 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Color and Texture Dual Pipeline Lightweight Style Transfer
Oct 02, 2023
Style transfer methods typically generate a single stylized output of color and texture coupling for reference styles, and color transfer schemes may introduce distortion or artifacts when processing reference images with duplicate textures. To solve the problem, we propose a Color and Texture Dual Pipeline Lightweight Style Transfer CTDP method, which employs a dual pipeline method to simultaneously output the results of color and texture transfer. Furthermore, we designed a masked total variation loss to suppress artifacts and small texture representations in color transfer results without affecting the semantic part of the content. More importantly, we are able to add texture structures with controllable intensity to color transfer results for the first time. Finally, we conducted feature visualization analysis on the texture generation mechanism of the framework and found that smoothing the input image can almost completely eliminate this texture structure. In comparative experiments, the color and texture transfer results generated by CTDP both achieve state-of-the-art performance. Additionally, the weight of the color transfer branch model size is as low as 20k, which is 100-1500 times smaller than that of other state-of-the-art models.
PASTA: PArallel Spatio-Temporal Attention with spatial auto-correlation gating for fine-grained crowd flow prediction
Oct 02, 2023Understanding the movement patterns of objects (e.g., humans and vehicles) in a city is essential for many applications, including city planning and management. This paper proposes a method for predicting future city-wide crowd flows by modeling the spatio-temporal patterns of historical crowd flows in fine-grained city-wide maps. We introduce a novel neural network named PArallel Spatio-Temporal Attention with spatial auto-correlation gating (PASTA) that effectively captures the irregular spatio-temporal patterns of fine-grained maps. The novel components in our approach include spatial auto-correlation gating, multi-scale residual block, and temporal attention gating module. The spatial auto-correlation gating employs the concept of spatial statistics to identify irregular spatial