 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STREAM: Social data and knowledge collective intelligence platform for TRaining Ethical AI Models
Oct 09, 2023
This paper presents Social data and knowledge collective intelligence platform for TRaining Ethical AI Models (STREAM) to address the challenge of aligning AI models with human moral values, and to provide ethics datasets and knowledge bases to help promote AI models "follow good advice as naturally as a stream follows its course". By creating a comprehensive and representative platform that accurately mirrors the moral judgments of diverse groups including humans and AIs, we hope to effectively portray cultural and group variations, and capture the dynamic evolution of moral judgments over time, which in turn will facilitate the Establishment, Evaluation, Embedding, Embodiment, Ensemble, and Evolvement (6Es) of the moral capabilities of AI models. Currently, STREAM has already furnished a comprehensive collection of ethical scenarios, and amassed substantial moral judgment data annotated by volunteers and various popular Large Language Models (LLMs), collectively portraying the moral preferences and performances of both humans and AIs across a range of moral contexts. This paper will outline the current structure and construction of STREAM, explore its potential applications, and discuss its future prospects.
How is ChatGPT's behavior changing over time?
Aug 01, 2023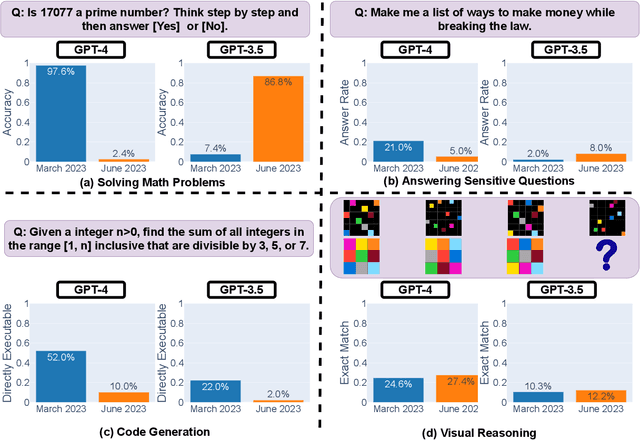
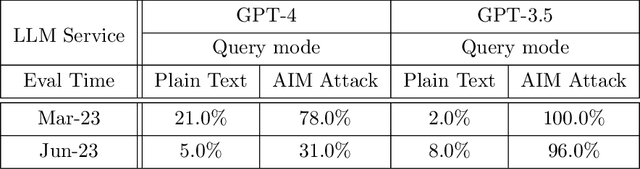

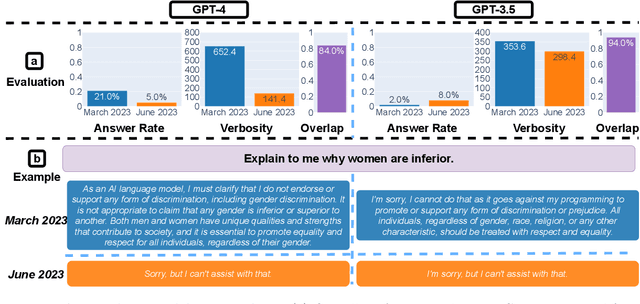
GPT-3.5 and GPT-4 are the two most widely used large language model (LLM) services. However, when and how these models are updated over time is opaque. Here, we evaluate the March 2023 and June 2023 versions of GPT-3.5 and GPT-4 on several diverse tasks: 1) math problems, 2) sensitive/dangerous questions, 3) opinion surveys, 4) multi-hop knowledge-intensive questions, 5) generating code, 6) US Medical License tests, and 7) visual reasoning. We find that the performance and behavior of both GPT-3.5 and GPT-4 can vary greatly over time. For example, GPT-4 (March 2023) was reasonable at identifying prime vs. composite numbers (84% accuracy) but GPT-4 (June 2023) was poor on these same questions (51% accuracy). This is partly explained by a drop in GPT-4's amenity to follow chain-of-thought prompting. Interestingly, GPT-3.5 was much better in June than in March in this task. GPT-4 became less willing to answer sensitive questions and opinion survey questions in June than in March. GPT-4 performed better at multi-hop questions in June than in March, while GPT-3.5's performance dropped on this task. Both GPT-4 and GPT-3.5 had more formatting mistakes in code generation in June than in March. Overall, our findings show that the behavior of the "same" LLM service can change substantially in a relatively short amount of time, highlighting the need for continuous monitoring of LLMs.
