 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Processing of Tri-Plane Hybrid Neural Fields
Oct 02, 2023
Driven by the appealing properties of neural fields for storing and communicating 3D data, the problem of directly processing them to address tasks such as classification and part segmentation has emerged and has been investigated in recent works. Early approaches employ neural fields parameterized by shared networks trained on the whole dataset, achieving good task performance but sacrificing reconstruction quality. To improve the latter, later methods focus on individual neural fields parameterized as large Multi-Layer Perceptrons (MLPs), which are, however, challenging to process due to the high dimensionality of the weight space, intrinsic weight space symmetries, and sensitivity to random initialization. Hence, results turn out significantly inferior to those achieved by processing explicit representations, e.g., point clouds or meshes. In the meantime, hybrid representations, in particular based on tri-planes, have emerged as a more effective and efficient alternative to realize neural fields, but their direct processing has not been investigated yet. In this paper, we show that the tri-plane discrete data structure encodes rich information, which can be effectively processed by standard deep-learning machinery. We define an extensive benchmark covering a diverse set of fields such as occupancy, signed/unsigned distance, and, for the first time, radiance fields. While processing a field with the same reconstruction quality, we achieve task performance far superior to frameworks that process large MLPs and, for the first time, almost on par with architectures handling explicit representations.
TimePool: Visually Answer "Which and When" Questions On Univariate Time Series
Aug 01, 2023
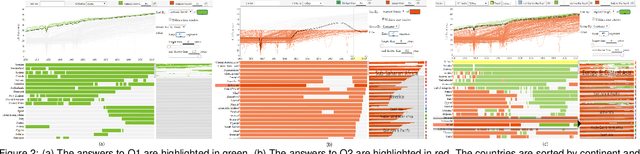
When exploring time series datasets, analysts often pose "which and when" questions. For example, with world life expectancy data over one hundred years, they may inquire about the top 10 countries in life expectancy and the time period when they achieved this status, or which countries have had longer life expectancy than Ireland and when. This paper proposes TimePool, a new visualization prototype, to address this need for univariate time series analysis. It allows users to construct interactive "which and when" queries and visually explore the results for insights.
Provably Efficient Exploration in Constrained Reinforcement Learning:Posterior Sampling Is All You Need
