 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automated Construction of Time-Space Diagrams for Traffic Analysis Using Street-View Video Sequence
Aug 11, 2023
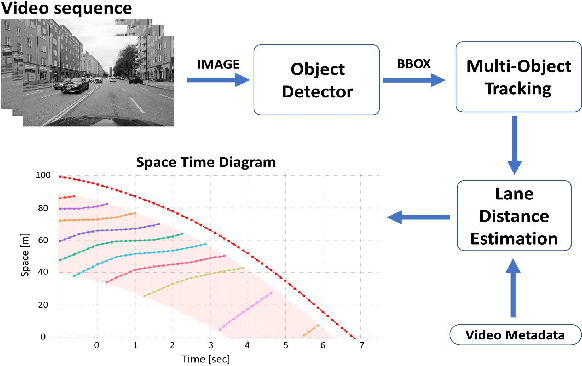

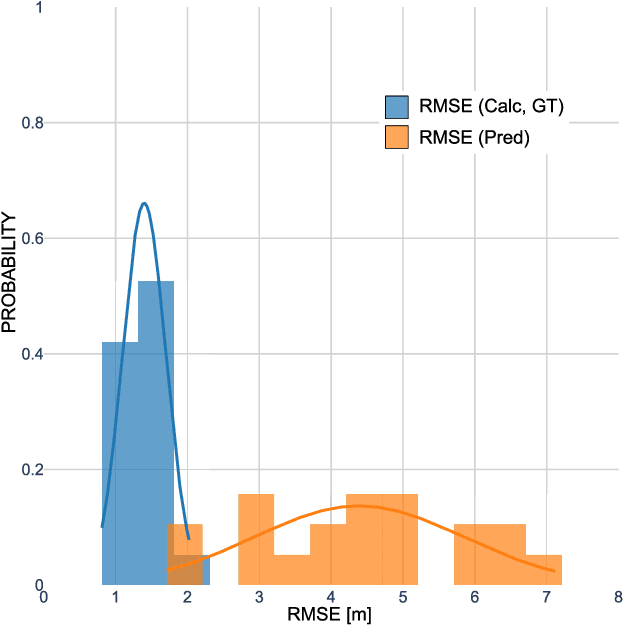
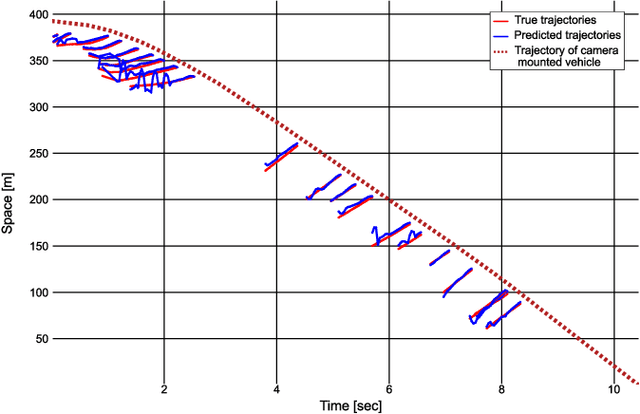
Time-space diagrams are essential tools for analyzing traffic patterns and optimizing transportation infrastructure and traffic management strategies. Traditional data collection methods for these diagrams have limitations in terms of temporal and spatial coverage. Recent advancements in camera technology have overcome these limitations and provided extensive urban data. In this study, we propose an innovative approach to constructing time-space diagrams by utilizing street-view video sequences captured by cameras mounted on moving vehicles. Using the state-of-the-art YOLOv5, StrongSORT, and photogrammetry techniques for distance calculation, we can infer vehicle trajectories from the video data and generate time-space diagrams. To evaluate the effectiveness of our proposed method, we utilized datasets from the KITTI computer vision benchmark suite. The evaluation results demonstrate that our approach can generate trajectories from video data, although there are some errors that can be mitigated by improving the performance of the detector, tracker, and distance calculation components. In conclusion, the utilization of street-view video sequences captured by cameras mounted on moving vehicles, combined with state-of-the-art computer vision techniques, has immense potential for constructing comprehensive time-space diagrams. These diagrams offer valuable insights into traffic patterns and contribute to the design of transportation infrastructure and traffic management strategies.
