 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Understanding the Robustness of Randomized Feature Defense Against Query-Based Adversarial Attacks
Oct 01, 2023
Recent works have shown that deep neural networks are vulnerable to adversarial examples that find samples close to the original image but can make the model misclassify. Even with access only to the model's output, an attacker can employ black-box attacks to generate such adversarial examples. In this work, we propose a simple and lightweight defense against black-box attacks by adding random noise to hidden features at intermediate layers of the model at inference time. Our theoretical analysis confirms that this method effectively enhances the model's resilience against both score-based and decision-based black-box attacks. Importantly, our defense does not necessitate adversarial training and has minimal impact on accuracy, rendering it applicable to any pre-trained model. Our analysis also reveals the significance of selectively adding noise to different parts of the model based on the gradient of the adversarial objective function, which can be varied during the attack. We demonstrate the robustness of our defense against multiple black-box attacks through extensive empirical experiments involving diverse models with various architectures.
GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length
Oct 01, 2023The evolving sophistication and intricacies of Large Language Models (LLMs) yield unprecedented advancements, yet they simultaneously demand considerable computational resources and incur significant costs. To alleviate these challenges, this paper introduces a novel, simple, and effective method named ``\growlength'' to accelerate the pretraining process of LLMs. Our method progressively increases the training length throughout the pretraining phase, thereby mitigating computational costs and enhancing efficiency. For instance, it begins with a sequence length of 128 and progressively extends to 4096. This approach enables models to process a larger number of tokens within limited time frames, potentially boosting their performance. In other words, the efficiency gain is derived from training with shorter sequences optimizing the utilization of resources. Our extensive experiments with various state-of-the-art LLMs have revealed that models trained using our method not only converge more swiftly but also exhibit superior performance metrics compared to those trained with existing methods. Furthermore, our method for LLMs pretraining acceleration does not require any additional engineering efforts, making it a practical solution in the realm of LLMs.
Sharingan: A Transformer-based Architecture for Gaze Following
Oct 01, 2023Gaze is a powerful form of non-verbal communication and social interaction that humans develop from an early age. As such, modeling this behavior is an important task that can benefit a broad set of application domains ranging from robotics to sociology. In particular, Gaze Following is defined as the prediction of the pixel-wise 2D location where a person in the image is looking. Prior efforts in this direction have focused primarily on CNN-based architectures to perform the task. In this paper, we introduce a novel transformer-based architecture for 2D gaze prediction. We experiment with 2 variants: the first one retains the same task formulation of predicting a gaze heatmap for one person at a time, while the second one casts the problem as a 2D point regression and allows us to perform multi-person gaze prediction with a single forward pass. This new architecture achieves state-of-the-art results on the GazeFollow and VideoAttentionTarget datasets. The code for this paper will be made publicly available.
Quantum image edge detection based on eight-direction Sobel operator for NEQR
Oct 01, 2023Quantum Sobel edge detection (QSED) is a kind of algorithm for image edge detection using quantum mechanism, which can solve the real-time problem encountered by classical algorithms. However, the existing QSED algorithms only consider two- or four-direction Sobel operator, which leads to a certain loss of edge detail information in some high-definition images. In this paper, a novel QSED algorithm based on eight-direction Sobel operator is proposed, which not only reduces the loss of edge information, but also simultaneously calculates eight directions' gradient values of all pixel in a quantum image. In addition, the concrete quantum circuits, which consist of gradient calculation, non-maximum suppression, double threshold detection and edge tracking units, are designed in details. For a 2^n x 2^n image with q gray scale, the complexity of our algorithm can be reduced to O(n^2 + q^2), which is lower than other existing classical or quantum algorithms. And the simulation experiment demonstrates that our algorithm can detect more edge information, especially diagonal edges, than the two- and four-direction QSED algorithms.
