 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Point-NeuS: Point-Guided Neural Implicit Surface Reconstruction by Volume Rendering
Oct 12, 2023
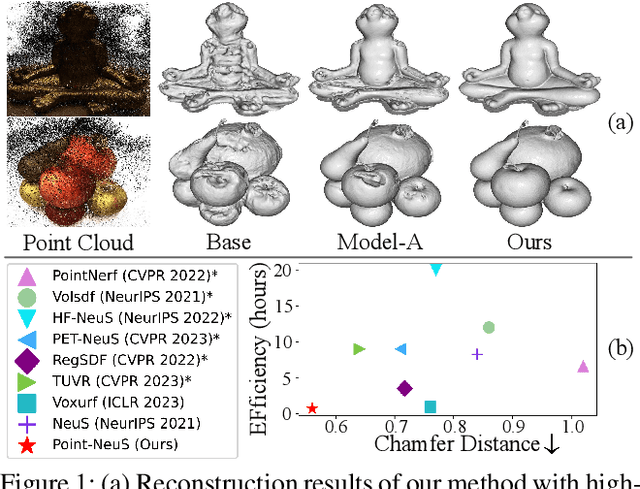
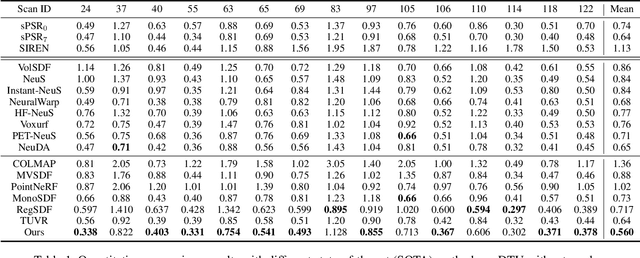
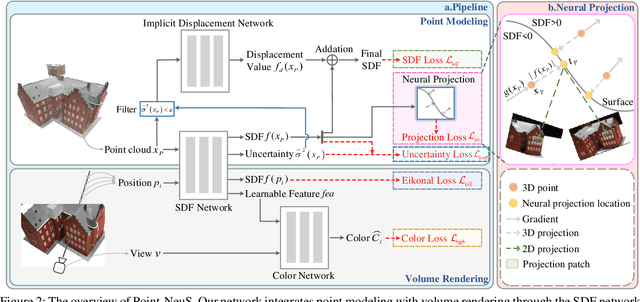

Recently, learning neural implicit surface by volume rendering has been a promising way for multi-view reconstruction. However, limited accuracy and excessive time complexity remain bottlenecks that current methods urgently need to overcome. To address these challenges, we propose a new method called Point-NeuS, utilizing point-guided mechanisms to achieve accurate and efficient reconstruction. Point modeling is organically embedded into the volume rendering to enhance and regularize the representation of implicit surface. Specifically, to achieve precise point guidance and noise robustness, aleatoric uncertainty of the point cloud is modeled to capture the distribution of noise and estimate the reliability of points. Additionally, a Neural Projection module connecting points and images is introduced to add geometric constraints to the Signed Distance Function (SDF). To better compensate for geometric bias between volume rendering and point modeling, high-fidelity points are filtered into an Implicit Displacement Network to improve the representation of SDF. Benefiting from our effective point guidance, lightweight networks are employed to achieve an impressive 11x speedup compared to NeuS. Extensive experiments show that our method yields high-quality surfaces, especially for fine-grained details and smooth regions. Moreover, it exhibits strong robustness to both noisy and sparse data.