Real-Time Non-Invasive Imaging and Detection of Spreading Depolarizations through EEG: An Ultra-Light Explainable Deep Learning Approach
Sep 06, 2023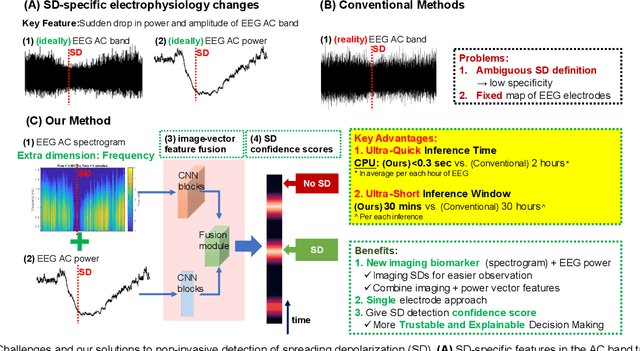
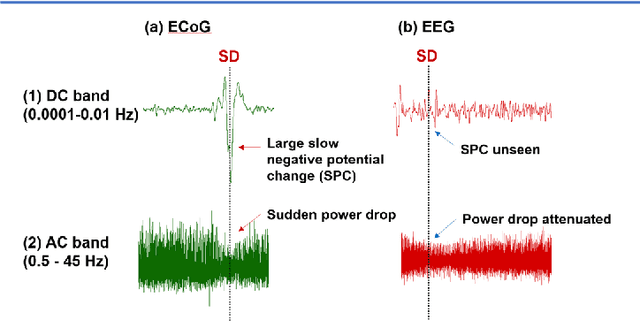
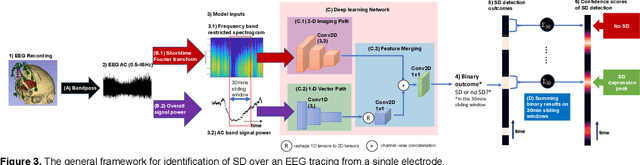
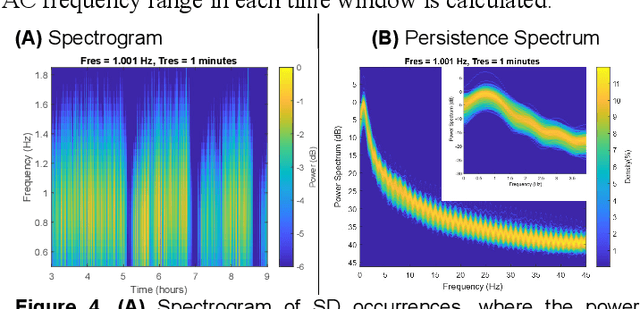
A core aim of neurocritical care is to prevent secondary brain injury. Spreading depolarizations (SDs) have been identified as an important independent cause of secondary brain injury. SDs are usually detected using invasive electrocorticography recorded at high sampling frequency. Recent pilot studies suggest a possible utility of scalp electrodes generated electroencephalogram (EEG) for non-invasive SD detection. However, noise and attenuation of EEG signals makes this detection task extremely challenging. Previous methods focus on detecting temporal power change of EEG over a fixed high-density map of scalp electrodes, which is not always clinically feasible. Having a specialized spectrogram as an input to the automatic SD detection model, this study is the first to transform SD identification problem from a detection task on a 1-D time-series wave to a task on a sequential 2-D rendered imaging. This study presented a novel ultra-light-weight multi-modal deep-learning network to fuse EEG spectrogram imaging and temporal power vectors to enhance SD identification accuracy over each single electrode, allowing flexible EEG map and paving the way for SD detection on ultra-low-density EEG with variable electrode positioning. Our proposed model has an ultra-fast processing speed (<0.3 sec). Compared to the conventional methods (2 hours), this is a huge advancement towards early SD detection and to facilitate instant brain injury prognosis. Seeing SDs with a new dimension - frequency on spectrograms, we demonstrated that such additional dimension could improve SD detection accuracy, providing preliminary evidence to support the hypothesis that SDs may show implicit features over the frequency profile.