regions. The multi-scale residual block is responsible for handling multiple range spatial dependencies in the fine-grained map, and the temporal attention gating filters out irrelevant temporal information for the prediction. The experimental results demonstrate that our model outperforms other competing baselines, especially under challenging conditions that contain irregular spatial regions. We also provide a qualitative analysis to derive the critical time information where our model assigns high attention scores in prediction.
Enhancing Secrecy Capacity in PLS Communication with NORAN based on Pilot Information Codebooks
Oct 02, 2023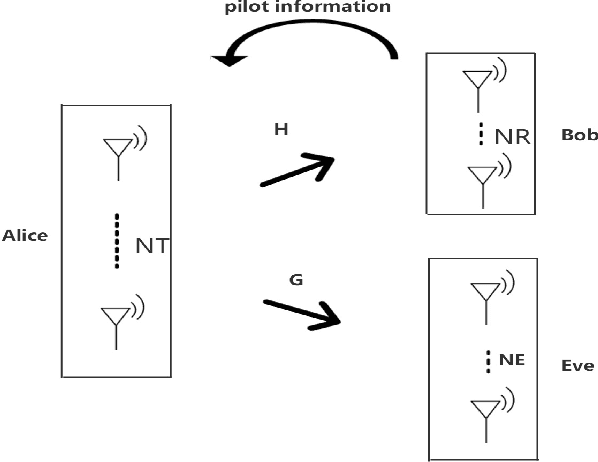
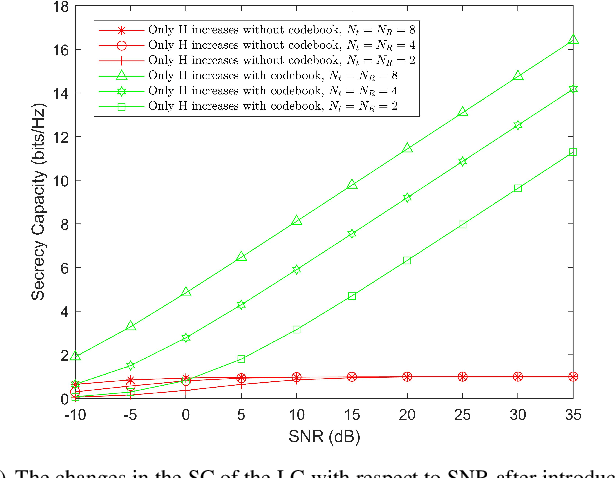
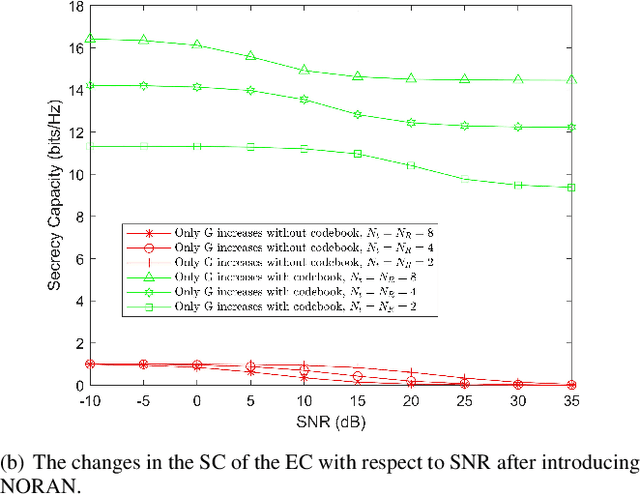
In recent research, non-orthogonal artificial noise (NORAN) has been proposed as an alternative to orthogonal artificial noise (AN). However, NORAN introduces additional noise into the channel, which reduces the capacity of the legitimate channel (LC). At the same time, selecting a NORAN design with ideal security performance from a large number of design options is also a challenging problem. To address these two issues, a novel NORAN based on a pilot information codebook is proposed in this letter. The codebook associates different suboptimal NORANs with pilot information as the key under different channel state information (CSI). The receiver interrogates the codebook using the pilot information to obtain the NORAN that the transmitter will transmit in the next moment, in order to eliminate the NORAN when receiving information. Therefore, NORAN based on pilot information codebooks can improve the secrecy capacity (SC) of the communication system by directly using suboptimal NORAN design schemes without increasing the noise in the LC. Numerical simulations and analyses show that the introduction of NORAN with a novel design using pilot information codebooks significantly enhances the security and improves the SC of the communication system.
Task Graph offloading via Deep Reinforcement Learning in Mobile Edge Computing
Oct 02, 2023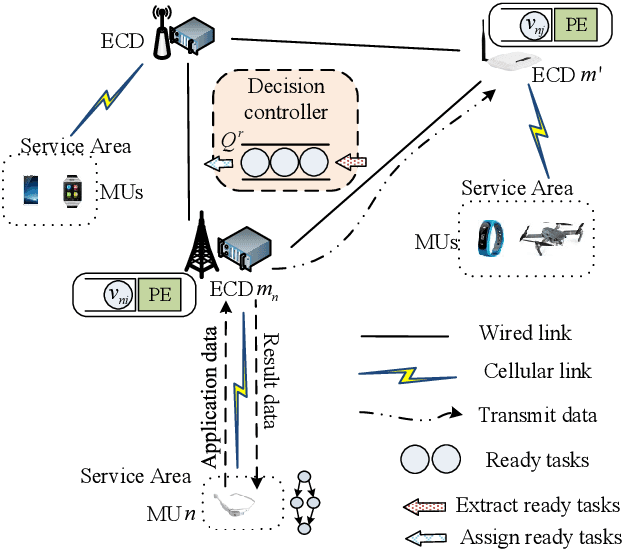
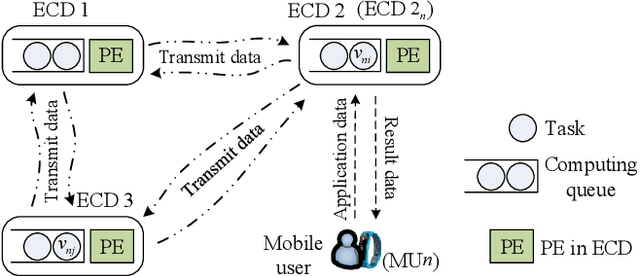
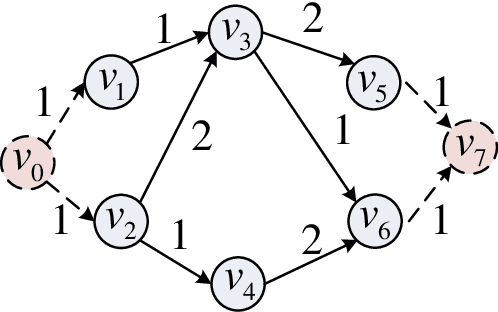
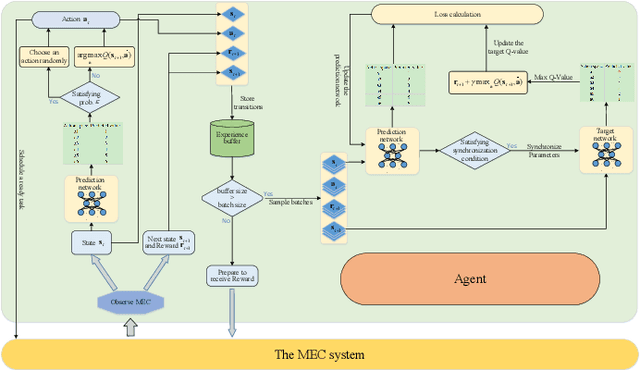