* 27 pages, 20 figures
Think before you speak: Training Language Models With Pause Tokens
Oct 03, 2023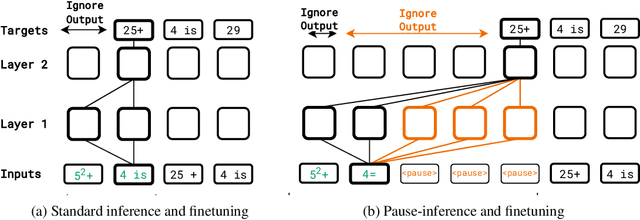
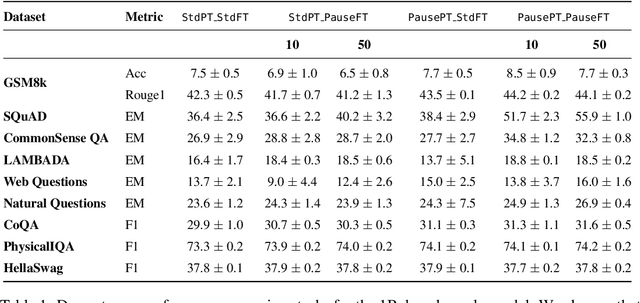
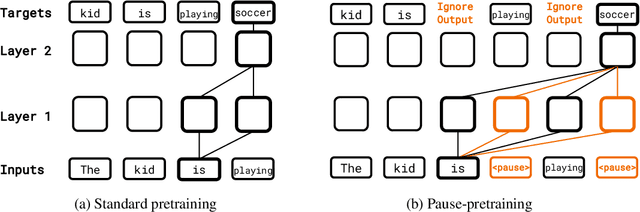
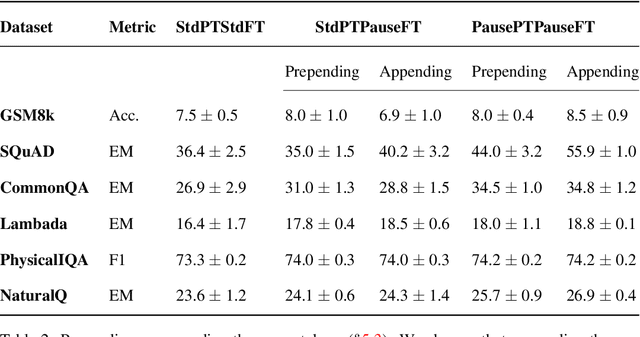
Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $\textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $\textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18\%$ EM score on the QA task of SQuAD, $8\%$ on CommonSenseQA and $1\%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization
Oct 03, 2023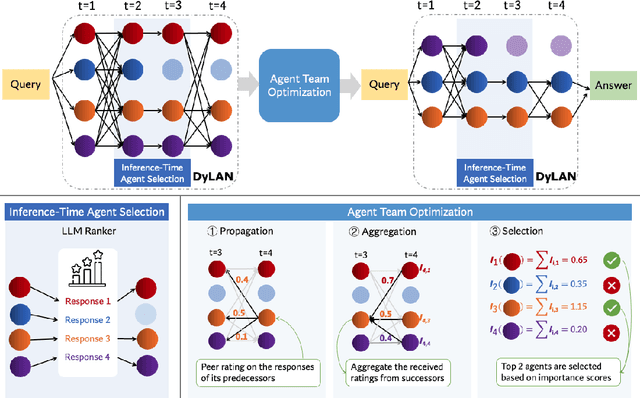
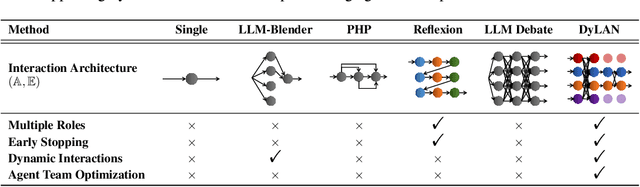

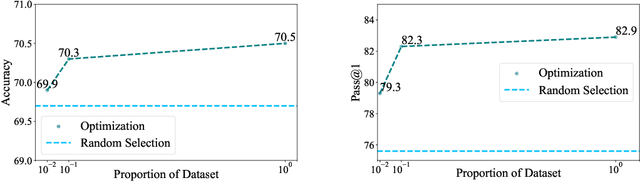
Large language model (LLM) agents have been shown effective on a wide range of tasks, and by ensembling multiple LLM agents, their performances could be further improved. Existing approaches employ a fixed set of agents to interact with each other in a static architecture, which limits their generalizability to various tasks and requires strong human prior in designing these agents. In this work, we propose to construct a strategic team of agents communicating in a dynamic interaction architecture based on the task query. Specifically, we build a framework named Dynamic LLM-Agent Network ($\textbf{DyLAN}$) for LLM-agent collaboration on complicated tasks like reasoning and code generation. DyLAN enables agents to interact for multiple rounds in a dynamic architecture with inference-time agent selection and an early-stopping mechanism to improve performance and efficiency. We further design an automatic agent team optimization algorithm based on an unsupervised metric termed $\textit{Agent Importance Score}$, enabling the selection of best agents based on the contribution each agent makes. Empirically, we demonstrate that DyLAN performs well in both reasoning and code generation tasks with reasonable computational cost. DyLAN achieves 13.0% and 13.3% improvement on MATH and HumanEval, respectively, compared to a single execution on GPT-35-turbo. On specific subjects of MMLU, agent team optimization in DyLAN increases accuracy by up to 25.0%.
