 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Receive Filter Design for Misaligned Over-the-Air Computation
Sep 27, 2023
Over-the-air computation (OAC) is a promising wireless communication method for aggregating data from many devices in dense wireless networks. The fundamental idea of OAC is to exploit signal superposition to compute functions of multiple simultaneously transmitted signals. However, the time- and phase-alignment of these superimposed signals have a significant effect on the quality of function computation. In this study, we analyze the OAC problem for a system with unknown random time delays and phase shifts. We show that the classical matched filter does not produce optimal results, and generates bias in the function estimates. To counteract this, we propose a new filter design and show that, under a bound on the maximum time delay, it is possible to achieve unbiased function computation. Additionally, we propose a Tikhonov regularization problem that produces an optimal filter given a tradeoff between the bias and noise-induced variance of the function estimates. When the time delays are long compared to the length of the transmitted pulses, our filter vastly outperforms the matched filter both in terms of bias and mean-squared error (MSE). For shorter time delays, our proposal yields similar MSE as the matched filter, while reducing the bias.
3D Gaussian Splatting for Real-Time Radiance Field Rendering
Aug 08, 2023Radiance Field methods have recently revolutionized novel-view synthesis of scenes captured with multiple photos or videos. However, achieving high visual quality still requires neural networks that are costly to train and render, while recent faster methods inevitably trade off speed for quality. For unbounded and complete scenes (rather than isolated objects) and 1080p resolution rendering, no current method can achieve real-time display rates. We introduce three key elements that allow us to achieve state-of-the-art visual quality while maintaining competitive training times and importantly allow high-quality real-time (>= 30 fps) novel-view synthesis at 1080p resolution. First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that supports anisotropic splatting and both accelerates training and allows realtime rendering. We demonstrate state-of-the-art visual quality and real-time rendering on several established datasets.
* https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Towards Open-Set Test-Time Adaptation Utilizing the Wisdom of Crowds in Entropy Minimization
Sep 04, 2023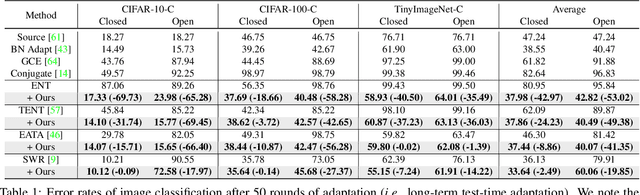
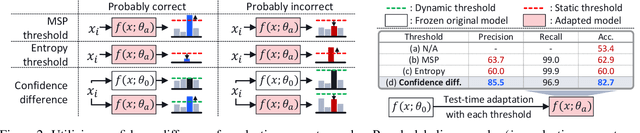
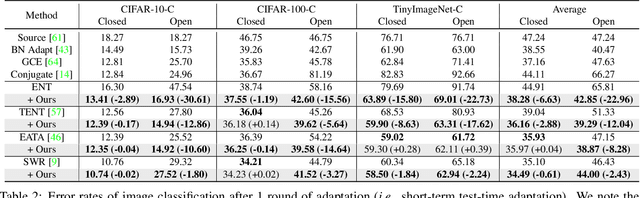
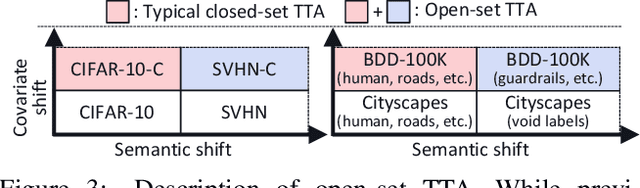
Test-time adaptation (TTA) methods, which generally rely on the model's predictions (e.g., entropy minimization) to adapt the source pretrained model to the unlabeled target domain, suffer from noisy signals originating from 1) incorrect or 2) open-set predictions. Long-term stable adaptation is hampered by such noisy signals, so training models without such error accumulation is crucial for practical TTA. To address these issues, including open-set TTA, we propose a simple yet effective sample selection method inspired by the following crucial empirical finding. While entropy minimization compels the model to increase the probability of its predicted label (i.e., confidence values), we found that noisy samples rather show decreased confidence values. To be more specific, entropy minimization attempts to raise the confidence values of an individual sample's prediction, but individual confidence values may rise or fall due to the influence of signals from numerous other predictions (i.e., wisdom of crowds). Due to this fact, noisy signals misaligned with such 'wisdom of crowds', generally found in the correct signals, fail to raise the individual confidence values of wrong samples, despite attempts to increase them. Based on such findings, we filter out the samples whose confidence values are lower in the adapted model than in the original model, as they are likely to be noisy. Our method is widely applicable to existing TTA methods and improves their long-term adaptation performance in both image classification (e.g., 49.4% reduced error rates with TENT) and semantic segmentation (e.g., 11.7% gain in mIoU with TENT).
