 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cell Tracking according to Biological Needs -- Strong Mitosis-aware Random-finite Sets Tracker with Aleatoric Uncertainty
Mar 25, 2024
Cell tracking and segmentation assist biologists in extracting insights from large-scale microscopy time-lapse data. Driven by local accuracy metrics, current tracking approaches often suffer from a lack of long-term consistency. To address this issue, we introduce an uncertainty estimation technique for neural tracking-by-regression frameworks and incorporate it into our novel extended Poisson multi-Bernoulli mixture tracker. Our uncertainty estimation identifies uncertain associations within high-performing tracking-by-regression methods using problem-specific test-time augmentations. Leveraging this uncertainty, along with a novel mitosis-aware assignment problem formulation, our tracker resolves false associations and mitosis detections stemming from long-term conflicts. We evaluate our approach on nine competitive datasets and demonstrate that it outperforms the current state-of-the-art on biologically relevant metrics substantially, achieving improvements by a factor of approximately $5.75$. Furthermore, we uncover new insights into the behavior of tracking-by-regression uncertainty.
Automating Catheterization Labs with Real-Time Perception
Mar 09, 2024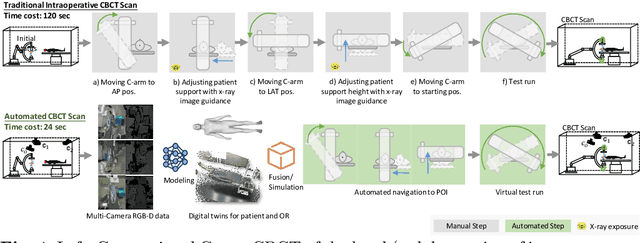
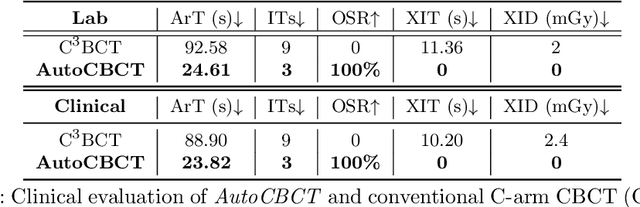
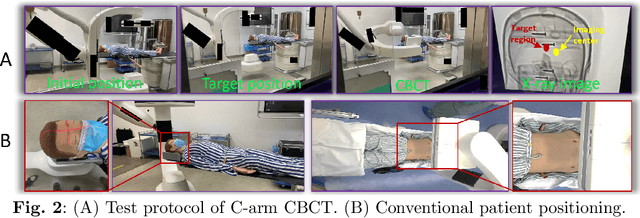
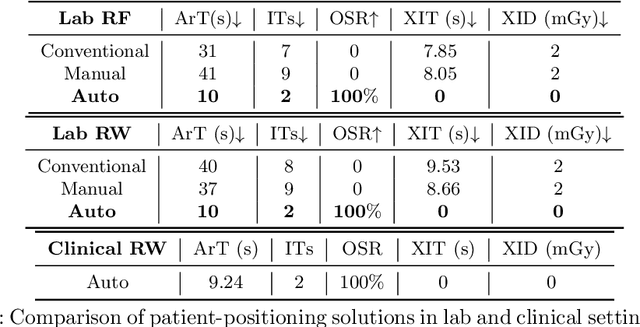
For decades, three-dimensional C-arm Cone-Beam Computed Tomography (CBCT) imaging system has been a critical component for complex vascular and nonvascular interventional procedures. While it can significantly improve multiplanar soft tissue imaging and provide pre-treatment target lesion roadmapping and guidance, the traditional workflow can be cumbersome and time-consuming, especially for less experienced users. To streamline this process and enhance procedural efficiency overall, we proposed a visual perception system, namely AutoCBCT, seamlessly integrated with an angiography suite. This system dynamically models both the patient's body and the surgical environment in real-time. AutoCBCT enables a novel workflow with automated positioning, navigation and simulated test-runs, eliminating the need for manual operations and interactions. The proposed system has been successfully deployed and studied in both lab and clinical settings, demonstrating significantly improved workflow efficiency.