MIMO-NeRF: Fast Neural Rendering with Multi-input Multi-output Neural Radiance Fields
Oct 03, 2023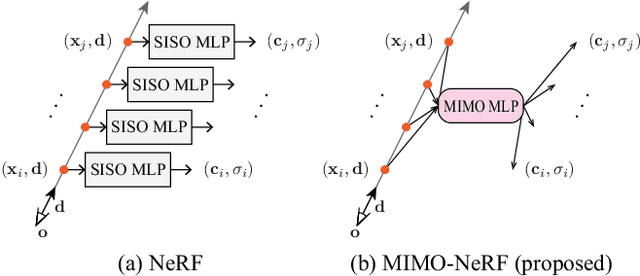
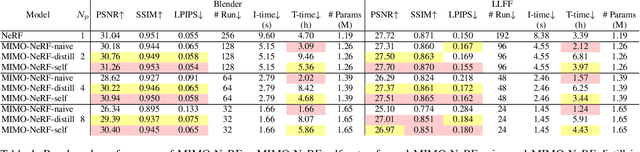
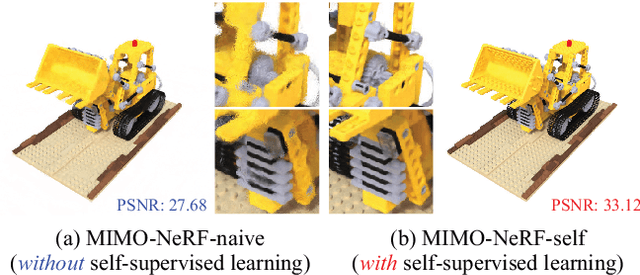
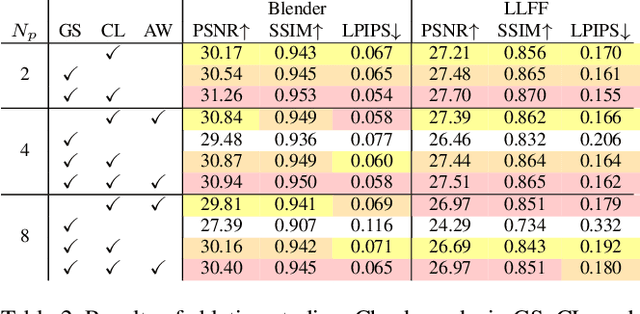
Neural radiance fields (NeRFs) have shown impressive results for novel view synthesis. However, they depend on the repetitive use of a single-input single-output multilayer perceptron (SISO MLP) that maps 3D coordinates and view direction to the color and volume density in a sample-wise manner, which slows the rendering. We propose a multi-input multi-output NeRF (MIMO-NeRF) that reduces the number of MLPs running by replacing the SISO MLP with a MIMO MLP and conducting mappings in a group-wise manner. One notable challenge with this approach is that the color and volume density of each point can differ according to a choice of input coordinates in a group, which can lead to some notable ambiguity. We also propose a self-supervised learning method that regularizes the MIMO MLP with multiple fast reformulated MLPs to alleviate this ambiguity without using pretrained models. The results of a comprehensive experimental evaluation including comparative and ablation studies are presented to show that MIMO-NeRF obtains a good trade-off between speed and quality with a reasonable training time. We then demonstrate that MIMO-NeRF is compatible with and complementary to previous advancements in NeRFs by applying it to two representative fast NeRFs, i.e., a NeRF with sample reduction (DONeRF) and a NeRF with alternative representations (TensoRF).