Exploring the Relationship Between Model Architecture and In-Context Learning Ability
Oct 12, 2023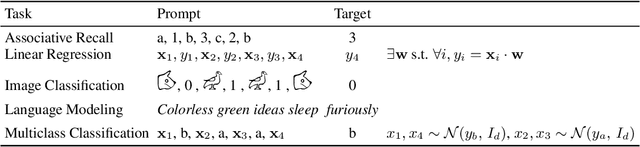
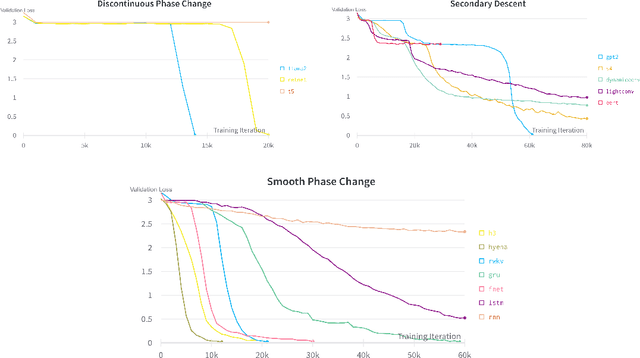
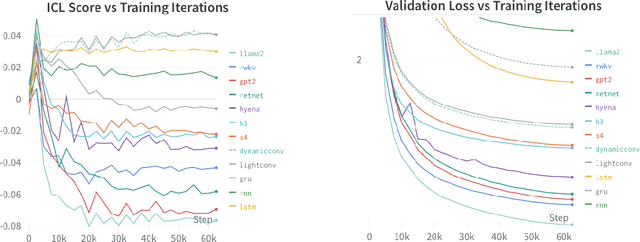
What is the relationship between model architecture and the ability to perform in-context learning? In this empirical study, we take the first steps towards answering this question. In particular, we evaluate fifteen model architectures across a suite of synthetic in-context learning tasks. The selected architectures represent a broad range of paradigms, including recurrent and convolution-based neural networks, transformers, and emerging attention alternatives. We discover that all considered architectures can perform in-context learning under certain conditions. However, contemporary architectures are found to be the best performing, especially as task complexity grows. Additionally, our follow-up experiments delve into various factors that influence in-context learning. We observe varied sensitivities among architectures with respect to hyperparameter settings. Our study of training dynamics reveals that certain architectures exhibit a smooth, progressive learning trajectory, while others demonstrate periods of stagnation followed by abrupt mastery of the task. Finally, and somewhat surprisingly, we find that several emerging attention alternatives are more robust in-context learners than transformers; since such approaches have constant-sized memory footprints at inference time, this result opens the future possibility of scaling up in-context learning to vastly larger numbers of in-context examples.
Rethinking Large-scale Pre-ranking System: Entire-chain Cross-domain Models
Oct 12, 2023Industrial systems such as recommender systems and online advertising, have been widely equipped with multi-stage architectures, which are divided into several cascaded modules, including matching, pre-ranking, ranking and re-ranking. As a critical bridge between matching and ranking, existing pre-ranking approaches mainly endure sample selection bias (SSB) problem owing to ignoring the entire-chain data dependence, resulting in sub-optimal performances. In this paper, we rethink pre-ranking system from the perspective of the entire sample space, and propose Entire-chain Cross-domain Models (ECM), which leverage samples from the whole cascaded stages to effectively alleviate SSB problem. Besides, we design a fine-grained neural structure named ECMM to further improve the pre-ranking accuracy. Specifically, we propose a cross-domain multi-tower neural network to comprehensively predict for each stage result, and introduce the sub-networking routing strategy with $L0$ regularization to reduce computational costs. Evaluations on real-world large-scale traffic logs demonstrate that our pre-ranking models outperform SOTA methods while time consumption is maintained within an acceptable level, which achieves better trade-off between efficiency and effectiveness.
* 5 pages, 2 figures
SEE-OoD: Supervised Exploration For Enhanced Out-of-Distribution Detection
Oct 12, 2023Current techniques for Out-of-Distribution (OoD) detection predominantly rely on quantifying predictive uncertainty and incorporating model regularization during the training phase, using either real or synthetic OoD samples. However, methods that utilize real OoD samples lack exploration and are prone to overfit the OoD samples at hand. Whereas synthetic samples are often generated based on features extracted from training data, rendering them less effective when the training and OoD data are highly overlapped in the feature space. In this work, we propose a Wasserstein-score-based generative adversarial training scheme to enhance OoD detection accuracy, which, for the first time, performs data augmentation and exploration simultaneously under the supervision of limited OoD samples. Specifically, the generator explores OoD spaces and generates synthetic OoD samples using feedback from the discriminator, while the discriminator exploits both the observed and synthesized samples for OoD detection using a predefined Wasserstein score. We provide theoretical guarantees that the optimal solutions of our generative scheme are statistically achievable through adversarial training in empirical settings. We then demonstrate that the proposed method outperforms state-of-the-art techniques on various computer vision datasets and exhibits superior generalizability to unseen OoD data.
