 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Speaker localization using direct path dominance test based on sound field directivity
Oct 05, 2023
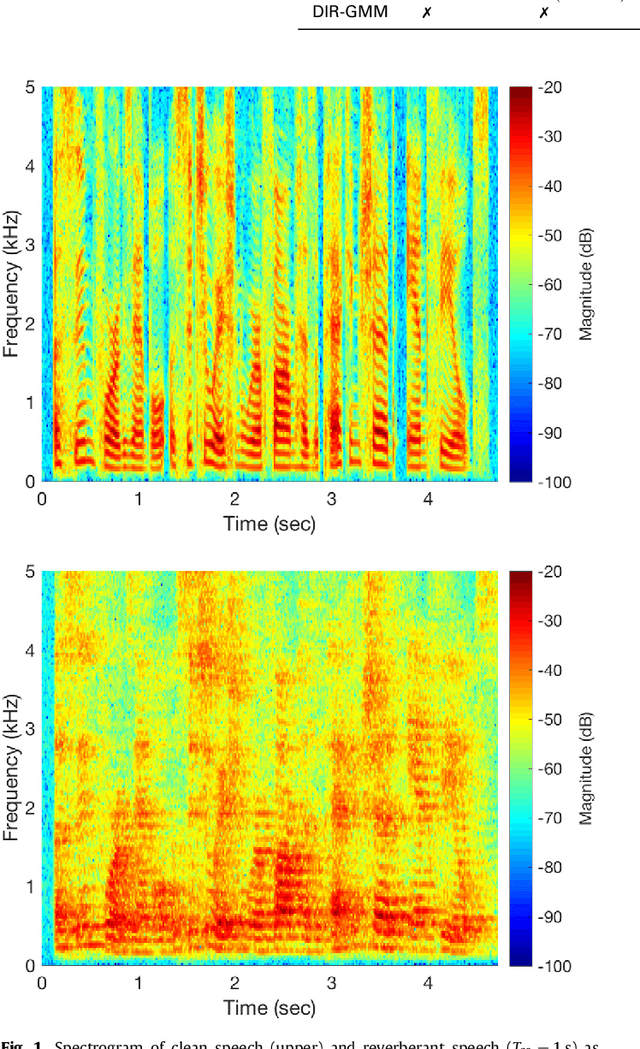
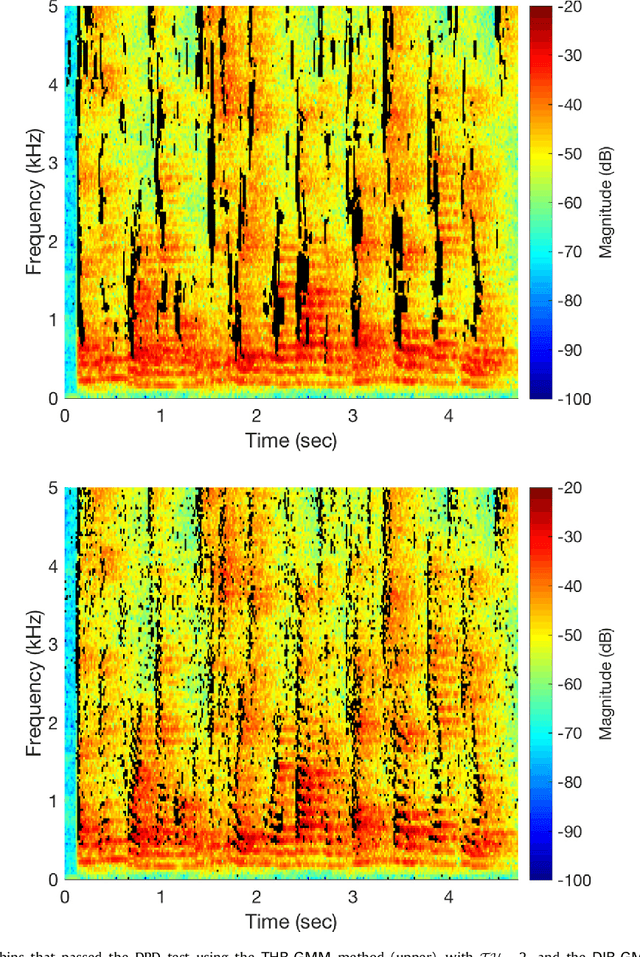

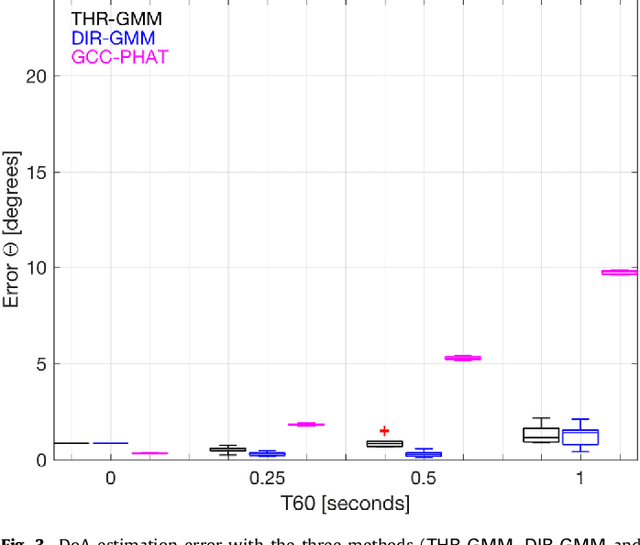
Estimation of the direction-of-arrival (DoA) of a speaker in a room is important in many audio signal processing applications. Environments with reverberation that masks the DoA information are particularly challenging. Recently, a DoA estimation method that is robust to reverberation has been developed. This method identifies time-frequency bins dominated by the contribution from the direct path, which carries the correct DoA information. However, its implementation is computationally demanding as it requires frequency smoothing to overcome the effect of coherent early reflections and matrix decomposition to apply the direct-path dominance (DPD) test. In this work, a novel computationally-efficient alternative to the DPD test is proposed, based on the directivity measure for sensor arrays, which requires neither frequency smoothing nor matrix decomposition, and which has been reformulated for sound field directivity with spherical microphone arrays. The paper presents the proposed method and a comparison to previous methods under a range of reverberation and noise conditions. Result demonstrate that the proposed method shows comparable performance to the original method in terms of robustness to reverberation and noise, and is about four times more computationally efficient for the given experiment.
TWICE Dataset: Digital Twin of Test Scenarios in a Controlled Environment
Oct 05, 2023Ensuring the safe and reliable operation of autonomous vehicles under adverse weather remains a significant challenge. To address this, we have developed a comprehensive dataset composed of sensor data acquired in a real test track and reproduced in the laboratory for the same test scenarios. The provided dataset includes camera, radar, LiDAR, inertial measurement unit (IMU), and GPS data recorded under adverse weather conditions (rainy, night-time, and snowy conditions). We