Deep Learning for Automatic Detection and Facial Recognition in Japanese Macaques: Illuminating Social Networks
Oct 10, 2023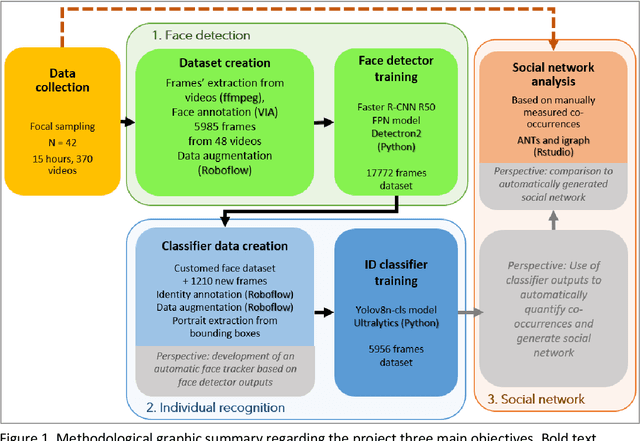


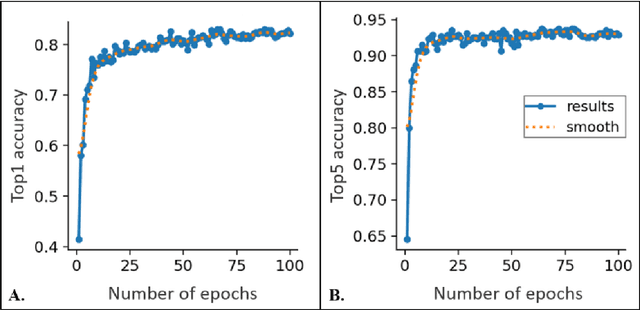
Individual identification plays a pivotal role in ecology and ethology, notably as a tool for complex social structures understanding. However, traditional identification methods often involve invasive physical tags and can prove both disruptive for animals and time-intensive for researchers. In recent years, the integration of deep learning in research offered new methodological perspectives through automatization of complex tasks. Harnessing object detection and recognition technologies is increasingly used by researchers to achieve identification on video footage. This study represents a preliminary exploration into the development of a non-invasive tool for face detection and individual identification of Japanese macaques (Macaca fuscata) through deep learning. The ultimate goal of this research is, using identifications done on the dataset, to automatically generate a social network representation of the studied population. The current main results are promising: (i) the creation of a Japanese macaques' face detector (Faster-RCNN model), reaching a 82.2% accuracy and (ii) the creation of an individual recognizer for K{\=o}jima island macaques population (YOLOv8n model), reaching a 83% accuracy. We also created a K{\=o}jima population social network by traditional methods, based on co-occurrences on videos. Thus, we provide a benchmark against which the automatically generated network will be assessed for reliability. These preliminary results are a testament to the potential of this innovative approach to provide the scientific community with a tool for tracking individuals and social network studies in Japanese macaques.
Fine-grained Audio-Visual Joint Representations for Multimodal Large Language Models
Oct 10, 2023Audio-visual large language models (LLM) have drawn significant attention, yet the fine-grained combination of both input streams is rather under-explored, which is challenging but necessary for LLMs to understand general video inputs. To this end, a fine-grained audio-visual joint representation (FAVOR) learning framework for multimodal LLMs is proposed in this paper, which extends a text-based LLM to simultaneously perceive speech and audio events in the audio input stream and images or videos in the visual input stream, at the frame level. To fuse the audio and visual feature streams into joint representations and to align the joint space with the LLM input embedding space, we propose a causal Q-Former structure with a causal attention module to enhance the capture of causal relations of the audio-visual frames across time. An audio-visual evaluation benchmark (AVEB) is also proposed which comprises six representative single-modal tasks with five cross-modal tasks reflecting audio-visual co-reasoning abilities. While achieving competitive single-modal performance on audio, speech and image tasks in AVEB, FAVOR achieved over 20% accuracy improvements on the video question-answering task when fine-grained information or temporal causal reasoning is required. FAVOR, in addition, demonstrated remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other multimodal LLMs. An interactive demo of FAVOR is available at https://github.com/BriansIDP/AudioVisualLLM.git, and the training code and model checkpoints will be released soon.
