 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Mar 13, 2024
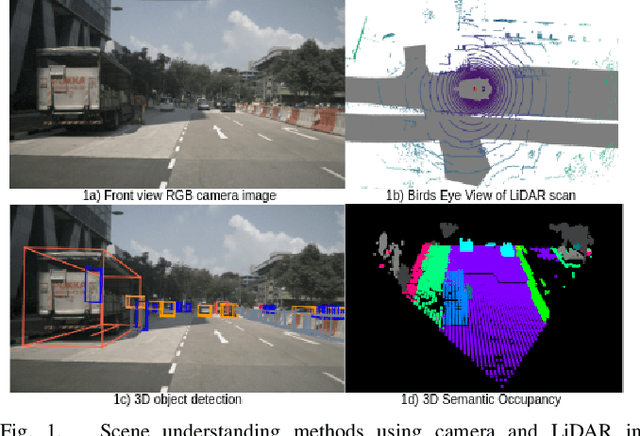
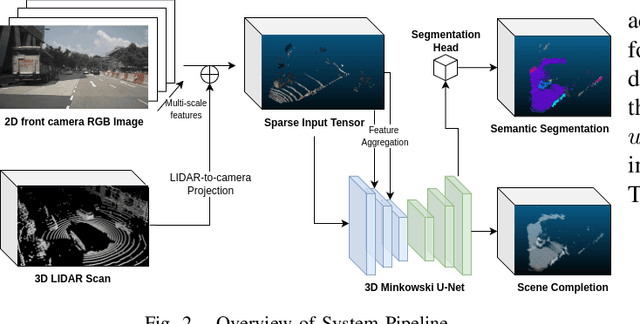
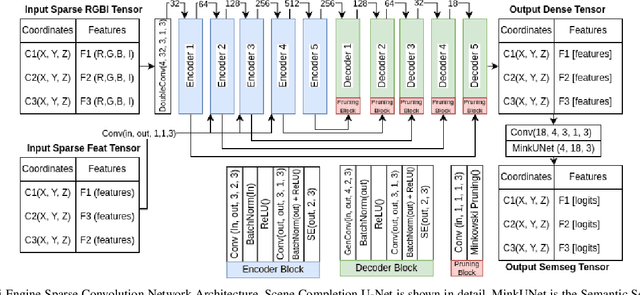
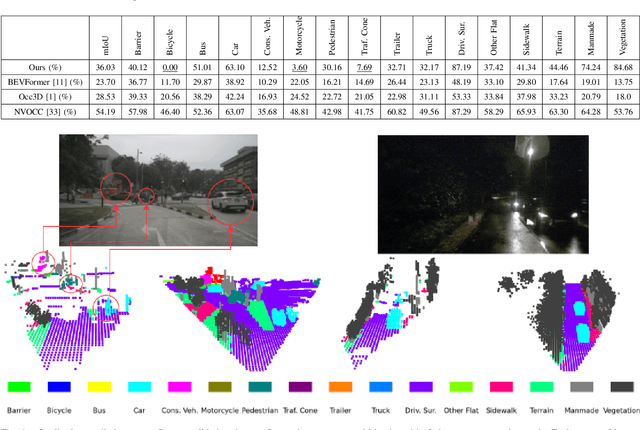
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
Finite-Time Error Analysis of Soft Q-Learning: Switching System Approach
Mar 11, 2024Soft Q-learning is a variation of Q-learning designed to solve entropy regularized Markov decision problems where an agent aims to maximize the entropy regularized value function. Despite its empirical success, there have been limited theoretical studies of soft Q-learning to date. This paper aims to offer a novel and unified finite-time, control-theoretic analysis of soft Q-learning algorithms. We focus on two types of soft Q-learning algorithms: one utilizing the log-sum-exp operator and the other employing the Boltzmann operator. By using dynamical switching system models, we derive novel finite-time error bounds for both soft Q-learning algorithms. We hope that our analysis will deepen the current understanding of soft Q-learning by establishing connections with switching system models and may even pave the way for new frameworks in the finite-time analysis of other reinforcement learning algorithms.
Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models
Mar 13, 2024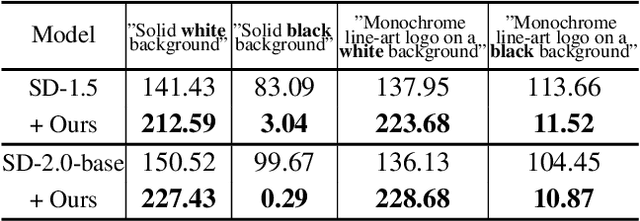
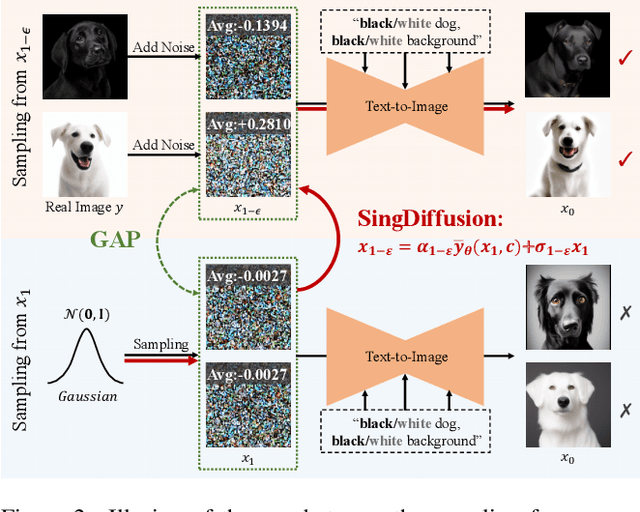


Most diffusion models assume that the reverse process adheres to a Gaussian distribution. However, this approximation has not been rigorously validated, especially at singularities, where t=0 and t=1. Improperly dealing with such singularities leads to an average brightness issue in applications, and limits the generation of images with extreme brightness or darkness. We primarily focus on tackling singularities from both theoretical and practical perspectives. Initially, we establish the error bounds for the reverse process approximation, and showcase its Gaussian characteristics at singularity time steps. Based on this theoretical insight, we confirm the singularity at t=1 is conditionally removable while it at t=0 is an inherent property. Upon these significant conclusions, we propose a novel plug-and-play method SingDiffusion to address the initial singular time step sampling, which not only effectively resolves the average brightness issue for a wide range of diffusion models without extra training efforts, but also enhances their generation capability in achieving notable lower FID scores. Code and models are released at https://github.com/PangzeCheung/SingDiffusion.
FastPerson: Enhancing Video Learning through Effective Video Summarization that Preserves Linguistic and Visual Contexts
Mar 26, 2024Quickly understanding lengthy lecture videos is essential for learners with limited time and interest in various topics to improve their learning efficiency. To this end, video summarization has been actively researched to enable users to view only important scenes from a video. However, these studies focus on either the visual or audio information of a video and extract important segments in the video. Therefore, there is a risk of missing important information when both the teacher's speech and visual information on the blackboard or slides are important, such as in a lecture video. To tackle this issue, we propose FastPerson, a video summarization approach that considers both the visual and auditory information in lecture videos. FastPerson creates summary videos by utilizing audio transcriptions along with on-screen images and text, minimizing the risk of overlooking crucial information for learners. Further, it provides a feature that allows learners to switch between the summary and original videos for each chapter of the video, enabling them to adjust the pace of learning based on their interests and level of understanding. We conducted an evaluation with 40 participants to assess the effectiveness of our method and confirmed that it reduced viewing time by 53\% at the same level of comprehension as that when using traditional video playback methods.
Project MOSLA: Recording Every Moment of Second Language Acquisition
Mar 26, 2024Second language acquisition (SLA) is a complex and dynamic process. Many SLA studies that have attempted to record and analyze this process have typically focused on a single modality (e.g., textual output of learners), covered only a short period of time, and/or lacked control (e.g., failed to capture every aspect of the learning process). In Project MOSLA (Moments of Second Language Acquisition), we have created a longitudinal, multimodal, multilingual, and controlled dataset by inviting participants to learn one of three target languages (Arabic, Spanish, and Chinese) from scratch over a span of two years, exclusively through online instruction, and recording every lesson using Zoom. The dataset is semi-automatically annotated with speaker/language IDs and transcripts by both human annotators and fine-tuned state-of-the-art speech models. Our experiments reveal linguistic insights into learners' proficiency development over time, as well as the potential for automatically detecting the areas of focus on the screen purely from the unannotated multimodal data. Our dataset is freely available for research purposes and can serve as a valuable resource for a wide range of applications, including but not limited to SLA, proficiency assessment, language and speech processing, pedagogy, and multimodal learning analytics.