An LLM-Based Digital Twin for Optimizing Human-in-the Loop Systems
Mar 25, 2024The increasing prevalence of Cyber-Physical Systems and the Internet of Things (CPS-IoT) applications and Foundation Models are enabling new applications that leverage real-time control of the environment. For example, real-time control of Heating, Ventilation and Air-Conditioning (HVAC) systems can reduce its usage when not needed for the comfort of human occupants, hence reducing energy consumption. Collecting real-time feedback on human preferences in such human-in-the-loop (HITL) systems, however, is difficult in practice. We propose the use of large language models (LLMs) to deal with the challenges of dynamic environments and difficult-to-obtain data in CPS optimization. In this paper, we present a case study that employs LLM agents to mimic the behaviors and thermal preferences of various population groups (e.g. young families, the elderly) in a shopping mall. The aggregated thermal preferences are integrated into an agent-in-the-loop based reinforcement learning algorithm AitL-RL, which employs the LLM as a dynamic simulation of the physical environment to learn how to balance between energy savings and occupant comfort. Our results show that LLMs are capable of simulating complex population movements within large open spaces. Besides, AitL-RL demonstrates superior performance compared to the popular existing policy of set point control, suggesting that adaptive and personalized decision-making is critical for efficient optimization in CPS-IoT applications. Through this case study, we demonstrate the potential of integrating advanced Foundation Models like LLMs into CPS-IoT to enhance system adaptability and efficiency. The project's code can be found on our GitHub repository.
Touch the Core: Exploring Task Dependence Among Hybrid Targets for Recommendation
Mar 26, 2024As user behaviors become complicated on business platforms, online recommendations focus more on how to touch the core conversions, which are highly related to the interests of platforms. These core conversions are usually continuous targets, such as \textit{watch time}, \textit{revenue}, and so on, whose predictions can be enhanced by previous discrete conversion actions. Therefore, multi-task learning (MTL) can be adopted as the paradigm to learn these hybrid targets. However, existing works mainly emphasize investigating the sequential dependence among discrete conversion actions, which neglects the complexity of dependence between discrete conversions and the final continuous conversion. Moreover, simultaneously optimizing hybrid tasks with stronger task dependence will suffer from volatile issues where the core regression task might have a larger influence on other tasks. In this paper, we study the MTL problem with hybrid targets for the first time and propose the model named Hybrid Targets Learning Network (HTLNet) to explore task dependence and enhance optimization. Specifically, we introduce label embedding for each task to explicitly transfer the label information among these tasks, which can effectively explore logical task dependence. We also further design the gradient adjustment regime between the final regression task and other classification tasks to enhance the optimization. Extensive experiments on two offline public datasets and one real-world industrial dataset are conducted to validate the effectiveness of HTLNet. Moreover, online A/B tests on the financial recommender system also show our model has superior improvement.
Using Quantum Computing to Infer Dynamic Behaviors of Biological and Artificial Neural Networks
Mar 27, 2024The exploration of new problem classes for quantum computation is an active area of research. An essentially completely unexplored topic is the use of quantum algorithms and computing to explore and ask questions \textit{about} the functional dynamics of neural networks. This is a component of the still-nascent topic of applying quantum computing to the modeling and simulations of biological and artificial neural networks. In this work, we show how a carefully constructed set of conditions can use two foundational quantum algorithms, Grover and Deutsch-Josza, in such a way that the output measurements admit an interpretation that guarantees we can infer if a simple representation of a neural network (which applies to both biological and artificial networks) after some period of time has the potential to continue sustaining dynamic activity. Or whether the dynamics are guaranteed to stop either through 'epileptic' dynamics or quiescence.