recorded test scenarios using objects of interest such as car, cyclist, truck and pedestrian -- some of which are inspired by EURONCAP (European New Car Assessment Programme). The sensor data generated in the laboratory is acquired by the execution of simulation-based tests in hardware-in-the-loop environment with the digital twin of each real test scenario. The dataset contains more than 2 hours of recording, which totals more than 280GB of data. Therefore, it is a valuable resource for researchers in the field of autonomous vehicles to test and improve their algorithms in adverse weather conditions, as well as explore the simulation-to-reality gap. The dataset is available for download at: https://twicedataset.github.io/site/
LaTeX: Language Pattern-aware Triggering Event Detection for Adverse Experience during Pandemics
Oct 05, 2023The COVID-19 pandemic has accentuated socioeconomic disparities across various racial and ethnic groups in the United States. While previous studies have utilized traditional survey methods like the Household Pulse Survey (HPS) to elucidate these disparities, this paper explores the role of social media platforms in both highlighting and addressing these challenges. Drawing from real-time data sourced from Twitter, we analyzed language patterns related to four major types of adverse experiences: loss of employment income (LI), food scarcity (FS), housing insecurity (HI), and unmet needs for mental health services (UM). We first formulate a sparsity optimization problem that extracts low-level language features from social media data sources. Second, we propose novel constraints on feature similarity exploiting prior knowledge about the similarity of the language patterns among the adverse experiences. The proposed problem is challenging to solve due to the non-convexity objective and non-smoothness penalties. We develop an algorithm based on the alternating direction method of multipliers (ADMM) framework to solve the proposed formulation. Extensive experiments and comparisons to other models on real-world social media and the detection of adverse experiences justify the efficacy of our model.
