 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PGraphDTA: Improving Drug Target Interaction Prediction using Protein Language Models and Contact Maps
Oct 06, 2023


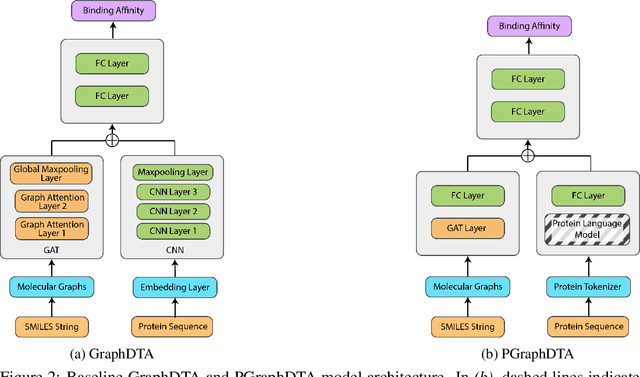
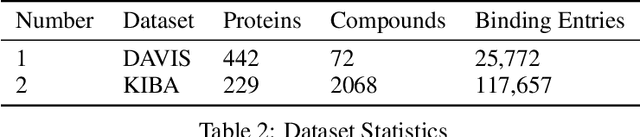
Developing and discovering new drugs is a complex and resource-intensive endeavor that often involves substantial costs, time investment, and safety concerns. A key aspect of drug discovery involves identifying novel drug-target (DT) interactions. Existing computational methods for predicting DT interactions have primarily focused on binary classification tasks, aiming to determine whether a DT pair interacts or not. However, protein-ligand interactions exhibit a continuum of binding strengths, known as binding affinity, presenting a persistent challenge for accurate prediction. In this study, we investigate various techniques employed in Drug Target Interaction (DTI) prediction and propose novel enhancements to enhance their performance. Our approaches include the integration of Protein Language Models (PLMs) and the incorporation of Contact Map information as an inductive bias within current models. Through extensive experimentation, we demonstrate that our proposed approaches outperform the baseline models considered in this study, presenting a compelling case for further development in this direction. We anticipate that the insights gained from this work will significantly narrow the search space for potential drugs targeting specific proteins, thereby accelerating drug discovery. Code and data for PGraphDTA are available at https://anonymous.4open.science/r/PGraphDTA.
Robust Losses for Decision-Focused Learning
Oct 06, 2023Optimization models used to make discrete decisions often contain uncertain parameters that are context-dependent and are estimated through prediction. To account for the quality of the decision made based on the prediction, decision-focused learning (end-to-end predict-then-optimize) aims at training the predictive model to minimize regret, i.e., the loss incurred by making a suboptimal decision. Despite the challenge of this loss function being possibly non-convex and in general non-differentiable, effective gradient-based learning approaches have been proposed to minimize the expected loss, using the empirical loss as a surrogate. However, empirical regret can be an ineffective surrogate because the uncertainty in the optimization model makes the empirical regret unequal to the expected regret in expectation. To illustrate the impact of this inequality, we evaluate the effect of aleatoric and epistemic uncertainty on the accuracy of empirical regret as a surrogate. Next, we propose three robust loss functions that more closely approximate expected regret. Experimental results show that training two state-of-the-art decision-focused learning approaches using robust regret losses improves test-sample empirical regret in general while keeping computational time equivalent relative to the number of training epochs.
Ultimate limit on learning non-Markovian behavior: Fisher information rate and excess information
Oct 06, 2023We address the fundamental limits of learning unknown parameters of any stochastic process from time-series data, and discover exact closed-form expressions for how optimal inference scales with observation length. Given a parametrized class of candidate models, the Fisher information of observed sequence probabilities lower-bounds the variance in model estimation from finite data. As sequence-length increases, the minimal variance scales as the square inverse of the length -- with constant coefficient given by the information rate. We discover a simple closed-form expression for this information rate, even in the case of infinite Markov order. We furthermore obtain the exact analytic lower bound on model variance from the observation-induced metadynamic among belief states. We discover ephemeral, exponential, and more general modes of convergence to the asymptotic information rate. Surprisingly, this myopic information rate converges to the asymptotic Fisher information rate with exactly the same relaxation timescales that appear in the myopic entropy rate as it converges to the Shannon entropy rate for the process. We illustrate these results with a sequence of examples that highlight qualitatively distinct features of stochastic processes that shape optimal learning.