Various mobile applications that comprise dependent tasks are gaining widespread popularity and are increasingly complex. These applications often have low-latency requirements, resulting in a significant surge in demand for computing resources. With the emergence of mobile edge computing (MEC), it becomes the most significant issue to offload the application tasks onto small-scale devices deployed at the edge of the mobile network for obtaining a high-quality user experience. However, since the environment of MEC is dynamic, most existing works focusing on task graph offloading, which rely heavily on expert knowledge or accurate analytical models, fail to fully adapt to such environmental changes, resulting in the reduction of user experience. This paper investigates the task graph offloading in MEC, considering the time-varying computation capabilities of edge computing devices. To adapt to environmental changes, we model the task graph scheduling for computation offloading as a Markov Decision Process (MDP). Then, we design a deep reinforcement learning algorithm (SATA-DRL) to learn the task scheduling strategy from the interaction with the environment, to improve user experience. Extensive simulations validate that SATA-DRL is superior to existing strategies in terms of reducing average makespan and deadline violation.
Automatic Concept Embedding Model (ACEM): No train-time concepts, No issue!
Sep 07, 2023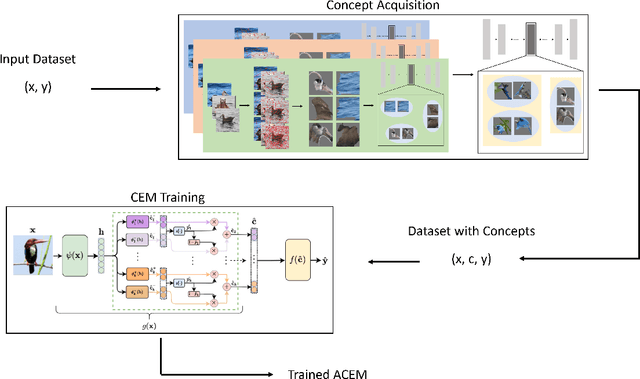
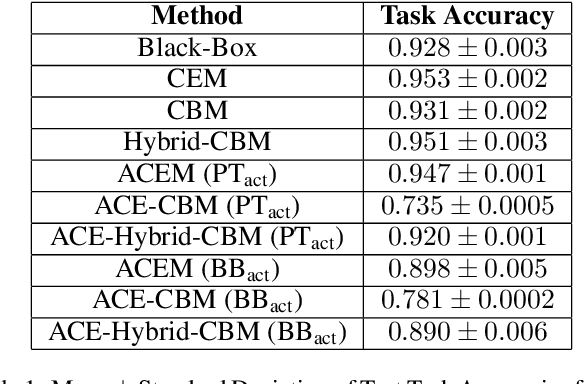
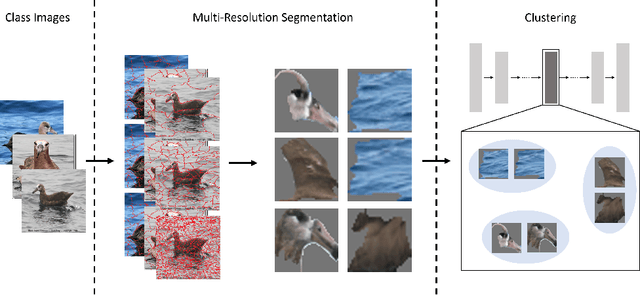
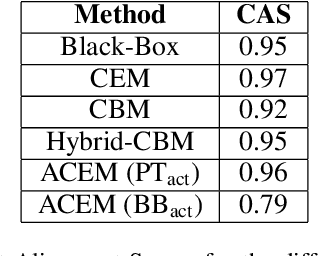
Interpretability and explainability of neural networks is continuously increasing in importance, especially within safety-critical domains and to provide the social right to explanation. Concept based explanations align well with how humans reason, proving to be a good way to explain models. Concept Embedding Models (CEMs) are one such concept based explanation architectures. These have shown to overcome the trade-off between explainability and performance. However, they have a key limitation -- they require concept annotations for all their training data. For large datasets, this can be expensive and infeasible. Motivated by this, we propose Automatic Concept Embedding Models (ACEMs), which learn the concept annotations automatically.