TempoNet: Empowering long-term Knee Joint Angle Prediction with Dynamic Temporal Attention in Exoskeleton Control
Oct 03, 2023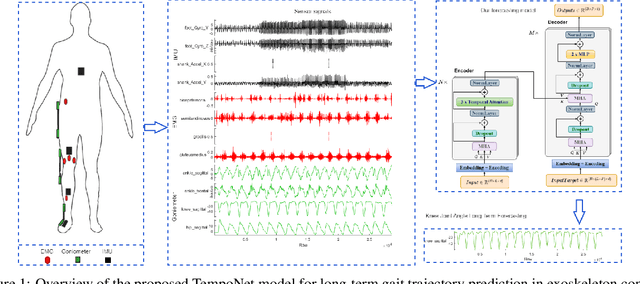
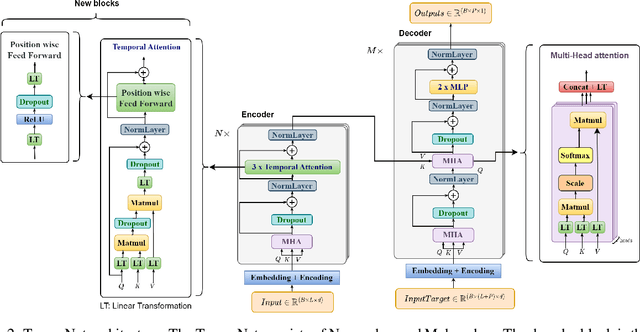
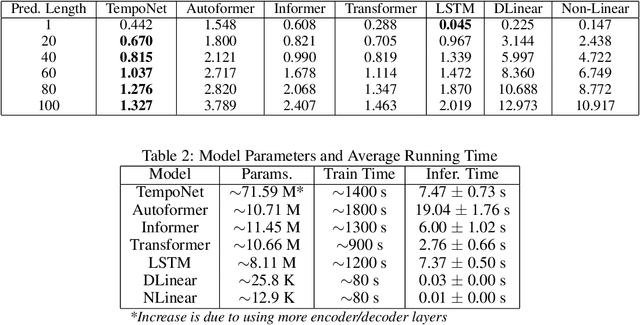
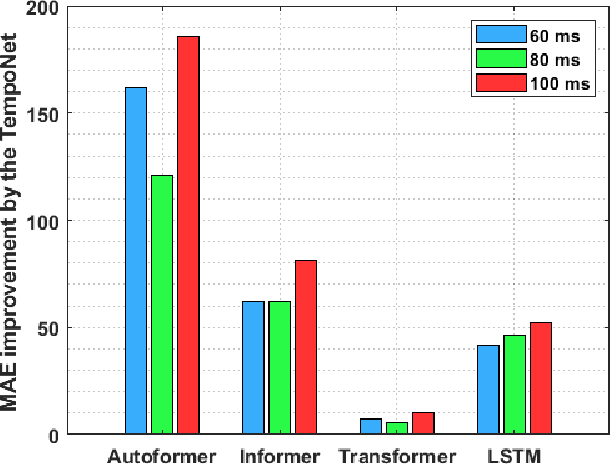
In the realm of exoskeleton control, achieving precise control poses challenges due to the mechanical delay of exoskeletons. To address this, incorporating future gait trajectories as feed-forward input has been proposed. However, existing deep learning models for gait prediction mainly focus on short-term predictions, leaving the long-term performance of these models relatively unexplored. In this study, we present TempoNet, a novel model specifically designed for precise knee joint angle prediction. By harnessing dynamic temporal attention within the Transformer-based architecture, TempoNet surpasses existing models in forecasting knee joint angles over extended time horizons. Notably, our model achieves a remarkable reduction of 10\% to 185\% in Mean Absolute Error (MAE) for 100 ms ahead forecasting compared to other transformer-based models, demonstrating its effectiveness. Furthermore, TempoNet exhibits further reliability and superiority over the baseline Transformer model, outperforming it by 14\% in MAE for the 200 ms prediction horizon. These findings highlight the efficacy of TempoNet in accurately predicting knee joint angles and emphasize the importance of incorporating dynamic temporal attention. TempoNet's capability to enhance knee joint angle prediction accuracy opens up possibilities for precise control, improved rehabilitation outcomes, advanced sports performance analysis, and deeper insights into biomechanical research. Code implementation for the TempoNet model can be found in the GitHub repository: https://github.com/LyesSaadSaoud/TempoNet.
