 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CoBEV: Elevating Roadside 3D Object Detection with Depth and Height Complementarity
Oct 04, 2023
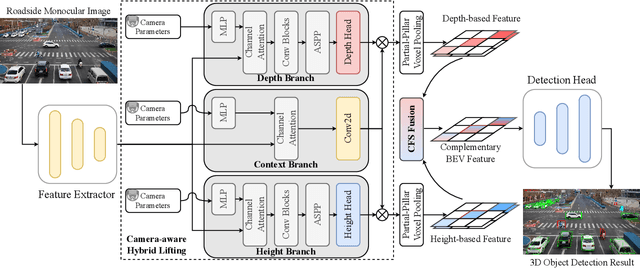
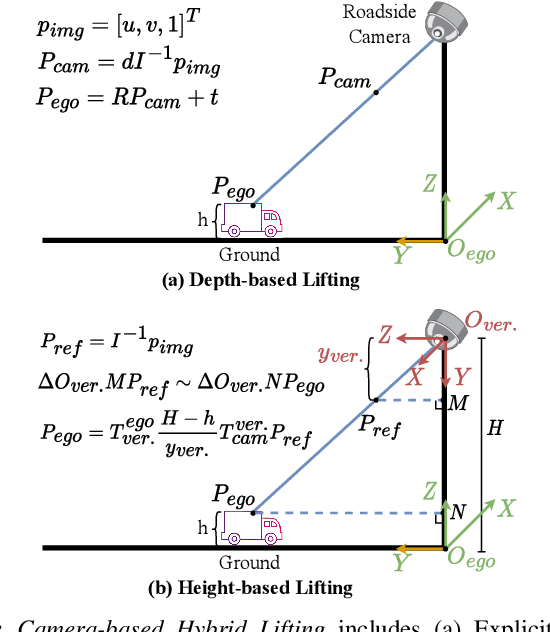

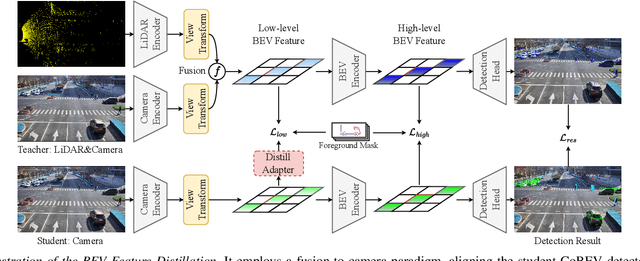
Roadside camera-driven 3D object detection is a crucial task in intelligent transportation systems, which extends the perception range beyond the limitations of vision-centric vehicles and enhances road safety. While previous studies have limitations in using only depth or height information, we find both depth and height matter and they are in fact complementary. The depth feature encompasses precise geometric cues, whereas the height feature is primarily focused on distinguishing between various categories of height intervals, essentially providing semantic context. This insight motivates the development of Complementary-BEV (CoBEV), a novel end-to-end monocular 3D object detection framework that integrates depth and height to construct robust BEV representations. In essence, CoBEV estimates each pixel's depth and height distribution and lifts the camera features into 3D space for lateral fusion using the newly proposed two-stage complementary feature selection (CFS) module. A BEV feature distillation framework is also seamlessly integrated to further enhance the detection accuracy from the prior knowledge of the fusion-modal CoBEV teacher. We conduct extensive experiments on the public 3D detection benchmarks of roadside camera-based DAIR-V2X-I and Rope3D, as well as the private Supremind-Road dataset, demonstrating that CoBEV not only achieves the accuracy of the new state-of-the-art, but also significantly advances the robustness of previous methods in challenging long-distance scenarios and noisy camera disturbance, and enhances generalization by a large margin in heterologous settings with drastic changes in scene and camera parameters. For the first time, the vehicle AP score of a camera model reaches 80% on DAIR-V2X-I in terms of easy mode. The source code will be made publicly available at https://github.com/MasterHow/CoBEV.
