 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Making PPO even better: Value-Guided Monte-Carlo Tree Search decoding
Sep 26, 2023
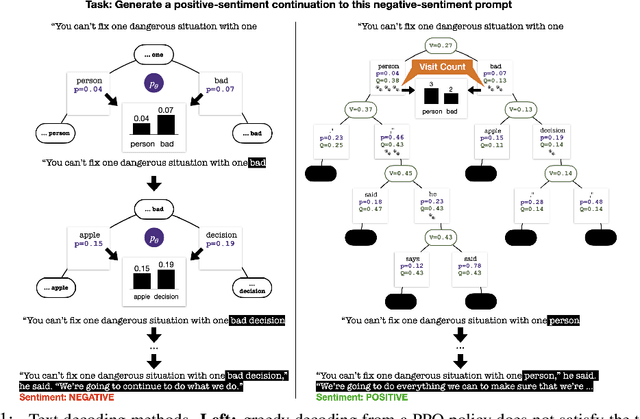
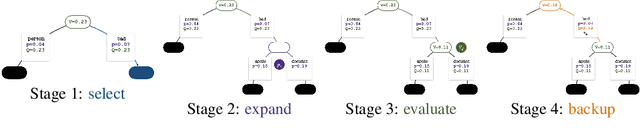


Inference-time search algorithms such as Monte-Carlo Tree Search (MCTS) may seem unnecessary when generating natural language text based on state-of-the-art reinforcement learning such as Proximal Policy Optimization (PPO). In this paper, we demonstrate that it is possible to get extra mileage out of PPO by integrating MCTS on top. The key idea is not to throw out the value network, a byproduct of PPO training for evaluating partial output sequences, when decoding text out of the policy network. More concretely, we present a novel value-guided decoding algorithm called PPO-MCTS, which can integrate the value network from PPO to work closely with the policy network during inference-time generation. Compared to prior approaches based on MCTS for controlled text generation, the key strength of our approach is to reduce the fundamental mismatch of the scoring mechanisms of the partial outputs between training and test. Evaluation on four text generation tasks demonstrate that PPO-MCTS greatly improves the preferability of generated text compared to the standard practice of using only the PPO policy. Our results demonstrate the promise of search algorithms even on top of the aligned language models from PPO, and the under-explored benefit of the value network.
Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints
Oct 05, 2023Text-driven 3D indoor scene generation could be useful for gaming, film industry, and AR/VR applications. However, existing methods cannot faithfully capture the room layout, nor do they allow flexible editing of individual objects in the room. To address these problems, we present Ctrl-Room, which is able to generate convincing 3D rooms with designer-style layouts and high-fidelity textures from just a text prompt. Moreover, Ctrl-Room enables versatile interactive editing operations such as resizing or moving individual furniture items. Our key insight is to separate the modeling of layouts and appearance. %how to model the room that takes into account both scene texture and geometry at the same time. To this end, Our proposed method consists of two stages, a `Layout Generation Stage' and an `Appearance Generation Stage'. The `Layout Generation Stage' trains a text-conditional diffusion model to learn the layout distribution with our holistic scene code parameterization. Next, the `Appearance Generation Stage' employs a fine-tuned ControlNet to produce a vivid panoramic image of the room guided by the 3D scene layout and text prompt. In this way, we achieve a high-quality 3D room with convincing layouts and lively textures. Benefiting from the scene code parameterization, we can easily edit the generated room model through our mask-guided editing module, without expensive editing-specific training. Extensive experiments on the Structured3D dataset demonstrate that our method outperforms existing methods in producing more reasonable, view-consistent, and editable 3D rooms from natural language prompts.
Combining Datasets with Different Label Sets for Improved Nucleus Segmentation and Classification
Oct 05, 2023Segmentation and classification of cell nuclei in histopathology images using deep neural networks (DNNs) can save pathologists' time for diagnosing various diseases, including cancers, by automating cell counting and morphometric assessments. It is now well-known that the accuracy of DNNs increases with the sizes of annotated datasets available for training. Although multiple datasets of histopathology images with nuclear annotations and class labels have been made publicly available, the set of class labels differ across these datasets. We propose a method to train DNNs for instance segmentation and classification on multiple datasets where the set of classes across the datasets are related but not the same. Specifically, our method is designed to utilize a coarse-to-fine class hierarchy, where the set of classes labeled and annotated in a dataset can be at any level of the hierarchy, as long as the classes are mutually exclusive. Within a dataset, the set of classes need not even be at the same level of the class hierarchy tree. Our results demonstrate that segmentation and classification metrics for the class set used by the test split of a dataset can improve by pre-training on another dataset that may even have a different set of classes due to the expansion of the training set enabled by our method. Furthermore, generalization to previously unseen datasets also improves by combining multiple other datasets with different sets of classes for training. The improvement is both qualitative and quantitative. The proposed method can be adapted for various loss functions, DNN architectures, and application domains.
RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation
Oct 05, 2023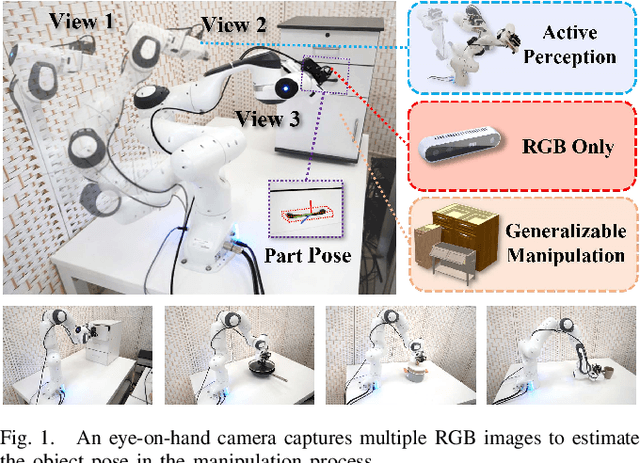
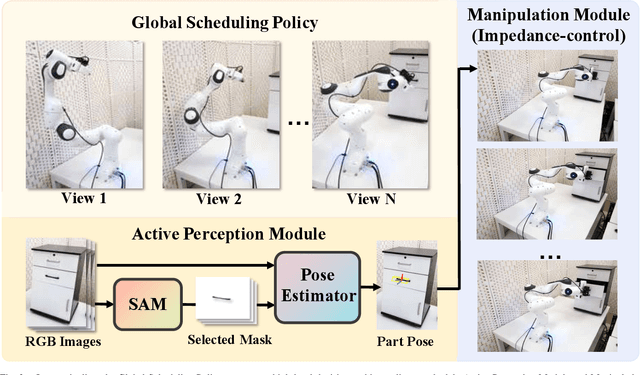

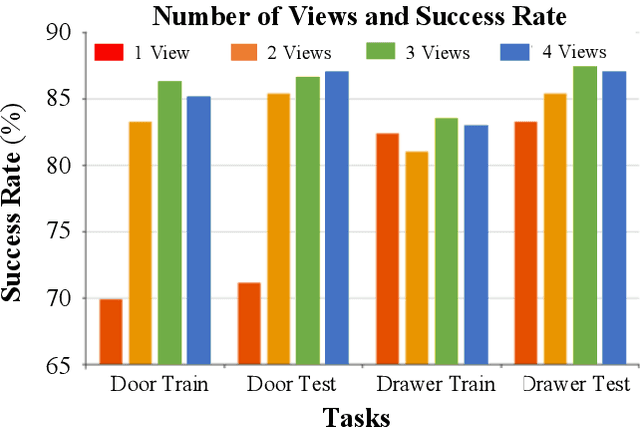
Robotic manipulation requires accurate perception of the environment, which poses a significant challenge due to its inherent complexity and constantly changing nature. In this context, RGB image and point-cloud observations are two commonly used modalities in visual-based robotic manipulation, but each of these modalities have their own limitations. Commercial point-cloud observations often suffer from issues like sparse sampling and noisy output due to the limits of the emission-reception imaging principle. On the other hand, RGB images, while rich in texture information, lack essential depth and 3D information crucial for robotic manipulation. To mitigate these challenges, we propose an image-only robotic manipulation framework that leverages an eye-on-hand monocular camera installed on the robot's parallel gripper. By moving with the robot gripper, this camera gains the ability to actively perceive object from multiple perspectives during the manipulation process. This enables the estimation of 6D object poses, which can be utilized for manipulation. While, obtaining images from more and diverse viewpoints typically improves pose estimation, it also increases the manipulation time. To address this trade-off, we employ a reinforcement learning policy to synchronize the manipulation strategy with active perception, achieving a balance between 6D pose accuracy and manipulation efficiency. Our experimental results in both simulated and real-world environments showcase the state-of-the-art effectiveness of our approach. %, which, to the best of our knowledge, is the first to achieve robust real-world robotic manipulation through active pose estimation. We believe that our method will inspire further research on real-world-oriented robotic manipulation.