Efficient Video Object Segmentation via Modulated Cross-Attention Memory
Mar 26, 2024Recently, transformer-based approaches have shown promising results for semi-supervised video object segmentation. However, these approaches typically struggle on long videos due to increased GPU memory demands, as they frequently expand the memory bank every few frames. We propose a transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6x, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. Notably on the LVOS dataset, our MAVOS achieves a J&F score of 63.3% while operating at 37 frames per second (FPS) on a single V100 GPU. Our code and models will be publicly available at: https://github.com/Amshaker/MAVOS.
Multi-Source Localization and Data Association for Time-Difference of Arrival Measurements
Mar 15, 2024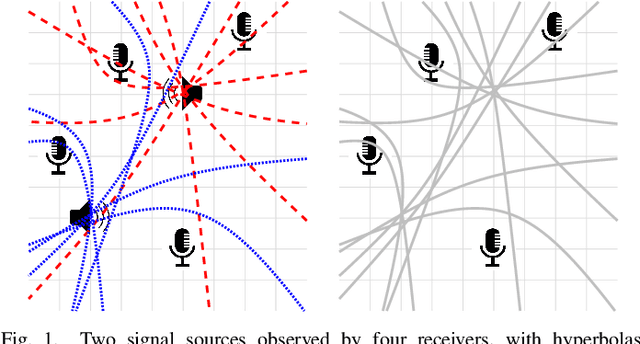
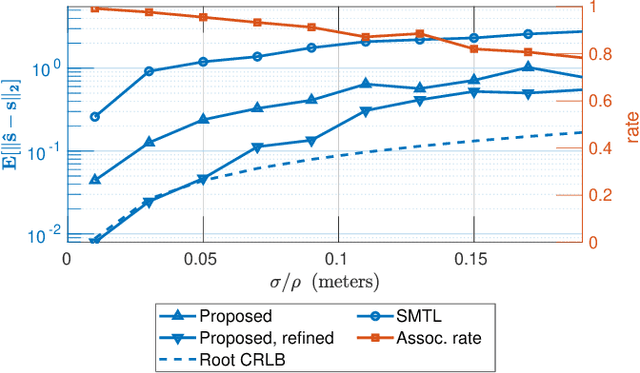
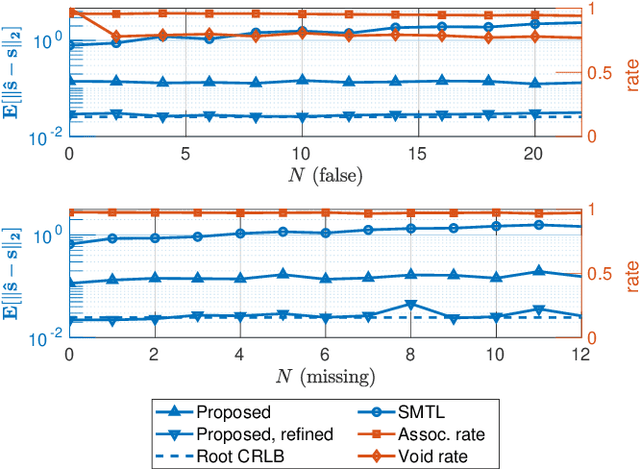
In this work, we consider the problem of localizing multiple signal sources based on time-difference of arrival (TDOA) measurements. In the blind setting, in which the source signals are not known, the localization task is challenging due to the data association problem. That is, it is not known which of the TDOA measurements correspond to the same source. Herein, we propose to perform joint localization and data association by means of an optimal transport formulation. The method operates by finding optimal groupings of TDOA measurements and associating these with candidate source locations. To allow for computationally feasible localization in three-dimensional space, an efficient set of candidate locations is constructed using a minimal multilateration solver based on minimal sets of receiver pairs. In numerical simulations, we demonstrate that the proposed method is robust both to measurement noise and TDOA detection errors. Furthermore, it is shown that the data association provided by the proposed method allows for statistically efficient estimates of the source locations.
