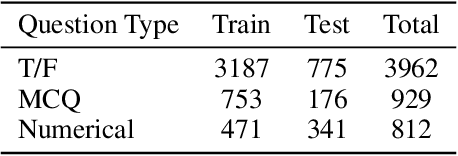
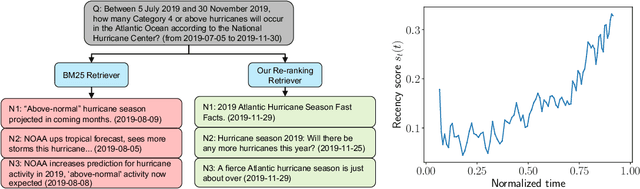
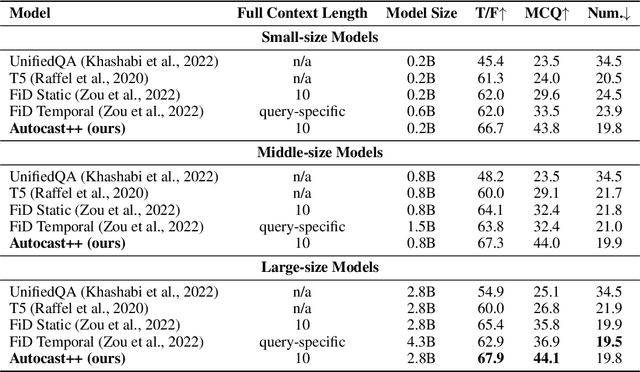
Machine-based prediction of real-world events is garnering attention due to its potential for informed decision-making. Whereas traditional forecasting predominantly hinges on structured data like time-series, recent breakthroughs in language models enable predictions using unstructured text. In particular, (Zou et al., 2022) unveils AutoCast, a new benchmark that employs news articles for answering forecasting queries. Nevertheless, existing methods still trail behind human performance. The cornerstone of accurate forecasting, we argue, lies in identifying a concise, yet rich subset of news snippets from a vast corpus. With this motivation, we introduce AutoCast++, a zero-shot ranking-based context retrieval system, tailored to sift through expansive news document collections for event forecasting. Our approach first re-ranks articles based on zero-shot question-passage relevance, honing in on semantically pertinent news. Following this, the chosen articles are subjected to zero-shot summarization to attain succinct context. Leveraging a pre-trained language model, we conduct both the relevance evaluation and article summarization without needing domain-specific training. Notably, recent articles can sometimes be at odds with preceding ones due to new facts or unanticipated incidents, leading to fluctuating temporal dynamics. To tackle this, our re-ranking mechanism gives preference to more recent articles, and we further regularize the multi-passage representation learning to align with human forecaster responses made on different dates. Empirical results underscore marked improvements across multiple metrics, improving the performance for multiple-choice questions (MCQ) by 48% and true/false (TF) questions by up to 8%.
Transforming Breast Cancer Diagnosis: Towards Real-Time Ultrasound to Mammogram Conversion for Cost-Effective Diagnosis
Aug 10, 2023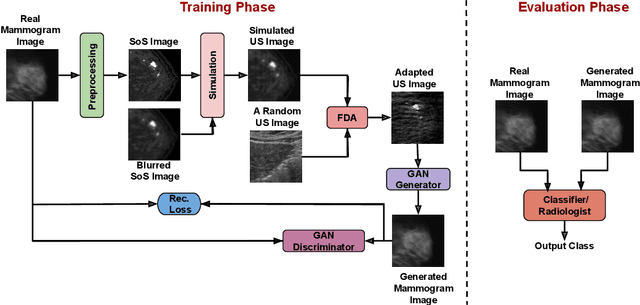
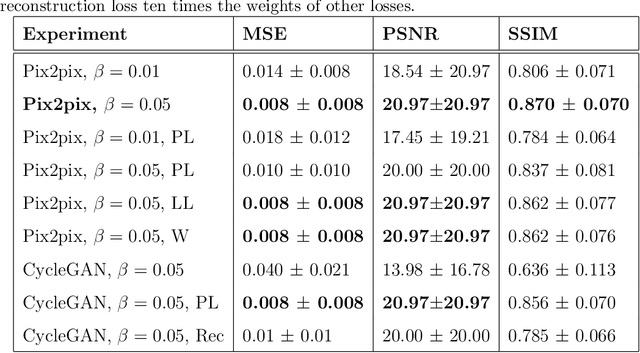

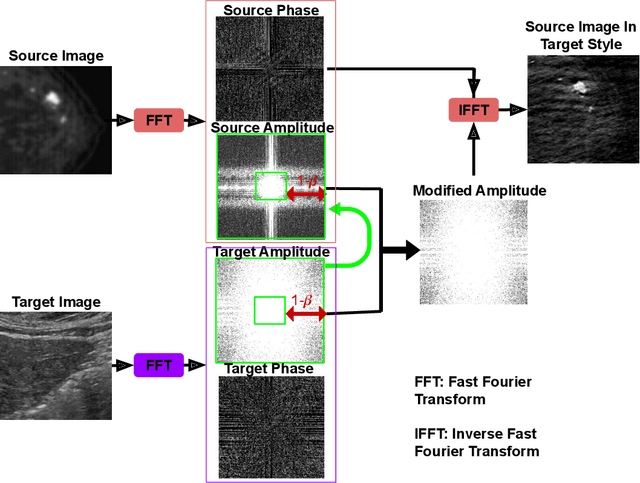
