 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HappyFeat -- An interactive and efficient BCI framework for clinical applications
Oct 04, 2023
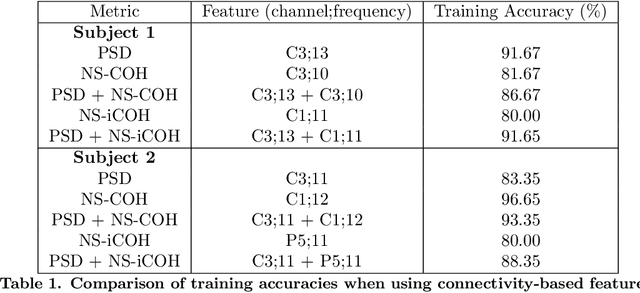
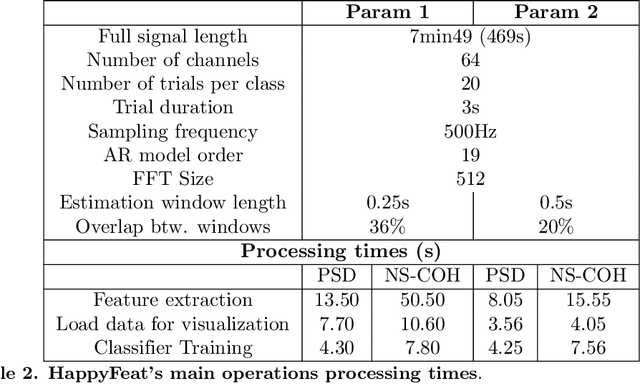
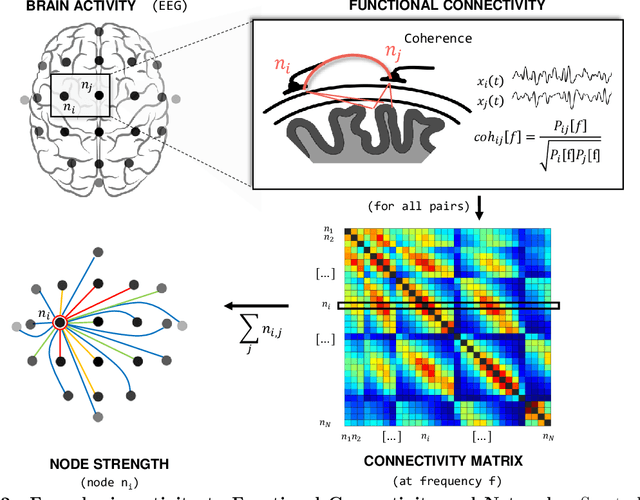
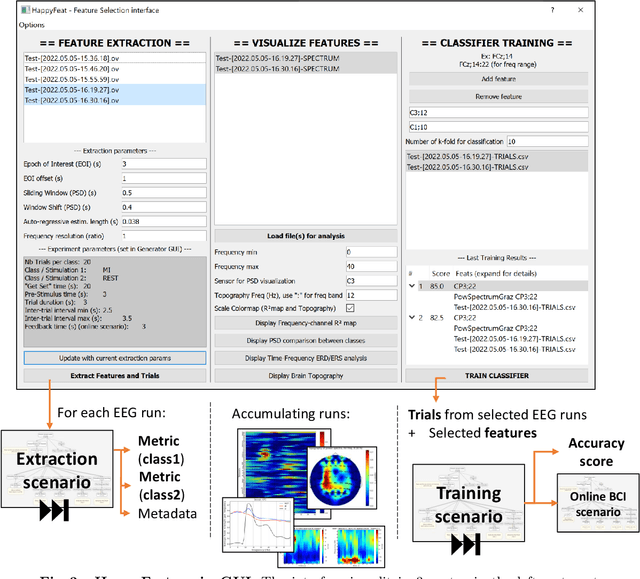
Brain-Computer Interface (BCI) systems allow users to perform actions by translating their brain activity into commands. Such systems usually need a training phase, consisting in training a classification algorithm to discriminate between mental states using specific features from the recorded signals. This phase of feature selection and training is crucial for BCI performance and presents specific constraints to be met in a clinical context, such as post-stroke rehabilitation. In this paper, we present HappyFeat, a software making Motor Imagery (MI) based BCI experiments easier, by gathering all necessary manipulations and analysis in a single convenient GUI and via automation of experiment or analysis parameters. The resulting workflow allows for effortlessly selecting the best features, helping to achieve good BCI performance in time-constrained environments. Alternative features based on Functional Connectivity can be used and compared or combined with Power Spectral Density, allowing a network-oriented approach. We then give details of HappyFeat's main mechanisms, and a review of its performances in typical use cases. We also show that it can be used as an efficient tool for comparing different metrics extracted from the signals, to train the classification algorithm. To this end, we show a comparison between the commonly-used Power Spectral Density and network metrics based on Functional Connectivity. HappyFeat is available as an open-source project which can be freely downloaded on GitHub.