Large Language Models Need Consultants for Reasoning: Becoming an Expert in a Complex Human System Through Behavior Simulation
Mar 27, 2024Large language models (LLMs), in conjunction with various reasoning reinforcement methodologies, have demonstrated remarkable capabilities comparable to humans in fields such as mathematics, law, coding, common sense, and world knowledge. In this paper, we delve into the reasoning abilities of LLMs within complex human systems. We propose a novel reasoning framework, termed ``Mosaic Expert Observation Wall'' (MEOW) exploiting generative-agents-based simulation technique. In the MEOW framework, simulated data are utilized to train an expert model concentrating ``experience'' about a specific task in each independent time of simulation. It is the accumulated ``experience'' through the simulation that makes for an expert on a task in a complex human system. We conduct the experiments within a communication game that mirrors real-world security scenarios. The results indicate that our proposed methodology can cooperate with existing methodologies to enhance the reasoning abilities of LLMs in complex human systems.
Exploring language relations through syntactic distances and geographic proximity
Mar 27, 2024Languages are grouped into families that share common linguistic traits. While this approach has been successful in understanding genetic relations between diverse languages, more analyses are needed to accurately quantify their relatedness, especially in less studied linguistic levels such as syntax. Here, we explore linguistic distances using series of parts of speech (POS) extracted from the Universal Dependencies dataset. Within an information-theoretic framework, we show that employing POS trigrams maximizes the possibility of capturing syntactic variations while being at the same time compatible with the amount of available data. Linguistic connections are then established by assessing pairwise distances based on the POS distributions. Intriguingly, our analysis reveals definite clusters that correspond to well known language families and groups, with exceptions explained by distinct morphological typologies. Furthermore, we obtain a significant correlation between language similarity and geographic distance, which underscores the influence of spatial proximity on language kinships.
REFeREE: A REference-FREE Model-Based Metric for Text Simplification
Mar 26, 2024Text simplification lacks a universal standard of quality, and annotated reference simplifications are scarce and costly. We propose to alleviate such limitations by introducing REFeREE, a reference-free model-based metric with a 3-stage curriculum. REFeREE leverages an arbitrarily scalable pretraining stage and can be applied to any quality standard as long as a small number of human annotations are available. Our experiments show that our metric outperforms existing reference-based metrics in predicting overall ratings and reaches competitive and consistent performance in predicting specific ratings while requiring no reference simplifications at inference time.
Terrain-Attentive Learning for Efficient 6-DoF Kinodynamic Modeling on Vertically Challenging Terrain
Mar 25, 2024Wheeled robots have recently demonstrated superior mechanical capability to traverse vertically challenging terrain (e.g., extremely rugged boulders comparable in size to the vehicles themselves). Negotiating such terrain introduces significant variations of vehicle pose in all six Degrees-of-Freedom (DoFs), leading to imbalanced contact forces, varying momentum, and chassis deformation due to non-rigid tires and suspensions. To autonomously navigate on vertically challenging terrain, all these factors need to be efficiently reasoned within limited onboard computation and strict real-time constraints. In this paper, we propose a 6-DoF kinodynamics learning approach that is attentive only to the specific underlying terrain critical to the current vehicle-terrain interaction, so that it can be efficiently queried in real-time motion planners onboard small robots. Physical experiment results show our Terrain-Attentive Learning demonstrates on average 51.1% reduction in model prediction error among all 6 DoFs compared to a state-of-the-art model for vertically challenging terrain.