Sep 27, 2023We present a new algorithm based on posterior sampling for learning in constrained Markov decision processes (CMDP) in the infinite-horizon undiscounted setting. The algorithm achieves near-optimal regret bounds while being advantageous empirically compared to the existing algorithms. Our main theoretical result is a Bayesian regret bound for each cost component of \tilde{O} (HS \sqrt{AT}) for any communicating CMDP with S states, A actions, and bound on the hitting time H. This regret bound matches the lower bound in order of time horizon T and is the best-known regret bound for communicating CMDPs in the infinite-horizon undiscounted setting. Empirical results show that, despite its simplicity, our posterior sampling algorithm outperforms the existing algorithms for constrained reinforcement learning.
A Hybrid Approach To Real-Time Multi-Object Tracking
Aug 02, 2023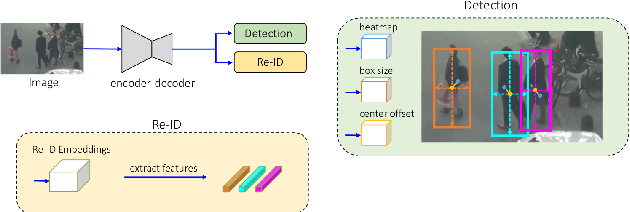
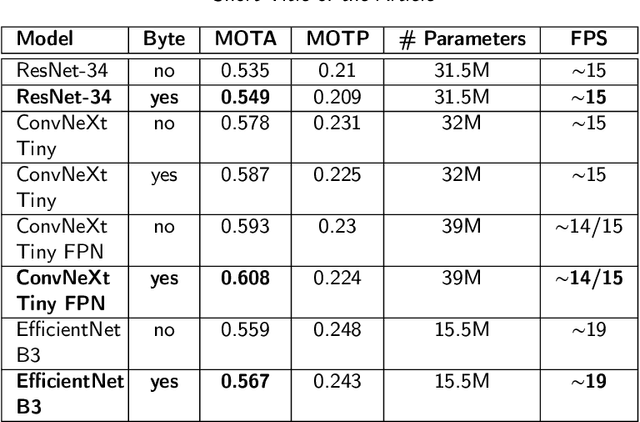

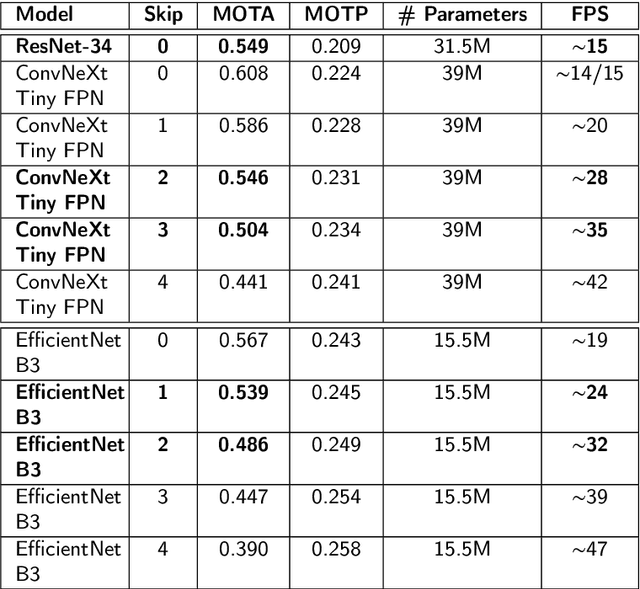
Multi-Object Tracking, also known as Multi-Target Tracking, is a significant area of computer vision that has many uses in a variety of settings. The development of deep learning, which has encouraged researchers to propose more and more work in this direction, has significantly impacted the scientific advancement around the study of tracking as well as many other domains related to computer vision. In fact, all of the solutions that are currently state-of-the-art in the literature and in the tracking industry, are built on top of deep learning methodologies that produce exceptionally good results. Deep learning is enabled thanks to the ever more powerful technology researchers can use to handle the significant computational resources demanded by these models. However, when real-time is a main requirement, developing a tracking system without being constrained by expensive hardware support with enormous computational resources is necessary to widen tracking applications in real-world contexts. To this end, a compromise is to combine powerful deep strategies with more traditional approaches to favor considerably lower processing solutions at the cost of less accurate tracking results even though suitable for real-time domains. Indeed, the present work goes in that direction, proposing a hybrid strategy for real-time multi-target tracking that combines effectively a classical optical flow algorithm with a deep learning architecture, targeted to a human-crowd tracking system exhibiting a desirable trade-off between performance in tracking precision and computational costs. The developed architecture was experimented with different settings, and yielded a MOTA of 0.608 out of the compared state-of-the-art 0.549 results, and about half the running time when introducing the optical flow phase, achieving almost the same performance in terms of accuracy.
Statistical Hypothesis Testing for Information Value (IV)
Sep 30, 2023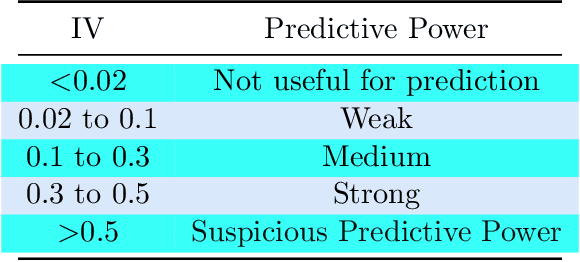
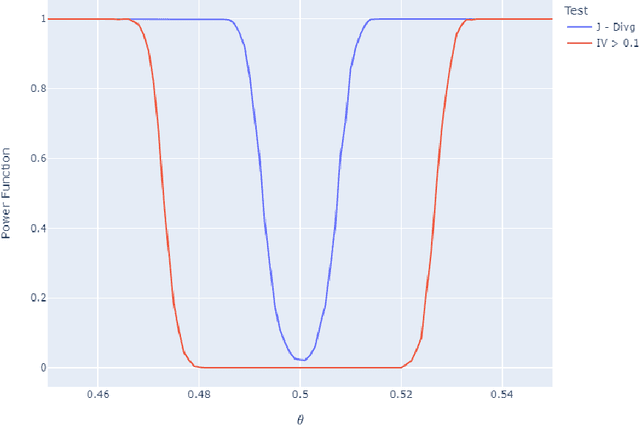
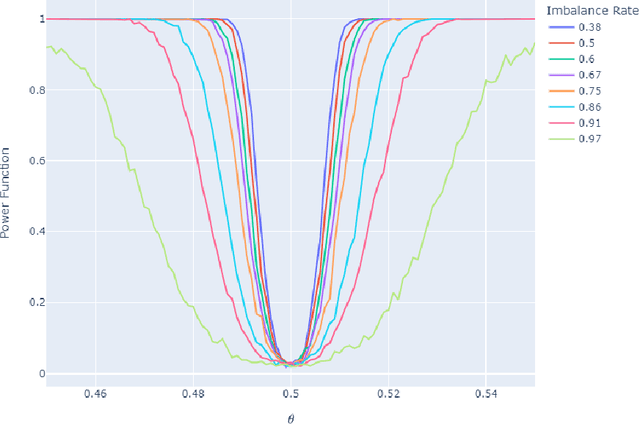