Prescanning Assembly Optimization Criteria for Computed Tomography
Sep 29, 2023Computerized Tomography assembly and system configuration are optimized for enhanced invertibility in sparse data reconstruction. Assembly generating maximum principal components/condition number of weight matrix is designated as best configuration. The gamma CT system is used for testing. The unoptimized sample location placement with 7.7% variation results in a maximum 50% root mean square error, 16.5% loss of similarity index, and 40% scattering noise in the reconstructed image relative to the optimized sample location when the proposed criteria are used. The method can help to automate the CT assembly, resulting in relatively artifact-free recovery and reducing the iteration to figure out the best scanning configuration for a given sample size, thus saving time, dosage, and operational cost.
Nowcasting day-ahead marginal emissions using multi-headed CNNs and deep generative models
Oct 02, 2023Nowcasting day-ahead marginal emissions factors is increasingly important for power systems with high flexibility and penetration of distributed energy resources. With a significant share of firm generation from natural gas and coal power plants, forecasting day-ahead emissions in the current energy system has been widely studied. In contrast, as we shift to an energy system characterized by flexible power markets, dispatchable sources, and competing low-cost generation such as large-scale battery or hydrogen storage, system operators will be able to choose from a mix of different generation as well as emission pathways. To fully develop the emissions implications of a given dispatch schedule, we need a near real-time workflow with two layers. The first layer is a market model that continuously solves a security-constrained economic dispatch model. The second layer determines the marginal emissions based on the output of the market model, which is the subject of this paper. We propose using multi-headed convolutional neural networks to generate day-ahead forecasts of marginal and average emissions for a given independent system operator.
It's MBR All the Way Down: Modern Generation Techniques Through the Lens of Minimum Bayes Risk
Oct 02, 2023Minimum Bayes Risk (MBR) decoding is a method for choosing the outputs of a machine learning system based not on the output with the highest probability, but the output with the lowest risk (expected error) among multiple candidates. It is a simple but powerful method: for an additional cost at inference time, MBR provides reliable several-point improvements across metrics for a wide variety of tasks without any additional data or training. Despite this, MBR is not frequently applied in NLP works, and knowledge of the method itself is limited. We first provide an introduction to the method and the recent literature. We show that several recent methods that do not reference MBR can be written as special cases of MBR; this reformulation provides additional theoretical justification for the performance of these methods, explaining some results that were previously only empirical. We provide theoretical and empirical results about the effectiveness of various MBR variants and make concrete recommendations for the application of MBR in NLP models, including future directions in this area.
