 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Baird Counterexample is Solved: with an example of How to Debug a Two-time-scale Algorithm
Sep 02, 2023
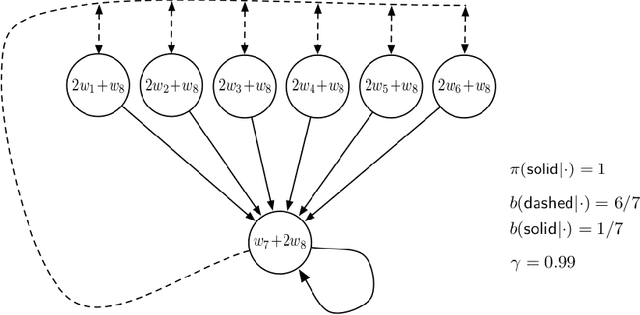
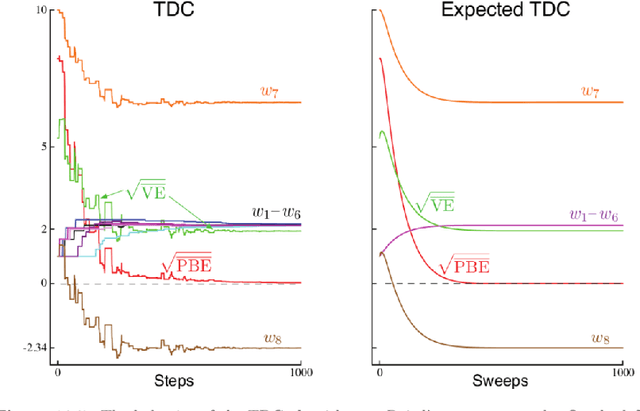
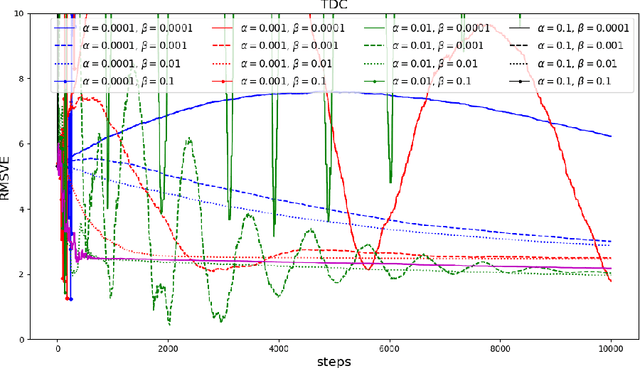
Baird counterexample was proposed by Leemon Baird in 1995, first used to show that the Temporal Difference (TD(0)) algorithm diverges on this example. Since then, it is often used to test and compare off-policy learning algorithms. Gradient TD algorithms solved the divergence issue of TD on Baird counterexample. However, their convergence on this example is still very slow, and the nature of the slowness is not well understood, e.g., see (Sutton and Barto 2018). This note is to understand in particular, why TDC is slow on this example, and provide a debugging analysis to understand this behavior. Our debugging technique can be used to study the convergence behavior of two-time-scale stochastic approximation algorithms. We also provide empirical results of the recent Impression GTD algorithm on this example, showing the convergence is very fast, in fact, in a linear rate. We conclude that Baird counterexample is solved, by an algorithm with the convergence guarantee to the TD solution in general, and a fast convergence rate.