Memorization with neural nets: going beyond the worst case
Oct 12, 2023In practice, deep neural networks are often able to easily interpolate their training data. To understand this phenomenon, many works have aimed to quantify the memorization capacity of a neural network architecture: the largest number of points such that the architecture can interpolate any placement of these points with any assignment of labels. For real-world data, however, one intuitively expects the presence of a benign structure so that interpolation already occurs at a smaller network size than suggested by memorization capacity. In this paper, we investigate interpolation by adopting an instance-specific viewpoint. We introduce a simple randomized algorithm that, given a fixed finite dataset with two classes, with high probability constructs an interpolating three-layer neural network in polynomial time. The required number of parameters is linked to geometric properties of the two classes and their mutual arrangement. As a result, we obtain guarantees that are independent of the number of samples and hence move beyond worst-case memorization capacity bounds. We illustrate the effectiveness of the algorithm in non-pathological situations with extensive numerical experiments and link the insights back to the theoretical results.
Beyond Sharing: Conflict-Aware Multivariate Time Series Anomaly Detection
Aug 25, 2023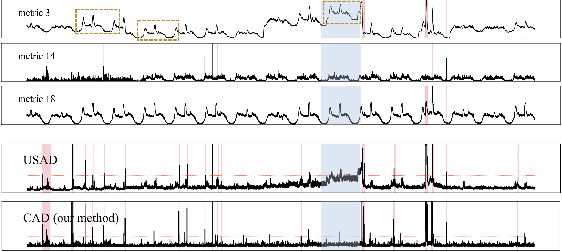
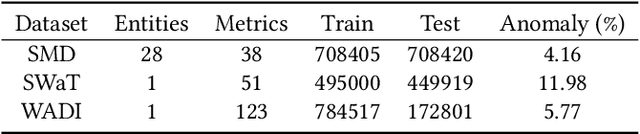
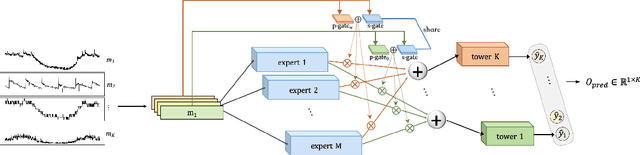
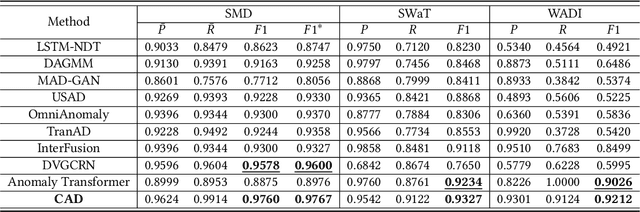
Massive key performance indicators (KPIs) are monitored as multivariate time series data (MTS) to ensure the reliability of the software applications and service system. Accurately detecting the abnormality of MTS is very critical for subsequent fault elimination. The scarcity of anomalies and manual labeling has led to the development of various self-supervised MTS anomaly detection (AD) methods, which optimize an overall objective/loss encompassing all metrics' regression objectives/losses. However, our empirical study uncovers the prevalence of conflicts among metrics' regression objectives, causing MTS models to grapple with different losses. This critical aspect significantly impacts detection performance but has been overlooked in existing approaches. To address this problem, by mimicking the design of multi-gate mixture-of-experts (MMoE), we introduce CAD, a Conflict-aware multivariate KPI Anomaly Detection algorithm. CAD offers an exclusive structure for each metric to mitigate potential conflicts while fostering inter-metric promotions. Upon thorough investigation, we find that the poor performance of vanilla MMoE mainly comes from the input-output misalignment settings of MTS formulation and convergence issues arising from expansive tasks. To address these challenges, we propose a straightforward yet effective task-oriented metric selection and p&s (personalized and shared) gating mechanism, which establishes CAD as the first practicable multi-task learning (MTL) based MTS AD model. Evaluations on multiple public datasets reveal that CAD obtains an average F1-score of 0.943 across three public datasets, notably outperforming state-of-the-art methods. Our code is accessible at https://github.com/dawnvince/MTS_CAD.