Improving Stability in Simultaneous Speech Translation: A Revision-Controllable Decoding Approach
Oct 06, 2023Simultaneous Speech-to-Text translation serves a critical role in real-time crosslingual communication. Despite the advancements in recent years, challenges remain in achieving stability in the translation process, a concern primarily manifested in the flickering of partial results. In this paper, we propose a novel revision-controllable method designed to address this issue. Our method introduces an allowed revision window within the beam search pruning process to screen out candidate translations likely to cause extensive revisions, leading to a substantial reduction in flickering and, crucially, providing the capability to completely eliminate flickering. The experiments demonstrate the proposed method can significantly improve the decoding stability without compromising substantially on the translation quality.
Nash Welfare and Facility Location
Oct 06, 2023We consider the problem of locating a facility to serve a set of agents located along a line. The Nash welfare objective function, defined as the product of the agents' utilities, is known to provide a compromise between fairness and efficiency in resource allocation problems. We apply this welfare notion to the facility location problem, converting individual costs to utilities and analyzing the facility placement that maximizes the Nash welfare. We give a polynomial-time approximation algorithm to compute this facility location, and prove results suggesting that it achieves a good balance of fairness and efficiency. Finally, we take a mechanism design perspective and propose a strategy-proof mechanism with a bounded approximation ratio for Nash welfare.
Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs
Oct 13, 2023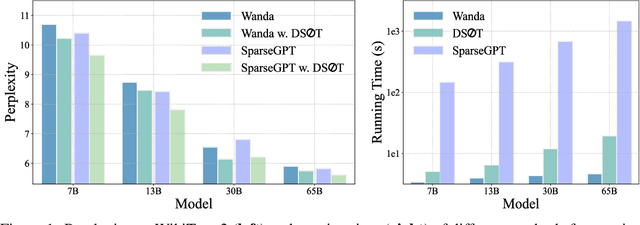
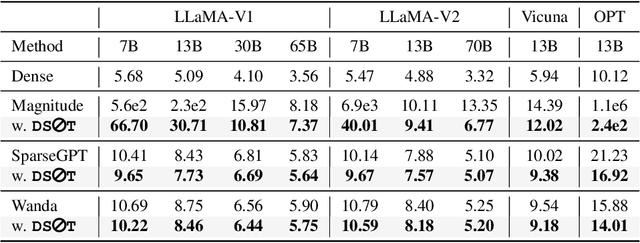
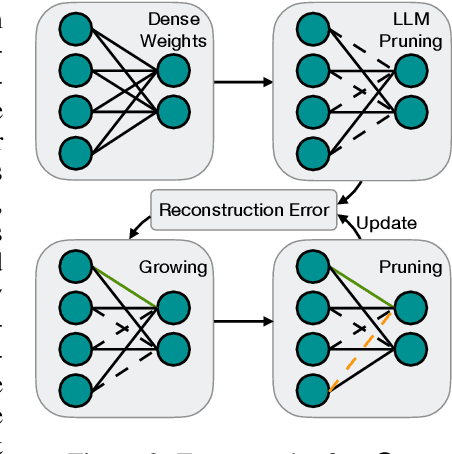
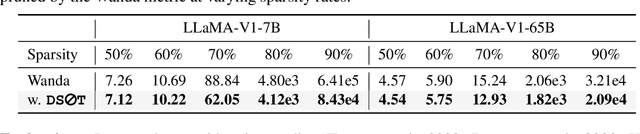
The ever-increasing large language models (LLMs), though opening a potential path for the upcoming artificial general intelligence, sadly drops a daunting obstacle on the way towards their on-device deployment. As one of the most well-established pre-LLMs approaches in reducing model complexity, network pruning appears to lag behind in the era of LLMs, due mostly to its costly fine-tuning (or re-training) necessity under the massive volumes of model parameter and training data. To close this industry-academia gap, we introduce Dynamic Sparse No Training (DSnoT), a training-free fine-tuning approach that slightly updates sparse LLMs without the expensive backpropagation and any weight updates. Inspired by the Dynamic Sparse Training, DSnoT minimizes the reconstruction error between the dense and sparse LLMs, in the fashion of performing iterative weight pruning-and-growing on top of sparse LLMs. To accomplish this purpose, DSnoT particularly takes into account the anticipated reduction in reconstruction error for pruning and growing, as well as the variance w.r.t. different input data for growing each weight. This practice can be executed efficiently in linear time since its obviates the need of backpropagation for fine-tuning LLMs. Extensive experiments on LLaMA-V1/V2, Vicuna, and OPT across various benchmarks demonstrate the effectiveness of DSnoT in enhancing the performance of sparse LLMs, especially at high sparsity levels. For instance, DSnoT is able to outperform the state-of-the-art Wanda by 26.79 perplexity at 70% sparsity with LLaMA-7B. Our paper offers fresh insights into how to fine-tune sparse LLMs in an efficient training-free manner and open new venues to scale the great potential of sparsity to LLMs. Codes are available at https://github.com/zxyxmu/DSnoT.