ConvNeXtv2 Fusion with Mask R-CNN for Automatic Region Based Coronary Artery Stenosis Detection for Disease Diagnosis
Oct 07, 2023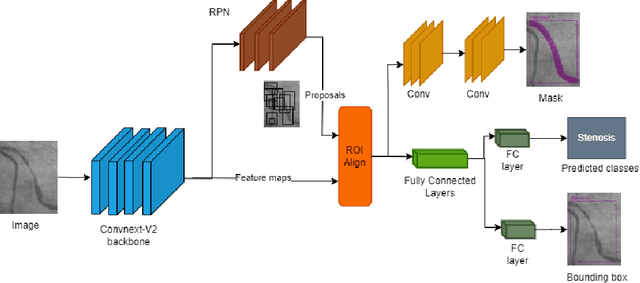

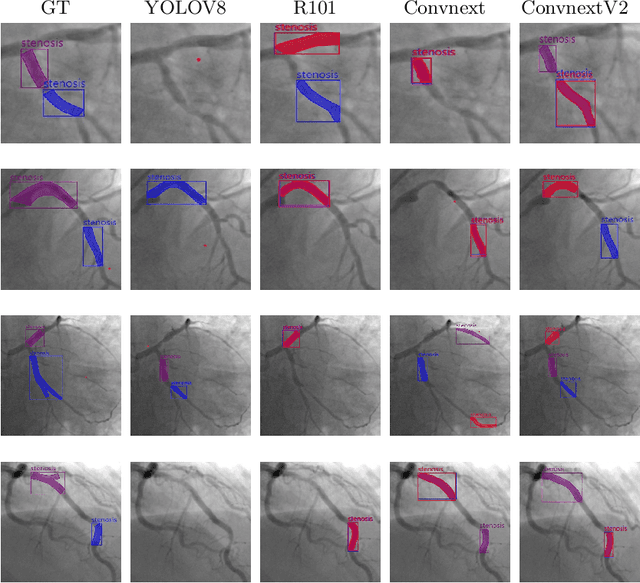

Coronary Artery Diseases although preventable are one of the leading cause of mortality worldwide. Due to the onerous nature of diagnosis, tackling CADs has proved challenging. This study addresses the automation of resource-intensive and time-consuming process of manually detecting stenotic lesions in coronary arteries in X-ray coronary angiography images. To overcome this challenge, we employ a specialized Convnext-V2 backbone based Mask RCNN model pre-trained for instance segmentation tasks. Our empirical findings affirm that the proposed model exhibits commendable performance in identifying stenotic lesions. Notably, our approach achieves a substantial F1 score of 0.5353 in this demanding task, underscoring its effectiveness in streamlining this intensive process.
Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Oct 13, 2023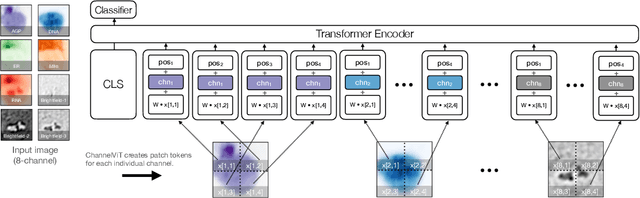
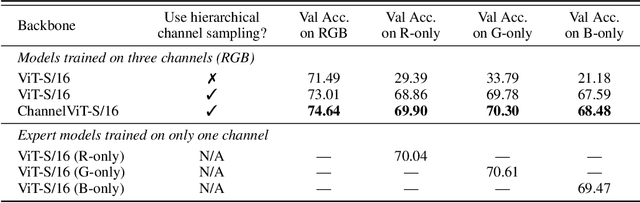
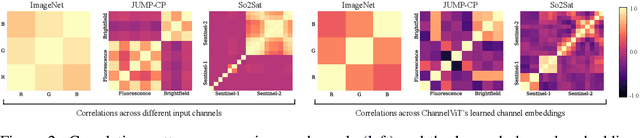
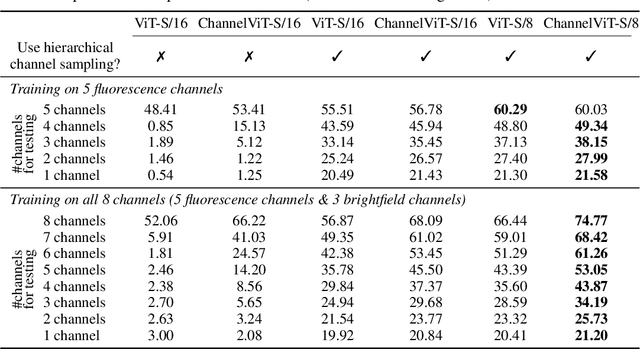
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems
Oct 13, 2023
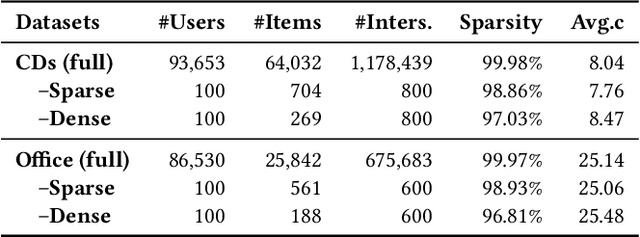
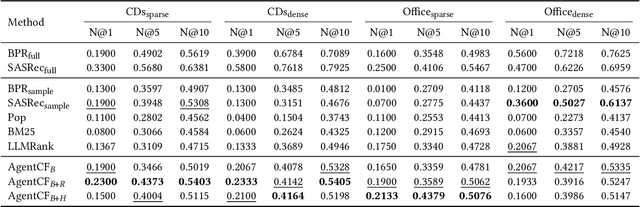

Recently, there has been an emergence of employing LLM-powered agents as believable human proxies, based on their remarkable decision-making capability. However, existing studies mainly focus on simulating human dialogue. Human non-verbal behaviors, such as item clicking in recommender systems, although implicitly exhibiting user preferences and could enhance the modeling of users, have not been deeply explored. The main reasons lie in the gap between language modeling and behavior modeling, as well as the incomprehension of LLMs about user-item relations. To address this issue, we propose AgentCF for simulating user-item interactions in recommender systems through agent-based collaborative filtering. We creatively consider not only users but also items as agents, and develop a collaborative learning approach that optimizes both kinds of agents together. Specifically, at each time step, we first prompt the user and item agents to interact autonomously. Then, based on the disparities between the agents' decisions and real-world interaction records, user and item agents are prompted