 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Persis: A Persian Font Recognition Pipeline Using Convolutional Neural Networks
Oct 10, 2023



What happens if we encounter a suitable font for our design work but do not know its name? Visual Font Recognition (VFR) systems are used to identify the font typeface in an image. These systems can assist graphic designers in identifying fonts used in images. A VFR system also aids in improving the speed and accuracy of Optical Character Recognition (OCR) systems. In this paper, we introduce the first publicly available datasets in the field of Persian font recognition and employ Convolutional Neural Networks (CNN) to address this problem. The results show that the proposed pipeline obtained 78.0% top-1 accuracy on our new datasets, 89.1% on the IDPL-PFOD dataset, and 94.5% on the KAFD dataset. Furthermore, the average time spent in the entire pipeline for one sample of our proposed datasets is 0.54 and 0.017 seconds for CPU and GPU, respectively. We conclude that CNN methods can be used to recognize Persian fonts without the need for additional pre-processing steps such as feature extraction, binarization, normalization, etc.
A Variational Autoencoder Framework for Robust, Physics-Informed Cyberattack Recognition in Industrial Cyber-Physical Systems
Oct 10, 2023Cybersecurity of Industrial Cyber-Physical Systems is drawing significant concerns as data communication increasingly leverages wireless networks. A lot of data-driven methods were develope for detecting cyberattacks, but few are focused on distinguishing them from equipment faults. In this paper, we develop a data-driven framework that can be used to detect, diagnose, and localize a type of cyberattack called covert attacks on networked industrial control systems. The framework has a hybrid design that combines a variational autoencoder (VAE), a recurrent neural network (RNN), and a Deep Neural Network (DNN). This data-driven framework considers the temporal behavior of a generic physical system that extracts features from the time series of the sensor measurements that can be used for detecting covert attacks, distinguishing them from equipment faults, as well as localize the attack/fault. We evaluate the performance of the proposed method through a realistic simulation study on a networked power transmission system as a typical example of ICS. We compare the performance of the proposed method with the traditional model-based method to show its applicability and efficacy.
FPGA Resource-aware Structured Pruning for Real-Time Neural Networks
Aug 09, 2023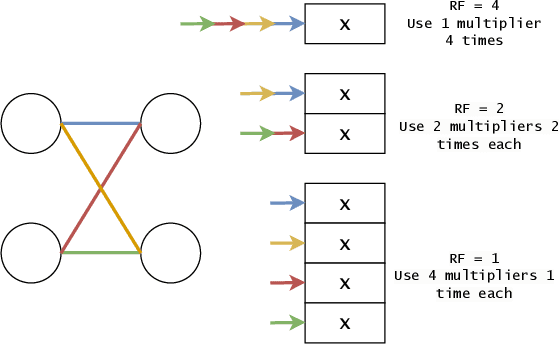
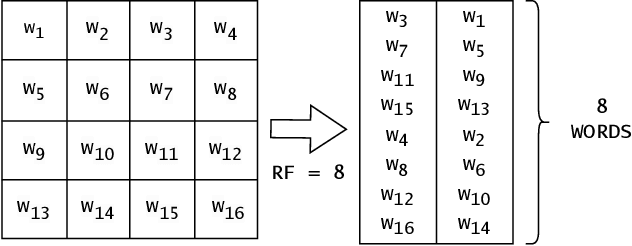
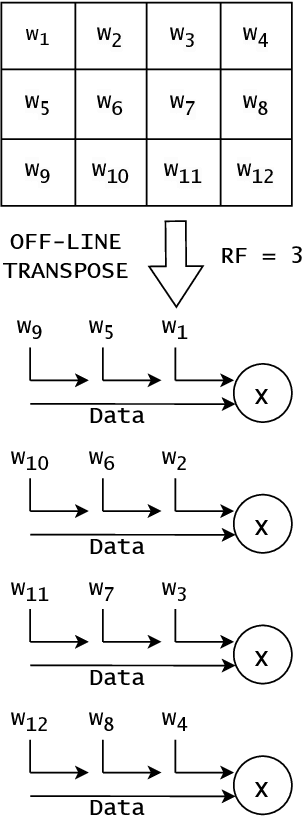
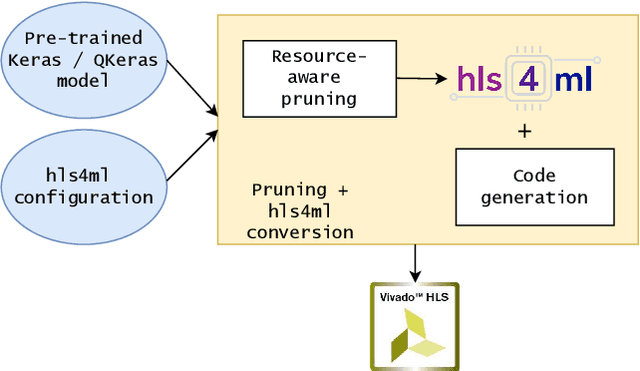