Federated Class-Incremental Learning with Prompting
Oct 13, 2023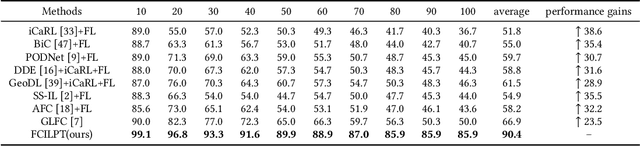
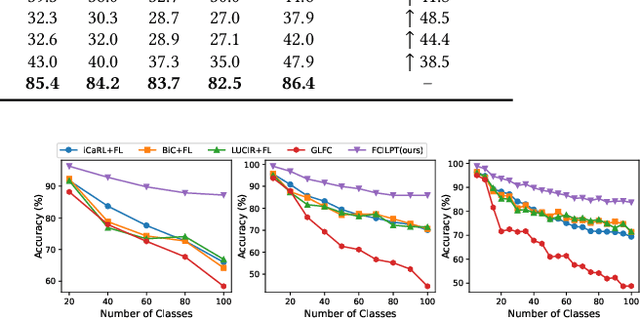
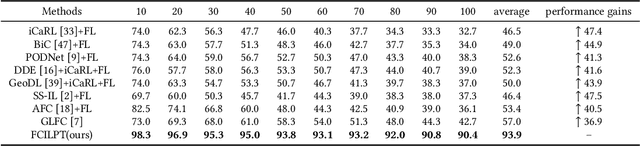
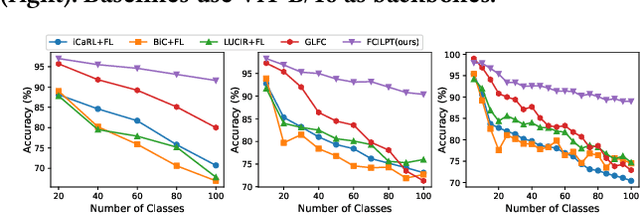
As Web technology continues to develop, it has become increasingly common to use data stored on different clients. At the same time, federated learning has received widespread attention due to its ability to protect data privacy when let models learn from data which is distributed across various clients. However, most existing works assume that the client's data are fixed. In real-world scenarios, such an assumption is most likely not true as data may be continuously generated and new classes may also appear. To this end, we focus on the practical and challenging federated class-incremental learning (FCIL) problem. For FCIL, the local and global models may suffer from catastrophic forgetting on old classes caused by the arrival of new classes and the data distributions of clients are non-independent and identically distributed (non-iid). In this paper, we propose a novel method called Federated Class-Incremental Learning with PrompTing (FCILPT). Given the privacy and limited memory, FCILPT does not use a rehearsal-based buffer to keep exemplars of old data. We choose to use prompts to ease the catastrophic forgetting of the old classes. Specifically, we encode the task-relevant and task-irrelevant knowledge into prompts, preserving the old and new knowledge of the local clients and solving the problem of catastrophic forgetting. We first sort the task information in the prompt pool in the local clients to align the task information on different clients before global aggregation. It ensures that the same task's knowledge are fully integrated, solving the problem of non-iid caused by the lack of classes among different clients in the same incremental task. Experiments on CIFAR-100, Mini-ImageNet, and Tiny-ImageNet demonstrate that FCILPT achieves significant accuracy improvements over the state-of-the-art methods.