Information value (IV) is a quite popular technique for features selection before the modeling phase. There are practical criteria, based on fixed thresholds for IV, but at the same time mysterious and lacking theoretical arguments, to decide if a predictor has sufficient predictive power to be considered in the modeling phase. However, the mathematical development and statistical inference methods for this technique are almost nonexistent in the literature. In this paper we present a theoretical framework for IV, and at the same time, we propose a non-parametric hypothesis test to evaluate the predictive power of features contemplated in a data set. Due to its relationship with divergence measures developed in the Information Theory, we call our proposal the J - Divergence test. We show how to efficiently compute our test statistic and we study its performance on simulated data. In various scenarios, particularly in unbalanced data sets, we show its superiority over conventional criteria based on fixed thresholds. Furthermore, we apply our test on fraud identification data and provide an open-source Python library, called "statistical-iv"(https://pypi.org/project/statistical-iv/), where we implement our main results.
NeuralFastLAS: Fast Logic-Based Learning from Raw Data
Oct 08, 2023Symbolic rule learners generate interpretable solutions, however they require the input to be encoded symbolically. Neuro-symbolic approaches overcome this issue by mapping raw data to latent symbolic concepts using a neural network. Training the neural and symbolic components jointly is difficult, due to slow and unstable learning, hence many existing systems rely on hand-engineered rules to train the network. We introduce NeuralFastLAS, a scalable and fast end-to-end approach that trains a neural network jointly with a symbolic learner. For a given task, NeuralFastLAS computes a relevant set of rules, proved to contain an optimal symbolic solution, trains a neural network using these rules, and finally finds an optimal symbolic solution to the task while taking network predictions into account. A key novelty of our approach is learning a posterior distribution on rules while training the neural network to improve stability during training. We provide theoretical results for a sufficient condition on network training to guarantee correctness of the final solution. Experimental results demonstrate that NeuralFastLAS is able to achieve state-of-the-art accuracy in arithmetic and logical tasks, with a training time that is up to two orders of magnitude faster than other jointly trained neuro-symbolic methods.
CARLG: Leveraging Contextual Clues and Role Correlations for Improving Document-level Event Argument Extraction
Oct 08, 2023
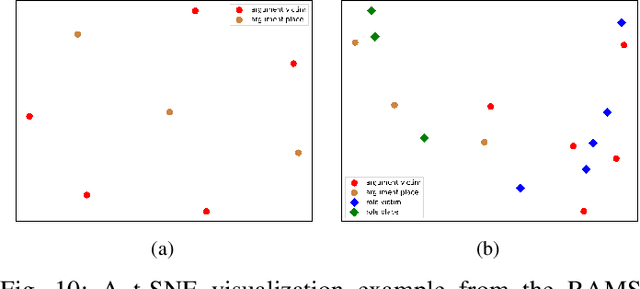
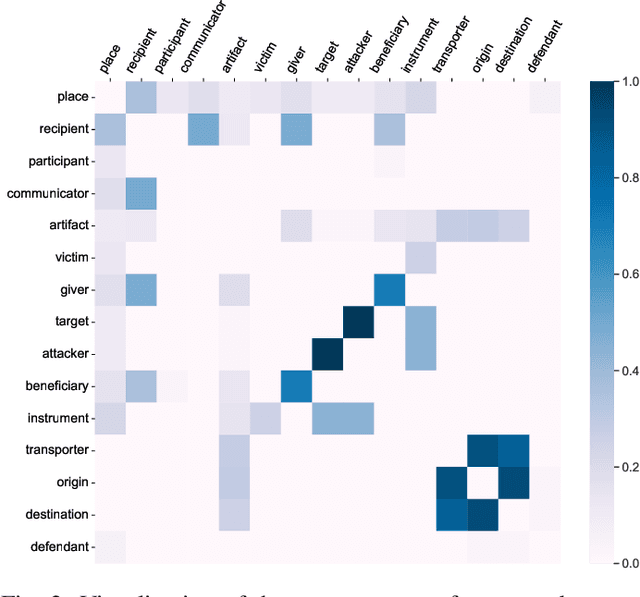
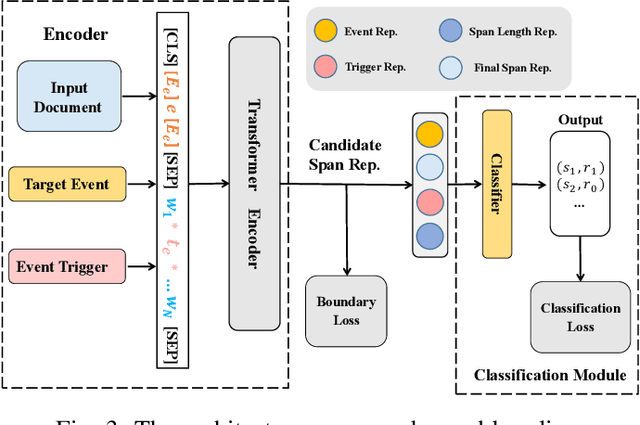