Multilingual Natural Language Processing Model for Radiology Reports -- The Summary is all you need!
Oct 06, 2023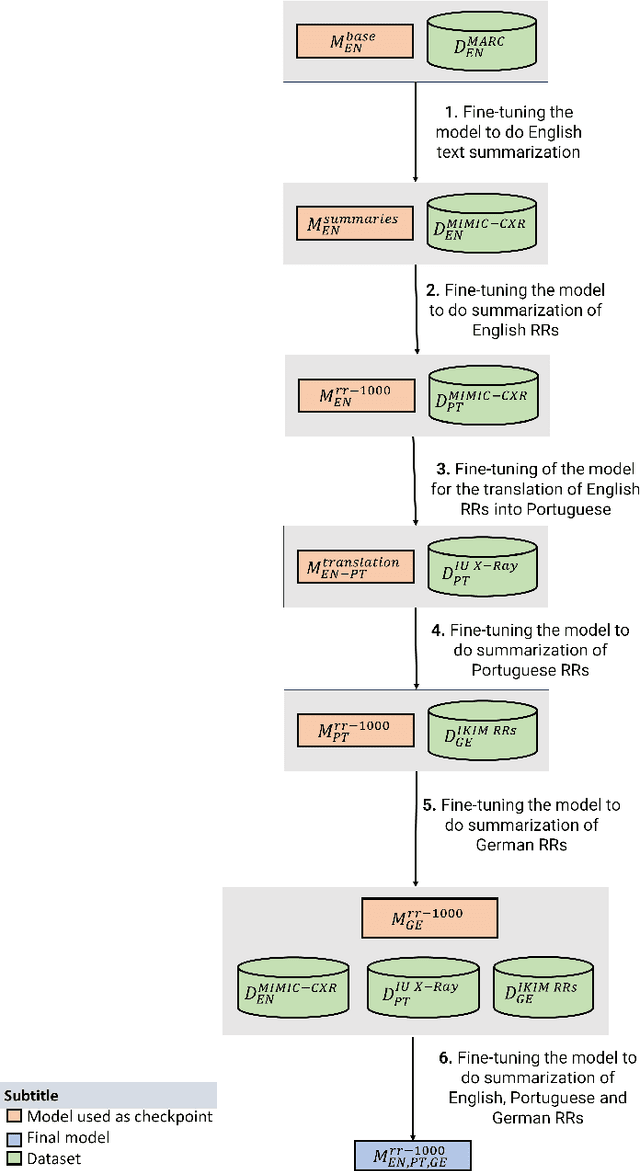

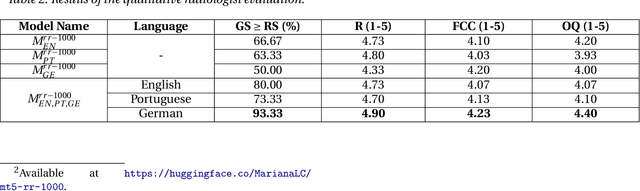
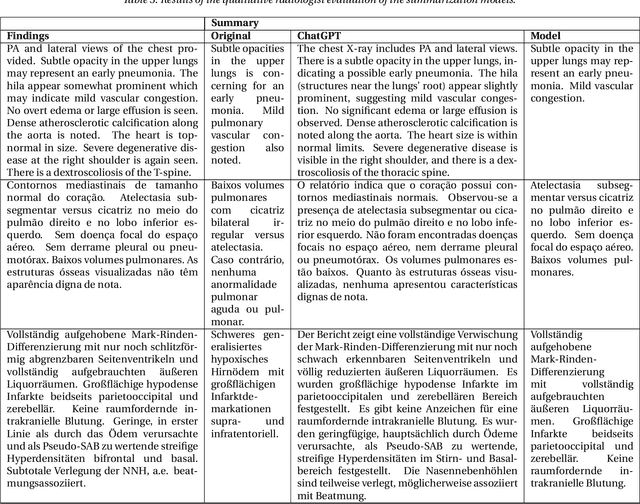
The impression section of a radiology report summarizes important radiology findings and plays a critical role in communicating these findings to physicians. However, the preparation of these summaries is time-consuming and error-prone for radiologists. Recently, numerous models for radiology report summarization have been developed. Nevertheless, there is currently no model that can summarize these reports in multiple languages. Such a model could greatly improve future research and the development of Deep Learning models that incorporate data from patients with different ethnic backgrounds. In this study, the generation of radiology impressions in different languages was automated by fine-tuning a model, publicly available, based on a multilingual text-to-text Transformer to summarize findings available in English, Portuguese, and German radiology reports. In a blind test, two board-certified radiologists indicated that for at least 70% of the system-generated summaries, the quality matched or exceeded the corresponding human-written summaries, suggesting substantial clinical reliability. Furthermore, this study showed that the multilingual model outperformed other models that specialized in summarizing radiology reports in only one language, as well as models that were not specifically designed for summarizing radiology reports, such as ChatGPT.
TimePool: Visually Answer "Which and When" Questions On Univariate Time Series
Aug 01, 2023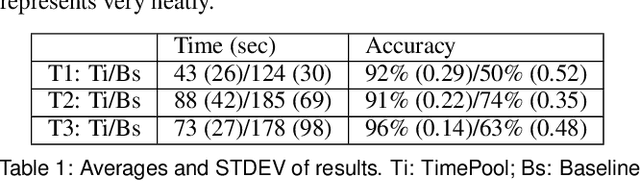
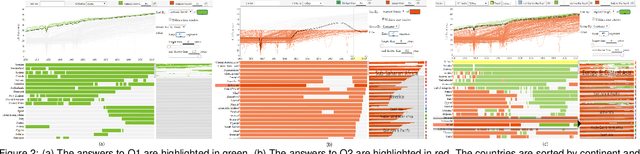
