 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inferring Inference
Oct 04, 2023

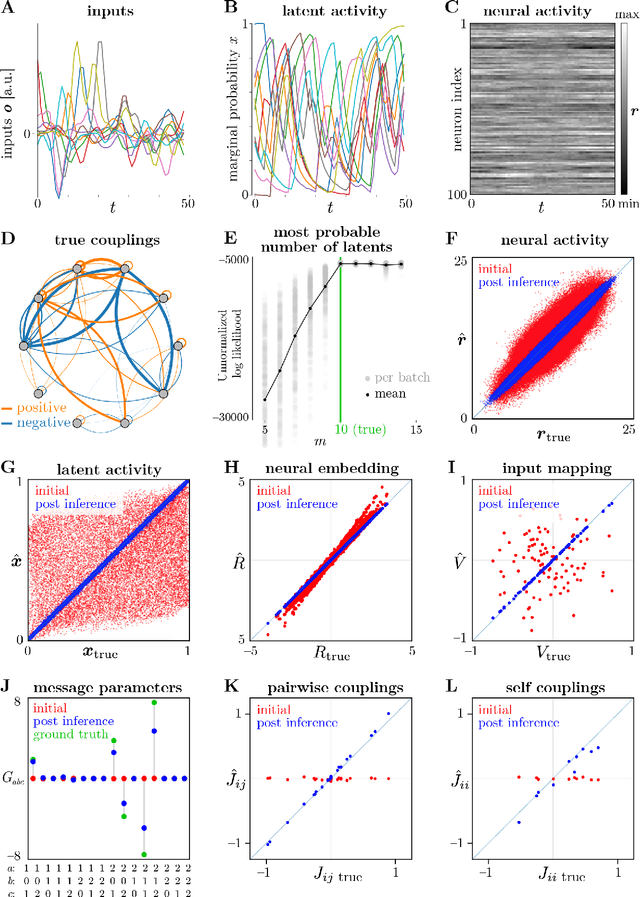
Patterns of microcircuitry suggest that the brain has an array of repeated canonical computational units. Yet neural representations are distributed, so the relevant computations may only be related indirectly to single-neuron transformations. It thus remains an open challenge how to define canonical distributed computations. We integrate normative and algorithmic theories of neural computation into a mathematical framework for inferring canonical distributed computations from large-scale neural activity patterns. At the normative level, we hypothesize that the brain creates a structured internal model of its environment, positing latent causes that explain its sensory inputs, and uses those sensory inputs to infer the latent causes. At the algorithmic level, we propose that this inference process is a nonlinear message-passing algorithm on a graph-structured model of the world. Given a time series of neural activity during a perceptual inference task, our framework finds (i) the neural representation of relevant latent variables, (ii) interactions between these variables that define the brain's internal model of the world, and (iii) message-functions specifying the inference algorithm. These targeted computational properties are then statistically distinguishable due to the symmetries inherent in any canonical computation, up to a global transformation. As a demonstration, we simulate recordings for a model brain that implicitly implements an approximate inference algorithm on a probabilistic graphical model. Given its external inputs and noisy neural activity, we recover the latent variables, their neural representation and dynamics, and canonical message-functions. We highlight features of experimental design needed to successfully extract canonical computations from neural data. Overall, this framework provides a new tool for discovering interpretable structure in neural recordings.