Chunking: Forgetting Matters in Continual Learning even without Changing Tasks
Oct 03, 2023Work on continual learning (CL) has largely focused on the problems arising from the dynamically-changing data distribution. However, CL can be decomposed into two sub-problems: (a) shifts in the data distribution, and (b) dealing with the fact that the data is split into chunks and so only a part of the data is available to be trained on at any point in time. In this work, we look at the latter sub-problem -- the chunking of data -- and note that previous analysis of chunking in the CL literature is sparse. We show that chunking is an important part of CL, accounting for around half of the performance drop from offline learning in our experiments. Furthermore, our results reveal that current CL algorithms do not address the chunking sub-problem, only performing as well as plain SGD training when there is no shift in the data distribution. We analyse why performance drops when learning occurs on chunks of data, and find that forgetting, which is often seen to be a problem due to distribution shift, still arises and is a significant problem. Motivated by an analysis of the linear case, we show that per-chunk weight averaging improves performance in the chunking setting and that this performance transfers to the full CL setting. Hence, we argue that work on chunking can help advance CL in general.
aSAGA: Automatic Sleep Analysis with Gray Areas
Oct 03, 2023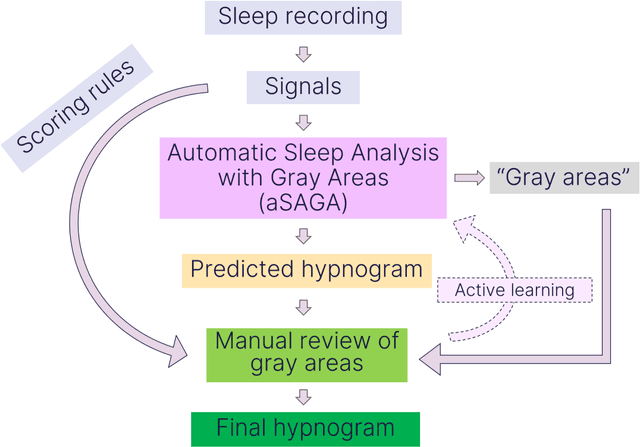
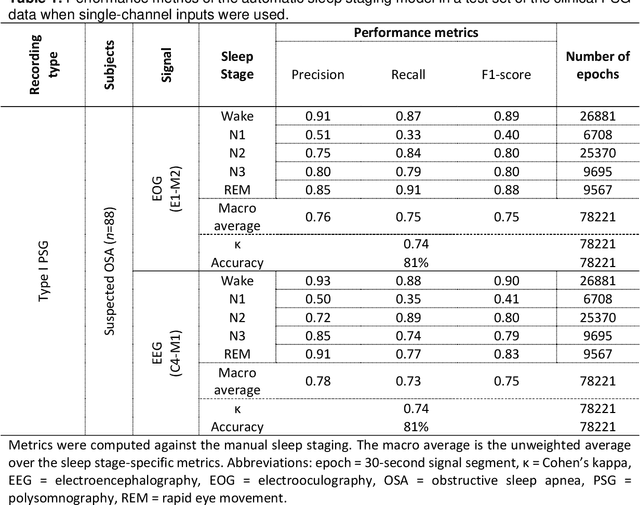