to reflect on and adjust the misleading simulations collaboratively, thereby modeling their two-sided relations. The optimized agents can also propagate their preferences to other agents in subsequent interactions, implicitly capturing the collaborative filtering idea. Overall, the optimized agents exhibit diverse interaction behaviors within our framework, including user-item, user-user, item-item, and collective interactions. The results show that these agents can demonstrate personalized behaviors akin to those of real-world individuals, sparking the development of next-generation user behavior simulation.
Leveraging Optimal Transport for Enhanced Offline Reinforcement Learning in Surgical Robotic Environments
Oct 13, 2023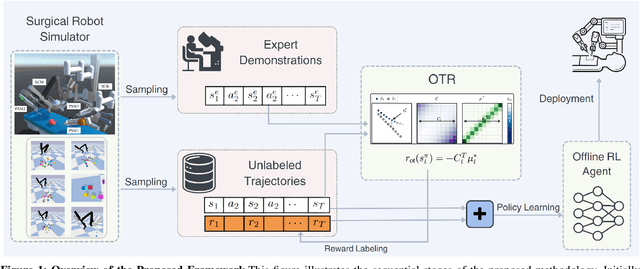


Most Reinforcement Learning (RL) methods are traditionally studied in an active learning setting, where agents directly interact with their environments, observe action outcomes, and learn through trial and error. However, allowing partially trained agents to interact with real physical systems poses significant challenges, including high costs, safety risks, and the need for constant supervision. Offline RL addresses these cost and safety concerns by leveraging existing datasets and reducing the need for resource-intensive real-time interactions. Nevertheless, a substantial challenge lies in the demand for these datasets to be meticulously annotated with rewards. In this paper, we introduce Optimal Transport Reward (OTR) labelling, an innovative algorithm designed to assign rewards to offline trajectories, using a small number of high-quality expert demonstrations. The core principle of OTR involves employing Optimal Transport (OT) to calculate an optimal alignment between an unlabeled trajectory from the dataset and an expert demonstration. This alignment yields a similarity measure that is effectively interpreted as a reward signal. An offline RL algorithm can then utilize these reward signals to learn a policy. This approach circumvents the need for handcrafted rewards, unlocking the potential to harness vast datasets for policy learning. Leveraging the SurRoL simulation platform tailored for surgical robot learning, we generate datasets and employ them to train policies using the OTR algorithm. By demonstrating the efficacy of OTR in a different domain, we emphasize its versatility and its potential to expedite RL deployment across a wide range of fields.