Scalable Multiuser Immersive Communications with Multi-numerology and Mini-slot
Sep 16, 2023This paper studies multiuser immersive communications networks in which different user equipment may demand various extended reality (XR) services. In such heterogeneous networks, time-frequency resource allocation needs to be more adaptive since XR services are usually multi-modal and latency-sensitive. To this end, we develop a scalable time-frequency resource allocation method based on multi-numerology and mini-slot. To appropriately determining the discrete parameters of multi-numerology and mini-slot for multiuser immersive communications, the proposed method first presents a novel flexible time-frequency resource block configuration, then it leverages the deep reinforcement learning to maximize the total quality-of-experience (QoE) under different users' QoE constraints. The results confirm the efficiency and scalability of the proposed time-frequency resource allocation method.
Treating Motion as Option with Output Selection for Unsupervised Video Object Segmentation
Sep 26, 2023Unsupervised video object segmentation (VOS) is a task that aims to detect the most salient object in a video without external guidance about the object. To leverage the property that salient objects usually have distinctive movements compared to the background, recent methods collaboratively use motion cues extracted from optical flow maps with appearance cues extracted from RGB images. However, as optical flow maps are usually very relevant to segmentation masks, the network is easy to be learned overly dependent on the motion cues during network training. As a result, such two-stream approaches are vulnerable to confusing motion cues, making their prediction unstable. To relieve this issue, we design a novel motion-as-option network by treating motion cues as optional. During network training, RGB images are randomly provided to the motion encoder instead of optical flow maps, to implicitly reduce motion dependency of the network. As the learned motion encoder can deal with both RGB images and optical flow maps, two different predictions can be generated depending on which source information is used as motion input. In order to fully exploit this property, we also propose an adaptive output selection algorithm to adopt optimal prediction result at test time. Our proposed approach affords state-of-the-art performance on all public benchmark datasets, even maintaining real-time inference speed.
Gaze-Driven Sentence Simplification for Language Learners: Enhancing Comprehension and Readability
Sep 30, 2023Language learners should regularly engage in reading challenging materials as part of their study routine. Nevertheless, constantly referring to dictionaries is time-consuming and distracting. This paper presents a novel gaze-driven sentence simplification system designed to enhance reading comprehension while maintaining their focus on the content. Our system incorporates machine learning models tailored to individual learners, combining eye gaze features and linguistic features to assess sentence comprehension. When the system identifies comprehension difficulties, it provides simplified versions by replacing complex vocabulary and grammar with simpler alternatives via GPT-3.5. We conducted an experiment with 19 English learners, collecting data on their eye movements while reading English text. The results demonstrated that our system is capable of accurately estimating sentence-level comprehension. Additionally, we found that GPT-3.5 simplification improved readability in terms of traditional readability metrics and individual word difficulty, paraphrasing across different linguistic levels.