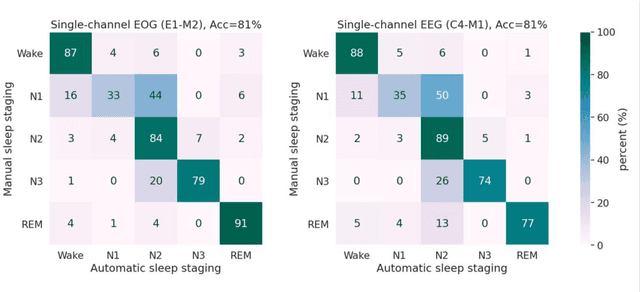
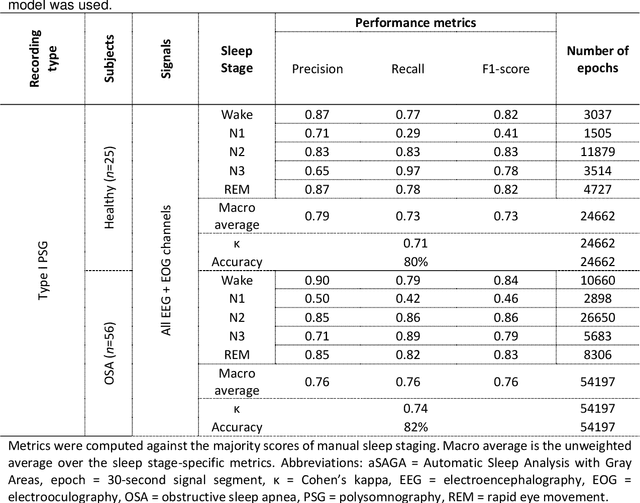
State-of-the-art automatic sleep staging methods have already demonstrated comparable reliability and superior time efficiency to manual sleep staging. However, fully automatic black-box solutions are difficult to adapt into clinical workflow and the interaction between explainable automatic methods and the work of sleep technologists remains underexplored and inadequately conceptualized. Thus, we propose a human-in-the-loop concept for sleep analysis, presenting an automatic sleep staging model (aSAGA), that performs effectively with both clinical polysomnographic recordings and home sleep studies. To validate the model, extensive testing was conducted, employing a preclinical validation approach with three retrospective datasets; open-access, clinical, and research-driven. Furthermore, we validate the utilization of uncertainty mapping to identify ambiguous regions, conceptualized as gray areas, in automatic sleep analysis that warrants manual re-evaluation. The results demonstrate that the automatic sleep analysis achieved a comparable level of agreement with manual analysis across different sleep recording types. Moreover, validation of the gray area concept revealed its potential to enhance sleep staging accuracy and identify areas in the recordings where sleep technologists struggle to reach a consensus. In conclusion, this study introduces and validates a concept from explainable artificial intelligence into sleep medicine and provides the basis for integrating human-in-the-loop automatic sleep staging into clinical workflows, aiming to reduce black-box criticism and the burden associated with manual sleep staging.