MEMTRACK: A Deep Learning-Based Approach to Microrobot Tracking in Dense and Low-Contrast Environments
Oct 13, 2023Tracking microrobots is challenging, considering their minute size and high speed. As the field progresses towards developing microrobots for biomedical applications and conducting mechanistic studies in physiologically relevant media (e.g., collagen), this challenge is exacerbated by the dense surrounding environments with feature size and shape comparable to microrobots. Herein, we report Motion Enhanced Multi-level Tracker (MEMTrack), a robust pipeline for detecting and tracking microrobots using synthetic motion features, deep learning-based object detection, and a modified Simple Online and Real-time Tracking (SORT) algorithm with interpolation for tracking. Our object detection approach combines different models based on the object's motion pattern. We trained and validated our model using bacterial micro-motors in collagen (tissue phantom) and tested it in collagen and aqueous media. We demonstrate that MEMTrack accurately tracks even the most challenging bacteria missed by skilled human annotators, achieving precision and recall of 77% and 48% in collagen and 94% and 35% in liquid media, respectively. Moreover, we show that MEMTrack can quantify average bacteria speed with no statistically significant difference from the laboriously-produced manual tracking data. MEMTrack represents a significant contribution to microrobot localization and tracking, and opens the potential for vision-based deep learning approaches to microrobot control in dense and low-contrast settings. All source code for training and testing MEMTrack and reproducing the results of the paper have been made publicly available https://github.com/sawhney-medha/MEMTrack.
LESSON: Learning to Integrate Exploration Strategies for Reinforcement Learning via an Option Framework
Oct 05, 2023In this paper, a unified framework for exploration in reinforcement learning (RL) is proposed based on an option-critic model. The proposed framework learns to integrate a set of diverse exploration strategies so that the agent can adaptively select the most effective exploration strategy over time to realize a relevant exploration-exploitation trade-off for each given task. The effectiveness of the proposed exploration framework is demonstrated by various experiments in the MiniGrid and Atari environments.