Evaluating Multi-Agent Coordination Abilities in Large Language Models
Oct 05, 2023A pivotal aim in contemporary AI research is to develop agents proficient in multi-agent coordination, enabling effective collaboration with both humans and other systems. Large Language Models (LLMs), with their notable ability to understand, generate, and interpret language in a human-like manner, stand out as promising candidates for the development of such agents. In this study, we build and assess the effectiveness of agents crafted using LLMs in various coordination scenarios. We introduce the LLM-Coordination (LLM-Co) Framework, specifically designed to enable LLMs to play coordination games. With the LLM-Co framework, we conduct our evaluation with three game environments and organize the evaluation into five aspects: Theory of Mind, Situated Reasoning, Sustained Coordination, Robustness to Partners, and Explicit Assistance. First, the evaluation of the Theory of Mind and Situated Reasoning reveals the capabilities of LLM to infer the partner's intention and reason actions accordingly. Then, the evaluation around Sustained Coordination and Robustness to Partners further showcases the ability of LLMs to coordinate with an unknown partner in complex long-horizon tasks, outperforming Reinforcement Learning baselines. Lastly, to test Explicit Assistance, which refers to the ability of an agent to offer help proactively, we introduce two novel layouts into the Overcooked-AI benchmark, examining if agents can prioritize helping their partners, sacrificing time that could have been spent on their tasks. This research underscores the promising capabilities of LLMs in sophisticated coordination environments and reveals the potential of LLMs in building strong real-world agents for multi-agent coordination.
Co-modeling the Sequential and Graphical Routes for Peptide Representation Learning
Oct 05, 2023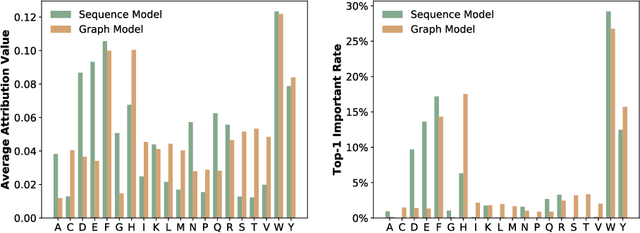
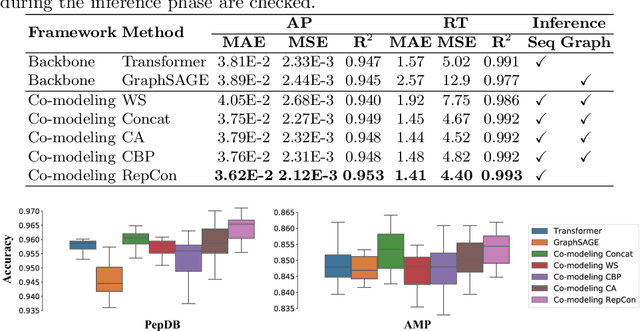
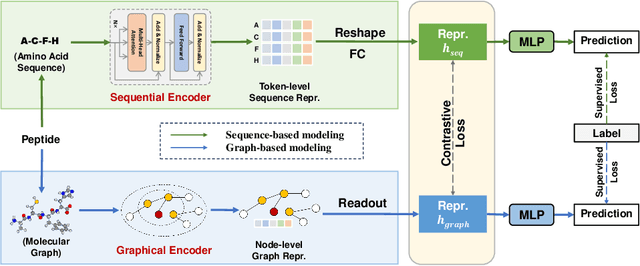
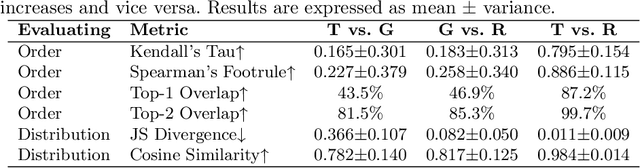
Peptides are formed by the dehydration condensation of multiple amino acids. The primary structure of a peptide can be represented either as an amino acid sequence or as a molecular graph consisting of atoms and chemical bonds. Previous studies have indicated that deep learning routes specific to sequential and graphical peptide forms exhibit comparable performance on downstream tasks. Despite the fact that these models learn representations of the same modality of peptides, we find that they explain their predictions differently. Considering sequential and graphical models as two experts making inferences from different perspectives, we work on fusing expert knowledge to enrich the learned representations for improving the discriminative performance. To achieve this, we propose a peptide co-modeling method, RepCon, which employs a contrastive learning-based framework to enhance the mutual information of representations from decoupled sequential and graphical end-to-end models. It considers representations from the sequential encoder and the graphical encoder for the same peptide sample as a positive pair and learns to enhance the consistency of representations between positive sample pairs and to repel representations between negative pairs. Empirical studies of RepCon and other co-modeling methods are conducted on open-source discriminative datasets, including aggregation propensity, retention time, antimicrobial peptide prediction, and family classification from Peptide Database. Our results demonstrate the superiority of the co-modeling approach over independent modeling, as well as the superiority of RepCon over other methods under the co-modeling framework. In addition, the attribution on RepCon further corroborates the validity of the approach at the level of model explanation.