Ultrasound (US) imaging is better suited for intraoperative settings because it is real-time and more portable than other imaging techniques, such as mammography. However, US images are characterized by lower spatial resolution noise-like artifacts. This research aims to address these limitations by providing surgeons with mammogram-like image quality in real-time from noisy US images. Unlike previous approaches for improving US image quality that aim to reduce artifacts by treating them as (speckle noise), we recognize their value as informative wave interference pattern (WIP). To achieve this, we utilize the Stride software to numerically solve the forward model, generating ultrasound images from mammograms images by solving wave-equations. Additionally, we leverage the power of domain adaptation to enhance the realism of the simulated ultrasound images. Then, we utilize generative adversarial networks (GANs) to tackle the inverse problem of generating mammogram-quality images from ultrasound images. The resultant images have considerably more discernible details than the original US images.
ReFlow-TTS: A Rectified Flow Model for High-fidelity Text-to-Speech
Sep 29, 2023
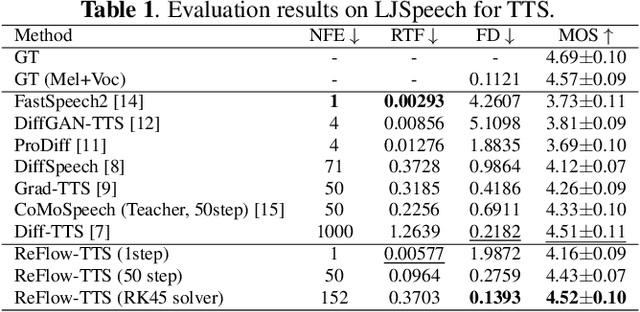
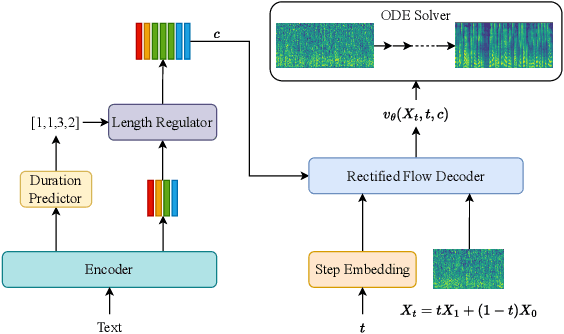

The diffusion models including Denoising Diffusion Probabilistic Models (DDPM) and score-based generative models have demonstrated excellent performance in speech synthesis tasks. However, its effectiveness comes at the cost of numerous sampling steps, resulting in prolonged sampling time required to synthesize high-quality speech. This drawback hinders its practical applicability in real-world scenarios. In this paper, we introduce ReFlow-TTS, a novel rectified flow based method for speech synthesis with high-fidelity. Specifically, our ReFlow-TTS is simply an Ordinary Differential Equation (ODE) model that transports Gaussian distribution to the ground-truth Mel-spectrogram distribution by straight line paths as much as possible. Furthermore, our proposed approach enables high-quality speech synthesis with a single sampling step and eliminates the need for training a teacher model. Our experiments on LJSpeech Dataset show that our ReFlow-TTS method achieves the best performance compared with other diffusion based models. And the ReFlow-TTS with one step sampling achieves competitive performance compared with existing one-step TTS models.