Neural networks achieve state-of-the-art performance in image classification, speech recognition, scientific analysis and many more application areas. With the ever-increasing need for faster computation and lower power consumption, driven by real-time systems and Internet-of-Things (IoT) devices, FPGAs have emerged as suitable devices for deep learning inference. Due to the high computational complexity and memory footprint of neural networks, various compression techniques, such as pruning, quantization and knowledge distillation, have been proposed in literature. Pruning sparsifies a neural network, reducing the number of multiplications and memory. However, pruning often fails to capture properties of the underlying hardware, causing unstructured sparsity and load-balance inefficiency, thus bottlenecking resource improvements. We propose a hardware-centric formulation of pruning, by formulating it as a knapsack problem with resource-aware tensor structures. The primary emphasis is on real-time inference, with latencies in the order of 1$\mu$s, accelerated with hls4ml, an open-source framework for deep learning inference on FPGAs. Evaluated on a range of tasks, including real-time particle classification at CERN's Large Hadron Collider and fast image classification, the proposed method achieves a reduction ranging between 55% and 92% in the utilization of digital signal processing blocks (DSP) and up to 81% in block memory (BRAM) utilization.
PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre-training Paradigm
Oct 13, 2023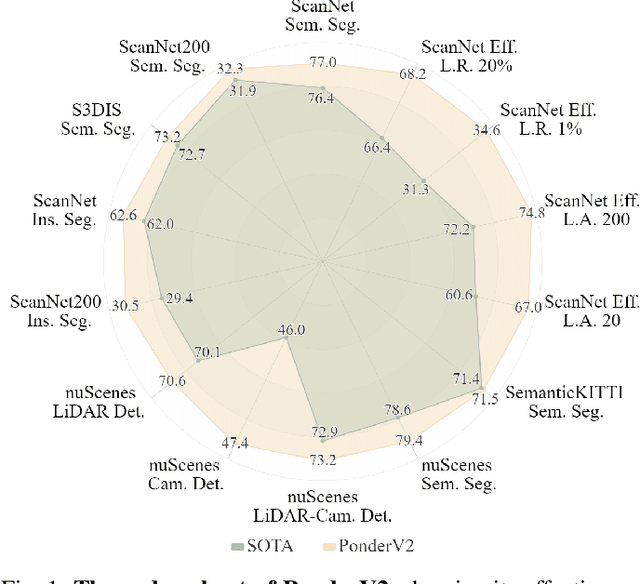
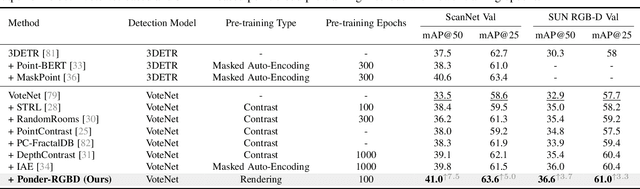
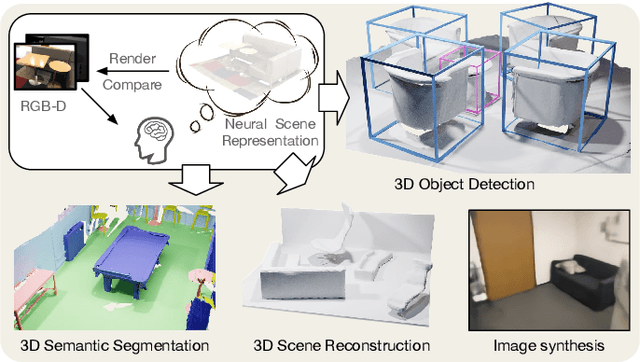

In contrast to numerous NLP and 2D computer vision foundational models, the learning of a robust and highly generalized 3D foundational model poses considerably greater challenges. This is primarily due to the inherent data variability and the diversity of downstream tasks. In this paper, we introduce a comprehensive 3D pre-training framework designed to facilitate the acquisition of efficient 3D representations, thereby establishing a pathway to 3D foundational models. Motivated by the fact that informative 3D features should be able to encode rich geometry and appearance cues that can be utilized to render realistic images, we propose a novel universal paradigm to learn point cloud representations by differentiable neural rendering, serving as a bridge between 3D and 2D worlds. We train a point cloud encoder within a devised volumetric neural renderer by comparing the rendered images with the real images. Notably, our approach demonstrates the seamless integration of the learned 3D encoder into diverse downstream tasks. These tasks encompass not only high-level challenges such as 3D detection and segmentation but also low-level objectives like 3D reconstruction and image synthesis, spanning both indoor and outdoor scenarios. Besides, we also illustrate the capability of pre-training a 2D backbone using the proposed universal methodology, surpassing conventional pre-training methods by a large margin. For the first time, PonderV2 achieves state-of-the-art performance on 11 indoor and outdoor benchmarks. The consistent improvements in various settings imply the effectiveness of the proposed method. Code and models will be made available at https://github.com/OpenGVLab/PonderV2.