Are Large Language Models Post Hoc Explainers?
Oct 10, 2023

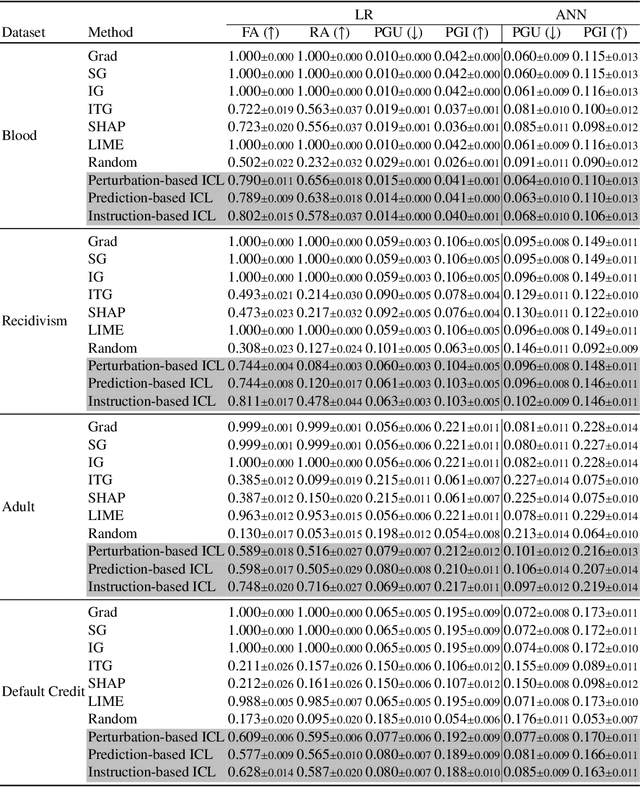

Large Language Models (LLMs) are increasingly used as powerful tools for a plethora of natural language processing (NLP) applications. A recent innovation, in-context learning (ICL), enables LLMs to learn new tasks by supplying a few examples in the prompt during inference time, thereby eliminating the need for model fine-tuning. While LLMs have been utilized in several applications, their applicability in explaining the behavior of other models remains relatively unexplored. Despite the growing number of new explanation techniques, many require white-box access to the model and/or are computationally expensive, highlighting a need for next-generation post hoc explainers. In this work, we present the first framework to study the effectiveness of LLMs in explaining other predictive models. More specifically, we propose a novel framework encompassing multiple prompting strategies: i) Perturbation-based ICL, ii) Prediction-based ICL, iii) Instruction-based ICL, and iv) Explanation-based ICL, with varying levels of information about the underlying ML model and the local neighborhood of the test sample. We conduct extensive experiments with real-world benchmark datasets to demonstrate that LLM-generated explanations perform on par with state-of-the-art post hoc explainers using their ability to leverage ICL examples and their internal knowledge in generating model explanations. On average, across four datasets and two ML models, we observe that LLMs identify the most important feature with 72.19% accuracy, opening up new frontiers in explainable artificial intelligence (XAI) to explore LLM-based explanation frameworks.
Automatic Sensor-free Affect Detection: A Systematic Literature Review
Oct 11, 2023Emotions and other affective states play a pivotal role in cognition and, consequently, the learning process. It is well-established that computer-based learning environments (CBLEs) that can detect and adapt to students' affective states can enhance learning outcomes. However, practical constraints often pose challenges to the deployment of sensor-based affect detection in CBLEs, particularly for large-scale or long-term applications. As a result, sensor-free affect detection, which exclusively relies on logs of students' interactions with CBLEs, emerges as a compelling alternative. This paper provides a comprehensive literature review on sensor-free affect detection. It delves into the most frequently identified affective states, the methodologies and techniques employed for sensor development, the defining attributes of CBLEs and data samples, as well as key research trends. Despite the field's evident maturity, demonstrated by the consistent performance of the models and the application of advanced machine learning techniques, there is ample scope for future research. Potential areas for further exploration include enhancing the performance of sensor-free detection models, amassing more samples of underrepresented emotions, and identifying additional emotions. There is also a need to refine model development practices and methods. This could involve comparing the accuracy of various data collection techniques, determining the optimal granularity of duration, establishing a shared database of action logs and emotion labels, and making the source code of these models publicly accessible. Future research should also prioritize the integration of models into CBLEs for real-time detection, the provision of meaningful interventions based on detected emotions, and a deeper understanding of the impact of emotions on learning.