Beam Squint Assisted User Localization in Near-Field Integrated Sensing and Communications Systems
Sep 25, 2023Integrated sensing and communication (ISAC) has been regarded as a key technology for 6G wireless communications, in which large-scale multiple input and multiple output (MIMO) array with higher and wider frequency bands will be adopted. However, recent studies show that the beam squint phenomenon can not be ignored in wideband MIMO system, which generally deteriorates the communications performance. In this paper, we find that with the aid of true-time-delay lines (TTDs), the range and trajectory of the beam squint in near-field communications systems can be freely controlled, and hence it is possible to reversely utilize the beam squint for user localization. We derive the trajectory equation for near-field beam squint points and design a way to control such trajectory. With the proposed design, beamforming from different subcarriers would purposely point to different angles and different distances, such that users from different positions would receive the maximum power at different subcarriers. Hence, one can simply localize multiple users from the beam squint effect in frequency domain, and thus reduce the beam sweeping overhead as compared to the conventional time domain beam search based approach. Furthermore, we utilize the phase difference of the maximum power subcarriers received by the user at different frequencies in several times beam sweeping to obtain a more accurate distance estimation result, ultimately realizing high accuracy and low beam sweeping overhead user localization. Simulation results demonstrate the effectiveness of the proposed schemes.
Hierarchical Network Data Analytics Framework for B5G Network Automation: Design and Implementation
Sep 28, 20235G introduced modularized network functions (NFs) to support emerging services in a more flexible and elastic manner. To mitigate the complexity in such modularized NF management, automated network operation and management are indispensable, and thus the 3rd generation partnership project (3GPP) has introduced a network data analytics function (NWDAF). However, a conventional NWDAF needs to conduct both inference and training tasks, and thus it is difficult