Semi-Federated Learning: Convergence Analysis and Optimization of A Hybrid Learning Framework
Oct 04, 2023Under the organization of the base station (BS), wireless federated learning (FL) enables collaborative model training among multiple devices. However, the BS is merely responsible for aggregating local updates during the training process, which incurs a waste of the computational resource at the BS. To tackle this issue, we propose a semi-federated learning (SemiFL) paradigm to leverage the computing capabilities of both the BS and devices for a hybrid implementation of centralized learning (CL) and FL. Specifically, each device sends both local gradients and data samples to the BS for training a shared global model. To improve communication efficiency over the same time-frequency resources, we integrate over-the-air computation for aggregation and non-orthogonal multiple access for transmission by designing a novel transceiver structure. To gain deep insights, we conduct convergence analysis by deriving a closed-form optimality gap for SemiFL and extend the result to two extra cases. In the first case, the BS uses all accumulated data samples to calculate the CL gradient, while a decreasing learning rate is adopted in the second case. Our analytical results capture the destructive effect of wireless communication and show that both FL and CL are special cases of SemiFL. Then, we formulate a non-convex problem to reduce the optimality gap by jointly optimizing the transmit power and receive beamformers. Accordingly, we propose a two-stage algorithm to solve this intractable problem, in which we provide the closed-form solutions to the beamformers. Extensive simulation results on two real-world datasets corroborate our theoretical analysis, and show that the proposed SemiFL outperforms conventional FL and achieves 3.2% accuracy gain on the MNIST dataset compared to state-of-the-art benchmarks.
Solution Path of Time-varying Markov Random Fields with Discrete Regularization
Jul 25, 2023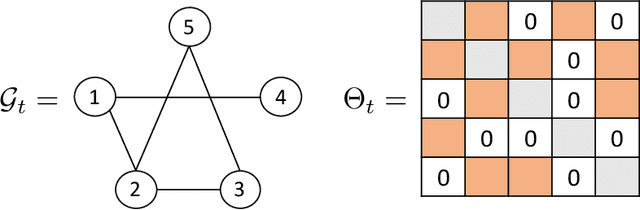
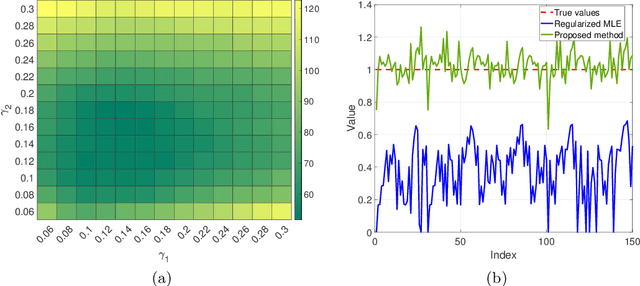

We study the problem of inferring sparse time-varying Markov random fields (MRFs) with different discrete and temporal regularizations on the parameters. Due to the intractability of discrete regularization, most approaches for solving this problem rely on the so-called maximum-likelihood estimation (MLE) with relaxed regularization, which neither results in ideal statistical properties nor scale to the dimensions encountered in realistic settings. In this paper, we address these challenges by departing from the MLE paradigm and resorting to a new class of constrained optimization problems with exact, discrete regularization to promote sparsity in the estimated parameters. Despite the nonconvex and discrete nature of our formulation, we show that it can be solved efficiently and parametrically for all sparsity levels. More specifically, we show that the entire solution path of the time-varying MRF for all sparsity levels can be obtained in $\mathcal{O}(pT^3)$, where $T$ is the number of time steps and $p$ is the number of unknown parameters at any given time. The efficient and parametric characterization of the solution path renders our approach highly suitable for cross-validation, where parameter estimation is required for varying regularization values. Despite its simplicity and efficiency, we show that our proposed approach achieves provably small estimation error for different classes of time-varying MRFs, namely Gaussian and discrete MRFs, with as few as one sample per time. Utilizing our algorithm, we can recover the complete solution path for instances of time-varying MRFs featuring over 30 million variables in less than 12 minutes on a standard laptop computer. Our code is available at \url{https://sites.google.com/usc.edu/gomez/data}.