Multi-Robot Geometric Task-and-Motion Planning for Collaborative Manipulation Tasks
Oct 13, 2023We address multi-robot geometric task-and-motion planning (MR-GTAMP) problems in synchronous, monotone setups. The goal of the MR-GTAMP problem is to move objects with multiple robots to goal regions in the presence of other movable objects. We focus on collaborative manipulation tasks where the robots have to adopt intelligent collaboration strategies to be successful and effective, i.e., decide which robot should move which objects to which positions, and perform collaborative actions, such as handovers. To endow robots with these collaboration capabilities, we propose to first collect occlusion and reachability information for each robot by calling motion-planning algorithms. We then propose a method that uses the collected information to build a graph structure which captures the precedence of the manipulations of different objects and supports the implementation of a mixed-integer program to guide the search for highly effective collaborative task-and-motion plans. The search process for collaborative task-and-motion plans is based on a Monte-Carlo Tree Search (MCTS) exploration strategy to achieve exploration-exploitation balance. We evaluate our framework in two challenging MR-GTAMP domains and show that it outperforms two state-of-the-art baselines with respect to the planning time, the resulting plan length and the number of objects moved. We also show that our framework can be applied to underground mining operations where a robotic arm needs to coordinate with an autonomous roof bolter. We demonstrate plan execution in two roof-bolting scenarios both in simulation and on robots.
Multi-Dimension-Embedding-Aware Modality Fusion Transformer for Psychiatric Disorder Clasification
Oct 04, 2023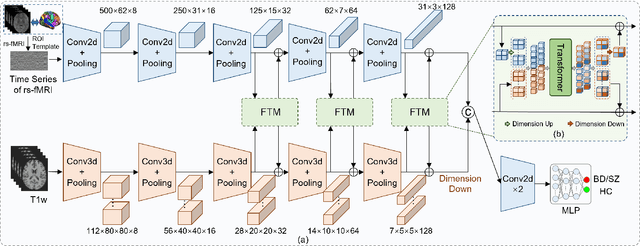
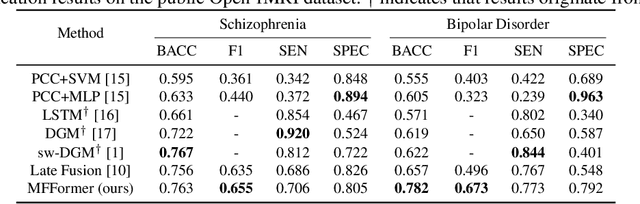
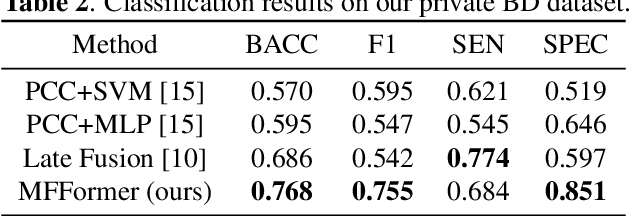
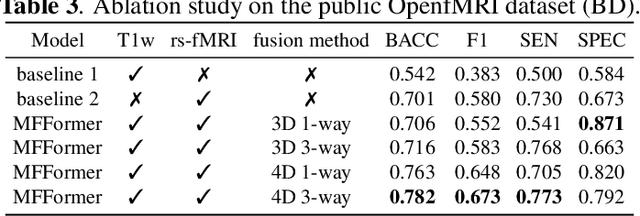
Deep learning approaches, together with neuroimaging techniques, play an important role in psychiatric disorders classification. Previous studies on psychiatric disorders diagnosis mainly focus on using functional connectivity matrices of resting-state functional magnetic resonance imaging (rs-fMRI) as input, which still needs to fully utilize the rich temporal information of the time series of rs-fMRI data. In this work, we proposed a multi-dimension-embedding-aware modality fusion transformer (MFFormer) for schizophrenia and bipolar disorder classification using rs-fMRI and T1 weighted structural MRI (T1w sMRI). Concretely, to fully utilize the temporal information