JSMoCo: Joint Coil Sensitivity and Motion Correction in Parallel MRI with a Self-Calibrating Score-Based Diffusion Model
Oct 14, 2023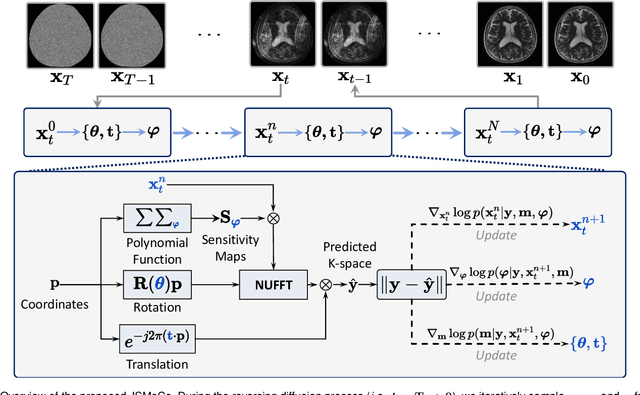
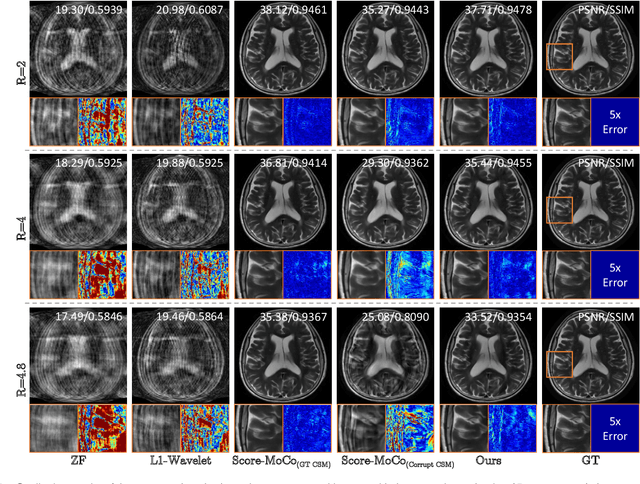
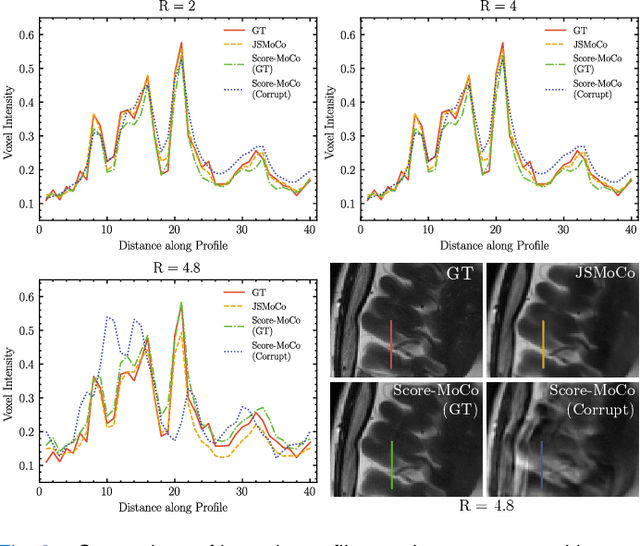

Magnetic Resonance Imaging (MRI) stands as a powerful modality in clinical diagnosis. However, it is known that MRI faces challenges such as long acquisition time and vulnerability to motion-induced artifacts. Despite the success of many existing motion correction algorithms, there has been limited research focused on correcting motion artifacts on the estimated coil sensitivity maps for fast MRI reconstruction. Existing methods might suffer from severe performance degradation due to error propagation resulting from the inaccurate coil sensitivity maps estimation. In this work, we propose to jointly estimate the motion parameters and coil sensitivity maps for under-sampled MRI reconstruction, referred to as JSMoCo. However, joint estimation of motion parameters and coil sensitivities results in a highly ill-posed inverse problem due to an increased number of unknowns. To address this, we introduce score-based diffusion models as powerful priors and leverage the MRI physical principles to efficiently constrain the solution space for this optimization problem. Specifically, we parameterize the rigid motion as three trainable variables and model coil sensitivity maps as polynomial functions. Leveraging the physical knowledge, we then employ Gibbs sampler for joint estimation, ensuring system consistency between sensitivity maps and desired images, avoiding error propagation from pre-estimated sensitivity maps to the reconstructed images. We conduct comprehensive experiments to evaluate the performance of JSMoCo on the fastMRI dataset. The results show that our method is capable of reconstructing high-quality MRI images from sparsely-sampled k-space data, even affected by motion. It achieves this by accurately estimating both motion parameters and coil sensitivities, effectively mitigating motion-related challenges during MRI reconstruction.