Semi-Aerodynamic Model Aided Invariant Kalman Filtering for UAV Full-State Estimation
Oct 03, 2023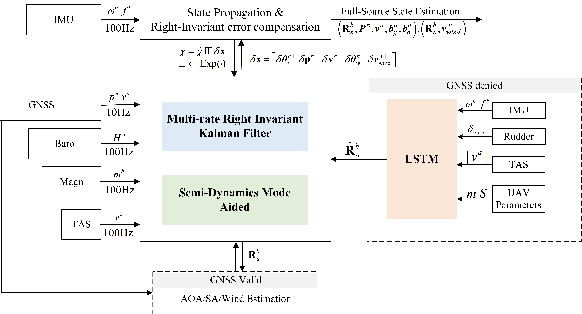
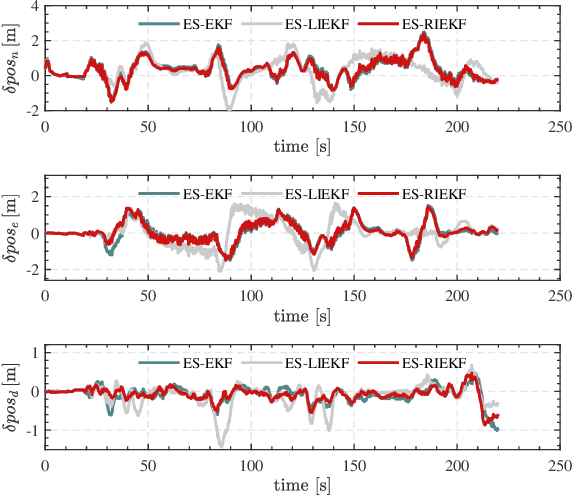
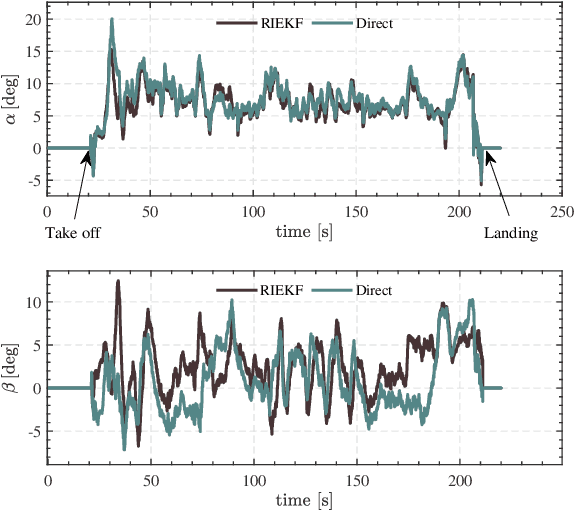
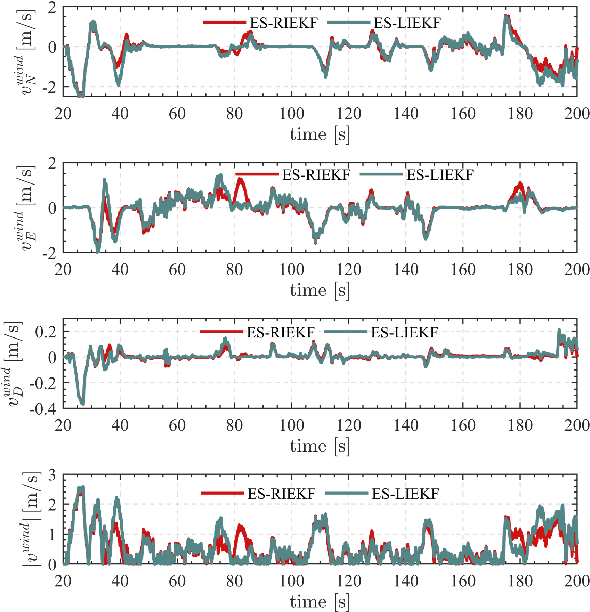
Due to the state trajectory-independent features of invariant Kalman filtering (InEKF), it has attracted widespread attention in the research community for its significantly improved state estimation accuracy and convergence under disturbance. In this paper, we formulate the full-source data fusion navigation problem for fixed-wing unmanned aerial vehicle (UAV) within a framework based on error state right-invariant extended Kalman filtering (ES-RIEKF) on Lie groups. We merge measurements from a multi-rate onboard sensor network on UAVs to achieve real-time estimation of pose, air flow angles, and wind speed. Detailed derivations are provided, and the algorithm's convergence and accuracy improvements over established methods like Error State EKF (ES-EKF) and Nonlinear Complementary Filter (NCF) are demonstrated using real-flight data from UAVs. Additionally, we introduce a semi-aerodynamic model fusion framework that relies solely on ground-measurable parameters. We design and train an Long Short Term Memory (LSTM) deep network to achieve drift-free prediction of the UAV's angle of attack (AOA) and side-slip angle (SA) using easily obtainable onboard data like control surface deflections, thereby significantly reducing dependency on GNSS or complicated aerodynamic model parameters. Further, we validate the algorithm's robust advantages under GNSS denied, where flight data shows that the maximum positioning error stays within 30 meters over a 130-second denial period. To the best of our knowledge, this study is the first to apply ES-RIEKF to full-source navigation applications for fixed-wing UAVs, aiming to provide engineering references for designers. Our implementations using MATLAB/Simulink will open source.