When exploring time series datasets, analysts often pose "which and when" questions. For example, with world life expectancy data over one hundred years, they may inquire about the top 10 countries in life expectancy and the time period when they achieved this status, or which countries have had longer life expectancy than Ireland and when. This paper proposes TimePool, a new visualization prototype, to address this need for univariate time series analysis. It allows users to construct interactive "which and when" queries and visually explore the results for insights.
RBF Weighted Hyper-Involution for RGB-D Object Detection
Sep 30, 2023A vast majority of conventional augmented reality devices are equipped with depth sensors. Depth images produced by such sensors contain complementary information for object detection when used with color images. Despite the benefits, it remains a complex task to simultaneously extract photometric and depth features in real time due to the immanent difference between depth and color images. Moreover, standard convolution operations are not sufficient to properly extract information directly from raw depth images leading to intermediate representations of depth which is inefficient. To address these issues, we propose a real-time and two stream RGBD object detection model. The proposed model consists of two new components: a depth guided hyper-involution that adapts dynamically based on the spatial interaction pattern in the raw depth map and an up-sampling based trainable fusion layer that combines the extracted depth and color image features without blocking the information transfer between them. We show that the proposed model outperforms other RGB-D based object detection models on NYU Depth v2 dataset and achieves comparable (second best) results on SUN RGB-D. Additionally, we introduce a new outdoor RGB-D object detection dataset where our proposed model outperforms other models. The performance evaluation on diverse synthetic data generated from CAD models and images shows the potential of the proposed model to be adapted to augmented reality based applications.