Leveraging Low-Rank and Sparse Recurrent Connectivity for Robust Closed-Loop Control
Oct 05, 2023Developing autonomous agents that can interact with changing environments is an open challenge in machine learning. Robustness is particularly important in these settings as agents are often fit offline on expert demonstrations but deployed online where they must generalize to the closed feedback loop within the environment. In this work, we explore the application of recurrent neural networks to tasks of this nature and understand how a parameterization of their recurrent connectivity influences robustness in closed-loop settings. Specifically, we represent the recurrent connectivity as a function of rank and sparsity and show both theoretically and empirically that modulating these two variables has desirable effects on network dynamics. The proposed low-rank, sparse connectivity induces an interpretable prior on the network that proves to be most amenable for a class of models known as closed-form continuous-time neural networks (CfCs). We find that CfCs with fewer parameters can outperform their full-rank, fully-connected counterparts in the online setting under distribution shift. This yields memory-efficient and robust agents while opening a new perspective on how we can modulate network dynamics through connectivity.
AI-based automated active learning for discovery of hidden dynamic processes: A use case in light microscopy
Oct 05, 2023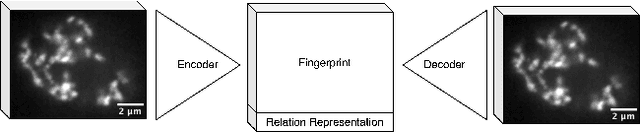
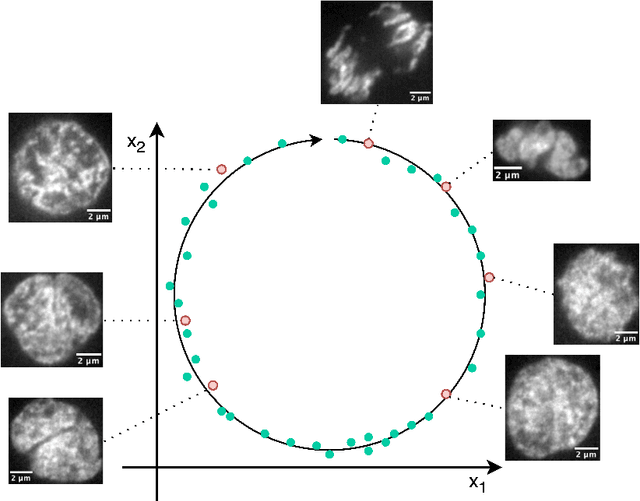
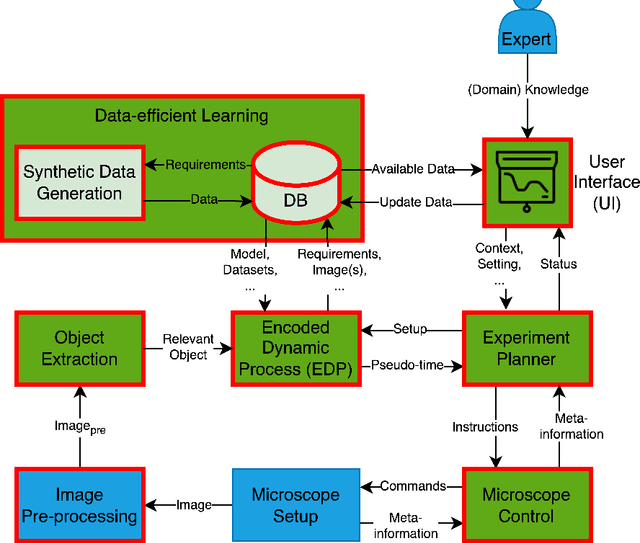
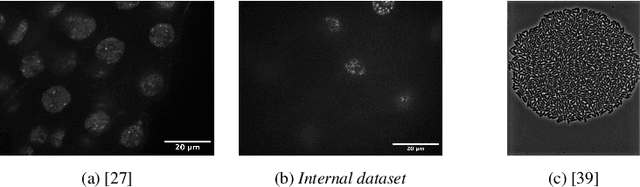
In the biomedical environment, experiments assessing dynamic processes are primarily performed by a human acquisition supervisor. Contemporary implementations of such experiments frequently aim to acquire a maximum number of relevant events from sometimes several hundred parallel, non-synchronous processes. Since in some high-throughput experiments, only one or a few instances of a given process can be observed simultaneously, a strategy for planning and executing an efficient acquisition paradigm is essential. To address this problem, we present two new methods in this paper. The first method, Encoded Dynamic Process (EDP), is Artificial Intelligence (AI)-based and represents dynamic processes so as to allow prediction of pseudo-time values from single still images. Second, with Experiment Automation Pipeline for Dynamic Processes (EAPDP), we present a Machine Learning Operations (MLOps)-based pipeline that uses the extracted knowledge from EDP to efficiently schedule acquisition in biomedical experiments for dynamic processes in practice. In a first experiment, we show that the pre-trained State-Of-The- Art (SOTA) object segmentation method Contour Proposal Networks (CPN) works reliably as a module of EAPDP to extract the relevant object for EDP from the acquired three-dimensional image stack.