Drifter: Efficient Online Feature Monitoring for Improved Data Integrity in Large-Scale Recommendation Systems
Sep 21, 2023
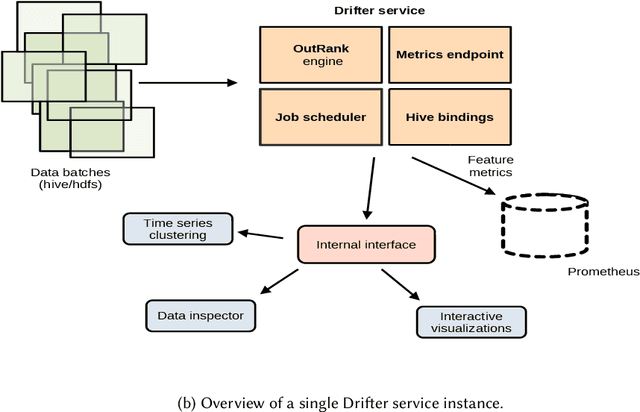
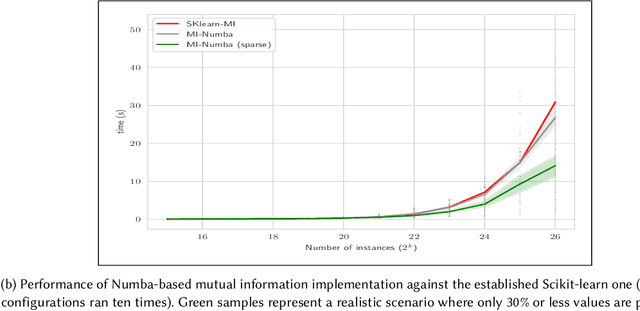
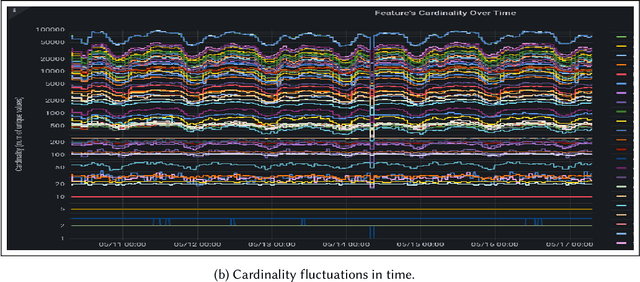
Real-world production systems often grapple with maintaining data quality in large-scale, dynamic streams. We introduce Drifter, an efficient and lightweight system for online feature monitoring and verification in recommendation use cases. Drifter addresses limitations of existing methods by delivering agile, responsive, and adaptable data quality monitoring, enabling real-time root cause analysis, drift detection and insights into problematic production events. Integrating state-of-the-art online feature ranking for sparse data and anomaly detection ideas, Drifter is highly scalable and resource-efficient, requiring only two threads and less than a gigabyte of RAM per production deployments that handle millions of instances per minute. Evaluation on real-world data sets demonstrates Drifter's effectiveness in alerting and mitigating data quality issues, substantially improving reliability and performance of real-time live recommender systems.
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion
Oct 01, 2023
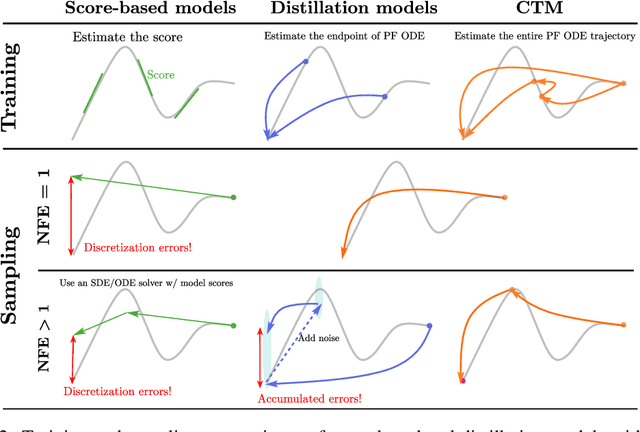

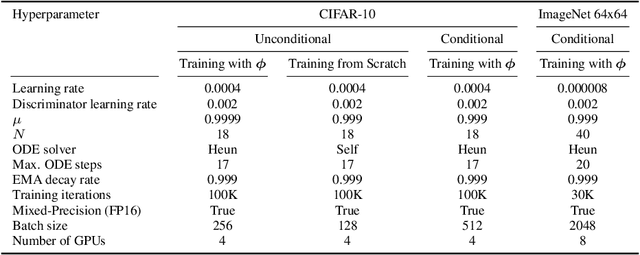
Consistency Models (CM) (Song et al., 2023) accelerate score-based diffusion model sampling at the cost of sample quality but lack a natural way to trade-off quality for speed. To address this limitation, we propose Consistency Trajectory Model (CTM), a generalization encompassing CM and score-based models as special cases. CTM trains a single neural network that can -- in a single forward pass -- output scores (i.e., gradients of log-density) and enables unrestricted traversal between any initial and final time along the Probability Flow Ordinary Differential Equation (ODE) in a diffusion process. CTM enables the efficient combination of adversarial training and denoising score matching loss to enhance performance and achieves new state-of-the-art FIDs for single-step diffusion model sampling on CIFAR-10 (FID 1.73) and ImageNet at 64X64 resolution (FID 2.06). CTM also enables a new family of sampling schemes, both deterministic and stochastic, involving long jumps along the ODE solution trajectories. It consistently improves sample quality as computational budgets increase, avoiding the degradation seen in CM. Furthermore, CTM's access to the score accommodates all diffusion model inference techniques, including exact likelihood computation.