Multi-Task Learning-Enabled Automatic Vessel Draft Reading for Intelligent Maritime Surveillance
Oct 11, 2023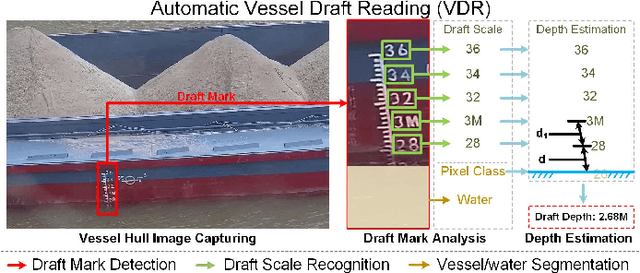
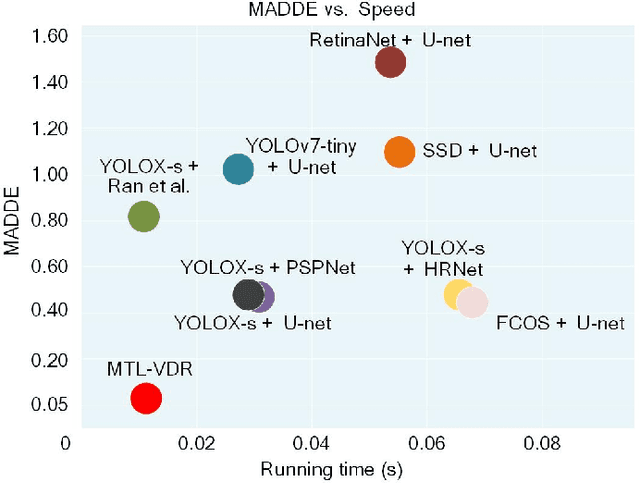


The accurate and efficient vessel draft reading (VDR) is an important component of intelligent maritime surveillance, which could be exploited to assist in judging whether the vessel is normally loaded or overloaded. The computer vision technique with an excellent price-to-performance ratio has become a popular medium to estimate vessel draft depth. However, the traditional estimation methods easily suffer from several limitations, such as sensitivity to low-quality images, high computational cost, etc. In this work, we propose a multi-task learning-enabled computational method (termed MTL-VDR) for generating highly reliable VDR. In particular, our MTL-VDR mainly consists of four components, i.e., draft mark detection, draft scale recognition, vessel/water segmentation, and final draft depth estimation. We first construct a benchmark dataset related to draft mark detection and employ a powerful and efficient convolutional neural network to accurately perform the detection task. The multi-task learning method is then proposed for simultaneous draft scale recognition and vessel/water segmentation. To obtain more robust VDR under complex conditions (e.g., damaged and stained scales, etc.), the accurate draft scales are generated by an automatic correction method, which is presented based on the spatial distribution rules of draft scales. Finally, an adaptive computational method is exploited to yield an accurate and robust draft depth. Extensive experiments have been implemented on the realistic dataset to compare our MTL-VDR with state-of-the-art methods. The results have demonstrated its superior performance in terms of accuracy, robustness, and efficiency. The computational speed exceeds 40 FPS, which satisfies the requirements of real-time maritime surveillance to guarantee vessel traffic safety.