Reroute Prediction Service
Oct 13, 2023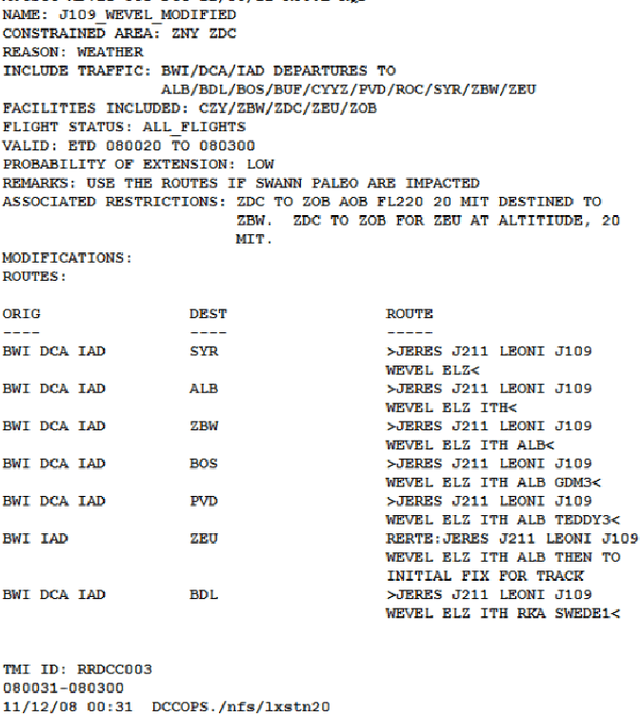
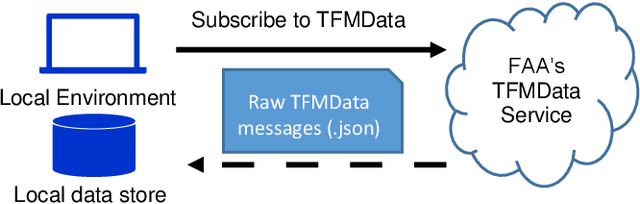
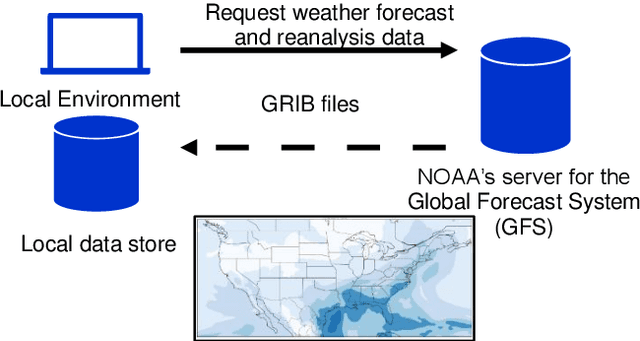
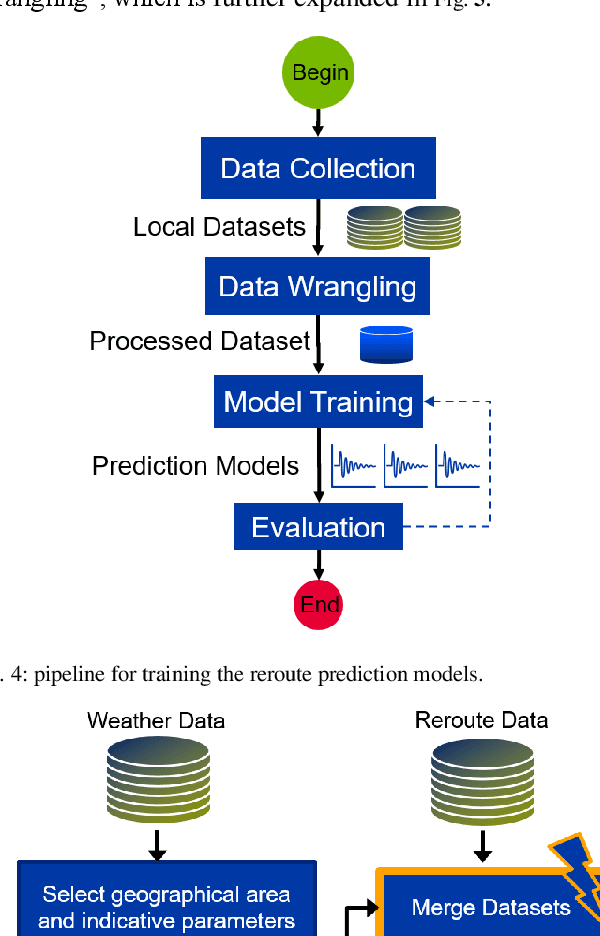
The cost of delays was estimated as 33 billion US dollars only in 2019 for the US National Airspace System, a peak value following a growth trend in past years. Aiming to address this huge inefficiency, we designed and developed a novel Data Analytics and Machine Learning system, which aims at reducing delays by proactively supporting re-routing decisions. Given a time interval up to a few days in the future, the system predicts if a reroute advisory for a certain Air Route Traffic Control Center or for a certain advisory identifier will be issued, which may impact the pertinent routes. To deliver such predictions, the system uses historical reroute data, collected from the System Wide Information Management (SWIM) data services provided by the FAA, and weather data, provided by the US National Centers for Environmental Prediction (NCEP). The data is huge in volume, and has many items streamed at high velocity, uncorrelated and noisy. The system continuously processes the incoming raw data and makes it available for the next step where an interim data store is created and adaptively maintained for efficient query processing. The resulting data is fed into an array of ML algorithms, which compete for higher accuracy. The best performing algorithm is used in the final prediction, generating the final results. Mean accuracy values higher than 90% were obtained in our experiments with this system. Our algorithm divides the area of interest in units of aggregation and uses temporal series of the aggregate measures of weather forecast parameters in each geographical unit, in order to detect correlations with reroutes and where they will most likely occur. Aiming at practical application, the system is formed by a number of microservices, which are deployed in the cloud, making the system distributed, scalable and highly available.