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Mar 28, 2024Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) a new jailbreaking dataset containing 100 unique behaviors, which we call JBB-Behaviors; (2) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.
Jamba: A Hybrid Transformer-Mamba Language Model
Mar 28, 2024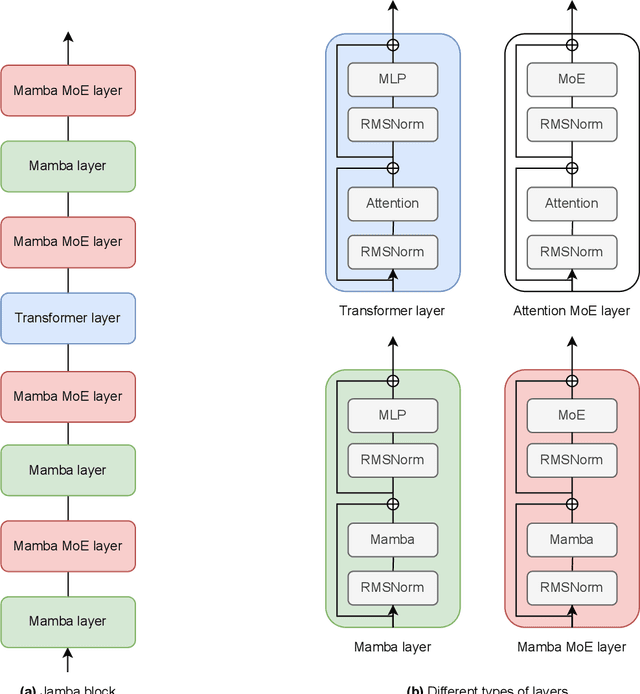

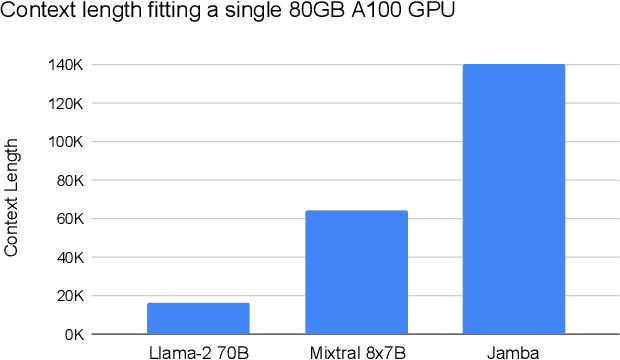
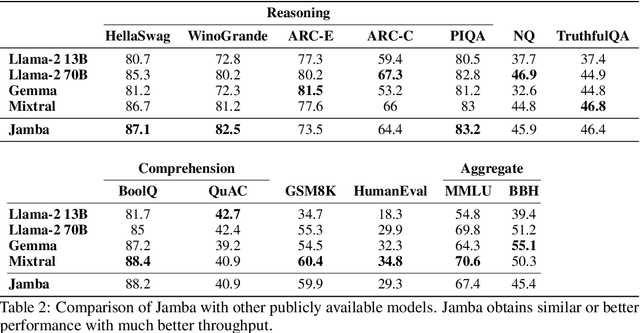
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
DeepSample: DNN sampling-based testing for operational accuracy assessment
Mar 28, 2024Deep Neural Networks (DNN) are core components for classification and regression tasks of many software systems. Companies incur in high costs for testing DNN with datasets representative of the inputs expected in operation, as these need to be manually labelled. The challenge is to select a representative set of test inputs as small as possible to reduce the labelling cost, while sufficing to yield unbiased high-confidence estimates of the expected DNN accuracy. At the same time, testers are interested in exposing as many DNN mispredictions as possible to improve the DNN, ending up in the need for techniques pursuing a threefold aim: small dataset size, trustworthy estimates, mispredictions exposure. This study presents DeepSample, a family of DNN testing techniques for cost-effective accuracy assessment based on probabilistic sampling. We investigate whether, to what extent, and under which conditions probabilistic sampling can help to tackle the outlined challenge. We implement five new sampling-based testing techniques, and perform a comprehensive comparison of such techniques and of three further state-of-the-art techniques for both DNN classification and regression tasks. Results serve as guidance for best use of sampling-based testing for faithful and high-confidence estimates of DNN accuracy in operation at low cost.