MFL Data Preprocessing and CNN-based Oil Pipeline Defects Detection
Sep 30, 2023
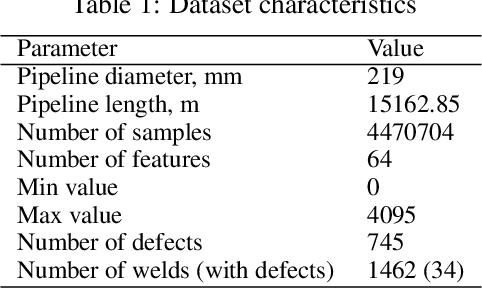
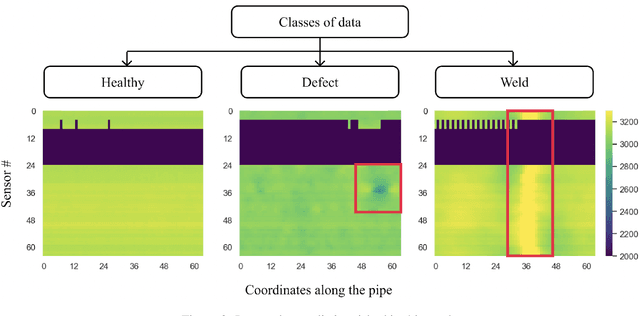
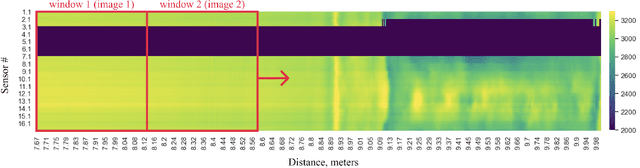
Recently, the application of computer vision for anomaly detection has been under attention in several industrial fields. An important example is oil pipeline defect detection. Failure of one oil pipeline can interrupt the operation of the entire transportation system or cause a far-reaching failure. The automated defect detection could significantly decrease the inspection time and the related costs. However, there is a gap in the related literature when it comes to dealing with this task. The existing studies do not sufficiently cover the research of the Magnetic Flux Leakage data and the preprocessing techniques that allow overcoming the limitations set by the available data. This work focuses on alleviating these issues. Moreover, in doing so, we exploited the recent convolutional neural network structures and proposed robust approaches, aiming to acquire high performance considering the related metrics. The proposed approaches and their applicability were verified using real-world data.
A Real-time Non-contact Localization Method for Faulty Electric Energy Storage Components using Highly Sensitive Magnetometers
Aug 15, 2023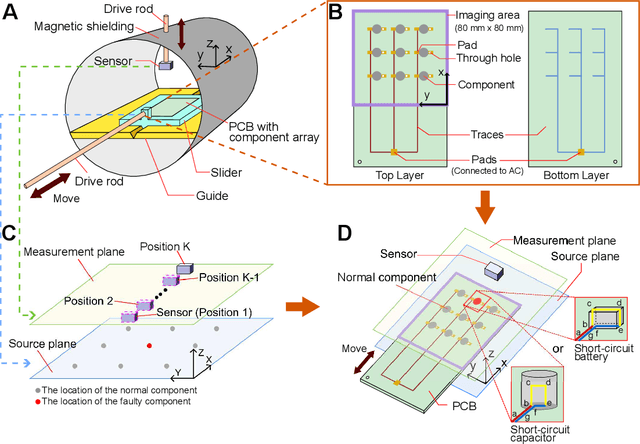
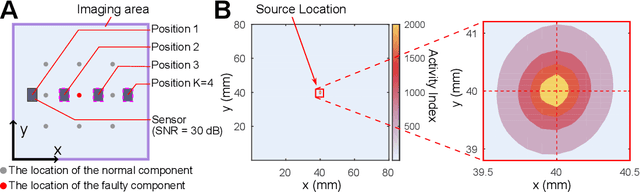
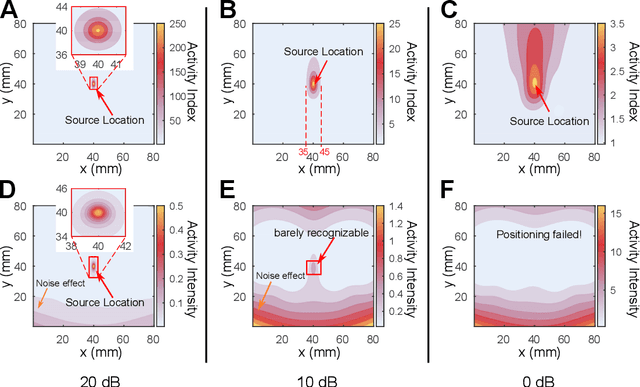

With the wide application of electric energy storage component arrays, such as battery arrays, capacitor arrays, inductor arrays, their potential safety risks have gradually drawn the public attention. However, existing technologies cannot meet the needs of non-contact and real-time diagnosis for faulty components inside these massive arrays. To solve this problem, this paper proposes a new method based on the beamforming spatial filtering algorithm to precisely locate the faulty components within the arrays in real-time. The method uses highly sensitive magnetometers to collect the magnetic signals from energy storage component arrays, without damaging or even contacting any component. The experimental results demonstrate the potential of the proposed method in securing energy storage component arrays. Within an imaging area of 80 mm $\times$ 80 mm, the one faulty component out of nine total components can be localized with an accuracy of 0.72 mm for capacitor arrays and 1.60 mm for battery arrays.