Content Bias in Deep Learning Age Approximation: A new Approach Towards more Explainability
Oct 03, 2023


In the context of temporal image forensics, it is not evident that a neural network, trained on images from different time-slots (classes), exploit solely age related features. Usually, images taken in close temporal proximity (e.g., belonging to the same age class) share some common content properties. Such content bias can be exploited by a neural network. In this work, a novel approach that evaluates the influence of image content is proposed. This approach is verified using synthetic images (where content bias can be ruled out) with an age signal embedded. Based on the proposed approach, it is shown that a `standard' neural network trained in the context of age classification is strongly dependent on image content. As a potential countermeasure, two different techniques are applied to mitigate the influence of the image content during training, and they are also evaluated by the proposed method.
Waveform Manipulation Against DNN-based Modulation Classification Attacks
Oct 03, 2023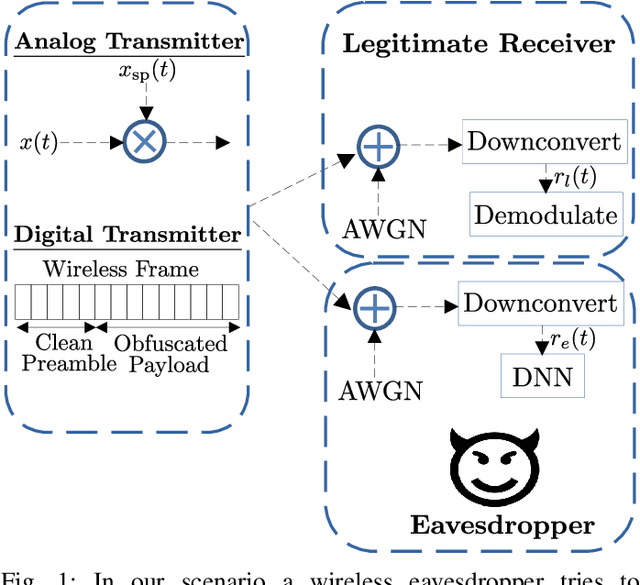
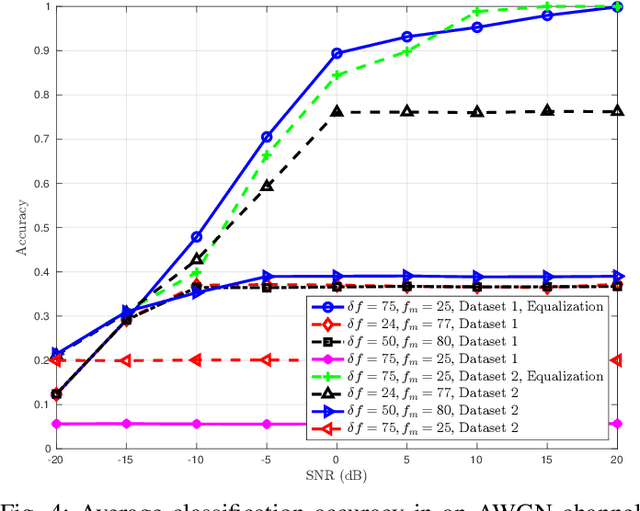
In this paper we propose a method for defending against an eavesdropper that uses a Deep Neural Network (DNN) for learning the modulation of wireless communication signals. Our method is based on manipulating the emitted waveform with the aid of a continuous time frequency-modulated (FM) obfuscating signal that is mixed with the modulated data. The resulting waveform allows a legitimate receiver (LRx) to demodulate the data but it increases the test error of a pre-trained or adversarially-trained DNN classifier at the eavesdropper. The scheme works for analog modulation and digital single carrier and multi carrier orthogonal frequency division multiplexing (OFDM) waveforms, while it can implemented in frame-based wireless protocols. The results indicate that careful selection of the parameters of the obfuscating waveform can drop classification performance at the eavesdropper to less than 10% in AWGN and fading channels with no performance loss at the LRx.