How Many Views Are Needed to Reconstruct an Unknown Object Using NeRF?
Oct 01, 2023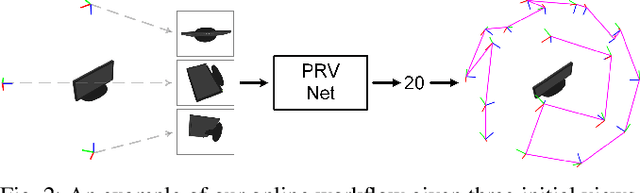
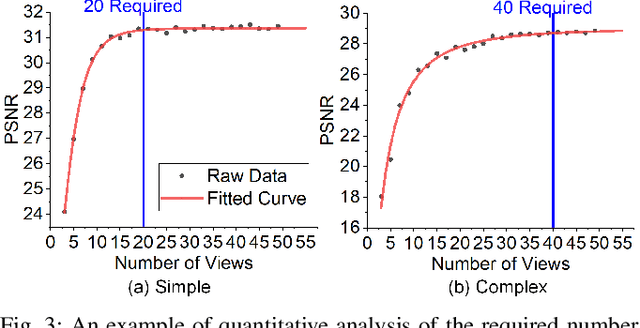
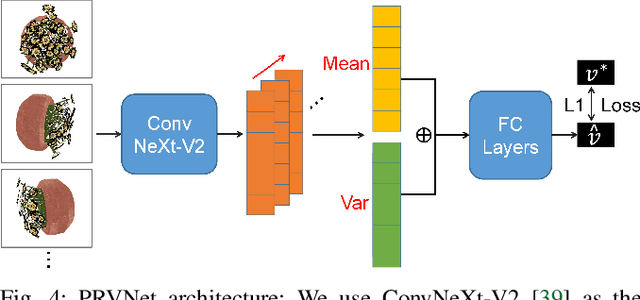

Neural Radiance Fields (NeRFs) are gaining significant interest for online active object reconstruction due to their exceptional memory efficiency and requirement for only posed RGB inputs. Previous NeRF-based view planning methods exhibit computational inefficiency since they rely on an iterative paradigm, consisting of (1) retraining the NeRF when new images arrive; and (2) planning a path to the next best view only. To address these limitations, we propose a non-iterative pipeline based on the Prediction of the Required number of Views (PRV). The key idea behind our approach is that the required number of views to reconstruct an object depends on its complexity. Therefore, we design a deep neural network, named PRVNet, to predict the required number of views, allowing us to tailor the data acquisition based on the object complexity and plan a globally shortest path. To train our PRVNet, we generate supervision labels using the ShapeNet dataset. Simulated experiments show that our PRV-based view planning method outperforms baselines, achieving good reconstruction quality while significantly reducing movement cost and planning time. We further justify the generalization ability of our approach in a real-world experiment.
TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series
Aug 16, 2023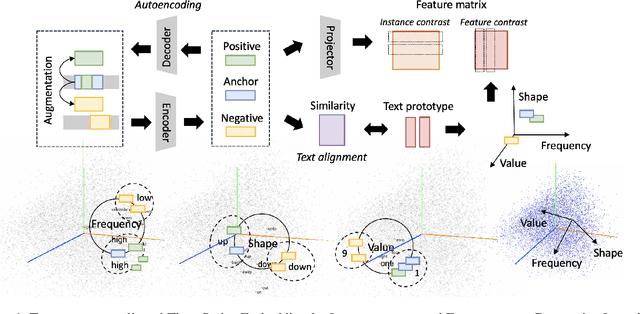
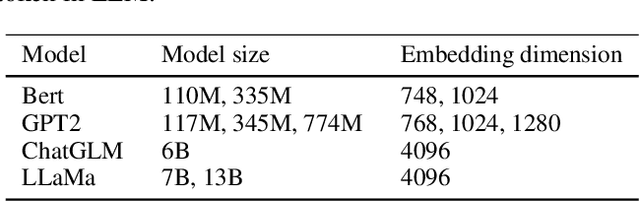
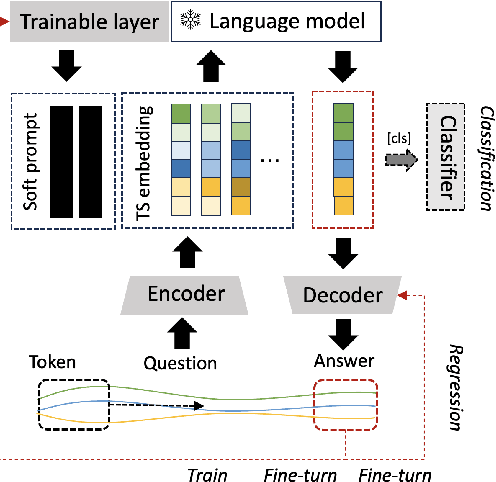
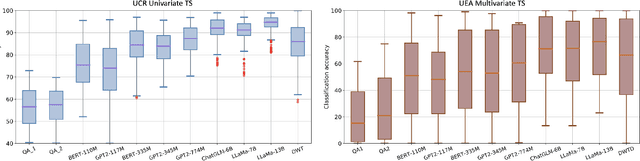
This work summarizes two strategies for completing time-series (TS) tasks using today's language model (LLM): LLM-for-TS, design and train a fundamental large model for TS data; TS-for-LLM, enable the pre-trained LLM to handle TS data. Considering the insufficient data accumulation, limited resources, and semantic context requirements, this work focuses on TS-for-LLM methods, where we aim to activate LLM's ability for TS data by designing a TS embedding method suitable for LLM. The proposed method is named TEST. It first tokenizes TS, builds an encoder to embed them by instance-wise, feature-wise, and text-prototype-aligned contrast, and then creates prompts to make LLM more open to embeddings, and finally implements TS tasks. Experiments are carried out on TS classification and forecasting tasks using 8 LLMs with different structures and sizes. Although its results cannot significantly outperform the current SOTA models customized for TS tasks, by treating LLM as the pattern machine, it can endow LLM's ability to process TS data without compromising the language ability. This paper is intended to serve as a foundational work that will inspire further research.