T1/T2 relaxation temporal modelling from accelerated acquisitions using a Latent Transformer
Sep 28, 2023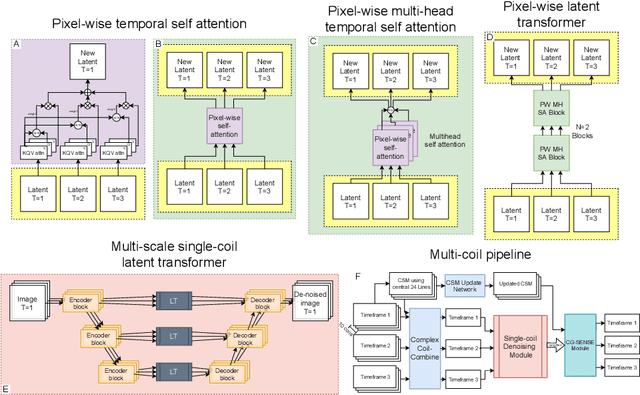
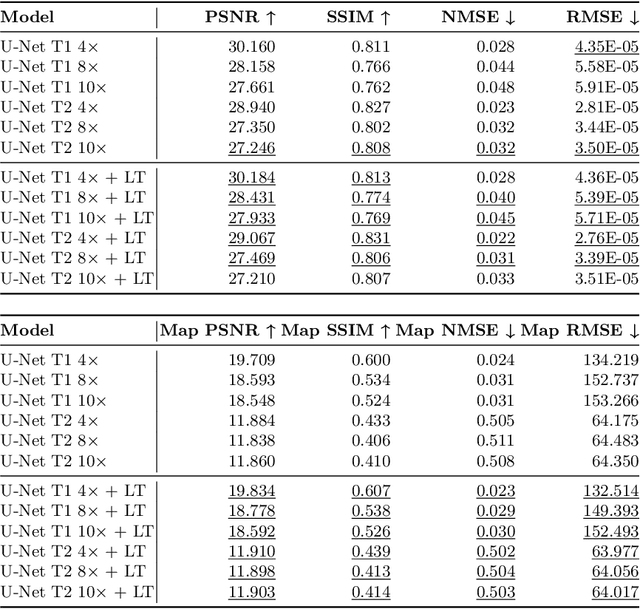
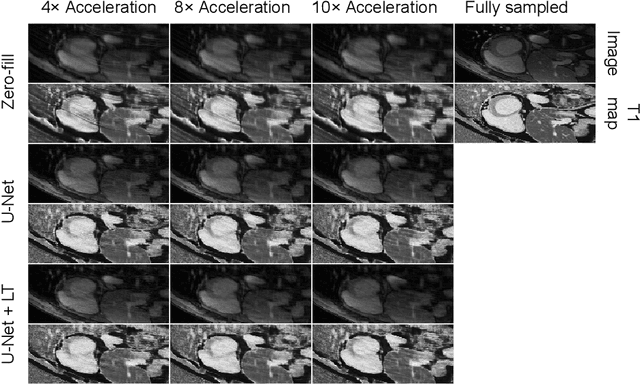
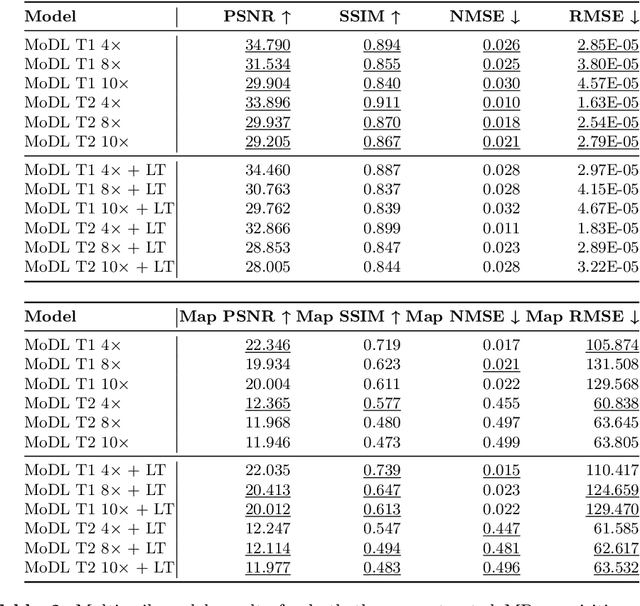
Quantitative cardiac magnetic resonance T1 and T2 mapping enable myocardial tissue characterisation but the lengthy scan times restrict their widespread clinical application. We propose a deep learning method that incorporates a time dependency Latent Transformer module to model relationships between parameterised time frames for improved reconstruction from undersampled data. The module, implemented as a multi-resolution sequence-to-sequence transformer, is integrated into an encoder-decoder architecture to leverage the inherent temporal correlations in relaxation processes. The presented results for accelerated T1 and T2 mapping show the model recovers maps with higher fidelity by explicit incorporation of time dynamics. This work demonstrates the importance of temporal modelling for artifact-free reconstruction in quantitative MRI.
Proving the Potential of Skeleton Based Action Recognition to Automate the Analysis of Manual Processes
Oct 12, 2023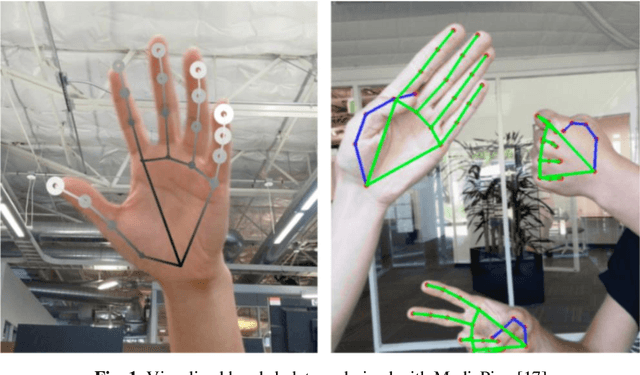

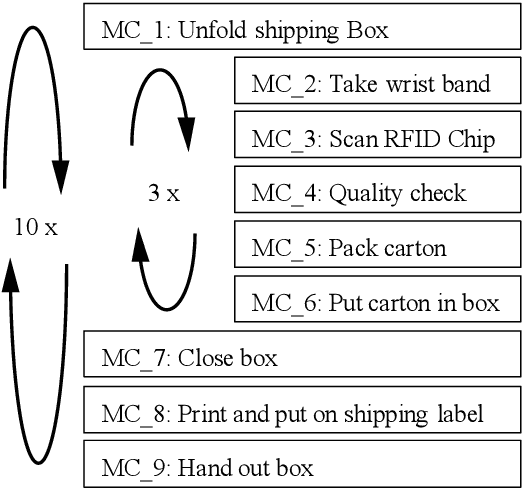
