 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepSample: DNN sampling-based testing for operational accuracy assessment
Mar 28, 2024
Deep Neural Networks (DNN) are core components for classification and regression tasks of many software systems. Companies incur in high costs for testing DNN with datasets representative of the inputs expected in operation, as these need to be manually labelled. The challenge is to select a representative set of test inputs as small as possible to reduce the labelling cost, while sufficing to yield unbiased high-confidence estimates of the expected DNN accuracy. At the same time, testers are interested in exposing as many DNN mispredictions as possible to improve the DNN, ending up in the need for techniques pursuing a threefold aim: small dataset size, trustworthy estimates, mispredictions exposure. This study presents DeepSample, a family of DNN testing techniques for cost-effective accuracy assessment based on probabilistic sampling. We investigate whether, to what extent, and under which conditions probabilistic sampling can help to tackle the outlined challenge. We implement five new sampling-based testing techniques, and perform a comprehensive comparison of such techniques and of three further state-of-the-art techniques for both DNN classification and regression tasks. Results serve as guidance for best use of sampling-based testing for faithful and high-confidence estimates of DNN accuracy in operation at low cost.
Inferring Latent Temporal Sparse Coordination Graph for Multi-Agent Reinforcement Learning
Mar 28, 2024Effective agent coordination is crucial in cooperative Multi-Agent Reinforcement Learning (MARL). While agent cooperation can be represented by graph structures, prevailing graph learning methods in MARL are limited. They rely solely on one-step observations, neglecting crucial historical experiences, leading to deficient graphs that foster redundant or detrimental information exchanges. Additionally, high computational demands for action-pair calculations in dense graphs impede scalability. To address these challenges, we propose inferring a Latent Temporal Sparse Coordination Graph (LTS-CG) for MARL. The LTS-CG leverages agents' historical observations to calculate an agent-pair probability matrix, where a sparse graph is sampled from and used for knowledge exchange between agents, thereby simultaneously capturing agent dependencies and relation uncertainty. The computational complexity of this procedure is only related to the number of agents. This graph learning process is further augmented by two innovative characteristics: Predict-Future, which enables agents to foresee upcoming observations, and Infer-Present, ensuring a thorough grasp of the environmental context from limited data. These features allow LTS-CG to construct temporal graphs from historical and real-time information, promoting knowledge exchange during policy learning and effective collaboration. Graph learning and agent training occur simultaneously in an end-to-end manner. Our demonstrated results on the StarCraft II benchmark underscore LTS-CG's superior performance.
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Mar 15, 2024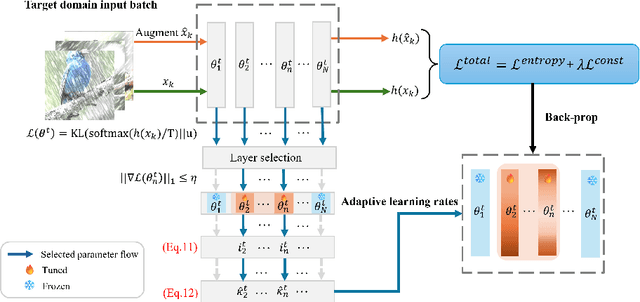
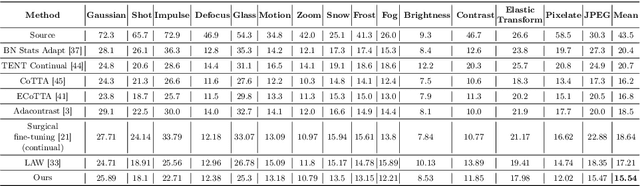
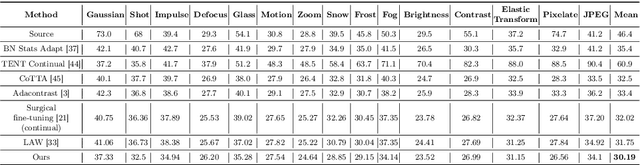
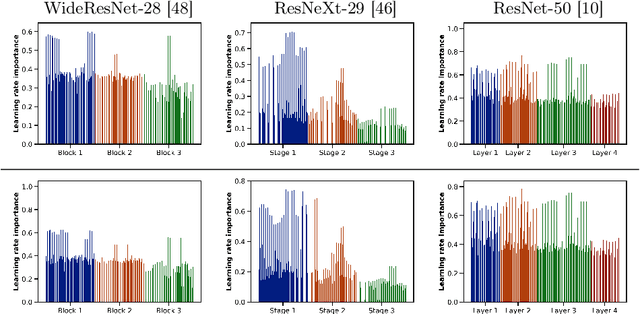
Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains using test data. A highly effective CTTA method involves applying layer-wise adaptive learning rates, and selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. In this work, we aim to overcome these limitations by identifying layers through the quantification of model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity in order to approximate the domain shift, followed by adjusting their learning rates accordingly. Overall, this approach leads to a more robust and stable optimization than prior approaches. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C and demonstrate the efficacy of our method against standard benchmarks and prior methods.