OceanNet: A principled neural operator-based digital twin for regional oceans
Oct 01, 2023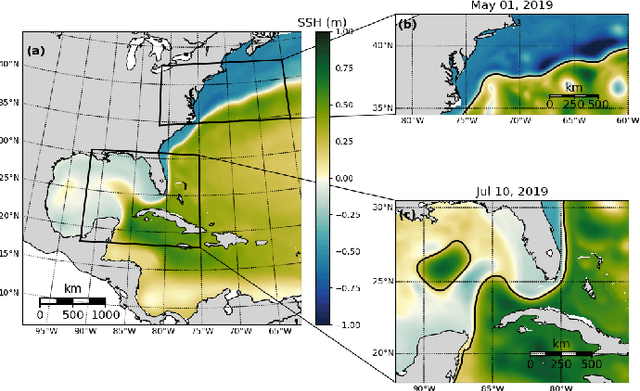
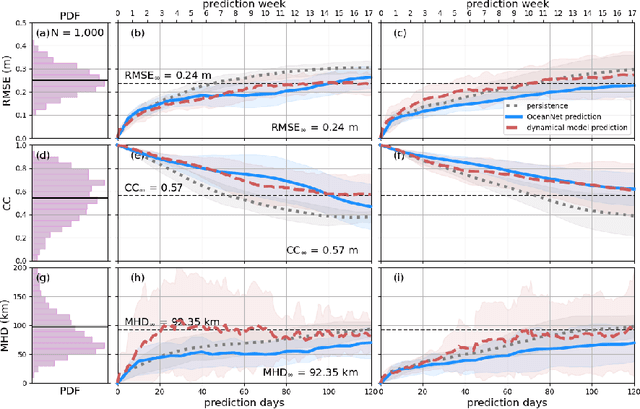
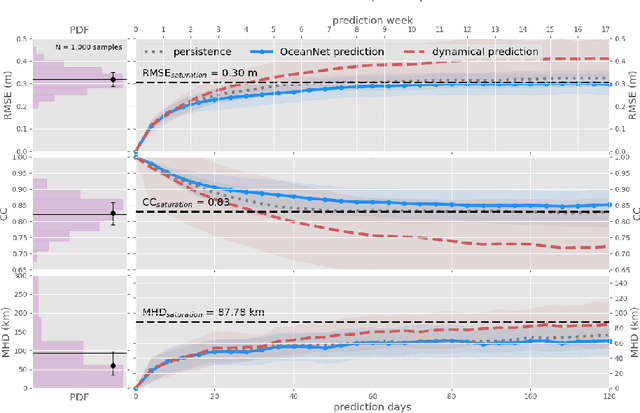
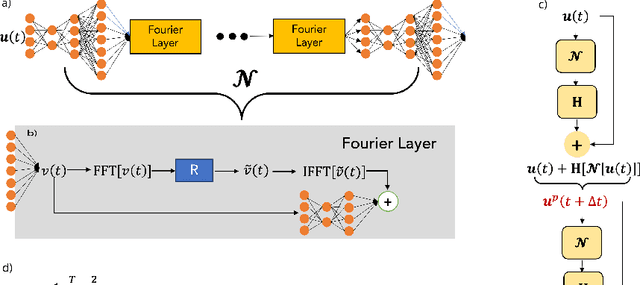
While data-driven approaches demonstrate great potential in atmospheric modeling and weather forecasting, ocean modeling poses distinct challenges due to complex bathymetry, land, vertical structure, and flow non-linearity. This study introduces OceanNet, a principled neural operator-based digital twin for ocean circulation. OceanNet uses a Fourier neural operator and predictor-evaluate-corrector integration scheme to mitigate autoregressive error growth and enhance stability over extended time scales. A spectral regularizer counteracts spectral bias at smaller scales. OceanNet is applied to the northwest Atlantic Ocean western boundary current (the Gulf Stream), focusing on the task of seasonal prediction for Loop Current eddies and the Gulf Stream meander. Trained using historical sea surface height (SSH) data, OceanNet demonstrates competitive forecast skill by outperforming SSH predictions by an uncoupled, state-of-the-art dynamical ocean model forecast, reducing computation by 500,000 times. These accomplishments demonstrate the potential of physics-inspired deep neural operators as cost-effective alternatives to high-resolution numerical ocean models.