1D-CapsNet-LSTM: A Deep Learning-Based Model for Multi-Step Stock Index Forecasting
Oct 03, 2023Multi-step forecasting of stock market index prices is a crucial task in the financial sector, playing a pivotal role in decision-making across various financial activities. However, forecasting results are often unsatisfactory owing to the stochastic and volatile nature of the data. Researchers have made various attempts, and this process is ongoing. Inspired by convolutional neural network long short-term memory (CNN-LSTM) networks that utilize a 1D CNN for feature extraction to boost model performance, this study explores the use of a capsule network (CapsNet) as an advanced feature extractor in an LSTM-based forecasting model to enhance multi-step predictions. To this end, a novel neural architecture called 1D-CapsNet-LSTM was introduced, which combines a 1D CapsNet to extract high-level features from 1D sequential data and an LSTM layer to capture the temporal dependencies between the previously extracted features and uses a multi-input multi-output (MIMO) strategy to maintain the stochastic dependencies between the predicted values at different time steps. The proposed model was evaluated based on several real-world stock market indices, including Standard & Poor's 500 (S&P 500), Dow Jones Industrial Average (DJIA), Nasdaq Composite Index (IXIC), and New York Stock Exchange (NYSE), and was compared with baseline models such as LSTM, recurrent neural network (RNN), and CNN-LSTM in terms of various evaluation metrics. The comparison results suggest that the 1D-CapsNet-LSTM model outperforms the baseline models and has immense potential for the effective handling of complex prediction tasks.
