 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Digital Twin-Empowered Smart Attack Detection System for 6G Edge of Things Networks
Oct 05, 2023
As global Internet of Things (IoT) devices connectivity surges, a significant portion gravitates towards the Edge of Things (EoT) network. This shift prompts businesses to deploy infrastructure closer to end-users, enhancing accessibility. However, the growing EoT network expands the attack surface, necessitating robust and proactive security measures. Traditional solutions fall short against dynamic EoT threats, highlighting the need for proactive and intelligent systems. We introduce a digital twin-empowered smart attack detection system for 6G EoT networks. Leveraging digital twin and edge computing, it monitors and simulates physical assets in real time, enhancing security. An online learning module in the proposed system optimizes the network performance. Our system excels in proactive threat detection, ensuring 6G EoT network security. The performance evaluations demonstrate its effectiveness, robustness, and adaptability using real datasets.
Taming Binarized Neural Networks and Mixed-Integer Programs
Oct 05, 2023There has been a great deal of recent interest in binarized neural networks, especially because of their explainability. At the same time, automatic differentiation algorithms such as backpropagation fail for binarized neural networks, which limits their applicability. By reformulating the problem of training binarized neural networks as a subadditive dual of a mixed-integer program, we show that binarized neural networks admit a tame representation. This, in turn, makes it possible to use the framework of Bolte et al. for implicit differentiation, which offers the possibility for practical implementation of backpropagation in the context of binarized neural networks. This approach could also be used for a broader class of mixed-integer programs, beyond the training of binarized neural networks, as encountered in symbolic approaches to AI and beyond.
A Comprehensive Indoor Environment Dataset from Single-family Houses in the US
Oct 05, 2023The paper describes a dataset comprising indoor environmental factors such as temperature, humidity, air quality, and noise levels. The data was collected from 10 sensing devices installed in various locations within three single-family houses in Virginia, USA. The objective of the data collection was to study the indoor environmental conditions of the houses over time. The data were collected at a frequency of one record per minute for a year, combining over 2.5 million records. The paper provides actual floor plans with sensor placements to aid researchers and practitioners in creating reliable building performance models. The techniques used to collect and verify the data are also explained in the paper. The resulting dataset can be employed to enhance models for building energy consumption, occupant behavior, predictive maintenance, and other relevant purposes.
Asynchronous Graph Generators
Sep 29, 2023We introduce the asynchronous graph generator (AGG), a novel graph neural network architecture for multi-channel time series which models observations as nodes on a dynamic graph and can thus perform data imputation by transductive node generation. Completely free from recurrent components or assumptions about temporal regularity, AGG represents measurements, timestamps and metadata directly in the nodes via learnable embeddings, to then leverage attention to learn expressive relationships across the variables of interest. This way, the proposed architecture implicitly learns a causal graph representation of sensor measurements which can be conditioned on unseen timestamps and metadata to predict new measurements by an expansion of the learnt graph. The proposed AGG is compared both conceptually and empirically to previous work, and the impact of data augmentation on the performance of AGG is also briefly discussed. Our experiments reveal that AGG achieved state-of-the-art results in time series data imputation, classification and prediction for the benchmark datasets Beijing Air Quality, PhysioNet Challenge 2012 and UCI localisation.