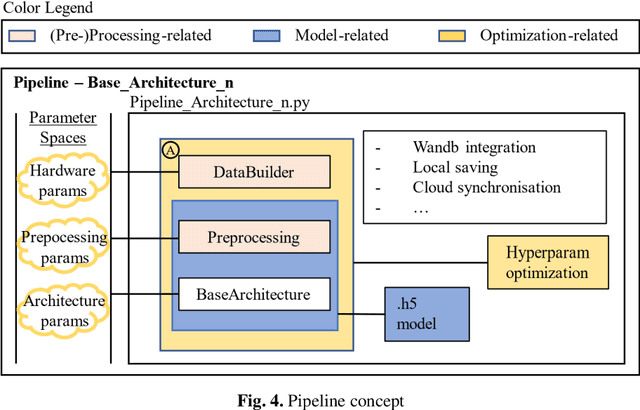
In manufacturing sectors such as textiles and electronics, manual processes are a fundamental part of production. The analysis and monitoring of the processes is necessary for efficient production design. Traditional methods for analyzing manual processes are complex, expensive, and inflexible. Compared to established approaches such as Methods-Time-Measurement (MTM), machine learning (ML) methods promise: Higher flexibility, self-sufficient & permanent use, lower costs. In this work, based on a video stream, the current motion class in a manual assembly process is detected. With information on the current motion, Key-Performance-Indicators (KPIs) can be derived easily. A skeleton-based action recognition approach is taken, as this field recently shows major success in machine vision tasks. For skeleton-based action recognition in manual assembly, no sufficient pre-work could be found. Therefore, a ML pipeline is developed, to enable extensive research on different (pre-) processing methods and neural nets. Suitable well generalizing approaches are found, proving the potential of ML to enhance analyzation of manual processes. Models detect the current motion, performed by an operator in manual assembly, but the results can be transferred to all kinds of manual processes.