Real World Time Series Benchmark Datasets with Distribution Shifts: Global Crude Oil Price and Volatility
Aug 21, 2023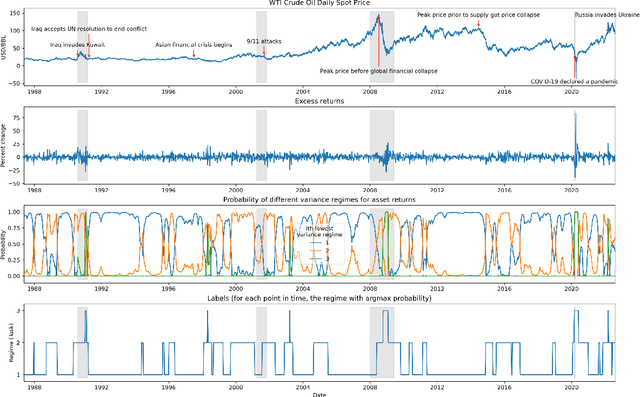
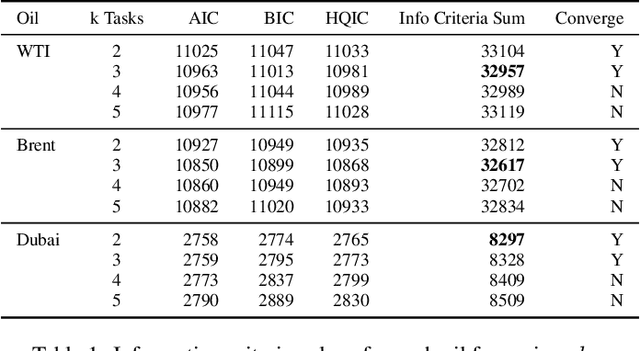
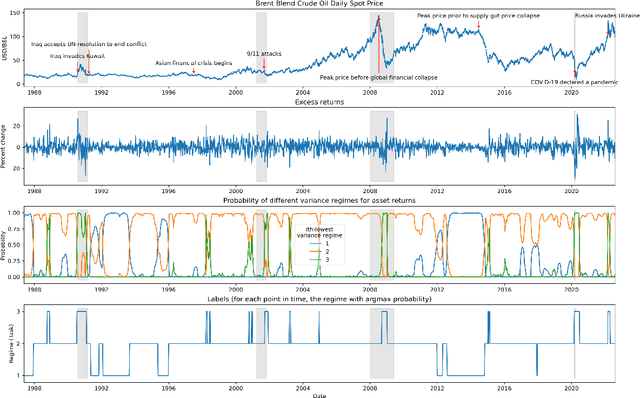
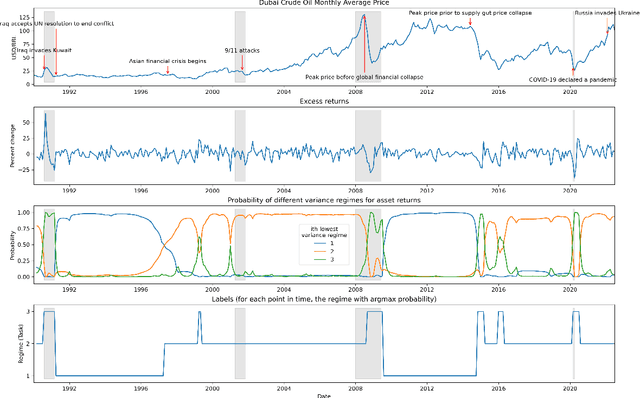
The scarcity of task-labeled time-series benchmarks in the financial domain hinders progress in continual learning. Addressing this deficit would foster innovation in this area. Therefore, we present COB, Crude Oil Benchmark datasets. COB includes 30 years of asset prices that exhibit significant distribution shifts and optimally generates corresponding task (i.e., regime) labels based on these distribution shifts for the three most important crude oils in the world. Our contributions include creating real-world benchmark datasets by transforming asset price data into volatility proxies, fitting models using expectation-maximization (EM), generating contextual task labels that align with real-world events, and providing these labels as well as the general algorithm to the public. We show that the inclusion of these task labels universally improves performance on four continual learning algorithms, some state-of-the-art, over multiple forecasting horizons. We hope these benchmarks accelerate research in handling distribution shifts in real-world data, especially due to the global importance of the assets considered. We've made the (1) raw price data, (2) task labels generated by our approach, (3) and code for our algorithm available at https://oilpricebenchmarks.github.io.