Surface-based parcellation and vertex-wise analysis of ultra high-resolution ex vivo 7 tesla MRI in neurodegenerative diseases
Mar 28, 2024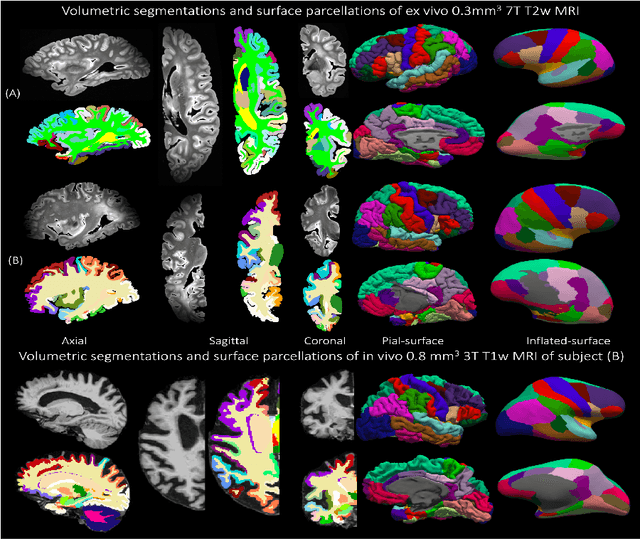
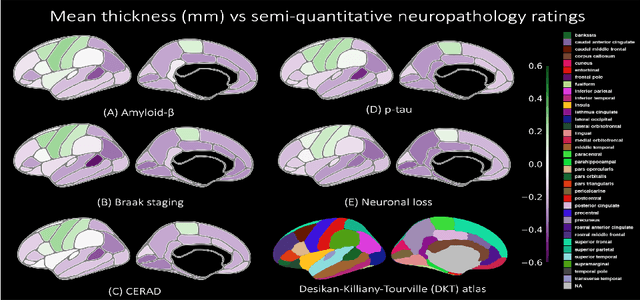
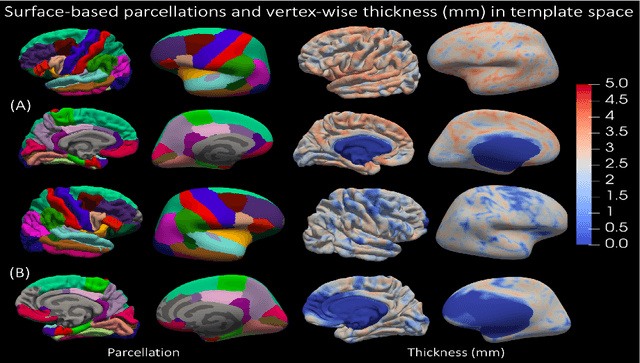
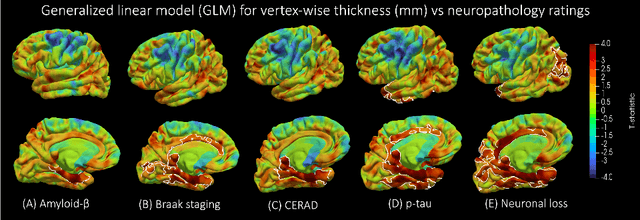
Magnetic resonance imaging (MRI) is the standard modality to understand human brain structure and function in vivo (antemortem). Decades of research in human neuroimaging has led to the widespread development of methods and tools to provide automated volume-based segmentations and surface-based parcellations which help localize brain functions to specialized anatomical regions. Recently ex vivo (postmortem) imaging of the brain has opened-up avenues to study brain structure at sub-millimeter ultra high-resolution revealing details not possible to observe with in vivo MRI. Unfortunately, there has been limited methodological development in ex vivo MRI primarily due to lack of datasets and limited centers with such imaging resources. Therefore, in this work, we present one-of-its-kind dataset of 82 ex vivo T2w whole brain hemispheres MRI at 0.3 mm isotropic resolution spanning Alzheimer's disease and related dementias. We adapted and developed a fast and easy-to-use automated surface-based pipeline to parcellate, for the first time, ultra high-resolution ex vivo brain tissue at the native subject space resolution using the Desikan-Killiany-Tourville (DKT) brain atlas. This allows us to perform vertex-wise analysis in the template space and thereby link morphometry measures with pathology measurements derived from histology. We will open-source our dataset docker container, Jupyter notebooks for ready-to-use out-of-the-box set of tools and command line options to advance ex vivo MRI clinical brain imaging research on the project webpage.