Generalized Benders Decomposition with Continual Learning for Hybrid Model Predictive Control in Dynamic Environment
Oct 10, 2023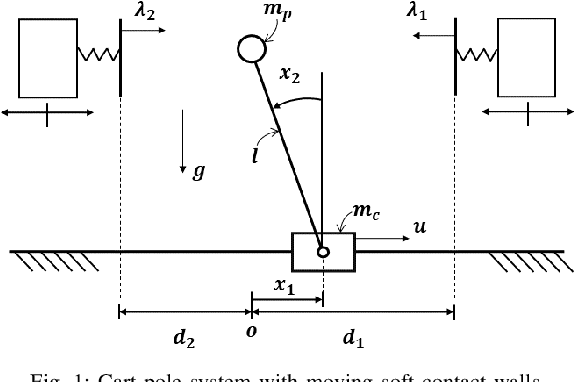
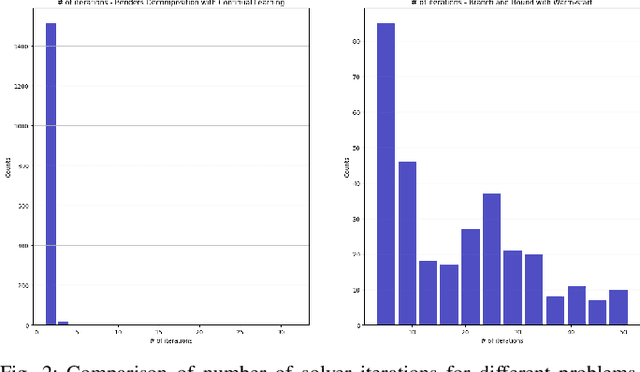
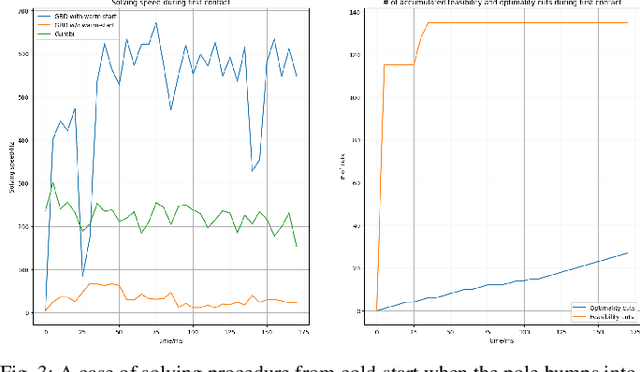
Hybrid model predictive control (MPC) with both continuous and discrete variables is widely applicable to robotic control tasks, especially those involving contact with the environment. Due to the combinatorial complexity, the solving speed of hybrid MPC can be insufficient for real-time applications. In this paper, we proposed a hybrid MPC solver based on Generalized Benders Decomposition (GBD) with continual learning. The algorithm accumulates cutting planes from the invariant dual space of the subproblems. After a short cold-start phase, the accumulated cuts provide warm-starts for the new problem instances to increase the solving speed. Despite the randomly changing environment that the control is unprepared for, the solving speed maintains. We verified our solver on controlling a cart-pole system with randomly moving soft contact walls and show that the solving speed is 2-3 times faster than the off-the-shelf solver Gurobi.
Precise Payload Delivery via Unmanned Aerial Vehicles: An Approach Using Object Detection Algorithms
Oct 10, 2023Recent years have seen tremendous advancements in the area of autonomous payload delivery via unmanned aerial vehicles, or drones. However, most of these works involve delivering the payload at a predetermined location using its GPS coordinates. By relying on GPS coordinates for navigation, the precision of payload delivery is restricted to the accuracy of the GPS network and the availability and strength of the GPS connection, which may be severely restricted by the weather condition at the time and place of operation. In this work we describe the development of a micro-class UAV and propose a novel navigation method that improves the accuracy of conventional navigation methods by incorporating a deep-learning-based computer vision approach to identify and precisely align the UAV with a target marked at the payload delivery position. This proposed method achieves a 500% increase in average horizontal precision over conventional GPS-based approaches.
Suppressing Overestimation in Q-Learning through Adversarial Behaviors
Oct 10, 2023
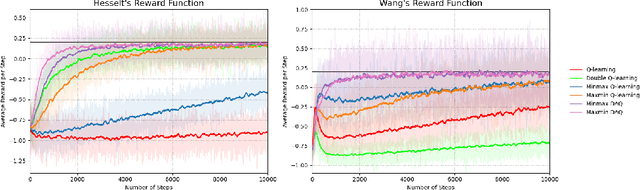
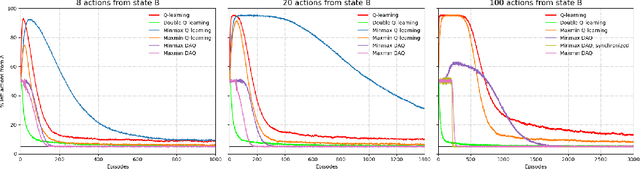
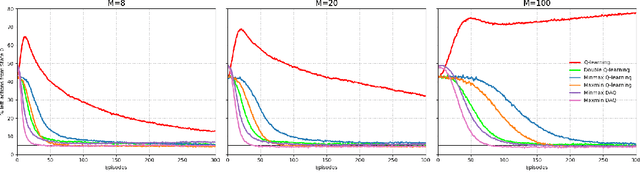
The goal of this paper is to propose a new Q-learning algorithm with a dummy adversarial player, which is called dummy adversarial Q-learning (DAQ), that can effectively regulate the overestimation bias in standard Q-learning. With the dummy player, the learning can be formulated as a two-player zero-sum game. The proposed DAQ unifies several Q-learning variations to control overestimation biases, such as maxmin Q-learning and minmax Q-learning (proposed in this paper) in a single framework. The proposed DAQ is a simple but effective way to suppress the overestimation bias thourgh dummy adversarial behaviors and can be easily applied to off-the-shelf reinforcement learning algorithms to improve the performances. A finite-time convergence of DAQ is analyzed from an integrated perspective by adapting an adversarial Q-learning. The performance of the suggested DAQ is empirically demonstrated under various benchmark environments.