DSformer: A Double Sampling Transformer for Multivariate Time Series Long-term Prediction
Aug 07, 2023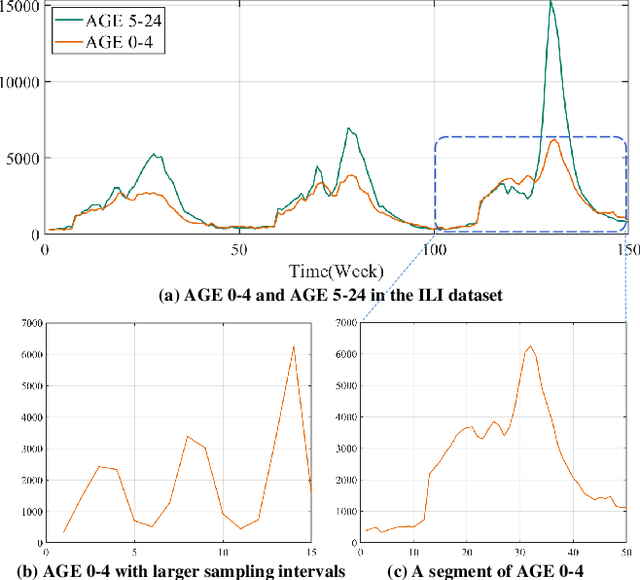
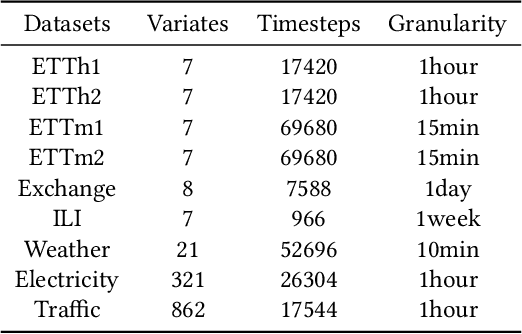
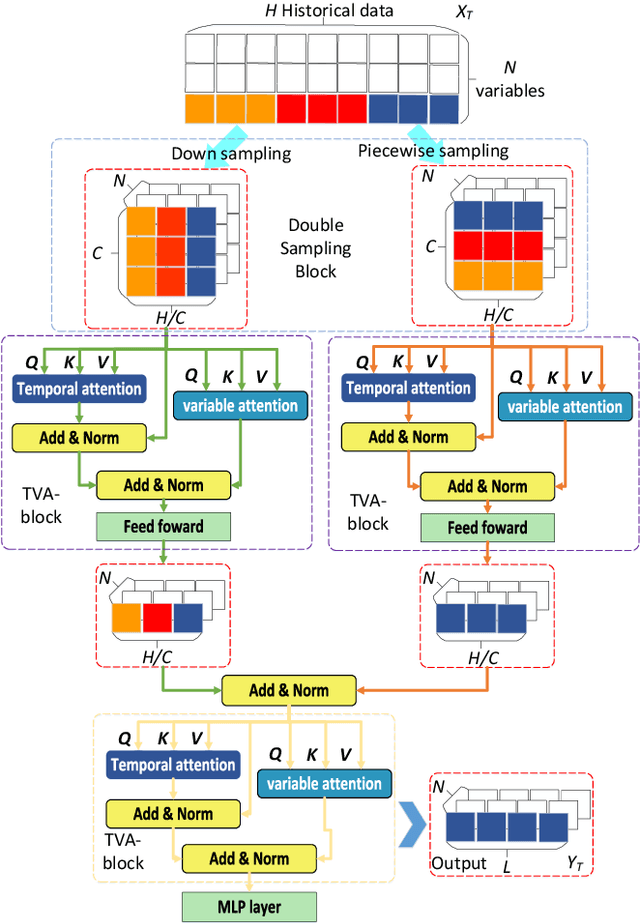
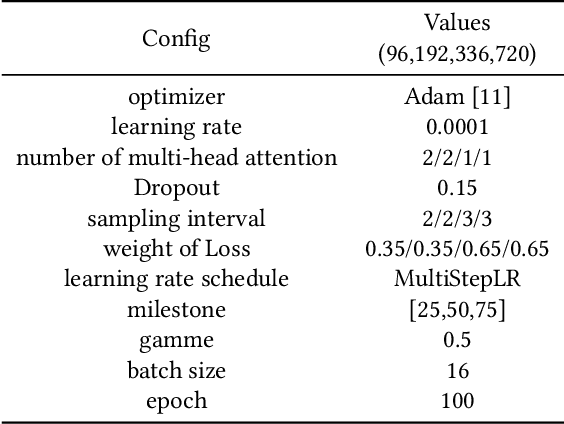
Multivariate time series long-term prediction, which aims to predict the change of data in a long time, can provide references for decision-making. Although transformer-based models have made progress in this field, they usually do not make full use of three features of multivariate time series: global information, local information, and variables correlation. To effectively mine the above three features and establish a high-precision prediction model, we propose a double sampling transformer (DSformer), which consists of the double sampling (DS) block and the temporal variable attention (TVA) block. Firstly, the DS block employs down sampling and piecewise sampling to transform the original series into feature vectors that focus on global information and local information respectively. Then, TVA block uses temporal attention and variable attention to mine these feature vectors from different dimensions and extract key information. Finally, based on a parallel structure, DSformer uses multiple TVA blocks to mine and integrate different features obtained from DS blocks respectively. The integrated feature information is passed to the generative decoder based on a multi-layer perceptron to realize multivariate time series long-term prediction. Experimental results on nine real-world datasets show that DSformer can outperform eight existing baselines.