Forecasting Response to Treatment with Deep Learning and Pharmacokinetic Priors
Sep 22, 2023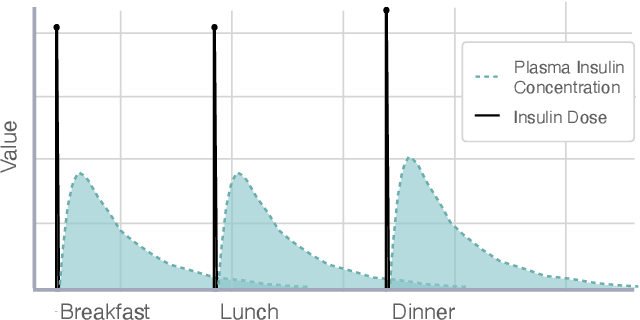
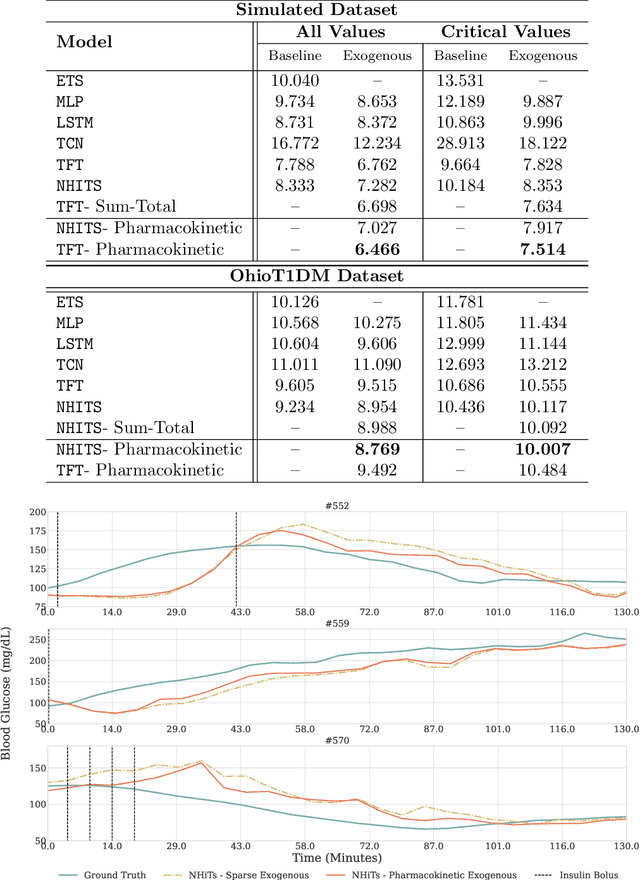
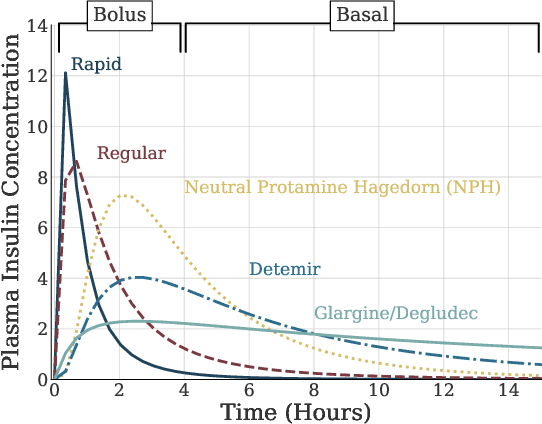
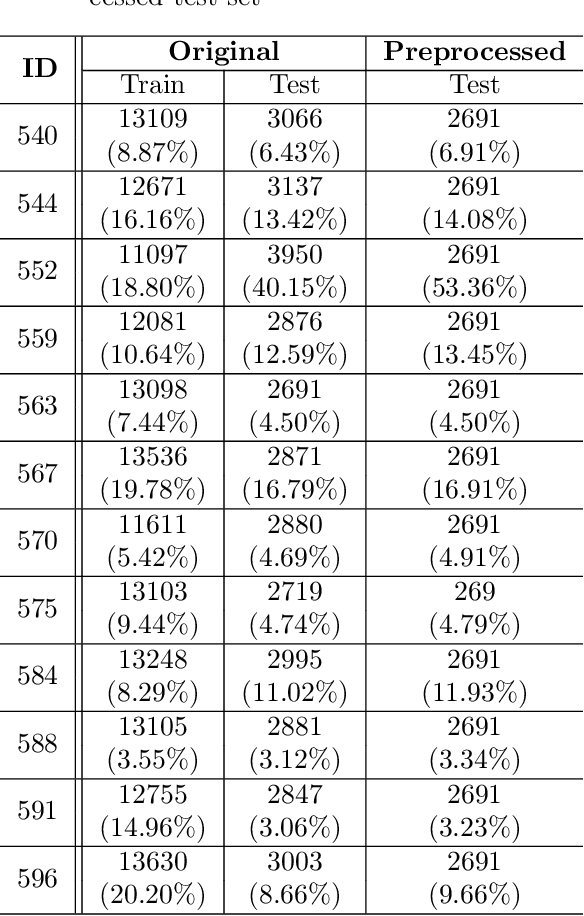
Forecasting healthcare time series is crucial for early detection of adverse outcomes and for patient monitoring. Forecasting, however, can be difficult in practice due to noisy and intermittent data. The challenges are often exacerbated by change points induced via extrinsic factors, such as the administration of medication. We propose a novel encoder that informs deep learning models of the pharmacokinetic effects of drugs to allow for accurate forecasting of time series affected by treatment. We showcase the effectiveness of our approach in a task to forecast blood glucose using both realistically simulated and real-world data. Our pharmacokinetic encoder helps deep learning models surpass baselines by approximately 11% on simulated data and 8% on real-world data. The proposed approach can have multiple beneficial applications in clinical practice, such as issuing early warnings about unexpected treatment responses, or helping to characterize patient-specific treatment effects in terms of drug absorption and elimination characteristics.
Learning Generative Models for Climbing Aircraft from Radar Data