to provide the analytics results to NFs in a timely manner for an increased number of analytics requests. In this article, we propose a hierarchical network data analytics framework (H-NDAF) where inference tasks are distributed to multiple leaf NWDAFs and training tasks are conducted at the root NWDAF. Extensive simulation results using open-source software (i.e., free5GC) demonstrate that H-NDAF can provide sufficiently accurate analytics and faster analytics provision time compared to the conventional NWDAF.
Social Navigation in Crowded Environments with Model Predictive Control and Deep Learning-Based Human Trajectory Prediction
Sep 28, 2023
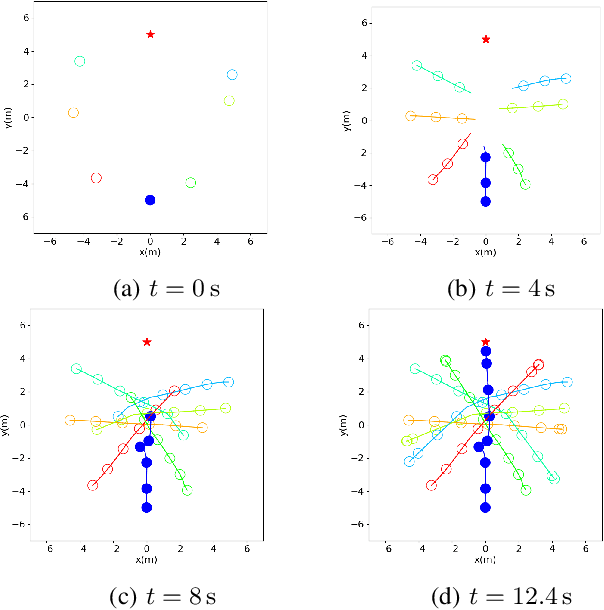
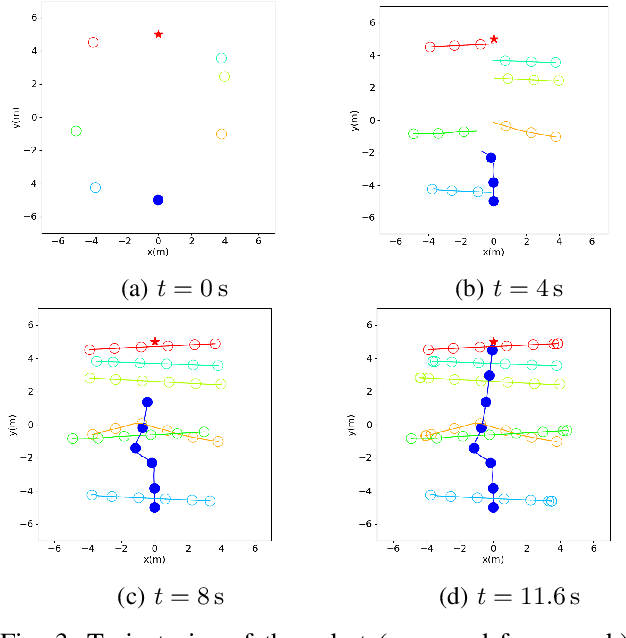
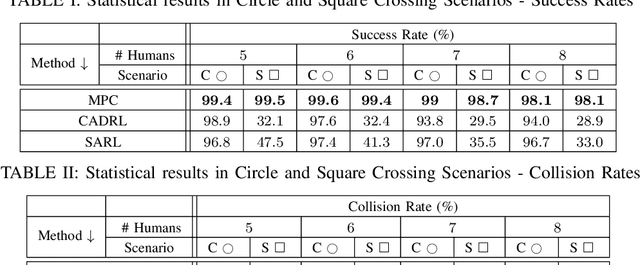
Crowd navigation has received increasing attention from researchers over the last few decades, resulting in the emergence of numerous approaches aimed at addressing this problem to date. Our proposed approach couples agent motion prediction and planning to avoid the freezing robot problem while simultaneously capturing multi-agent social interactions by utilizing a state-of-the-art trajectory prediction model i.e., social long short-term memory model (Social-LSTM). Leveraging the output of Social-LSTM for the prediction of future trajectories of pedestrians at each time-step given the robot's possible actions, our framework computes the optimal control action using Model Predictive Control (MPC) for the robot to navigate among pedestrians. We demonstrate the effectiveness of our proposed approach in multiple scenarios of simulated crowd navigation and compare it against several state-of-the-art reinforcement learning-based methods.
Uncertainty-aware hybrid paradigm of nonlinear MPC and model-based RL for offroad navigation: Exploration of transformers in the predictive model
Oct 01, 2023
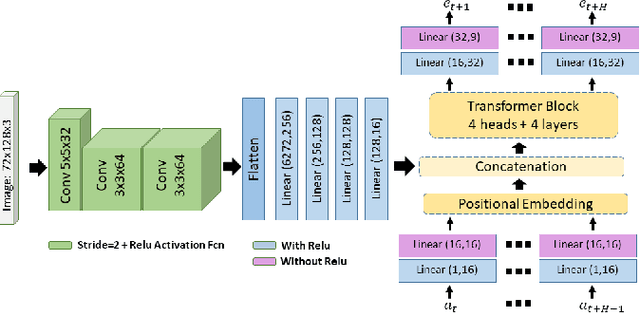
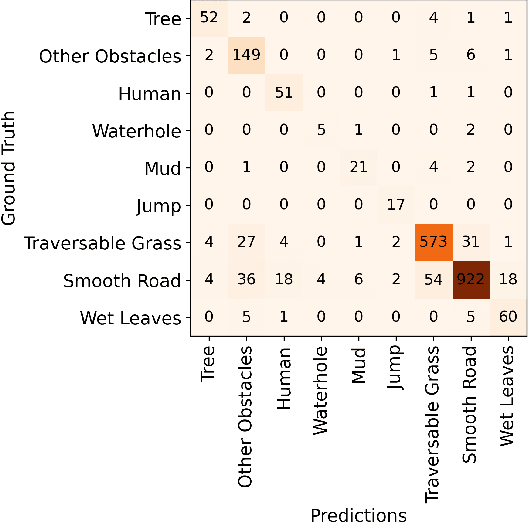
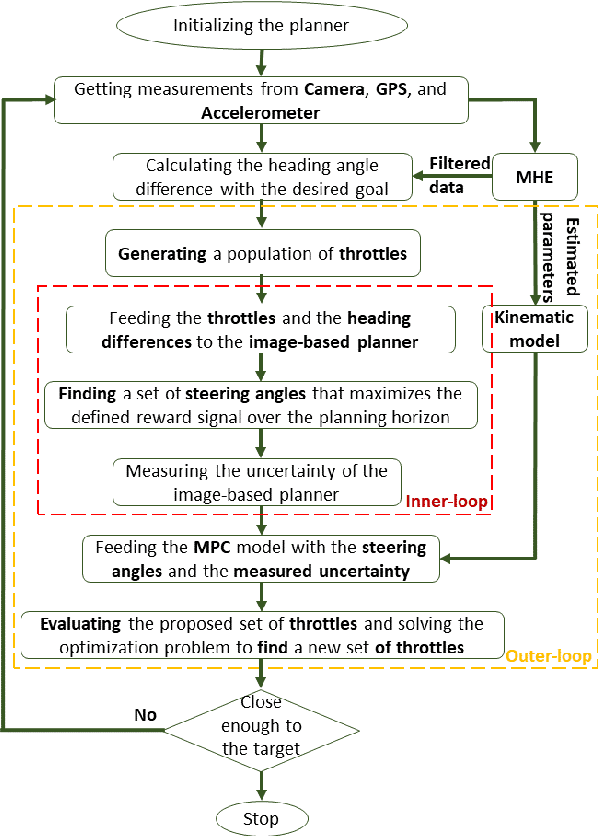