DeepZero: Scaling up Zeroth-Order Optimization for Deep Model Training
Oct 03, 2023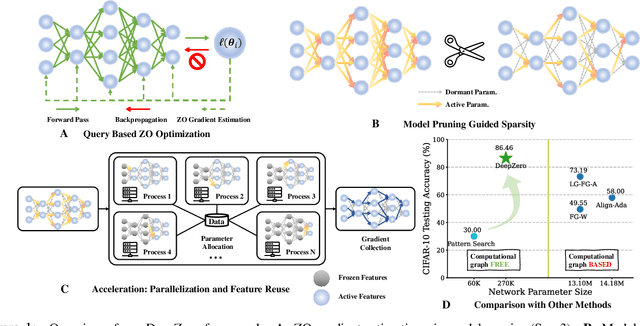
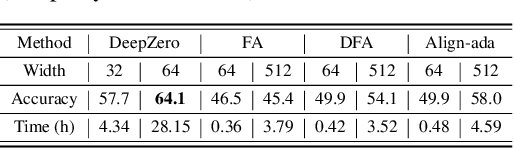
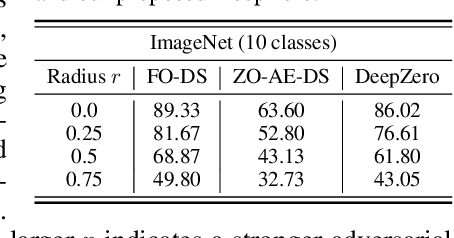
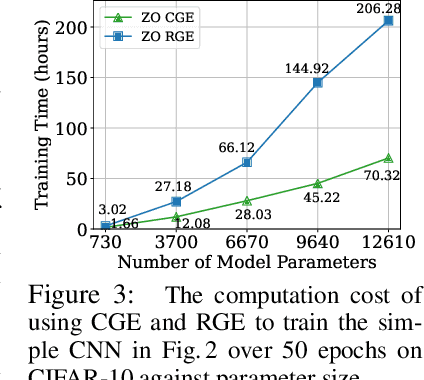
Zeroth-order (ZO) optimization has become a popular technique for solving machine learning (ML) problems when first-order (FO) information is difficult or impossible to obtain. However, the scalability of ZO optimization remains an open problem: Its use has primarily been limited to relatively small-scale ML problems, such as sample-wise adversarial attack generation. To our best knowledge, no prior work has demonstrated the effectiveness of ZO optimization in training deep neural networks (DNNs) without a significant decrease in performance. To overcome this roadblock, we develop DeepZero, a principled ZO deep learning (DL) framework that can scale ZO optimization to DNN training from scratch through three primary innovations. First, we demonstrate the advantages of coordinate-wise gradient estimation (CGE) over randomized vector-wise gradient estimation in training accuracy and computational efficiency. Second, we propose a sparsity-induced ZO training protocol that extends the model pruning methodology using only finite differences to explore and exploit the sparse DL prior in CGE. Third, we develop the methods of feature reuse and forward parallelization to advance the practical implementations of ZO training. Our extensive experiments show that DeepZero achieves state-of-the-art (SOTA) accuracy on ResNet-20 trained on CIFAR-10, approaching FO training performance for the first time. Furthermore, we show the practical utility of DeepZero in applications of certified adversarial defense and DL-based partial differential equation error correction, achieving 10-20% improvement over SOTA. We believe our results will inspire future research on scalable ZO optimization and contribute to advancing DL with black box.