TRAM: Benchmarking Temporal Reasoning for Large Language Models
Oct 03, 2023Reasoning about time is essential for understanding the nuances of events described in natural language. Previous research on this topic has been limited in scope, characterized by a lack of standardized benchmarks that would allow for consistent evaluations across different studies. In this paper, we introduce TRAM, a temporal reasoning benchmark composed of ten datasets, encompassing various temporal aspects of events such as order, arithmetic, frequency, and duration, designed to facilitate a comprehensive evaluation of the temporal reasoning capabilities of large language models (LLMs). We conduct an extensive evaluation using popular LLMs, such as GPT-4 and Llama2, in both zero-shot and few-shot learning scenarios. Additionally, we employ BERT-based models to establish the baseline evaluations. Our findings indicate that these models still trail human performance in temporal reasoning tasks. It is our aspiration that TRAM will spur further progress in enhancing the temporal reasoning abilities of LLMs.
JoMA: Demystifying Multilayer Transformers via JOint Dynamics of MLP and Attention
Oct 03, 2023We propose Joint MLP/Attention (JoMA) dynamics, a novel mathematical framework to understand the training procedure of multilayer Transformer architectures. This is achieved by integrating out the self-attention layer in Transformers, producing a modified dynamics of MLP layers only. JoMA removes unrealistic assumptions in previous analysis (e.g., lack of residual connection) and predicts that the attention first becomes sparse (to learn salient tokens), then dense (to learn less salient tokens) in the presence of nonlinear activations, while in the linear case, it is consistent with existing works that show attention becomes sparse over time. We leverage JoMA to qualitatively explains how tokens are combined to form hierarchies in multilayer Transformers, when the input tokens are generated by a latent hierarchical generative model. Experiments on models trained from real-world dataset (Wikitext2/Wikitext103) and various pre-trained models (OPT, Pythia) verify our theoretical findings.
Network Traffic Classification based on Single Flow Time Series Analysis
Jul 25, 2023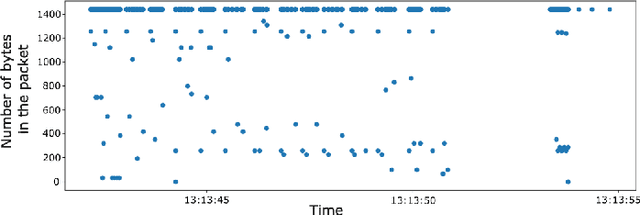
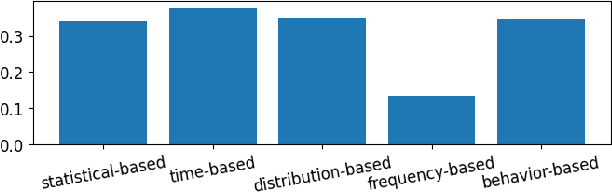
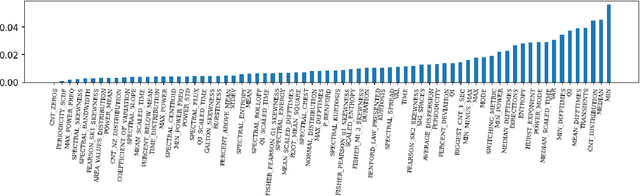

Network traffic monitoring using IP flows is used to handle the current challenge of analyzing encrypted network communication. Nevertheless, the packet aggregation into flow records naturally causes information loss; therefore, this paper proposes a novel flow extension for traffic features based on the time series analysis of the Single Flow Time series, i.e., a time series created by the number of bytes in each packet and its timestamp. We propose 69 universal features based on the statistical analysis of data points, time domain analysis, packet distribution within the flow timespan, time series behavior, and frequency domain analysis. We have demonstrated the usability and universality of the proposed feature vector for various network traffic classification tasks using 15 well-known publicly available datasets. Our evaluation shows that the novel feature vector achieves classification performance similar or better than related works on both binary and multiclass classification tasks. In more than half of the evaluated tasks, the classification performance increased by up to 5\%.