Automating Catheterization Labs with Real-Time Perception
Mar 09, 2024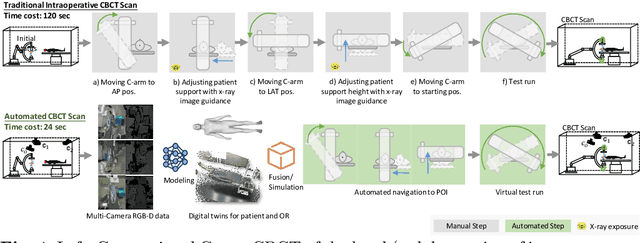
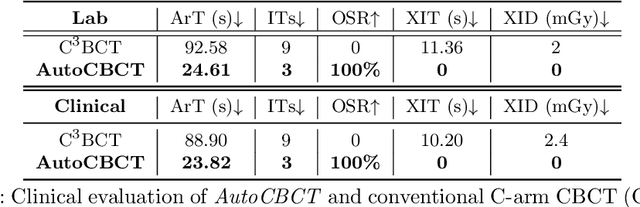
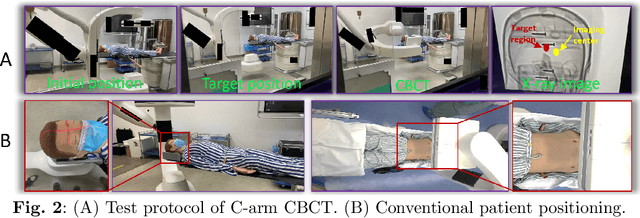
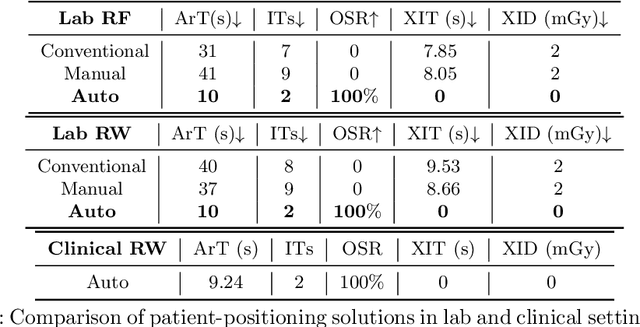
For decades, three-dimensional C-arm Cone-Beam Computed Tomography (CBCT) imaging system has been a critical component for complex vascular and nonvascular interventional procedures. While it can significantly improve multiplanar soft tissue imaging and provide pre-treatment target lesion roadmapping and guidance, the traditional workflow can be cumbersome and time-consuming, especially for less experienced users. To streamline this process and enhance procedural efficiency overall, we proposed a visual perception system, namely AutoCBCT, seamlessly integrated with an angiography suite. This system dynamically models both the patient's body and the surgical environment in real-time. AutoCBCT enables a novel workflow with automated positioning, navigation and simulated test-runs, eliminating the need for manual operations and interactions. The proposed system has been successfully deployed and studied in both lab and clinical settings, demonstrating significantly improved workflow efficiency.