Performance/power assessment of CNN packages on embedded automotive platforms
Oct 12, 2023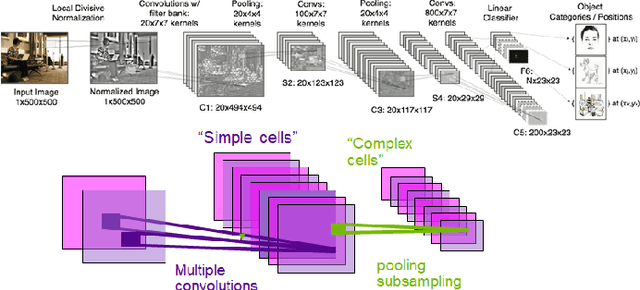
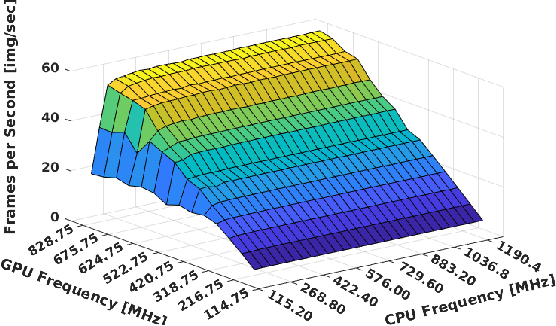
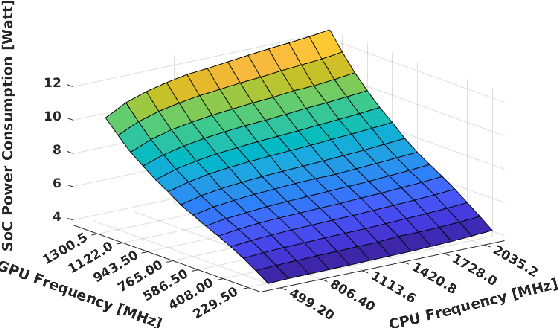
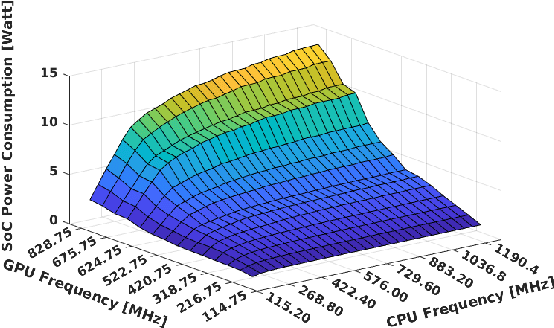
The rise of power-efficient embedded computers based on highly-parallel accelerators opens a number of opportunities and challenges for researchers and engineers, and paved the way to the era of edge computing. At the same time, advances in embedded AI for object detection and categorization such as YOLO, GoogleNet and AlexNet reached an unprecedented level of accuracy (mean-Average Precision - mAP) and performance (Frames-Per-Second - FPS). Today, edge computers based on heterogeneous many-core systems are a predominant choice to deploy such systems in industry 4.0, wearable devices, and - our focus - autonomous driving systems. In these latter systems, engineers struggle to make reduced automotive power and size budgets co-exist with the accuracy and performance targets requested by autonomous driving. We aim at validating the effectiveness and efficiency of most recent networks on state-of-the-art platforms with embedded commercial-off-the-shelf System-on-Chips, such as Xavier AGX, Tegra X2 and Nano for NVIDIA and XCZU9EG and XCZU3EG of the Zynq UltraScale+ family, for the Xilinx counterpart. Our work aims at supporting engineers in choosing the most appropriate CNN package and computing system for their designs, and deriving guidelines for adequately sizing their systems.