of rs-fMRI and spatial information of sMRI, we constructed a deep learning architecture that takes as input 2D time series of rs-fMRI and 3D volumes T1w. Furthermore, to promote intra-modality attention and information fusion across different modalities, a fusion transformer module (FTM) is designed through extensive self-attention of hybrid feature maps of multi-modality. In addition, a dimension-up and dimension-down strategy is suggested to properly align feature maps of multi-dimensional from different modalities. Experimental results on our private and public OpenfMRI datasets show that our proposed MFFormer performs better than that using a single modality or multi-modality MRI on schizophrenia and bipolar disorder diagnosis.
Faithful Explanations of Black-box NLP Models Using LLM-generated Counterfactuals
Oct 01, 2023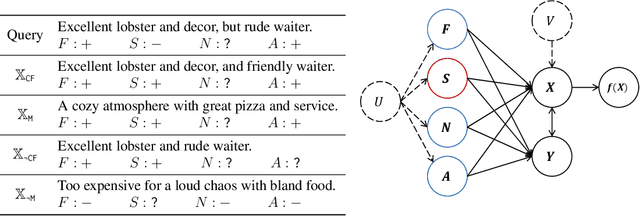
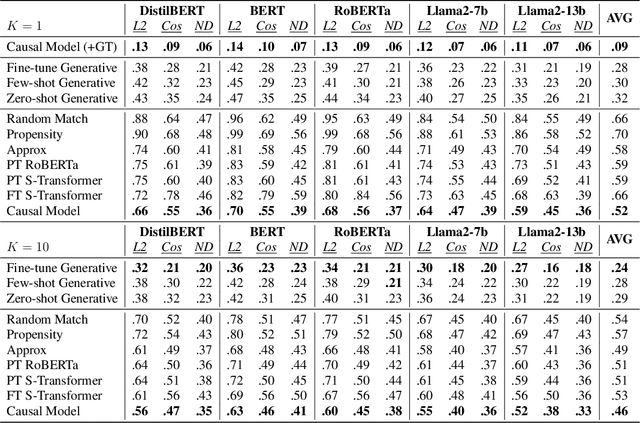
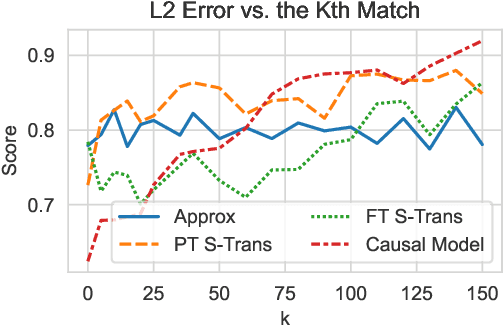
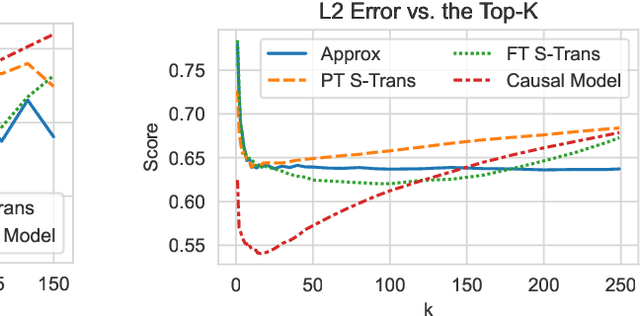
Causal explanations of the predictions of NLP systems are essential to ensure safety and establish trust. Yet, existing methods often fall short of explaining model predictions effectively or efficiently and are often model-specific. In this paper, we address model-agnostic explanations, proposing two approaches for counterfactual (CF) approximation. The first approach is CF generation, where a large language model (LLM) is prompted to change a specific text concept while keeping confounding concepts unchanged. While this approach is demonstrated to be very effective, applying LLM at inference-time is costly. We hence present a second approach based on matching, and propose a method that is guided by an LLM at training-time and learns a dedicated embedding space. This space is faithful to a given causal graph and effectively serves to identify matches that approximate CFs. After showing theoretically that approximating CFs is required in order to construct faithful explanations, we benchmark our approaches and explain several models, including LLMs with billions of parameters. Our empirical results demonstrate the excellent performance of CF generation models as model-agnostic explainers. Moreover, our matching approach, which requires far less test-time resources, also provides effective explanations, surpassing many baselines. We also find that Top-K techniques universally improve every tested method. Finally, we showcase the potential of LLMs in constructing new benchmarks for model explanation and subsequently validate our conclusions. Our work illuminates new pathways for efficient and accurate approaches to interpreting NLP systems.