Sep 26, 2023Accurate trajectory prediction (TP) for climbing aircraft is hampered by the presence of epistemic uncertainties concerning aircraft operation, which can lead to significant misspecification between predicted and observed trajectories. This paper proposes a generative model for climbing aircraft in which the standard Base of Aircraft Data (BADA) model is enriched by a functional correction to the thrust that is learned from data. The method offers three features: predictions of the arrival time with 66.3% less error when compared to BADA; generated trajectories that are realistic when compared to test data; and a means of computing confidence bounds for minimal computational cost.
KV Inversion: KV Embeddings Learning for Text-Conditioned Real Image Action Editing
Sep 28, 2023
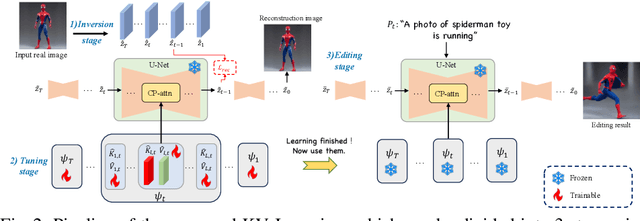


Text-conditioned image editing is a recently emerged and highly practical task, and its potential is immeasurable. However, most of the concurrent methods are unable to perform action editing, i.e. they can not produce results that conform to the action semantics of the editing prompt and preserve the content of the original image. To solve the problem of action editing, we propose KV Inversion, a method that can achieve satisfactory reconstruction performance and action editing, which can solve two major problems: 1) the edited result can match the corresponding action, and 2) the edited object can retain the texture and identity of the original real image. In addition, our method does not require training the Stable Diffusion model itself, nor does it require scanning a large-scale dataset to perform time-consuming training.