Seismogram Transformer: A generic deep learning backbone network for multiple earthquake monitoring tasks
Oct 02, 2023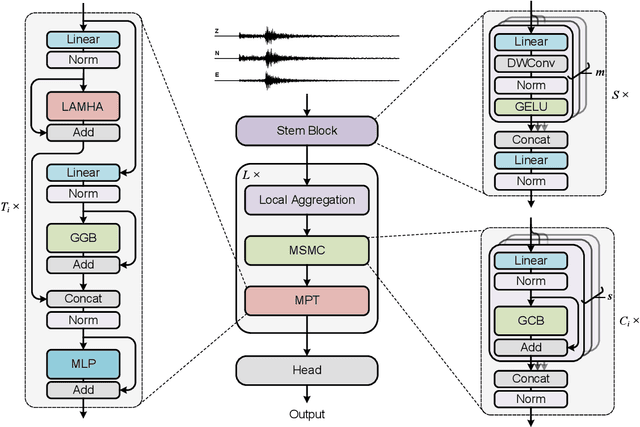
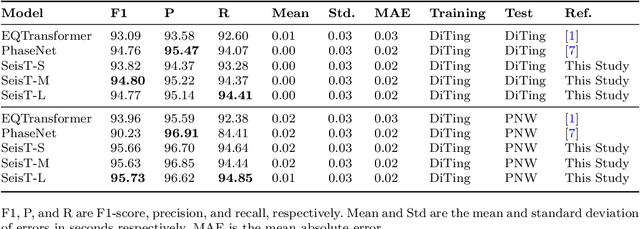
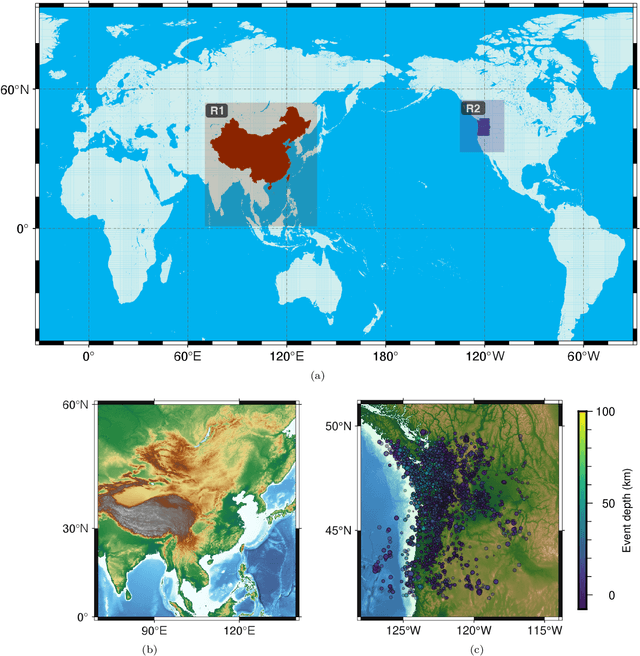
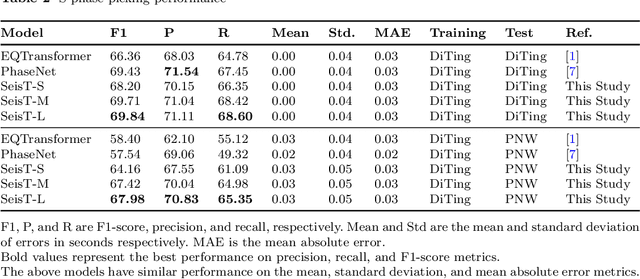
Seismic records, known as seismograms, are crucial records of ground motion resulting from seismic events, constituting the backbone of earthquake research and monitoring. The latest advancements in deep learning have significantly facilitated various seismic signal processing tasks. This paper introduces a novel backbone neural network model designed for various seismic monitoring tasks, named Seismogram Transformer (SeisT). Thanks to its efficient network architecture, SeisT matches or even outperforms the state-of-the-art models in earthquake detection, seismic phase picking, first-motion polarity classification, magnitude estimation, and azimuth estimation tasks, particularly in terms of out-of-distribution generalization performance. SeisT consists of multiple network layers composed of different foundational blocks, which help the model understand multi-level feature representations of seismograms from low-level to high-level complex features, effectively extracting features such as frequency, phase, and time-frequency relationships from input seismograms. Three different-sized models were customized based on these diverse foundational modules. Through extensive experiments and performance evaluations, this study showcases the capabilities and potential of SeisT in advancing seismic signal processing and earthquake research.