Propagating Semantic Labels in Video Data
Oct 01, 2023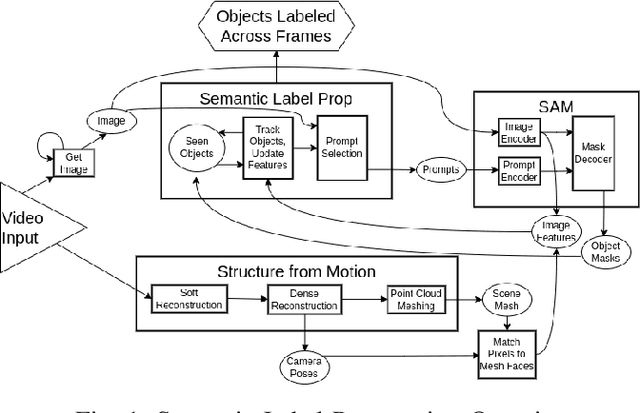


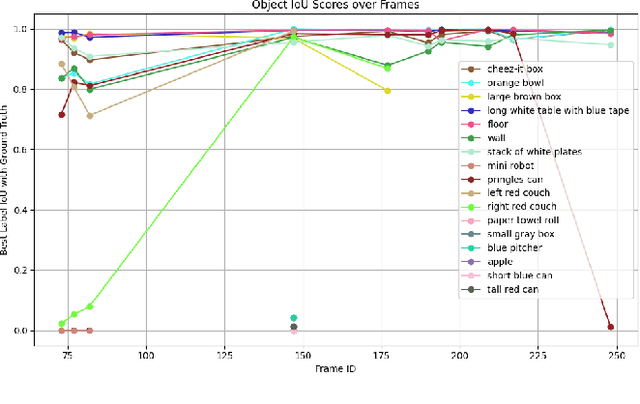
Semantic Segmentation combines two sub-tasks: the identification of pixel-level image masks and the application of semantic labels to those masks. Recently, so-called Foundation Models have been introduced; general models trained on very large datasets which can be specialized and applied to more specific tasks. One such model, the Segment Anything Model (SAM), performs image segmentation. Semantic segmentation systems such as CLIPSeg and MaskRCNN are trained on datasets of paired segments and semantic labels. Manual labeling of custom data, however, is time-consuming. This work presents a method for performing segmentation for objects in video. Once an object has been found in a frame of video, the segment can then be propagated to future frames; thus reducing manual annotation effort. The method works by combining SAM with Structure from Motion (SfM). The video input to the system is first reconstructed into 3D geometry using SfM. A frame of video is then segmented using SAM. Segments identified by SAM are then projected onto the the reconstructed 3D geometry. In subsequent video frames, the labeled 3D geometry is reprojected into the new perspective, allowing SAM to be invoked fewer times. System performance is evaluated, including the contributions of the SAM and SfM components. Performance is evaluated over three main metrics: computation time, mask IOU with manual labels, and the number of tracking losses. Results demonstrate that the system has substantial computation time improvements over human performance for tracking objects over video frames, but suffers in performance.