Fusing Monocular Images and Sparse IMU Signals for Real-time Human Motion Capture
Sep 01, 2023
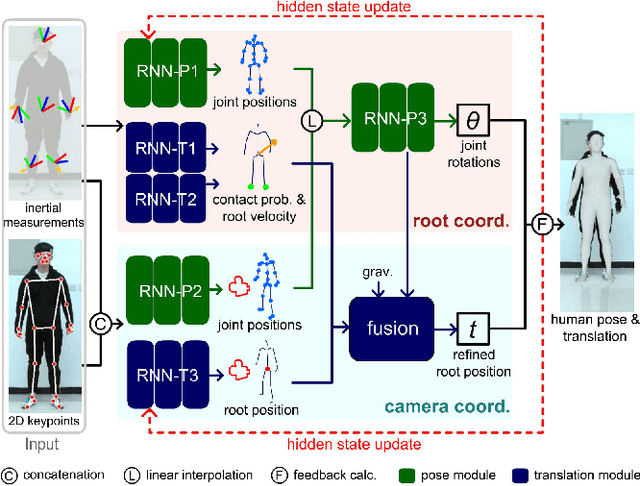
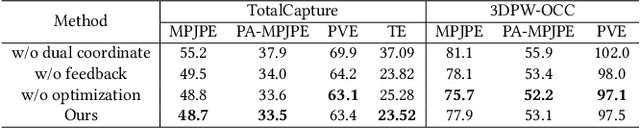

Either RGB images or inertial signals have been used for the task of motion capture (mocap), but combining them together is a new and interesting topic. We believe that the combination is complementary and able to solve the inherent difficulties of using one modality input, including occlusions, extreme lighting/texture, and out-of-view for visual mocap and global drifts for inertial mocap. To this end, we propose a method that fuses monocular images and sparse IMUs for real-time human motion capture. Our method contains a dual coordinate strategy to fully explore the IMU signals with different goals in motion capture. To be specific, besides one branch transforming the IMU signals to the camera coordinate system to combine with the image information, there is another branch to learn from the IMU signals in the body root coordinate system to better estimate body poses. Furthermore, a hidden state feedback mechanism is proposed for both two branches to compensate for their own drawbacks in extreme input cases. Thus our method can easily switch between the two kinds of signals or combine them in different cases to achieve a robust mocap. %The two divided parts can help each other for better mocap results under different conditions. Quantitative and qualitative results demonstrate that by delicately designing the fusion method, our technique significantly outperforms the state-of-the-art vision, IMU, and combined methods on both global orientation and local pose estimation. Our codes are available for research at https://shaohua-pan.github.io/robustcap-page/.