Physics-Informed Neural Networks for Accelerating Power System State Estimation
Oct 04, 2023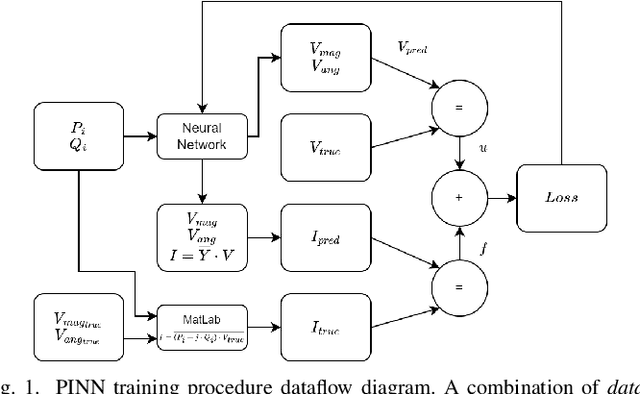
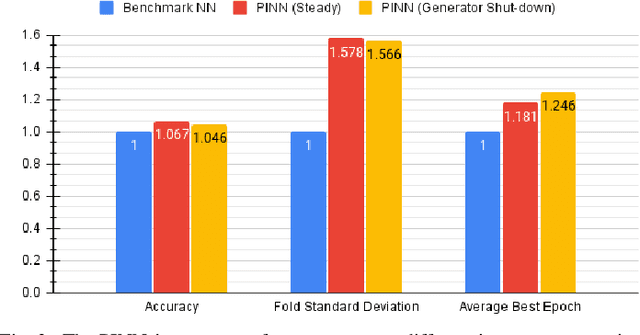
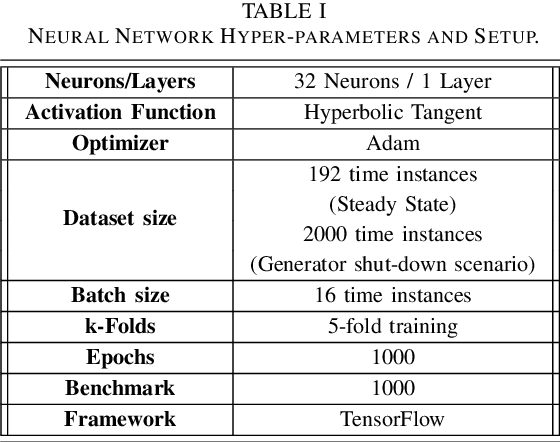
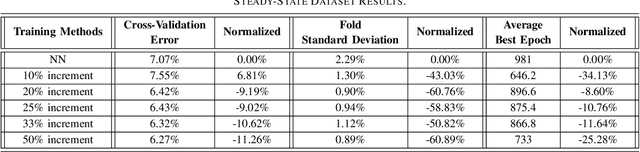
State estimation is the cornerstone of the power system control center since it provides the operating condition of the system in consecutive time intervals. This work investigates the application of physics-informed neural networks (PINNs) for accelerating power systems state estimation in monitoring the operation of power systems. Traditional state estimation techniques often rely on iterative algorithms that can be computationally intensive, particularly for large-scale power systems. In this paper, a novel approach that leverages the inherent physical knowledge of power systems through the integration of PINNs is proposed. By incorporating physical laws as prior knowledge, the proposed method significantly reduces the computational complexity associated with state estimation while maintaining high accuracy. The proposed method achieves up to 11% increase in accuracy, 75% reduction in standard deviation of results, and 30% faster convergence, as demonstrated by comprehensive experiments on the IEEE 14-bus system.