Multivariate Time Series Anomaly Detection: Fancy Algorithms and Flawed Evaluation Methodology
Aug 24, 2023Multivariate Time Series (MVTS) anomaly detection is a long-standing and challenging research topic that has attracted tremendous research effort from both industry and academia recently. However, a careful study of the literature makes us realize that 1) the community is active but not as organized as other sibling machine learning communities such as Computer Vision (CV) and Natural Language Processing (NLP), and 2) most proposed solutions are evaluated using either inappropriate or highly flawed protocols, with an apparent lack of scientific foundation. So flawed is one very popular protocol, the so-called \pa protocol, that a random guess can be shown to systematically outperform \emph{all} algorithms developed so far. In this paper, we review and evaluate many recent algorithms using more robust protocols and discuss how a normally good protocol may have weaknesses in the context of MVTS anomaly detection and how to mitigate them. We also share our concerns about benchmark datasets, experiment design and evaluation methodology we observe in many works. Furthermore, we propose a simple, yet challenging, baseline algorithm based on Principal Components Analysis (PCA) that surprisingly outperforms many recent Deep Learning (DL) based approaches on popular benchmark datasets. The main objective of this work is to stimulate more effort towards important aspects of the research such as data, experiment design, evaluation methodology and result interpretability, instead of putting the highest weight on the design of increasingly more complex and "fancier" algorithms.
D-Band 2D MIMO FMCW Radar System Design for Indoor Wireless Sensing