Enhancing Representation Learning for Periodic Time Series with Floss: A Frequency Domain Regularization Approach
Aug 09, 2023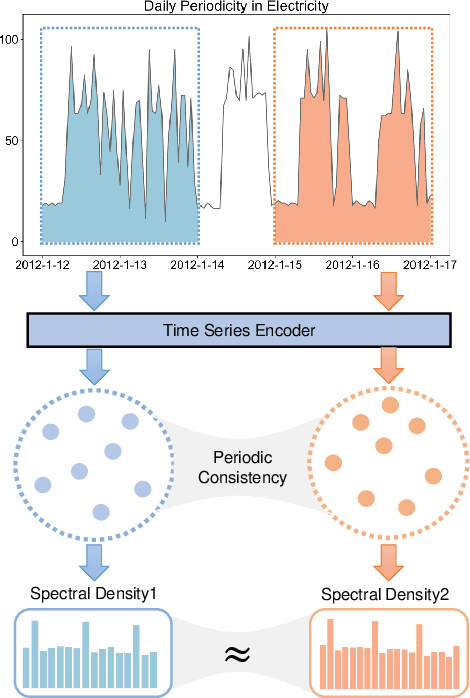

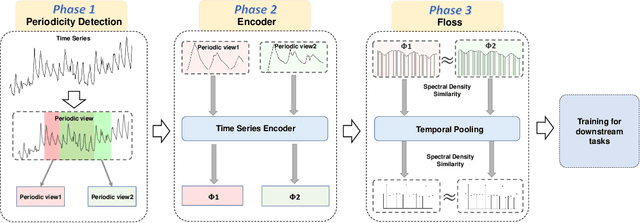
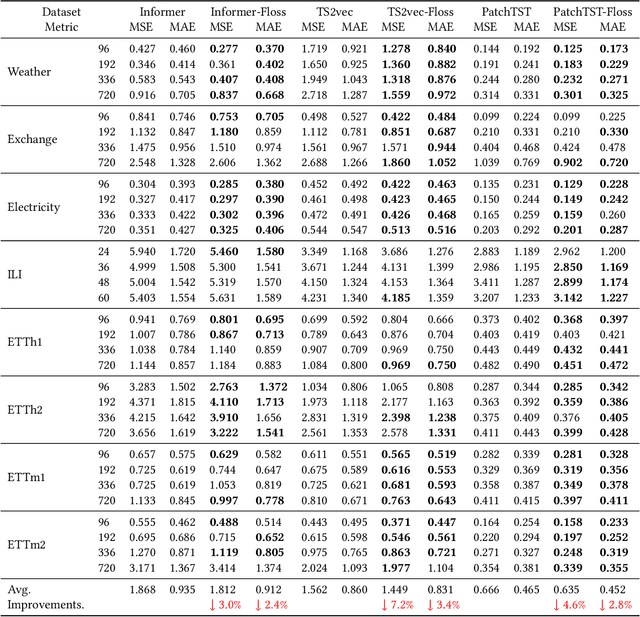
Time series analysis is a fundamental task in various application domains, and deep learning approaches have demonstrated remarkable performance in this area. However, many real-world time series data exhibit significant periodic or quasi-periodic dynamics that are often not adequately captured by existing deep learning-based solutions. This results in an incomplete representation of the underlying dynamic behaviors of interest. To address this gap, we propose an unsupervised method called Floss that automatically regularizes learned representations in the frequency domain. The Floss method first automatically detects major periodicities from the time series. It then employs periodic shift and spectral density similarity measures to learn meaningful representations with periodic consistency. In addition, Floss can be easily incorporated into both supervised, semi-supervised, and unsupervised learning frameworks. We conduct extensive experiments on common time series classification, forecasting, and anomaly detection tasks to demonstrate the effectiveness of Floss. We incorporate Floss into several representative deep learning solutions to justify our design choices and demonstrate that it is capable of automatically discovering periodic dynamics and improving state-of-the-art deep learning models.
Asynchrony-Robust Collaborative Perception via Bird's Eye View Flow
Oct 09, 2023Collaborative perception can substantially boost each agent's perception ability by facilitating communication among multiple agents. However, temporal asynchrony among agents is inevitable in the real world due to communication delays, interruptions, and clock misalignments. This issue causes information mismatch during multi-agent fusion, seriously shaking the foundation of collaboration. To address this issue, we propose CoBEVFlow, an asynchrony-robust collaborative perception system based on bird's eye view (BEV) flow. The key intuition of CoBEVFlow is to compensate motions to align asynchronous collaboration messages sent by multiple agents. To model the motion in a scene, we propose BEV flow, which is a collection of the motion vector corresponding to each spatial location. Based on BEV flow, asynchronous perceptual features can be reassigned to appropriate positions, mitigating the impact of asynchrony. CoBEVFlow has two advantages: (i) CoBEVFlow can handle asynchronous collaboration messages sent at irregular, continuous time stamps without discretization; and (ii) with BEV flow, CoBEVFlow only transports the original perceptual features, instead of generating new perceptual features, avoiding additional noises. To validate CoBEVFlow's efficacy, we create IRregular V2V(IRV2V), the first synthetic collaborative perception dataset with various temporal asynchronies that simulate different real-world scenarios. Extensive experiments conducted on both IRV2V and the real-world dataset DAIR-V2X show that CoBEVFlow consistently outperforms other baselines and is robust in extremely asynchronous settings. The code is available at https://github.com/MediaBrain-SJTU/CoBEVFlow.