Adaptive Spatio-Temporal Voxels Based Trajectory Planning for Autonomous Driving in Highway Traffic Flow
Oct 04, 2023
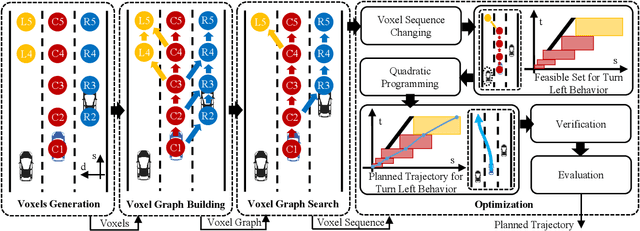
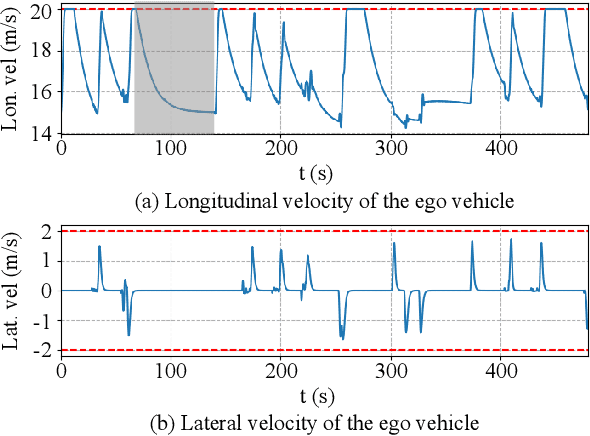
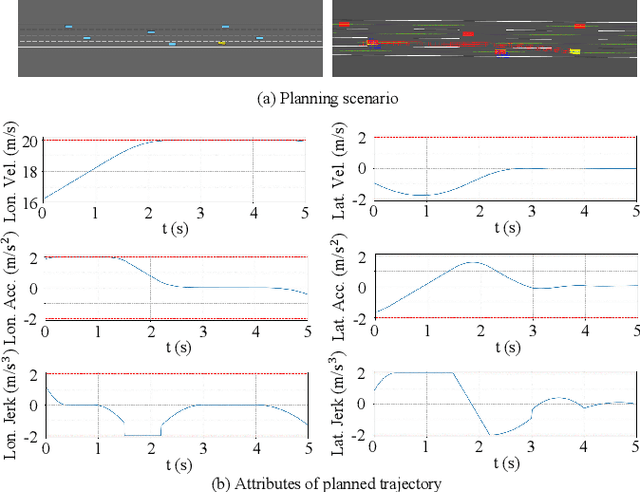
Trajectory planning is crucial for the safe driving of autonomous vehicles in highway traffic flow. Currently, some advanced trajectory planning methods utilize spatio-temporal voxels to construct feasible regions and then convert trajectory planning into optimization problem solving based on the feasible regions. However, these feasible region construction methods cannot adapt to the changes in dynamic environments, making them difficult to apply in complex traffic flow. In this paper, we propose a trajectory planning method based on adaptive spatio-temporal voxels which improves the construction of feasible regions and trajectory optimization while maintaining the quadratic programming form. The method can adjust feasible regions and trajectory planning according to real-time traffic flow and environmental changes, realizing vehicles to drive safely in complex traffic flow. The proposed method has been tested in both open-loop and closed-loop environments, and the test results show that our method outperforms the current planning methods.
* 8 pages, 5 figures
On Computational Entanglement and Its Interpretation in Adversarial Machine Learning
Oct 04, 2023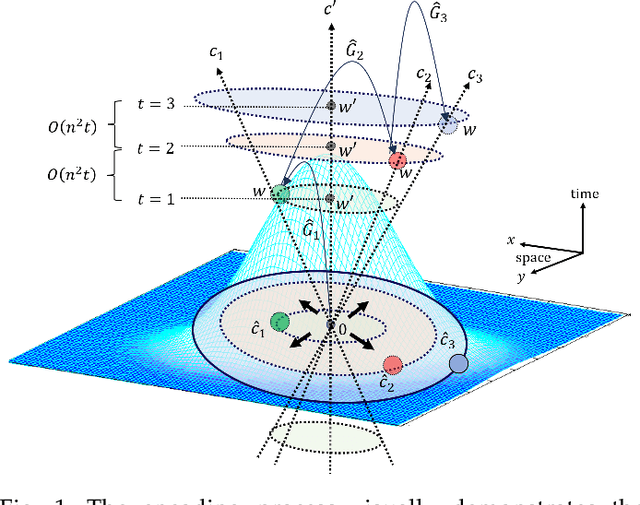
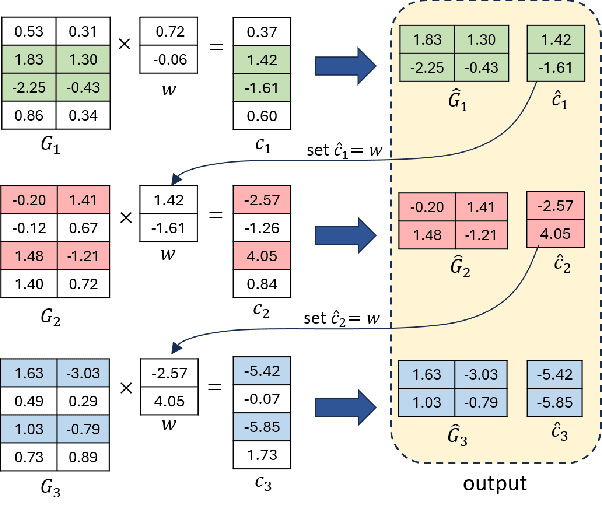
Adversarial examples in machine learning has emerged as a focal point of research due to their remarkable ability to deceive models with seemingly inconspicuous input perturbations, potentially resulting in severe consequences. In this study, we embark on a comprehensive exploration of adversarial machine learning models, shedding light on their intrinsic complexity and interpretability. Our investigation reveals intriguing links between machine learning model complexity and Einstein's theory of special relativity, through