In this paper, we investigate a hybrid scheme that combines nonlinear model predictive control (MPC) and model-based reinforcement learning (RL) for navigation planning of an autonomous model car across offroad, unstructured terrains without relying on predefined maps. Our innovative approach takes inspiration from BADGR, an LSTM-based network that primarily concentrates on environment modeling, but distinguishes itself by substituting LSTM modules with transformers to greatly elevate the performance our model. Addressing uncertainty within the system, we train an ensemble of predictive models and estimate the mutual information between model weights and outputs, facilitating dynamic horizon planning through the introduction of variable speeds. Further enhancing our methodology, we incorporate a nonlinear MPC controller that accounts for the intricacies of the vehicle's model and states. The model-based RL facet produces steering angles and quantifies inherent uncertainty. At the same time, the nonlinear MPC suggests optimal throttle settings, striking a balance between goal attainment speed and managing model uncertainty influenced by velocity. In the conducted studies, our approach excels over the existing baseline by consistently achieving higher metric values in predicting future events and seamlessly integrating the vehicle's kinematic model for enhanced decision-making. The code and the evaluation data are available at https://github.com/FARAZLOTFI/offroad_autonomous_navigation/).
Class Incremental Learning via Likelihood Ratio Based Task Prediction
Oct 01, 2023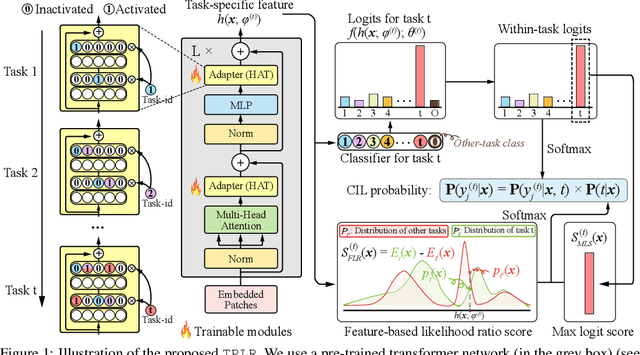
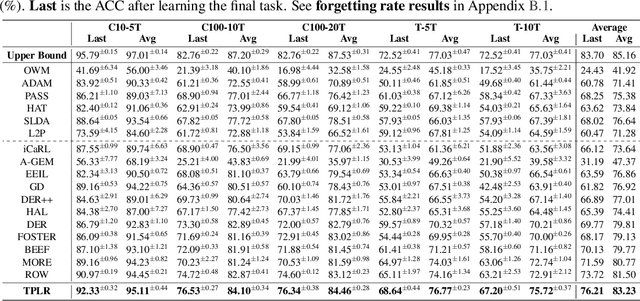
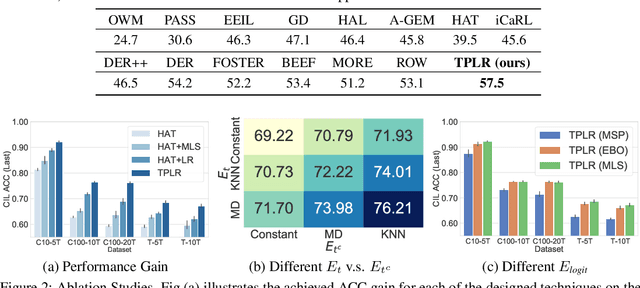
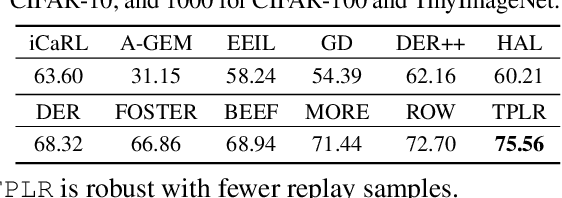
Class incremental learning (CIL) is a challenging setting of continual learning, which learns a series of tasks sequentially. Each task consists of a set of unique classes. The key feature of CIL is that no task identifier (or task-id) is provided at test time for each test sample. Predicting the task-id for each test sample is a challenging problem. An emerging theoretically justified and effective approach is to train a task-specific model for each task in a shared network for all tasks based on a task-incremental learning (TIL) method to deal with forgetting. The model for each task in this approach is an out-of-distribution (OOD) detector rather than a conventional classifier. The OOD detector can perform both within-task (in-distribution (IND)) class prediction and OOD