Overcoming Distribution Shifts in Plug-and-Play Methods with Test-Time Training
Mar 15, 2024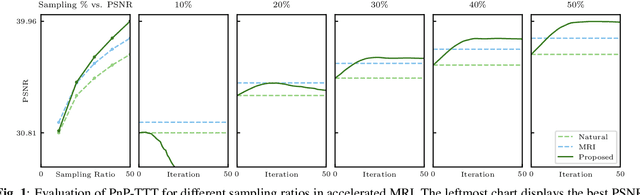
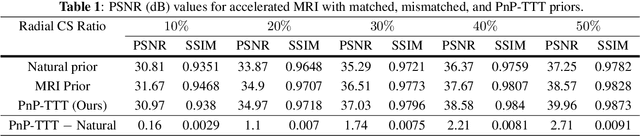
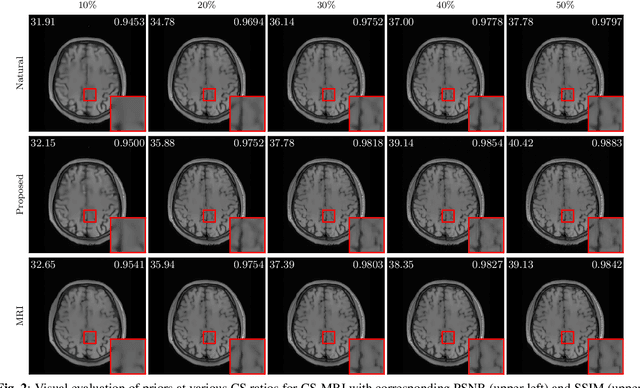
Plug-and-Play Priors (PnP) is a well-known class of methods for solving inverse problems in computational imaging. PnP methods combine physical forward models with learned prior models specified as image denoisers. A common issue with the learned models is that of a performance drop when there is a distribution shift between the training and testing data. Test-time training (TTT) was recently proposed as a general strategy for improving the performance of learned models when training and testing data come from different distributions. In this paper, we propose PnP-TTT as a new method for overcoming distribution shifts in PnP. PnP-TTT uses deep equilibrium learning (DEQ) for optimizing a self-supervised loss at the fixed points of PnP iterations. PnP-TTT can be directly applied on a single test sample to improve the generalization of PnP. We show through simulations that given a sufficient number of measurements, PnP-TTT enables the use of image priors trained on natural images for image reconstruction in magnetic resonance imaging (MRI).
ChroniclingAmericaQA: A Large-scale Question Answering Dataset based on Historical American Newspaper Pages
Mar 26, 2024Question answering (QA) and Machine Reading Comprehension (MRC) tasks have significantly advanced in recent years due to the rapid development of deep learning techniques and, more recently, large language models. At the same time, many benchmark datasets have become available for QA and MRC tasks. However, most existing large-scale benchmark datasets have been created predominantly using synchronous document collections like Wikipedia or the Web. Archival document collections, such as historical newspapers, contain valuable information from the past that is still not widely used to train large language models. To further contribute to advancing QA and MRC tasks and to overcome the limitation of previous datasets, we introduce ChroniclingAmericaQA, a large-scale dataset with 485K question-answer pairs created based on the historical newspaper collection Chronicling America. Our dataset is constructed from a subset of the Chronicling America newspaper collection spanning 120 years. One of the significant challenges for utilizing digitized historical newspaper collections is the low quality of OCR text. Therefore, to enable realistic testing of QA models, our dataset can be used in three different ways: answering questions from raw and noisy content, answering questions from cleaner, corrected version of the content, as well as answering questions from scanned images of newspaper pages. This and the fact that ChroniclingAmericaQA spans the longest time period among available QA datasets make it quite a unique and useful resource.