Beyond Traditional DoE: Deep Reinforcement Learning for Optimizing Experiments in Model Identification of Battery Dynamics
Oct 12, 2023
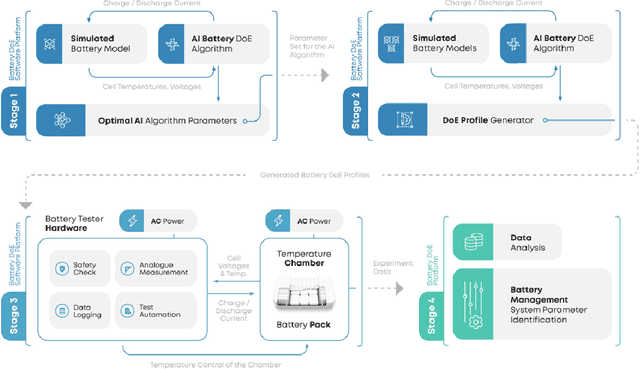
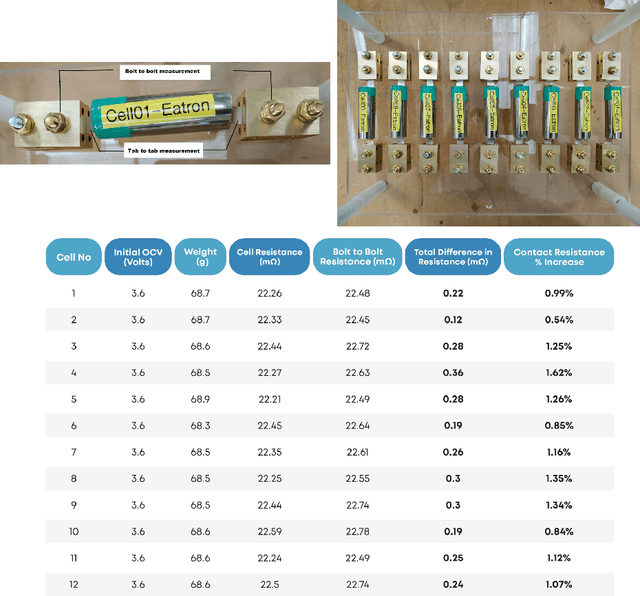
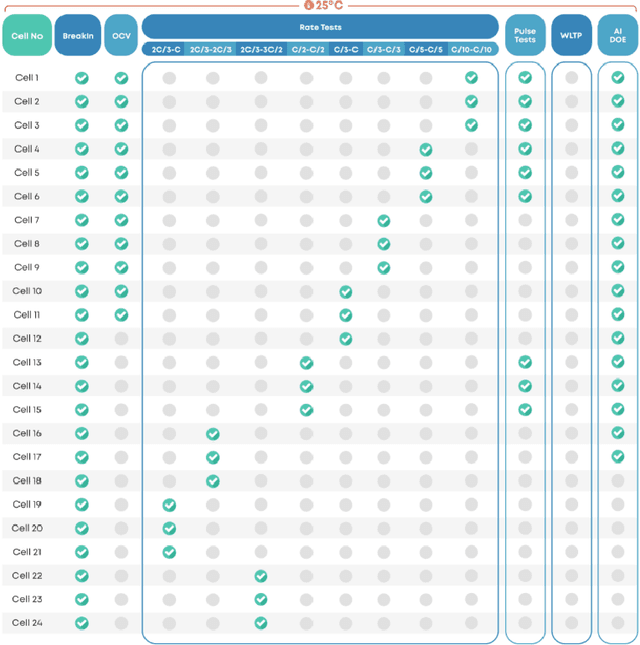
Model identification of battery dynamics is a central problem in energy research; many energy management systems and design processes rely on accurate battery models for efficiency optimization. The standard methodology for battery modelling is traditional design of experiments (DoE), where the battery dynamics are excited with many different current profiles and the measured outputs are used to estimate the system dynamics. However, although it is possible to obtain useful models with the traditional approach, the process is time consuming and expensive because of the need to sweep many different current-profile configurations. In the present work, a novel DoE approach is developed based on deep reinforcement learning, which alters the configuration of the experiments on the fly based on the statistics of past experiments. Instead of sticking to a library of predefined current profiles, the proposed approach modifies the current profiles dynamically by updating the output space covered by past measurements, hence only the current profiles that are informative for future experiments are applied. Simulations and real experiments are used to show that the proposed approach gives models that are as accurate as those obtained with traditional DoE but by using 85\% less resources.