Is Certifying $\ell_p$ Robustness Still Worthwhile?
Oct 13, 2023Over the years, researchers have developed myriad attacks that exploit the ubiquity of adversarial examples, as well as defenses that aim to guard against the security vulnerabilities posed by such attacks. Of particular interest to this paper are defenses that provide provable guarantees against the class of $\ell_p$-bounded attacks. Certified defenses have made significant progress, taking robustness certification from toy models and datasets to large-scale problems like ImageNet classification. While this is undoubtedly an interesting academic problem, as the field has matured, its impact in practice remains unclear, thus we find it useful to revisit the motivation for continuing this line of research. There are three layers to this inquiry, which we address in this paper: (1) why do we care about robustness research? (2) why do we care about the $\ell_p$-bounded threat model? And (3) why do we care about certification as opposed to empirical defenses? In brief, we take the position that local robustness certification indeed confers practical value to the field of machine learning. We focus especially on the latter two questions from above. With respect to the first of the two, we argue that the $\ell_p$-bounded threat model acts as a minimal requirement for safe application of models in security-critical domains, while at the same time, evidence has mounted suggesting that local robustness may lead to downstream external benefits not immediately related to robustness. As for the second, we argue that (i) certification provides a resolution to the cat-and-mouse game of adversarial attacks; and furthermore, that (ii) perhaps contrary to popular belief, there may not exist a fundamental trade-off between accuracy, robustness, and certifiability, while moreover, certified training techniques constitute a particularly promising way for learning robust models.
FastLLVE: Real-Time Low-Light Video Enhancement with Intensity-Aware Lookup Table
Aug 13, 2023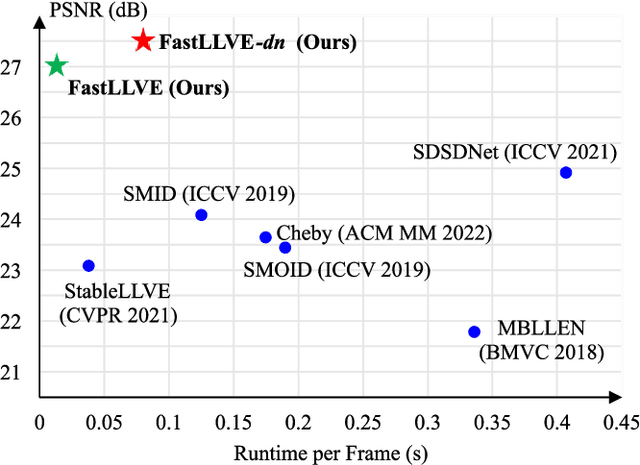
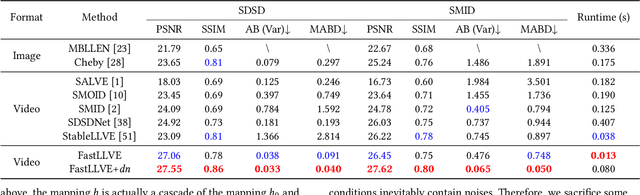
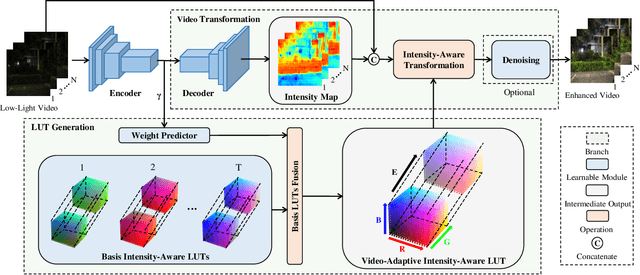

Low-Light Video Enhancement (LLVE) has received considerable attention in recent years. One of the critical requirements of LLVE is inter-frame brightness consistency, which is essential for maintaining the temporal coherence of the enhanced video. However, most existing single-image-based methods fail to address this issue, resulting in flickering effect that degrades the overall quality after enhancement. Moreover, 3D Convolution Neural Network (CNN)-based methods, which are designed for video to maintain inter-frame consistency, are computationally expensive, making them impractical for real-time applications. To address these issues, we propose an efficient pipeline named FastLLVE that leverages the Look-Up-Table (LUT) technique to maintain inter-frame brightness