Automating Customer Service using LangChain: Building custom open-source GPT Chatbot for organizations
Oct 09, 2023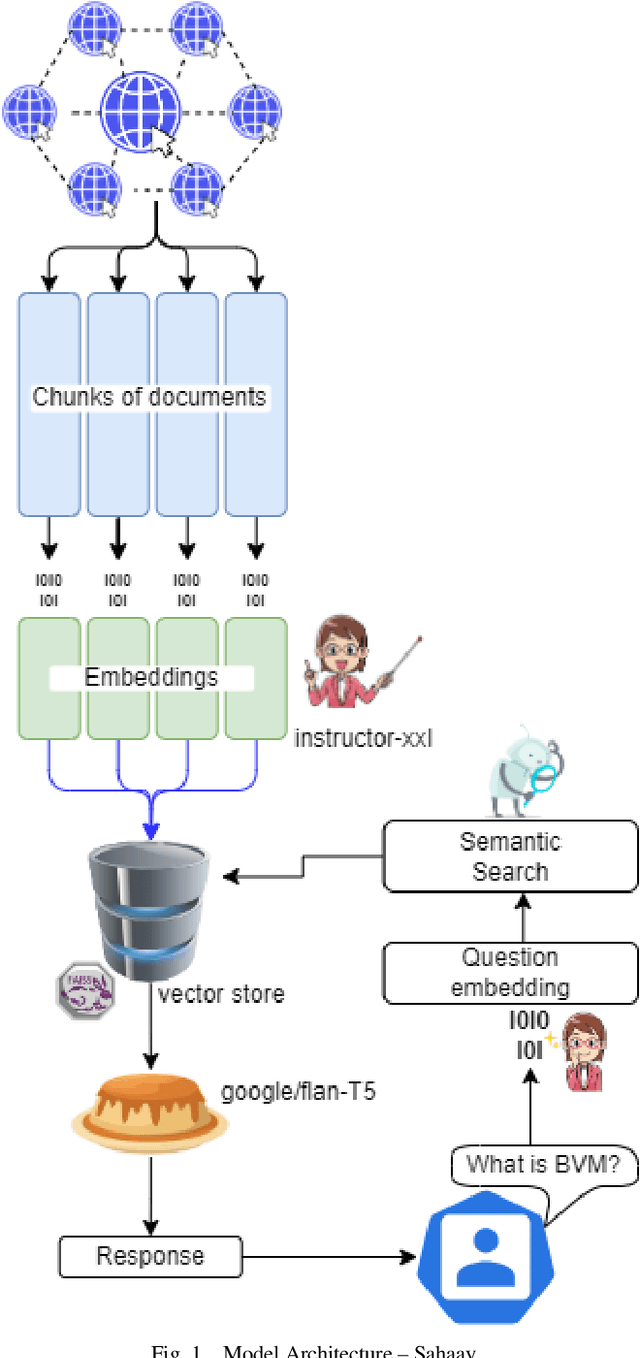



In the digital age, the dynamics of customer service are evolving, driven by technological advancements and the integration of Large Language Models (LLMs). This research paper introduces a groundbreaking approach to automating customer service using LangChain, a custom LLM tailored for organizations. The paper explores the obsolescence of traditional customer support techniques, particularly Frequently Asked Questions (FAQs), and proposes a paradigm shift towards responsive, context-aware, and personalized customer interactions. The heart of this innovation lies in the fusion of open-source methodologies, web scraping, fine-tuning, and the seamless integration of LangChain into customer service platforms. This open-source state-of-the-art framework, presented as "Sahaay," demonstrates the ability to scale across industries and organizations, offering real-time support and query resolution. Key elements of this research encompass data collection via web scraping, the role of embeddings, the utilization of Google's Flan T5 XXL, Base and Small language models for knowledge retrieval, and the integration of the chatbot into customer service platforms. The results section provides insights into their performance and use cases, here particularly within an educational institution. This research heralds a new era in customer service, where technology is harnessed to create efficient, personalized, and responsive interactions. Sahaay, powered by LangChain, redefines the customer-company relationship, elevating customer retention, value extraction, and brand image. As organizations embrace LLMs, customer service becomes a dynamic and customer-centric ecosystem.