detection. The OOD detection capability is the key for task-id prediction during inference for each test sample. However, this paper argues that using a traditional OOD detector for task-id prediction is sub-optimal because additional information (e.g., the replay data and the learned tasks) available in CIL can be exploited to design a better and principled method for task-id prediction. We call the new method TPLR (Task-id Prediction based on Likelihood Ratio}). TPLR markedly outperforms strong CIL baselines.
WarpEM: Dynamic Time Warping for Accurate Catheter Registration in EM-guided Procedures
Aug 07, 2023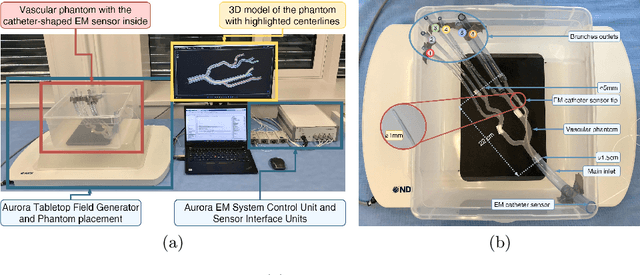
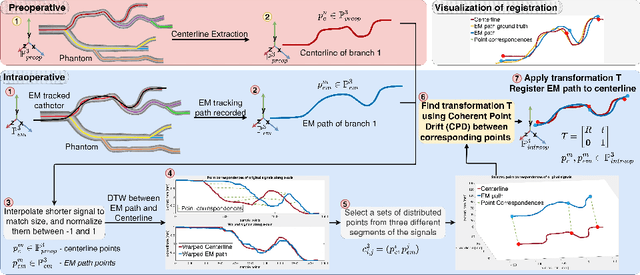
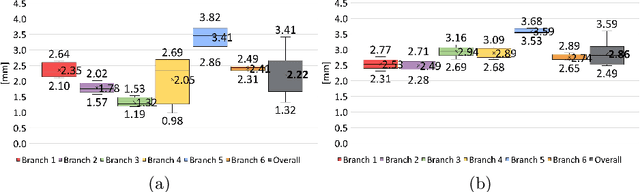
Accurate catheter tracking is crucial during minimally invasive endovascular procedures (MIEP), and electromagnetic (EM) tracking is a widely used technology that serves this purpose. However, registration between preoperative images and the EM tracking system is often challenging. Existing registration methods typically require manual interactions, which can be time-consuming, increase the risk of errors and change the procedural workflow. Although several registration methods are available for catheter tracking, such as marker-based and path-based approaches, their limitations can impact the accuracy of the resulting tracking solution, consequently, the outcome of the medical procedure. This paper introduces a novel automated catheter registration method for EM-guided MIEP. The method utilizes 3D signal temporal analysis, such as Dynamic Time Warping (DTW) algorithms, to improve registration accuracy and reliability compared to existing methods. DTW can accurately warp and match EM-tracked paths to the vessel's centerline, making it particularly suitable for registration. The introduced registration method is evaluated for accuracy in a vascular phantom using a marker-based registration as the ground truth. The results indicate that the DTW method yields accurate and reliable registration outcomes, with a mean error of $2.22$mm. The introduced registration method presents several advantages over state-of-the-art methods, such as high registration accuracy, no initialization required, and increased automation.