SLM: Bridge the thin gap between speech and text foundation models
Sep 30, 2023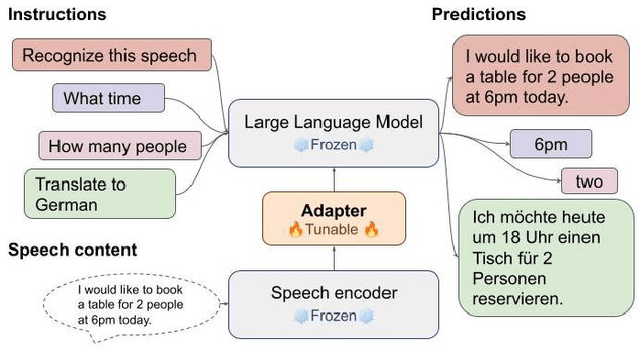
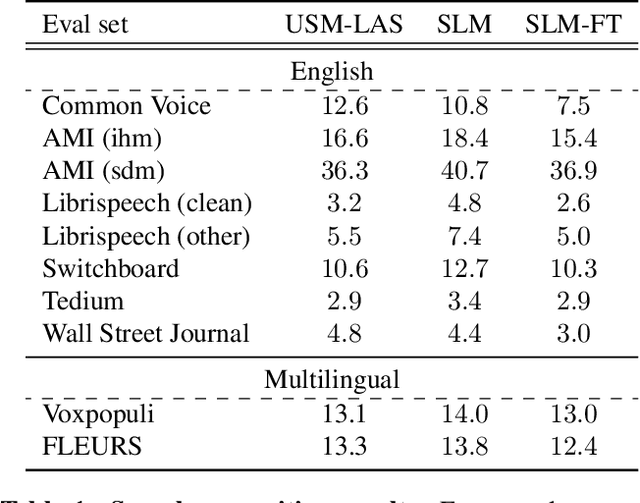
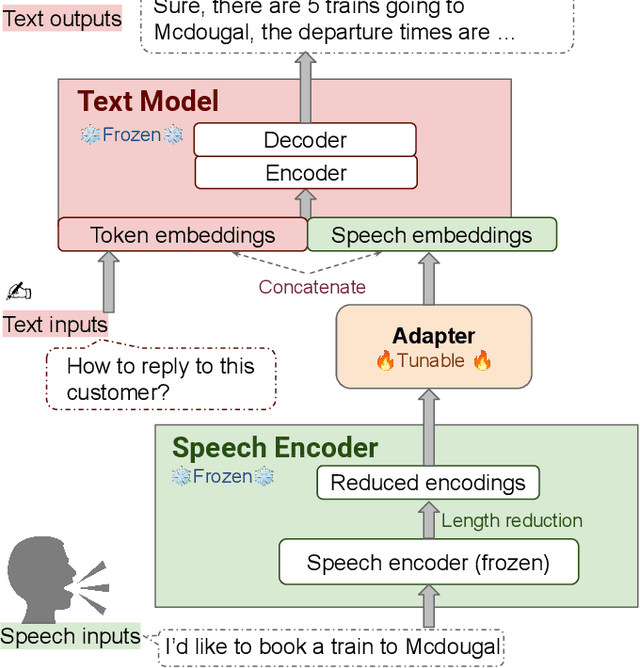
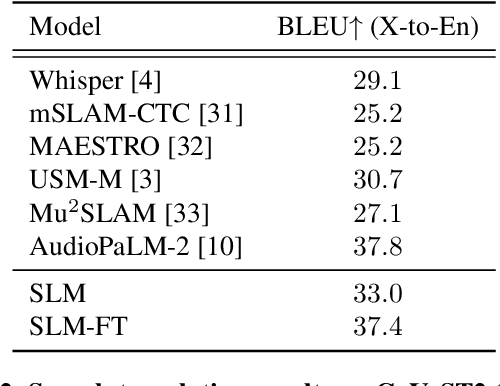
We present a joint Speech and Language Model (SLM), a multitask, multilingual, and dual-modal model that takes advantage of pretrained foundational speech and language models. SLM freezes the pretrained foundation models to maximally preserves their capabilities, and only trains a simple adapter with just 1\% (156M) of the foundation models' parameters. This adaptation not only leads SLM to achieve strong performance on conventional tasks such as speech recognition (ASR) and speech translation (AST), but also introduces the novel capability of zero-shot instruction-following for more diverse tasks: given a speech input and a text instruction, SLM is able to perform unseen generation tasks including contextual biasing ASR using real-time context, dialog generation, speech continuation, and question answering, etc. Our approach demonstrates that the representational gap between pretrained speech and language models might be narrower than one would expect, and can be bridged by a simple adaptation mechanism. As a result, SLM is not only efficient to train, but also inherits strong capabilities already acquired in foundation models of different modalities.