the concept of entanglement. More specific, we define entanglement computationally and demonstrate that distant feature samples can exhibit strong correlations, akin to entanglement in quantum realm. This revelation challenges conventional perspectives in describing the phenomenon of adversarial transferability observed in contemporary machine learning models. By drawing parallels with the relativistic effects of time dilation and length contraction during computation, we gain deeper insights into adversarial machine learning, paving the way for more robust and interpretable models in this rapidly evolving field.
Synergistic Signal Denoising for Multimodal Time Series of Structure Vibration
Aug 17, 2023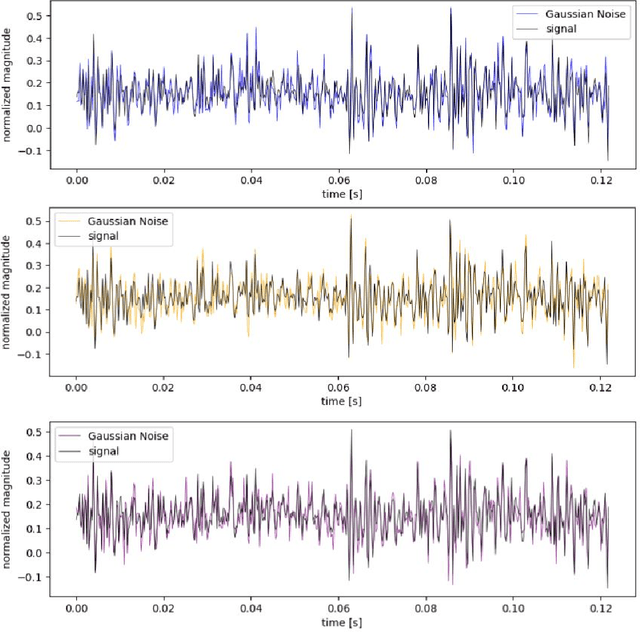
Structural Health Monitoring (SHM) plays an indispensable role in ensuring the longevity and safety of infrastructure. With the rapid growth of sensor technology, the volume of data generated from various structures has seen an unprecedented surge, bringing forth challenges in efficient analysis and interpretation. This paper introduces a novel deep learning algorithm tailored for the complexities inherent in multimodal vibration signals prevalent in SHM. By amalgamating convolutional and recurrent architectures, the algorithm adeptly captures both localized and prolonged structural behaviors. The pivotal integration of attention mechanisms further enhances the model's capability, allowing it to discern and prioritize salient structural responses from extraneous noise. Our results showcase significant improvements in predictive accuracy, early damage detection, and adaptability across multiple SHM scenarios. In light of the critical nature of SHM, the proposed approach not only offers a robust analytical tool but also paves the way for more transparent and interpretable AI-driven SHM solutions. Future prospects include real-time processing, integration with external environmental factors, and a deeper emphasis on model interpretability.