Application of frozen large-scale models to multimodal task-oriented dialogue
Oct 02, 2023In this study, we use the existing Large Language Models ENnhanced to See Framework (LENS Framework) to test the feasibility of multimodal task-oriented dialogues. The LENS Framework has been proposed as a method to solve computer vision tasks without additional training and with fixed parameters of pre-trained models. We used the Multimodal Dialogs (MMD) dataset, a multimodal task-oriented dialogue benchmark dataset from the fashion field, and for the evaluation, we used the ChatGPT-based G-EVAL, which only accepts textual modalities, with arrangements to handle multimodal data. Compared to Transformer-based models in previous studies, our method demonstrated an absolute lift of 10.8% in fluency, 8.8% in usefulness, and 5.2% in relevance and coherence. The results show that using large-scale models with fixed parameters rather than using models trained on a dataset from scratch improves performance in multimodal task-oriented dialogues. At the same time, we show that Large Language Models (LLMs) are effective for multimodal task-oriented dialogues. This is expected to lead to efficient applications to existing systems.
Ultrafast and Ultralight Network-Based Intelligent System for Real-time Diagnosis of Ear diseases in Any Devices
Aug 21, 2023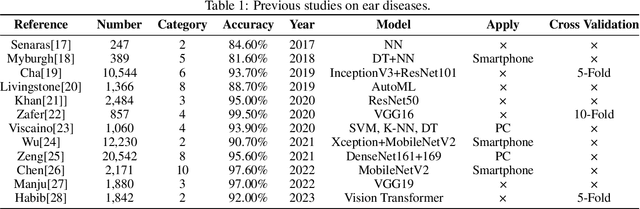
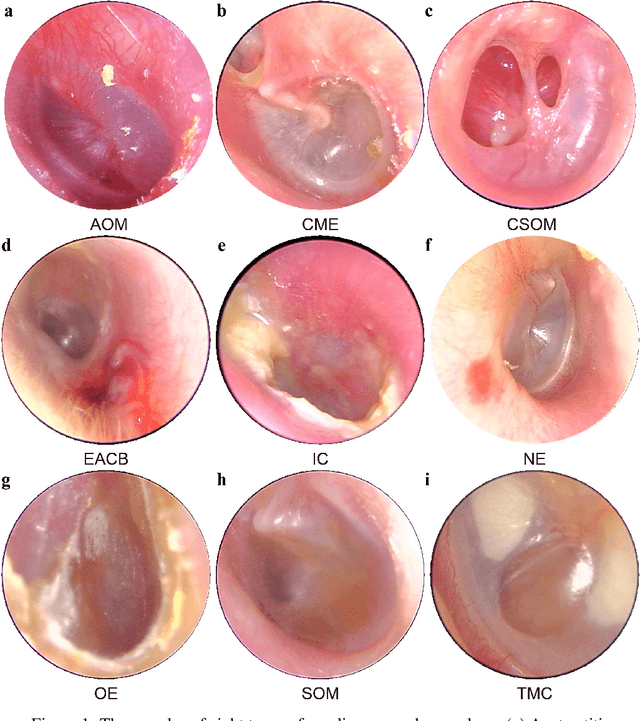

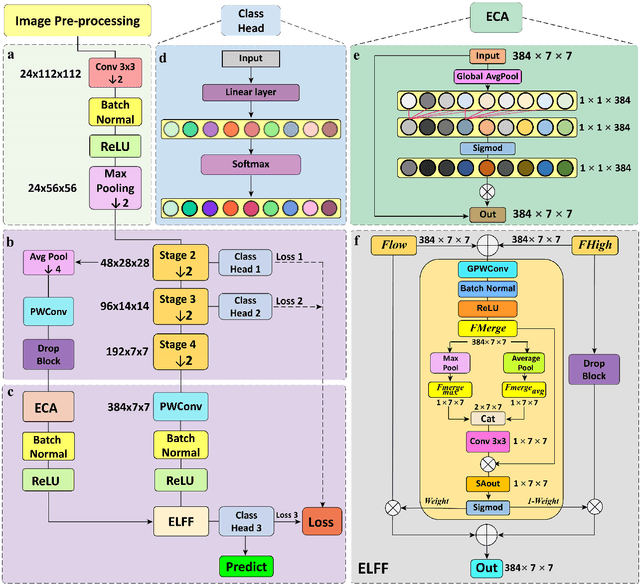
Traditional ear disease diagnosis heavily depends on experienced specialists and specialized equipment, frequently resulting in misdiagnoses, treatment delays, and financial burdens for some patients. Utilizing deep learning models for efficient ear disease diagnosis has proven effective and affordable. However, existing research overlooked model inference speed and parameter size required for deployment. To tackle these challenges, we constructed a large-scale dataset comprising eight ear disease categories and normal ear canal samples from two hospitals. Inspired by ShuffleNetV2, we developed Best-EarNet, an ultrafast and ultralight network enabling real-time ear disease diagnosis. Best-EarNet incorporates the novel Local-Global Spatial Feature Fusion Module which can capture global and local spatial information simultaneously and guide the network to focus on crucial regions within feature maps at various levels, mitigating low accuracy issues. Moreover, our network uses multiple auxiliary classification heads for efficient parameter optimization. With 0.77M parameters, Best-EarNet achieves an average frames per second of 80 on CPU. Employing transfer learning and five-fold cross-validation with 22,581 images from Hospital-1, the model achieves an impressive 