GradientSurf: Gradient-Domain Neural Surface Reconstruction from RGB Video
Oct 09, 2023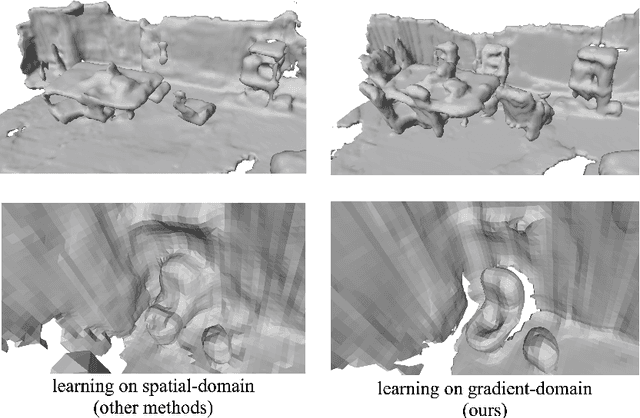
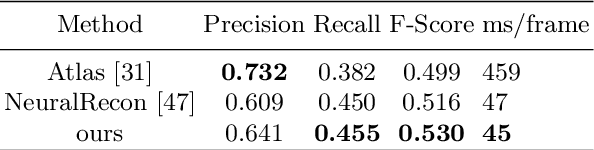
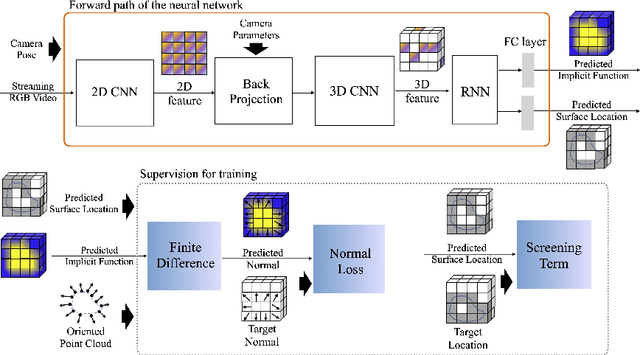
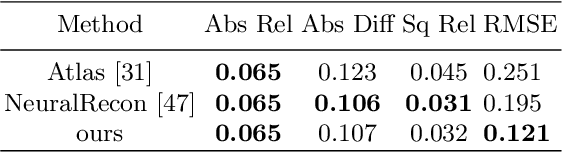
This paper proposes GradientSurf, a novel algorithm for real time surface reconstruction from monocular RGB video. Inspired by Poisson Surface Reconstruction, the proposed method builds on the tight coupling between surface, volume, and oriented point cloud and solves the reconstruction problem in gradient-domain. Unlike Poisson Surface Reconstruction which finds an offline solution to the Poisson equation by solving a linear system after the scanning process is finished, our method finds online solutions from partial scans with a neural network incrementally where the Poisson layer is designed to supervise both local and global reconstruction. The main challenge that existing methods suffer from when reconstructing from RGB signal is a lack of details in the reconstructed surface. We hypothesize this is due to the spectral bias of neural networks towards learning low frequency geometric features. To address this issue, the reconstruction problem is cast onto gradient domain, where zeroth-order and first-order energies are minimized. The zeroth-order term penalizes location of the surface. The first-order term penalizes the difference between the gradient of reconstructed implicit function and the vector field formulated from oriented point clouds sampled at adaptive local densities. For the task of indoor scene reconstruction, visual and quantitative experimental results show that the proposed method reconstructs surfaces with more details in curved regions and higher fidelity for small objects than previous methods.