Adaptive Quantization for Key Generation in Low-Power Wide-Area Networks
Oct 11, 2023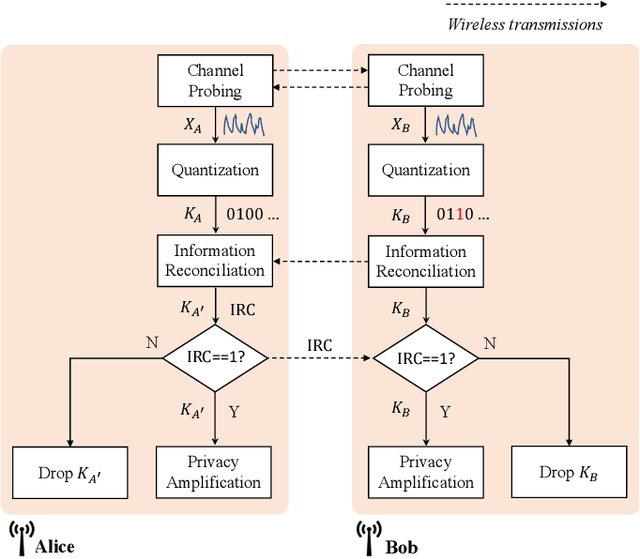
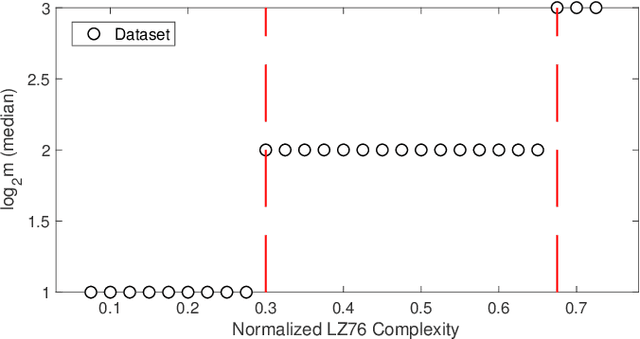
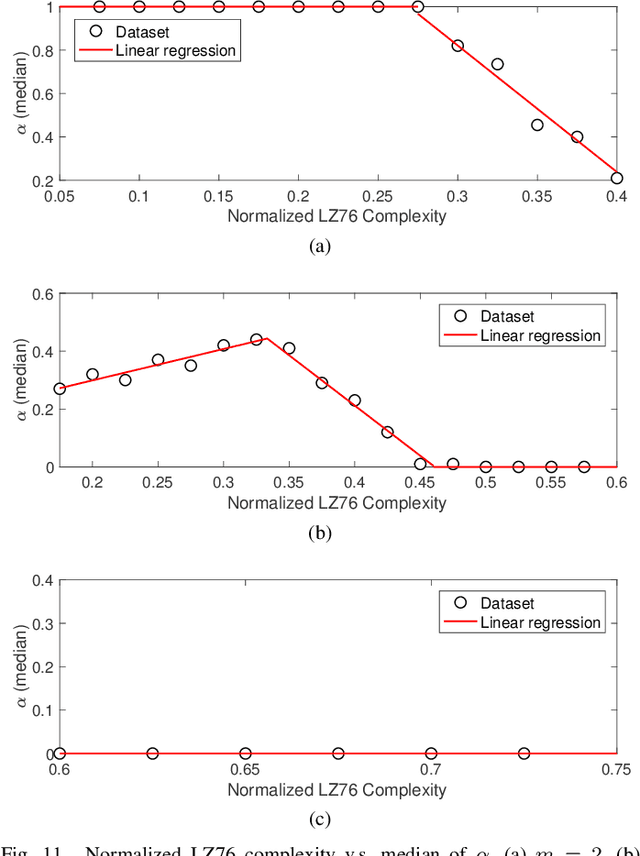
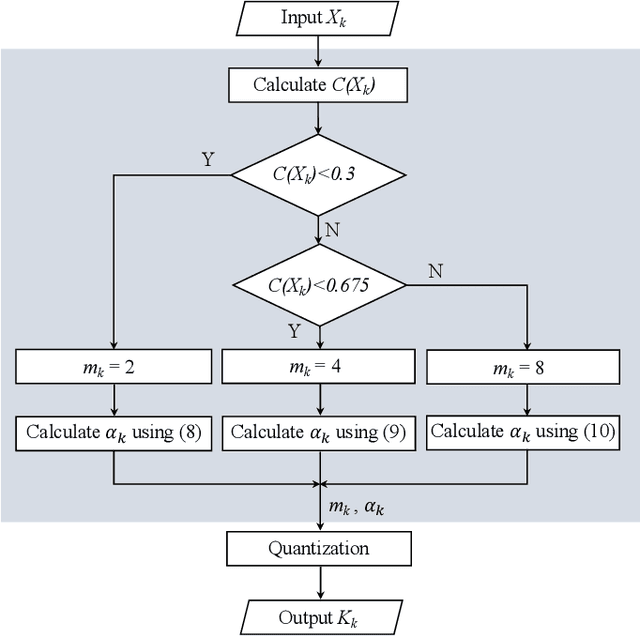
Physical layer key generation based on reciprocal and random wireless channels has been an attractive solution for securing resource-constrained low-power wide-area networks (LPWANs). When quantizing channel measurements, namely received signal strength indicator (RSSI), into key bits, the existing works mainly adopt fixed quantization levels and guard band parameters, which fail to fully extract keys from RSSI measurements. In this paper, we propose a novel adaptive quantization scheme for key generation in LPWANs, taking LoRa as a case study. The proposed adaptive quantization scheme can dynamically adjust the quantization parameters according to the randomness of RSSI measurements estimated by Lempel-Ziv complexity (LZ76), while ensuring a predefined key disagreement ratio (KDR). Specifically, our scheme uses pre-trained linear regression models to determine the appropriate quantization level and guard band parameter for each segment of RSSI measurements. Moreover, we propose a guard band parameter calibration scheme during information reconciliation during real-time key generation operation. Experimental evaluations using LoRa devices show that the proposed adaptive quantization scheme outperforms the benchmark differential quantization and fixed quantization with up to 2.35$\times$ and 1.51$\times$ key generation rate (KGR) gains, respectively.