95.23% accuracy. External testing on 1,652 images from Hospital-2 validates its performance, yielding 92.14% accuracy. Compared to state-of-the-art networks, Best-EarNet establishes a new state-of-the-art (SOTA) in practical applications. Most importantly, we developed an intelligent diagnosis system called Ear Keeper, which can be deployed on common electronic devices. By manipulating a compact electronic otoscope, users can perform comprehensive scanning and diagnosis of the ear canal using real-time video. This study provides a novel paradigm for ear endoscopy and other medical endoscopic image recognition applications.
Identifying Representations for Intervention Extrapolation
Oct 06, 2023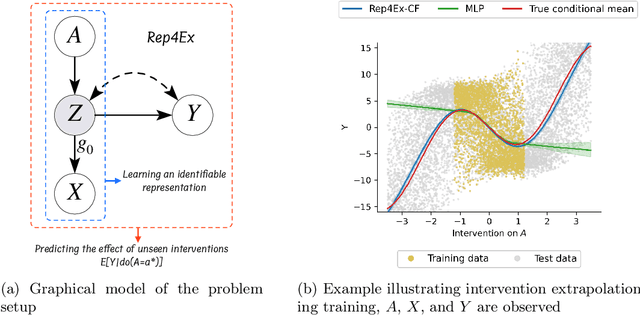
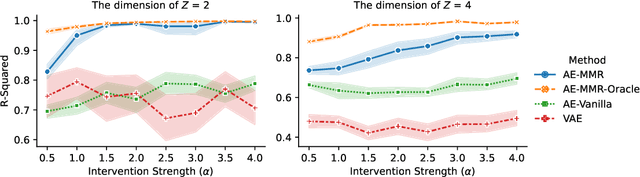
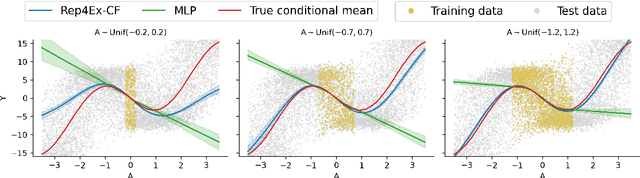
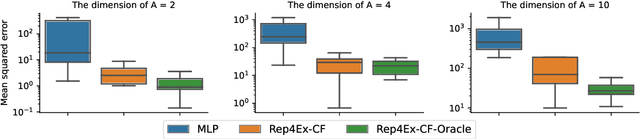
The premise of identifiable and causal representation learning is to improve the current representation learning paradigm in terms of generalizability or robustness. Despite recent progress in questions of identifiability, more theoretical results demonstrating concrete advantages of these methods for downstream tasks are needed. In this paper, we consider the task of intervention extrapolation: predicting how interventions affect an outcome, even when those interventions are not observed at training time, and show that identifiable representations can provide an effective solution to this task even if the interventions affect the outcome non-linearly. Our setup includes an outcome Y, observed features X, which are generated as a non-linear transformation of latent features Z, and exogenous action variables A, which influence Z. The objective of intervention extrapolation is to predict how interventions on A that lie outside the training support of A affect Y. Here, extrapolation becomes possible if the effect of A on Z is linear and the residual when regressing Z on A has full support. As Z is latent, we combine the task of intervention extrapolation with identifiable representation learning, which we call Rep4Ex: we aim to map the observed features X into a subspace that allows for non-linear extrapolation in A. We show using Wiener's Tauberian theorem that the hidden representation is identifiable up to an affine transformation in Z-space, which is sufficient for intervention extrapolation. The identifiability is characterized by a novel constraint describing the linearity assumption of A on Z. Based on this insight, we propose a method that enforces the linear invariance constraint and can be combined with any type of autoencoder. We validate our theoretical findings through synthetic experiments and show that our approach succeeds in predicting the effects of unseen interventions.