Three-Stage Cascade Framework for Blurry Video Frame Interpolation
Oct 09, 2023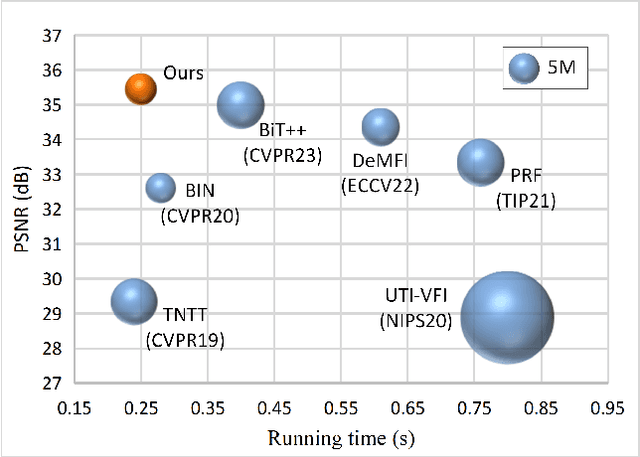
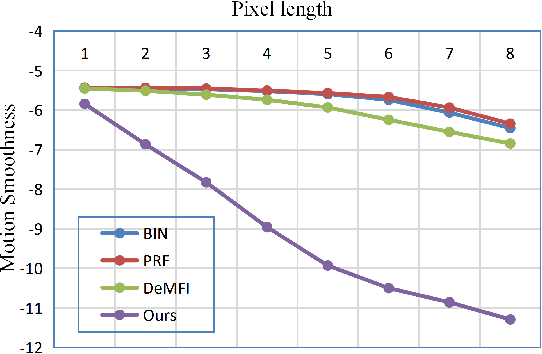

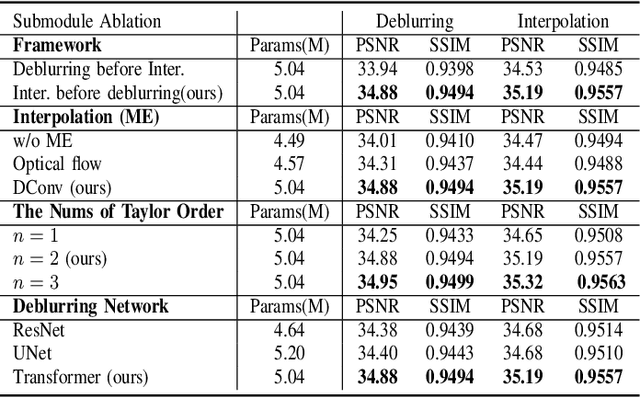
Blurry video frame interpolation (BVFI) aims to generate high-frame-rate clear videos from low-frame-rate blurry videos, is a challenging but important topic in the computer vision community. Blurry videos not only provide spatial and temporal information like clear videos, but also contain additional motion information hidden in each blurry frame. However, existing BVFI methods usually fail to fully leverage all valuable information, which ultimately hinders their performance. In this paper, we propose a simple end-to-end three-stage framework to fully explore useful information from blurry videos. The frame interpolation stage designs a temporal deformable network to directly sample useful information from blurry inputs and synthesize an intermediate frame at an arbitrary time interval. The temporal feature fusion stage explores the long-term temporal information for each target frame through a bi-directional recurrent deformable alignment network. And the deblurring stage applies a transformer-empowered Taylor approximation network to recursively recover the high-frequency details. The proposed three-stage framework has clear task assignment for each module and offers good expandability, the effectiveness of which are demonstrated by various experimental results. We evaluate our model on four benchmarks, including the Adobe240 dataset, GoPro dataset, YouTube240 dataset and Sony dataset. Quantitative and qualitative results indicate that our model outperforms existing SOTA methods. Besides, experiments on real-world blurry videos also indicate the good generalization ability of our model.
Optimal Exploration is no harder than Thompson Sampling
Oct 09, 2023


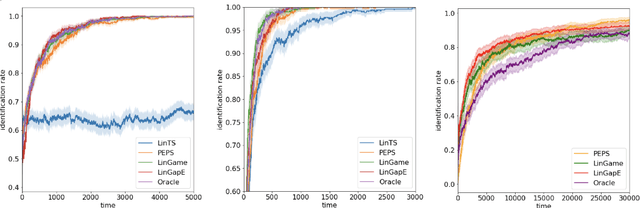
Given a set of arms $\mathcal{Z}\subset \mathbb{R}^d$ and an unknown parameter vector $\theta_\ast\in\mathbb{R}^d$, the pure exploration linear bandit problem aims to return $\arg\max_{z\in \mathcal{Z}} z^{\top}\theta_{\ast}$, with high probability through noisy measurements of $x^{\top}\theta_{\ast}$ with $x\in \mathcal{X}\subset \mathbb{R}^d$. Existing (asymptotically) optimal methods require either a) potentially costly projections for each arm $z\in \mathcal{Z}$ or b) explicitly maintaining a subset of $\mathcal{Z}$ under consideration at each time. This complexity is at odds with the popular and simple Thompson Sampling algorithm for regret minimization, which just requires access to a posterior sampling and argmax oracle, and does not need to enumerate $\mathcal{Z}$ at any point. Unfortunately, Thompson sampling is known to be sub-optimal for pure exploration. In this work, we pose a natural question: is there an algorithm that can explore optimally and only needs the same computational primitives as Thompson Sampling? We answer the question in the affirmative. We provide an algorithm that leverages only sampling and argmax oracles and achieves an exponential convergence rate, with the exponent being the optimal among all possible allocations asymptotically. In addition, we show that our algorithm can be easily implemented and performs as well empirically as existing asymptotically optimal methods.