Document-level event argument extraction (EAE) is a crucial but challenging subtask in information extraction. Most existing approaches focus on the interaction between arguments and event triggers, ignoring two critical points: the information of contextual clues and the semantic correlations among argument roles. In this paper, we propose the CARLG model, which consists of two modules: Contextual Clues Aggregation (CCA) and Role-based Latent Information Guidance (RLIG), effectively leveraging contextual clues and role correlations for improving document-level EAE. The CCA module adaptively captures and integrates contextual clues by utilizing context attention weights from a pre-trained encoder. The RLIG module captures semantic correlations through role-interactive encoding and provides valuable information guidance with latent role representation. Notably, our CCA and RLIG modules are compact, transplantable and efficient, which introduce no more than 1% new parameters and can be easily equipped on other span-base methods with significant performance boost. Extensive experiments on the RAMS, WikiEvents, and MLEE datasets demonstrate the superiority of the proposed CARLG model. It outperforms previous state-of-the-art approaches by 1.26 F1, 1.22 F1, and 1.98 F1, respectively, while reducing the inference time by 31%. Furthermore, we provide detailed experimental analyses based on the performance gains and illustrate the interpretability of our model.
Enhancing Kernel Flexibility via Learning Asymmetric Locally-Adaptive Kernels
Oct 08, 2023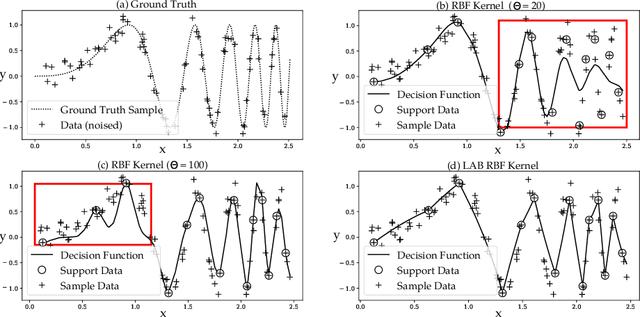
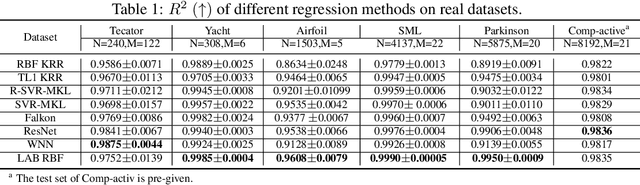
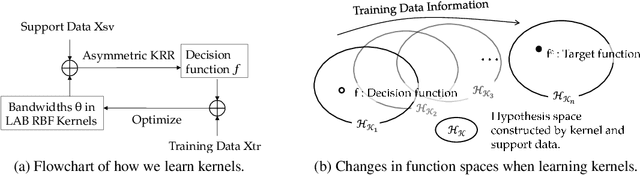
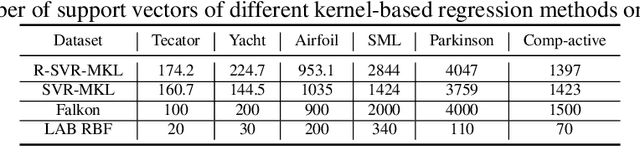
The lack of sufficient flexibility is the key bottleneck of kernel-based learning that relies on manually designed, pre-given, and non-trainable kernels. To enhance kernel flexibility, this paper introduces the concept of Locally-Adaptive-Bandwidths (LAB) as trainable parameters to enhance the Radial Basis Function (RBF) kernel, giving rise to the LAB RBF kernel. The parameters in LAB RBF kernels are data-dependent, and its number can increase with the dataset, allowing for better adaptation to diverse data patterns and enhancing the flexibility of the learned function. This newfound flexibility also brings challenges, particularly with regards to asymmetry and the need for an efficient learning algorithm. To address these challenges, this paper for the first time establishes an asymmetric kernel ridge regression framework and introduces an iterative kernel learning algorithm. This novel approach not only reduces the demand for extensive support data but also significantly improves generalization by training bandwidths on the available training data. Experimental results on real datasets underscore the remarkable performance of the proposed algorithm, showcasing its superior capability in handling large-scale datasets compared to Nystr\"om approximation-based algorithms. Moreover, it demonstrates a significant improvement in regression accuracy over existing kernel-based learning methods and even surpasses residual neural networks.