A Marketplace Price Anomaly Detection System at Scale
Oct 09, 2023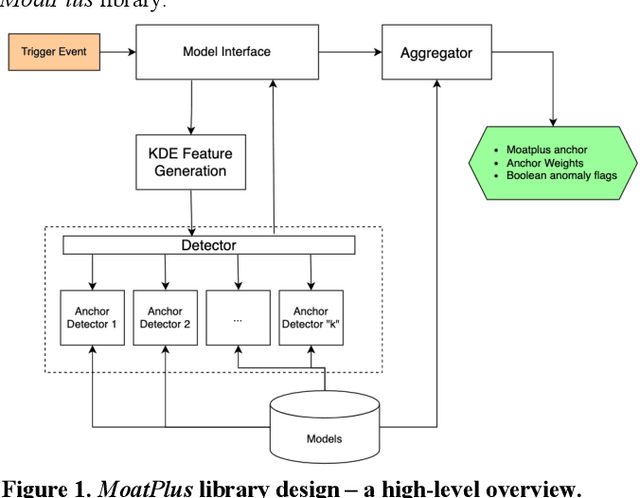
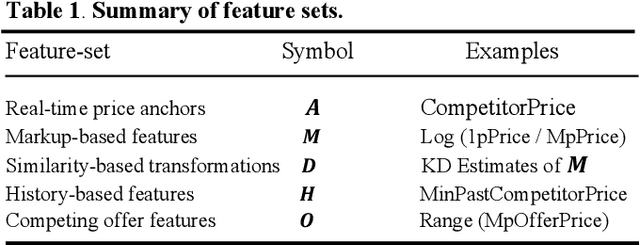
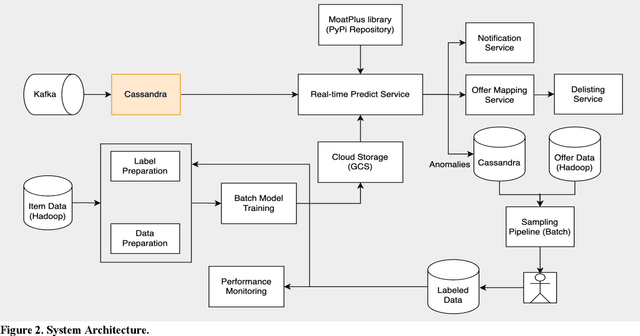
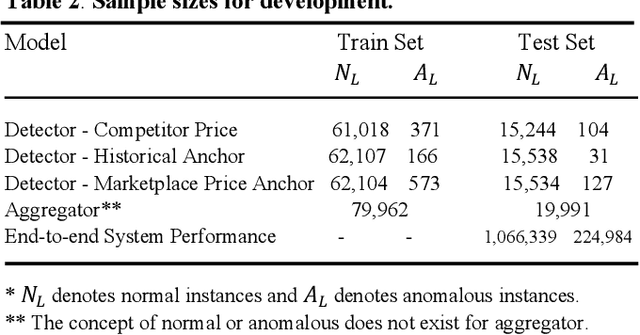
Online marketplaces execute large volume of price updates that are initiated by individual marketplace sellers each day on the platform. This price democratization comes with increasing challenges with data quality. Lack of centralized guardrails that are available for a traditional online retailer causes a higher likelihood for inaccurate prices to get published on the website, leading to poor customer experience and potential for revenue loss. We present MoatPlus (Masked Optimal Anchors using Trees, Proximity-based Labeling and Unsupervised Statistical-features), a scalable price anomaly detection framework for a growing marketplace platform. The goal is to leverage proximity and historical price trends from unsupervised statistical features to generate an upper price bound. We build an ensemble of models to detect irregularities in price-based features, exclude irregular features and use optimized weighting scheme to build a reliable price bound in real-time pricing pipeline. We observed that our approach improves precise anchor coverage by up to 46.6% in high-vulnerability item subsets
Humanoid Agents: Platform for Simulating Human-like Generative Agents
Oct 09, 2023Just as computational simulations of atoms, molecules and cells have shaped the way we study the sciences, true-to-life simulations of human-like agents can be valuable tools for studying human behavior. We propose Humanoid Agents, a system that guides Generative Agents to behave more like humans by introducing three elements of System 1 processing: Basic needs (e.g. hunger, health and energy), Emotion and Closeness in Relationships. Humanoid Agents are able to use these dynamic elements to adapt their daily activities and conversations with other agents, as supported with empirical experiments. Our system is designed to be extensible to various settings, three of which we demonstrate, as well as to other elements influencing human behavior (e.g. empathy, moral values and cultural background). Our platform also includes a Unity WebGL game interface for visualization and an interactive analytics dashboard to show agent statuses over time. Our platform is available on https://www.humanoidagents.com/ and code is on https://github.com/HumanoidAgents/HumanoidAgents