CoralVOS: Dataset and Benchmark for Coral Video Segmentation
Oct 03, 2023
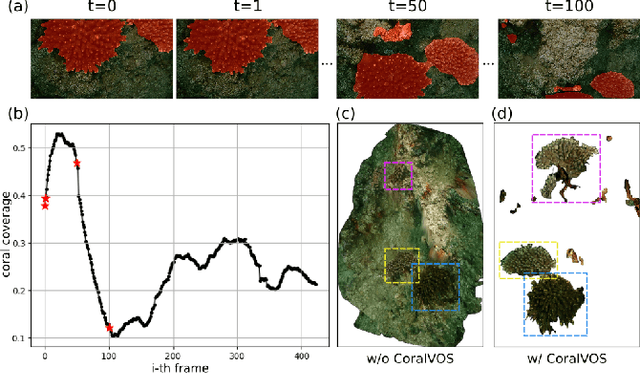

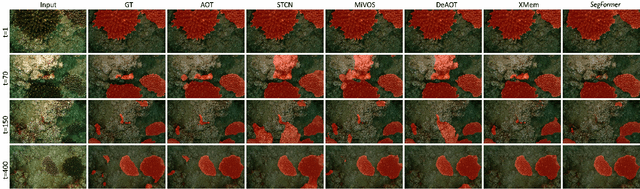
Coral reefs formulate the most valuable and productive marine ecosystems, providing habitat for many marine species. Coral reef surveying and analysis are currently confined to coral experts who invest substantial effort in generating comprehensive and dependable reports (\emph{e.g.}, coral coverage, population, spatial distribution, \textit{etc}), from the collected survey data. However, performing dense coral analysis based on manual efforts is significantly time-consuming, the existing coral analysis algorithms compromise and opt for performing down-sampling and only conducting sparse point-based coral analysis within selected frames. However, such down-sampling will \textbf{inevitable} introduce the estimation bias or even lead to wrong results. To address this issue, we propose to perform \textbf{dense coral video segmentation}, with no down-sampling involved. Through video object segmentation, we could generate more \textit{reliable} and \textit{in-depth} coral analysis than the existing coral reef analysis algorithms. To boost such dense coral analysis, we propose a large-scale coral video segmentation dataset: \textbf{CoralVOS} as demonstrated in Fig. 1. To the best of our knowledge, our CoralVOS is the first dataset and benchmark supporting dense coral video segmentation. We perform experiments on our CoralVOS dataset, including 6 recent state-of-the-art video object segmentation (VOS) algorithms. We fine-tuned these VOS algorithms on our CoralVOS dataset and achieved observable performance improvement. The results show that there is still great potential for further promoting the segmentation accuracy. The dataset and trained models will be released with the acceptance of this work to foster the coral reef research community.
AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval
Oct 03, 2023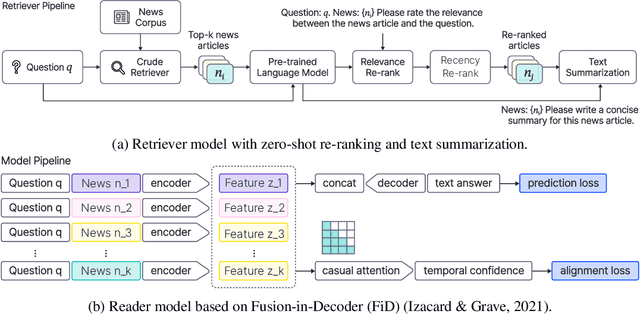
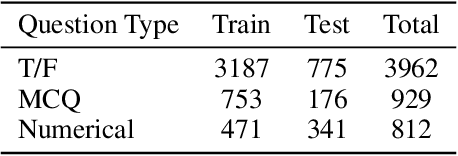
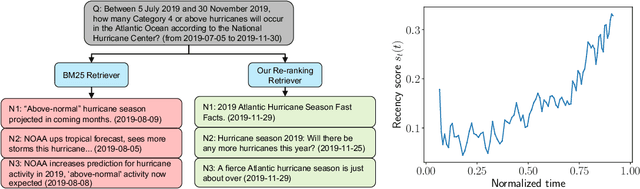
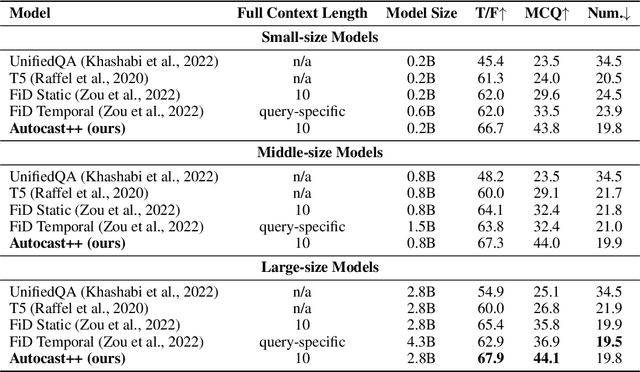
Machine-based prediction of real-world events is garnering attention due to its potential for informed decision-making. Whereas traditional forecasting predominantly hinges on structured data like time-series, recent breakthroughs in language models enable predictions using unstructured text. In particular, (Zou et al., 2022) unveils AutoCast, a new benchmark that employs news articles for answering forecasting queries. Nevertheless, existing methods still trail behind human performance. The cornerstone