A Fisher-Rao gradient flow for entropy-regularised Markov decision processes in Polish spaces
Oct 04, 2023We study the global convergence of a Fisher-Rao policy gradient flow for infinite-horizon entropy-regularised Markov decision processes with Polish state and action space. The flow is a continuous-time analogue of a policy mirror descent method. We establish the global well-posedness of the gradient flow and demonstrate its exponential convergence to the optimal policy. Moreover, we prove the flow is stable with respect to gradient evaluation, offering insights into the performance of a natural policy gradient flow with log-linear policy parameterisation. To overcome challenges stemming from the lack of the convexity of the objective function and the discontinuity arising from the entropy regulariser, we leverage the performance difference lemma and the duality relationship between the gradient and mirror descent flows.
Speech-Based Human-Exoskeleton Interaction for Lower Limb Motion Planning
Oct 04, 2023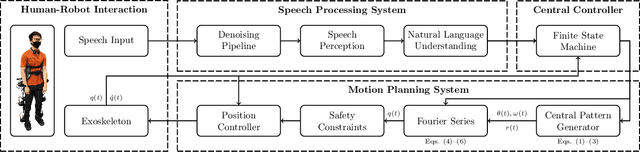

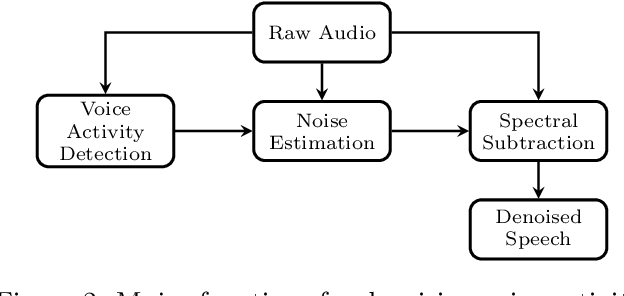
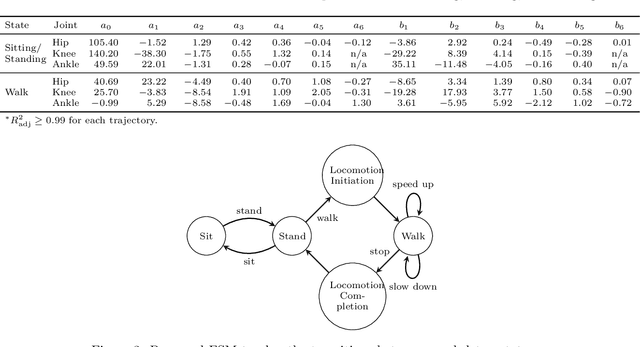
This study presents a speech-based motion planning strategy (SBMP) developed for lower limb exoskeletons to facilitate safe and compliant human-robot interaction. A speech processing system, finite state machine, and central pattern generator are the building blocks of the proposed strategy for online planning of the exoskeleton's trajectory. According to experimental evaluations, this speech-processing system achieved low levels of word and intent errors. Regarding locomotion, the completion time for users with voice commands was 54% faster than that using a mobile app interface. With the proposed SBMP, users are able to maintain their postural stability with both hands-free. This supports its use as an effective motion planning method for the assistance and rehabilitation of individuals with lower-limb impairments.