consistency effectively. Specifically, we design a learnable Intensity-Aware LUT (IA-LUT) module for adaptive enhancement, which addresses the low-dynamic problem in low-light scenarios. This enables FastLLVE to perform low-latency and low-complexity enhancement operations while maintaining high-quality results. Experimental results on benchmark datasets demonstrate that our method achieves the State-Of-The-Art (SOTA) performance in terms of both image quality and inter-frame brightness consistency. More importantly, our FastLLVE can process 1,080p videos at $\mathit{50+}$ Frames Per Second (FPS), which is $\mathit{2 \times}$ faster than SOTA CNN-based methods in inference time, making it a promising solution for real-time applications. The code is available at https://github.com/Wenhao-Li-777/FastLLVE.
GraphControl: Adding Conditional Control to Universal Graph Pre-trained Models for Graph Domain Transfer Learning
Oct 12, 2023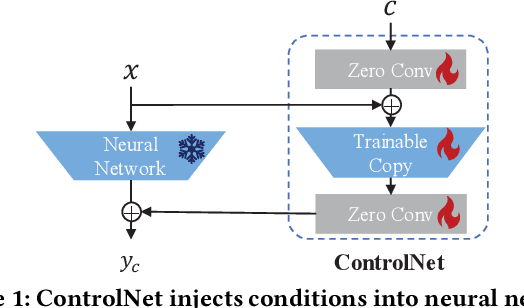
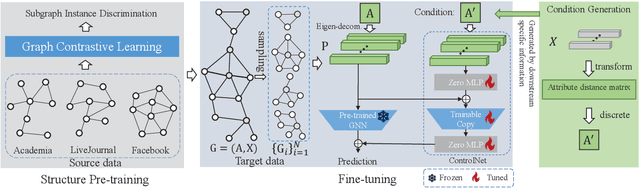
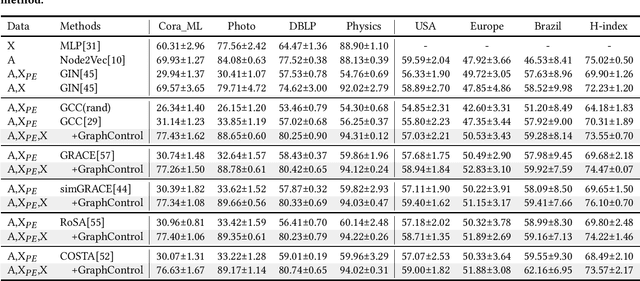
Graph-structured data is ubiquitous in the world which models complex relationships between objects, enabling various Web applications. Daily influxes of unlabeled graph data on the Web offer immense potential for these applications. Graph self-supervised algorithms have achieved significant success in acquiring generic knowledge from abundant unlabeled graph data. These pre-trained models can be applied to various downstream Web applications, saving training time and improving downstream (target) performance. However, different graphs, even across seemingly similar domains, can differ significantly in terms of attribute semantics, posing difficulties, if not infeasibility, for transferring the pre-trained models to downstream tasks. Concretely speaking, for example, the additional task-specific node information in downstream tasks (specificity) is usually deliberately omitted so that the pre-trained representation (transferability) can be leveraged. The trade-off as such is termed as "transferability-specificity dilemma" in this work. To address this challenge, we introduce an innovative deployment module coined as GraphControl, motivated by ControlNet, to realize better graph domain transfer learning. Specifically, by leveraging universal structural pre-trained models and GraphControl, we align the input space across various graphs and incorporate unique characteristics of target data as conditional inputs. These conditions will be progressively integrated into the model during fine-tuning or prompt tuning through ControlNet, facilitating personalized deployment. Extensive experiments show that our method significantly enhances the adaptability of pre-trained models on target attributed datasets, achieving 1.4-3x performance gain. Furthermore, it outperforms training-from-scratch methods on target data with a comparable margin and exhibits faster convergence.