Prediction-sharing During Training and Inference
Mar 26, 2024Two firms are engaged in a competitive prediction task. Each firm has two sources of data -- labeled historical data and unlabeled inference-time data -- and uses the former to derive a prediction model, and the latter to make predictions on new instances. We study data-sharing contracts between the firms. The novelty of our study is to introduce and highlight the differences between contracts that share prediction models only, contracts to share inference-time predictions only, and contracts to share both. Our analysis proceeds on three levels. First, we develop a general Bayesian framework that facilitates our study. Second, we narrow our focus to two natural settings within this framework: (i) a setting in which the accuracy of each firm's prediction model is common knowledge, but the correlation between the respective models is unknown; and (ii) a setting in which two hypotheses exist regarding the optimal predictor, and one of the firms has a structural advantage in deducing it. Within these two settings we study optimal contract choice. More specifically, we find the individually rational and Pareto-optimal contracts for some notable cases, and describe specific settings where each of the different sharing contracts emerge as optimal. Finally, in the third level of our analysis we demonstrate the applicability of our concepts in a synthetic simulation using real loan data.
The Effects of Short Video-Sharing Services on Video Copy Detection
Mar 26, 2024The short video-sharing services that allow users to post 10-30 second videos (e.g., YouTube Shorts and TikTok) have attracted a lot of attention in recent years. However, conventional video copy detection (VCD) methods mainly focus on general video-sharing services (e.g., YouTube and Bilibili), and the effects of short video-sharing services on video copy detection are still unclear. Considering that illegally copied videos in short video-sharing services have service-distinctive characteristics, especially in those time lengths, the pros and cons of VCD in those services are required to be analyzed. In this paper, we examine the effects of short video-sharing services on VCD by constructing a dataset that has short video-sharing service characteristics. Our novel dataset is automatically constructed from the publicly available dataset to have reference videos and fixed short-time-length query videos, and such automation procedures assure the reproducibility and data privacy preservation of this paper. From the experimental results focusing on segment-level and video-level situations, we can see that three effects: "Segment-level VCD in short video-sharing services is more difficult than those in general video-sharing services", "Video-level VCD in short video-sharing services is easier than those in general video-sharing services", "The video alignment component mainly suppress the detection performance in short video-sharing services".
SAT-NGP : Unleashing Neural Graphics Primitives for Fast Relightable Transient-Free 3D reconstruction from Satellite Imagery
Mar 27, 2024Current stereo-vision pipelines produce high accuracy 3D reconstruction when using multiple pairs or triplets of satellite images. However, these pipelines are sensitive to the changes between images that can occur as a result of multi-date acquisitions. Such variations are mainly due to variable shadows, reflexions and transient objects (cars, vegetation). To take such changes into account, Neural Radiance Fields (NeRF) have recently been applied to multi-date satellite imagery. However, Neural methods are very compute-intensive, taking dozens of hours to learn, compared with minutes for standard stereo-vision pipelines. Following the ideas of Instant Neural Graphics Primitives we propose to use an efficient sampling strategy and multi-resolution hash encoding to accelerate the learning. Our model, Satellite Neural Graphics Primitives (SAT-NGP) decreases the learning time to 15 minutes while maintaining the quality of the 3D reconstruction.
Towards Understanding Dual BN In Hybrid Adversarial Training
Mar 28, 2024There is a growing concern about applying batch normalization (BN) in adversarial training (AT), especially when the model is trained on both adversarial samples and clean samples (termed Hybrid-AT). With the assumption that adversarial and clean samples are from two different domains, a common practice in prior works is to adopt Dual BN, where BN and BN are used for adversarial and clean branches, respectively. A popular belief for motivating Dual BN is that estimating normalization statistics of this mixture distribution is challenging and thus disentangling it for normalization achieves stronger robustness. In contrast to this belief, we reveal that disentangling statistics plays a less role than disentangling affine parameters in model training. This finding aligns with prior work (Rebuffi et al., 2023), and we build upon their research for further investigations. We demonstrate that the domain gap between adversarial and clean samples is not very large, which is counter-intuitive considering the significant influence of adversarial perturbation on the model accuracy. We further propose a two-task hypothesis which serves as the empirical foundation and a unified framework for Hybrid-AT improvement. We also investigate Dual BN in test-time and reveal that affine parameters characterize the robustness during inference. Overall, our work sheds new light on understanding the mechanism of Dual BN in Hybrid-AT and its underlying justification.