Comparing the robustness of modern no-reference image- and video-quality metrics to adversarial attacks
Oct 10, 2023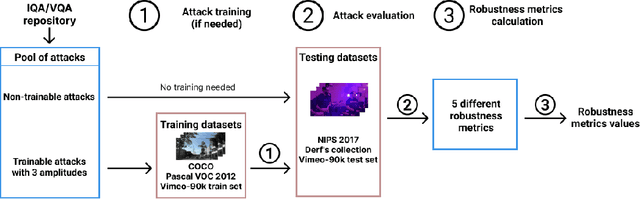
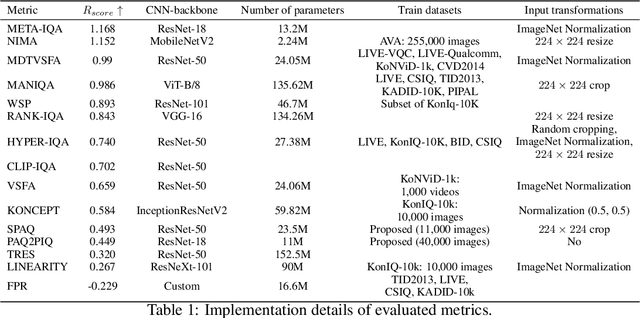
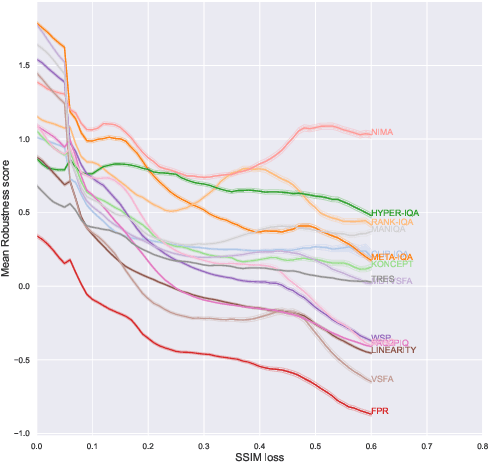
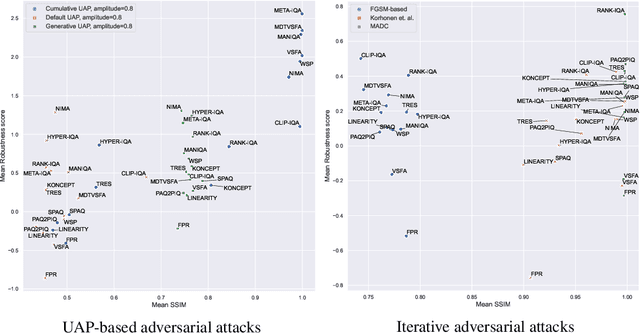
Nowadays neural-network-based image- and video-quality metrics show better performance compared to traditional methods. However, they also became more vulnerable to adversarial attacks that increase metrics' scores without improving visual quality. The existing benchmarks of quality metrics compare their performance in terms of correlation with subjective quality and calculation time. However, the adversarial robustness of image-quality metrics is also an area worth researching. In this paper, we analyse modern metrics' robustness to different adversarial attacks. We adopted adversarial attacks from computer vision tasks and compared attacks' efficiency against 15 no-reference image/video-quality metrics. Some metrics showed high resistance to adversarial attacks which makes their usage in benchmarks safer than vulnerable metrics. The benchmark accepts new metrics submissions for researchers who want to make their metrics more robust to attacks or to find such metrics for their needs. Try our benchmark using pip install robustness-benchmark.