Quantum generative adversarial learning in photonics
Oct 01, 2023Quantum Generative Adversarial Networks (QGANs), an intersection of quantum computing and machine learning, have attracted widespread attention due to their potential advantages over classical analogs. However, in the current era of Noisy Intermediate-Scale Quantum (NISQ) computing, it is essential to investigate whether QGANs can perform learning tasks on near-term quantum devices usually affected by noise and even defects. In this Letter, using a programmable silicon quantum photonic chip, we experimentally demonstrate the QGAN model in photonics for the first time, and investigate the effects of noise and defects on its performance. Our results show that QGANs can generate high-quality quantum data with a fidelity higher than 90\%, even under conditions where up to half of the generator's phase shifters are damaged, or all of the generator and discriminator's phase shifters are subjected to phase noise up to 0.04$\pi$. Our work sheds light on the feasibility of implementing QGANs on NISQ-era quantum hardware.
GeoAdapt: Self-Supervised Test-Time Adaption in LiDAR Place Recognition Using Geometric Priors
Aug 09, 2023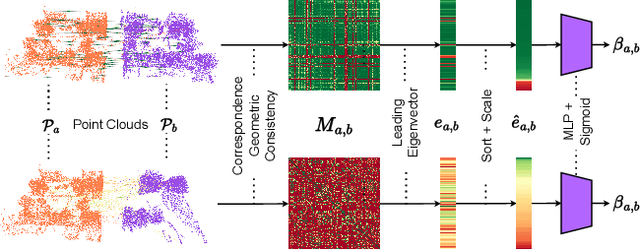
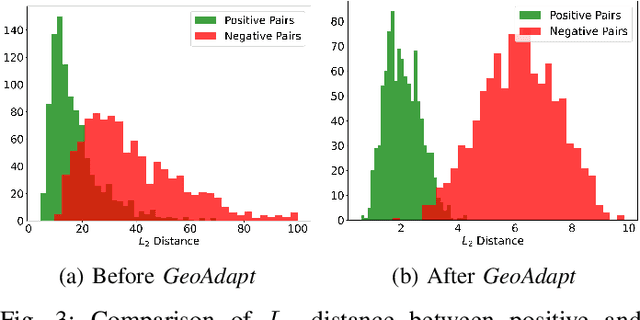
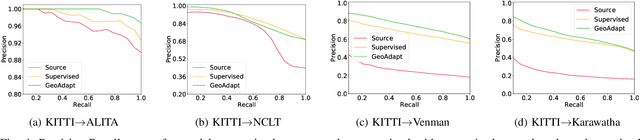

LiDAR place recognition approaches based on deep learning suffer a significant degradation in performance when there is a shift between the distribution of the training and testing datasets, with re-training often required to achieve top performance. However, obtaining accurate ground truth on new environments can be prohibitively expensive, especially in complex or GPS-deprived environments. To address this issue we propose GeoAdapt, which introduces a novel auxiliary classification head to generate pseudo-labels for re-training on unseen environments in a self-supervised manner. GeoAdapt uses geometric consistency as a prior to improve the robustness of our generated pseudo-labels against domain shift, improving the performance and reliability of our Test-Time Adaptation approach. Comprehensive experiments show that GeoAdapt significantly boosts place recognition performance across moderate to severe domain shifts, and is competitive with fully supervised test-time adaptation approaches. Our code will be available at https://github.com/csiro-robotics/GeoAdapt.
Integrate-and-fire circuit for converting analog signals to spikes using phase encoding
Oct 03, 2023Processing sensor data with spiking neural networks on digital neuromorphic chips requires converting continuous analog signals into spike pulses. Two strategies are promising for achieving low energy consumption and fast processing speeds in end-to-end neuromorphic applications. First, to directly encode analog signals to spikes to bypass the need for an analog-to-digital converter (ADC). Second, to use temporal encoding techniques to maximize the spike sparsity, which is a crucial parameter for fast and efficient neuromorphic processing. In this work, we propose an adaptive control of the refractory period of the leaky integrate-and-fire (LIF) neuron model for encoding continuous analog signals into a train of time-coded spikes. The LIF-based encoder generates phase-encoded spikes that are compatible with digital hardware. We implemented the neuron model on a physical circuit and tested it with different electric signals. A digital neuromorphic chip processed the generated spike trains and computed the signal's frequency spectrum using a spiking version of the Fourier transform. We tested the prototype circuit on electric signals up to 1 KHz. Thus, we provide an end-to-end neuromorphic application that generates the frequency spectrum of an electric signal without the need for an ADC or a digital signal processing algorithm.
* 13 pages