Label Shift Adapter for Test-Time Adaptation under Covariate and Label Shifts
Aug 17, 2023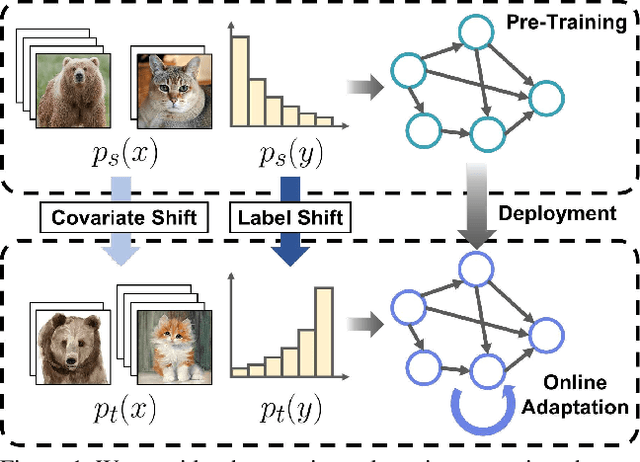
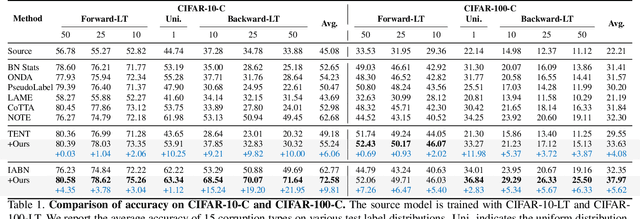
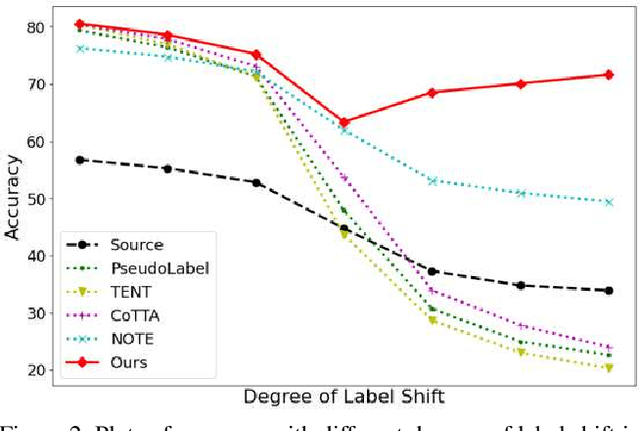
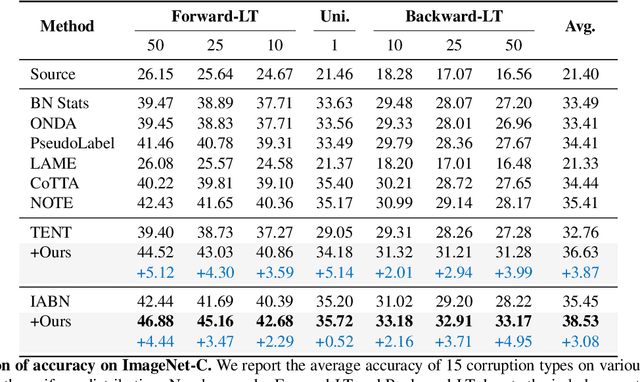
Test-time adaptation (TTA) aims to adapt a pre-trained model to the target domain in a batch-by-batch manner during inference. While label distributions often exhibit imbalances in real-world scenarios, most previous TTA approaches typically assume that both source and target domain datasets have balanced label distribution. Due to the fact that certain classes appear more frequently in certain domains (e.g., buildings in cities, trees in forests), it is natural that the label distribution shifts as the domain changes. However, we discover that the majority of existing TTA methods fail to address the coexistence of covariate and label shifts. To tackle this challenge, we propose a novel label shift adapter that can be incorporated into existing TTA approaches to deal with label shifts during the TTA process effectively. Specifically, we estimate the label distribution of the target domain to feed it into the label shift adapter. Subsequently, the label shift adapter produces optimal parameters for the target label distribution. By predicting only the parameters for a part of the pre-trained source model, our approach is computationally efficient and can be easily applied, regardless of the model architectures. Through extensive experiments, we demonstrate that integrating our strategy with TTA approaches leads to substantial performance improvements under the joint presence of label and covariate shifts.