of accurate forecasting, we argue, lies in identifying a concise, yet rich subset of news snippets from a vast corpus. With this motivation, we introduce AutoCast++, a zero-shot ranking-based context retrieval system, tailored to sift through expansive news document collections for event forecasting. Our approach first re-ranks articles based on zero-shot question-passage relevance, honing in on semantically pertinent news. Following this, the chosen articles are subjected to zero-shot summarization to attain succinct context. Leveraging a pre-trained language model, we conduct both the relevance evaluation and article summarization without needing domain-specific training. Notably, recent articles can sometimes be at odds with preceding ones due to new facts or unanticipated incidents, leading to fluctuating temporal dynamics. To tackle this, our re-ranking mechanism gives preference to more recent articles, and we further regularize the multi-passage representation learning to align with human forecaster responses made on different dates. Empirical results underscore marked improvements across multiple metrics, improving the performance for multiple-choice questions (MCQ) by 48% and true/false (TF) questions by up to 8%.
TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series
Aug 16, 2023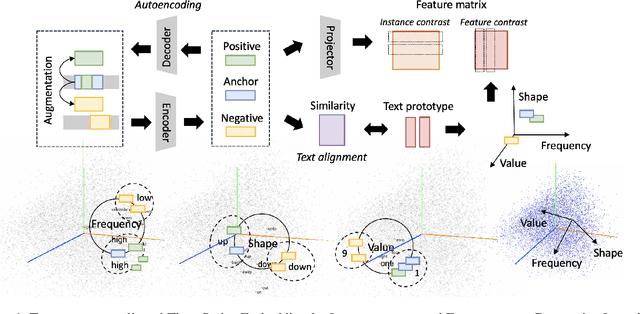
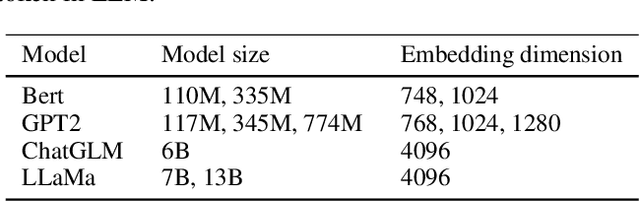
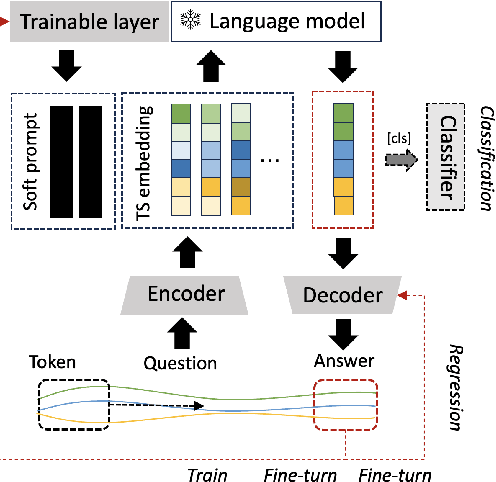
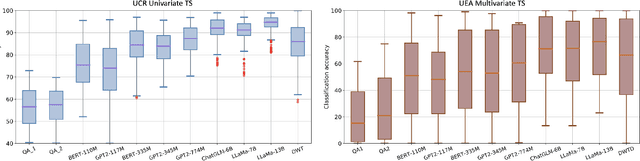
This work summarizes two strategies for completing time-series (TS) tasks using today's language model (LLM): LLM-for-TS, design and train a fundamental large model for TS data; TS-for-LLM, enable the pre-trained LLM to handle TS data. Considering the insufficient data accumulation, limited resources, and semantic context requirements, this work focuses on TS-for-LLM methods, where we aim to activate LLM's ability for TS data by designing a TS embedding method suitable for LLM. The proposed method is named TEST. It first tokenizes TS, builds an encoder to embed them by instance-wise, feature-wise, and text-prototype-aligned contrast, and then creates prompts to make LLM more open to embeddings, and finally implements TS tasks. Experiments are carried out on TS classification and forecasting tasks using 8 LLMs with different structures and sizes. Although its results cannot significantly outperform the current SOTA models customized for TS tasks, by treating LLM as the pattern machine, it can endow LLM's ability to process TS data without compromising the language ability. This paper is intended to serve as a foundational work that will inspire further research.