Understanding, Predicting and Better Resolving Q-Value Divergence in Offline-RL
Oct 06, 2023The divergence of the Q-value estimation has been a prominent issue in offline RL, where the agent has no access to real dynamics. Traditional beliefs attribute this instability to querying out-of-distribution actions when bootstrapping value targets. Though this issue can be alleviated with policy constraints or conservative Q estimation, a theoretical understanding of the underlying mechanism causing the divergence has been absent. In this work, we aim to thoroughly comprehend this mechanism and attain an improved solution. We first identify a fundamental pattern, self-excitation, as the primary cause of Q-value estimation divergence in offline RL. Then, we propose a novel Self-Excite Eigenvalue Measure (SEEM) metric based on Neural Tangent Kernel (NTK) to measure the evolving property of Q-network at training, which provides an intriguing explanation of the emergence of divergence. For the first time, our theory can reliably decide whether the training will diverge at an early stage, and even predict the order of the growth for the estimated Q-value, the model's norm, and the crashing step when an SGD optimizer is used. The experiments demonstrate perfect alignment with this theoretic analysis. Building on our insights, we propose to resolve divergence from a novel perspective, namely improving the model's architecture for better extrapolating behavior. Through extensive empirical studies, we identify LayerNorm as a good solution to effectively avoid divergence without introducing detrimental bias, leading to superior performance. Experimental results prove that it can still work in some most challenging settings, i.e. using only 1 transitions of the dataset, where all previous methods fail. Moreover, it can be easily plugged into modern offline RL methods and achieve SOTA results on many challenging tasks. We also give unique insights into its effectiveness.
* 31 pages, 20 figures
Markov Decision Processes with Time-Varying Geometric Discounting
Jul 19, 2023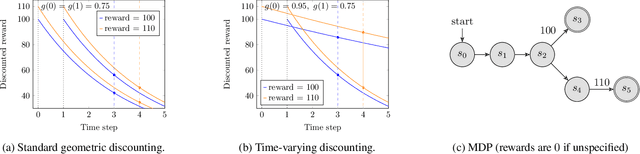

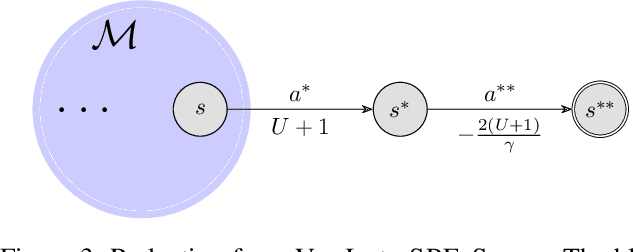
Canonical models of Markov decision processes (MDPs) usually consider geometric discounting based on a constant discount factor. While this standard modeling approach has led to many elegant results, some recent studies indicate the necessity of modeling time-varying discounting in certain applications. This paper studies a model of infinite-horizon MDPs with time-varying discount factors. We take a game-theoretic perspective -- whereby each time step is treated as an independent decision maker with their own (fixed) discount factor -- and we study the subgame perfect equilibrium (SPE) of the resulting game as well as the related algorithmic problems. We present a constructive proof of the existence of an SPE and demonstrate the EXPTIME-hardness of computing an SPE. We also turn to the approximate notion of $\epsilon$-SPE and show that an $\epsilon$-SPE exists under milder assumptions. An algorithm is presented to compute an $\epsilon$-SPE, of which an upper bound of the time complexity, as a function of the convergence property of the time-varying discount factor, is provided.
* 24 pages, 3 figures