Sep 29, 2023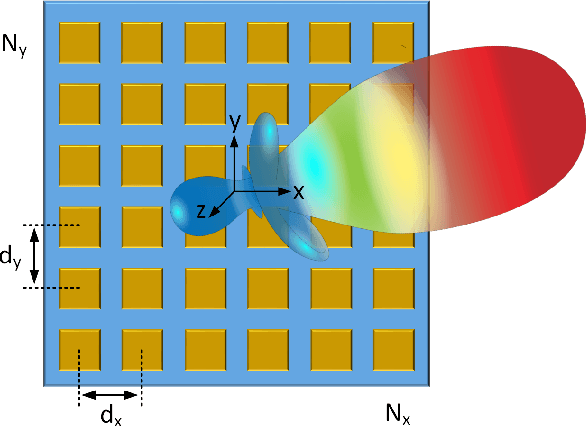
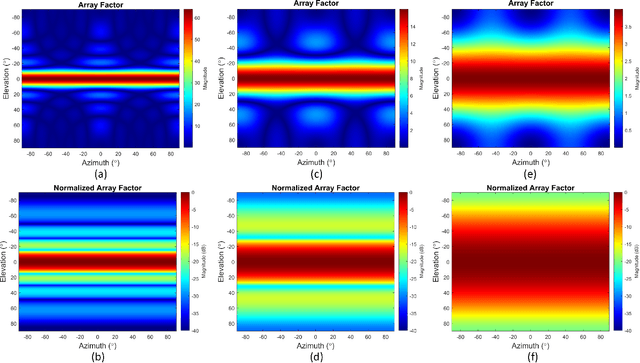
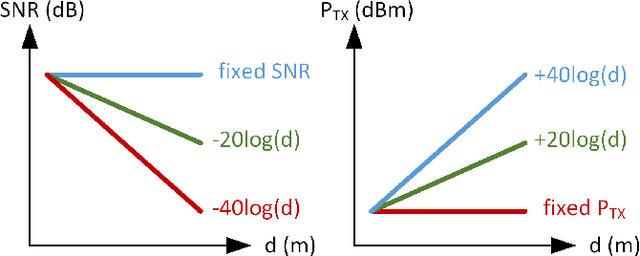
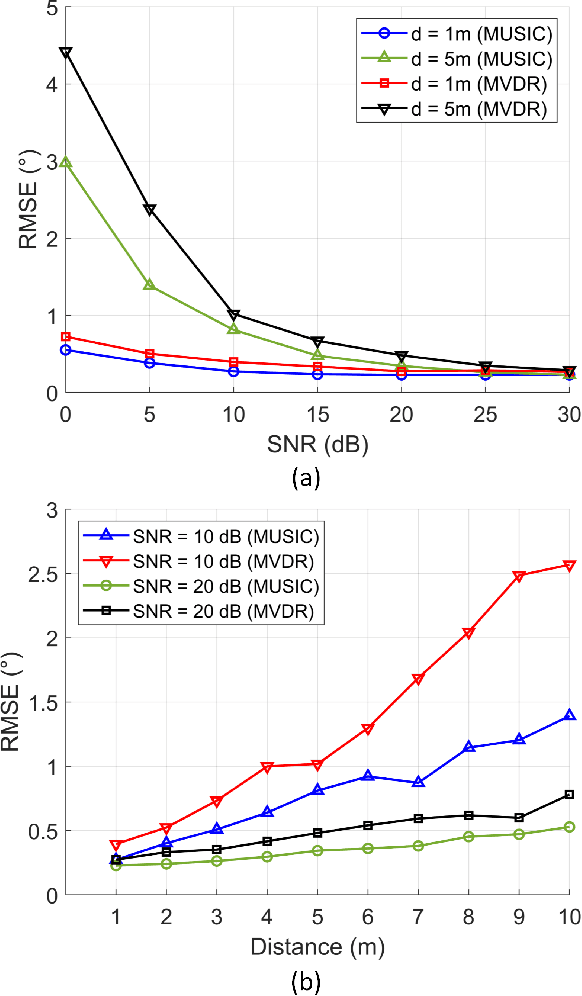
In this article, we present system design of D-band multi-input multi-output (MIMO) frequency-modulated continuous-wave (FMCW) radar for indoor wireless sensing. A uniform rectangular array (URA) of radar elements is used for 2D direction-of-arrival (DOA) estimation. The DOA estimation accuracy of the MIMO radar array in the presence of noise is evaluated using the multiple-signal classification (MUSIC) and the minimum variance distortionless response (MVDR) algorithms. We investigate different scaling scenarios for the radar receiver (RX) SNR and the transmitter (TX) output power with the target distance. The DOA estimation algorithm providing the highest accuracy and shortest simulation time is shown to depend on the size of the radar array. Specifically, for a 64-element array, the MUSIC achieves lower root-mean-square error (RMSE) compared to the MVDR across 1--10\,m indoor distances and 0--30\,dB SNR (e.g., $\rm 0.8^{\circ}$/$\rm 0.3^{\circ}$ versus $\rm 1.0^{\circ}$/$\rm 0.5^{\circ}$ at 10/20\,dB SNR and 5\,m distance) and 0.5x simulation time. For a 16-element array, the two algorithms provide comparable performance, while for a 4-element array, the MVDR outperforms the MUSIC by a large margin (e.g., $\rm 8.3^{\circ}$/$\rm 3.8^{\circ}$ versus $\rm 62.2^{\circ}$/$\rm 48.8^{\circ}$ at 10/20\,dB SNR and 5\,m distance) and 0.8x simulation time. Furthermore, the TX output power requirement of the radar array is investigated in free-space and through-wall wireless sensing scenarios, and is benchmarked by the state-of-the-art D-band on-chip radars.