CenTime: Event-Conditional Modelling of Censoring in Survival Analysis
Sep 15, 2023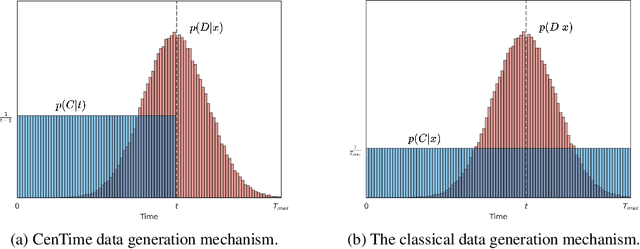
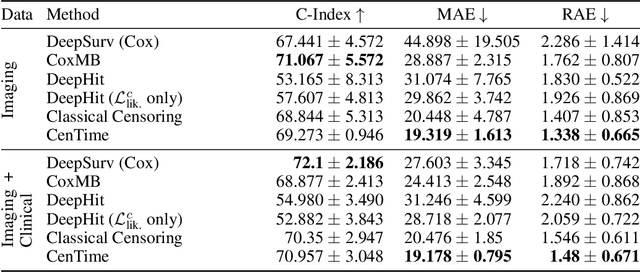
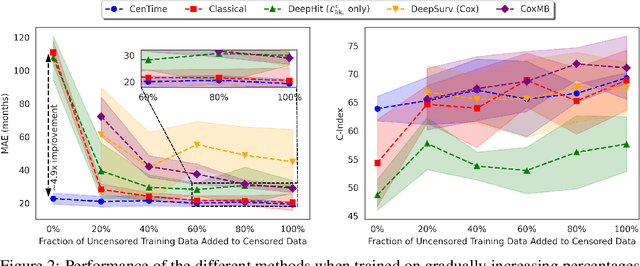
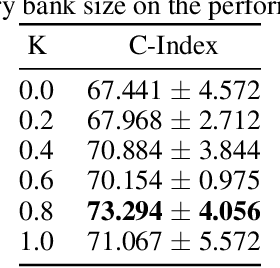
Survival analysis is a valuable tool for estimating the time until specific events, such as death or cancer recurrence, based on baseline observations. This is particularly useful in healthcare to prognostically predict clinically important events based on patient data. However, existing approaches often have limitations; some focus only on ranking patients by survivability, neglecting to estimate the actual event time, while others treat the problem as a classification task, ignoring the inherent time-ordered structure of the events. Furthermore, the effective utilization of censored samples - training data points where the exact event time is unknown - is essential for improving the predictive accuracy of the model. In this paper, we introduce CenTime, a novel approach to survival analysis that directly estimates the time to event. Our method features an innovative event-conditional censoring mechanism that performs robustly even when uncensored data is scarce. We demonstrate that our approach forms a consistent estimator for the event model parameters, even in the absence of uncensored data. Furthermore, CenTime is easily integrated with deep learning models with no restrictions on batch size or the number of uncensored samples. We compare our approach with standard survival analysis methods, including the Cox proportional-hazard model and DeepHit. Our results indicate that CenTime offers state-of-the-art performance in predicting time-to-death while maintaining comparable ranking performance. Our implementation is publicly available at https://github.com/ahmedhshahin/CenTime.