Crowdsourced and Automatic Speech Prominence Estimation
Oct 12, 2023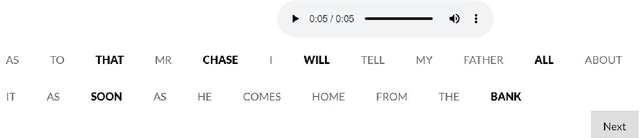
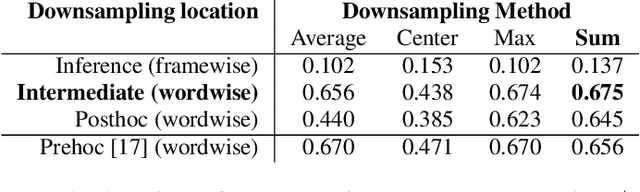
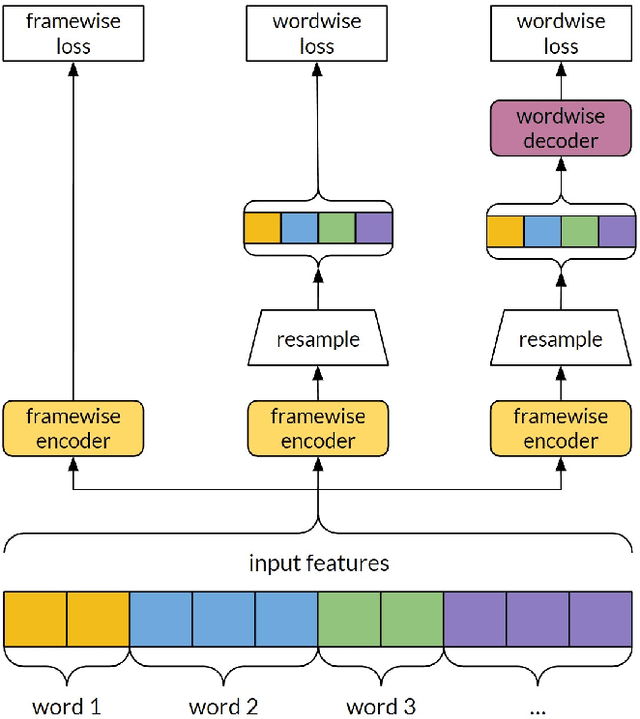
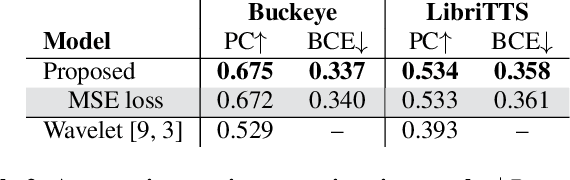
The prominence of a spoken word is the degree to which an average native listener perceives the word as salient or emphasized relative to its context. Speech prominence estimation is the process of assigning a numeric value to the prominence of each word in an utterance. These prominence labels are useful for linguistic analysis, as well as training automated systems to perform emphasis-controlled text-to-speech or emotion recognition. Manually annotating prominence is time-consuming and expensive, which motivates the development of automated methods for speech prominence estimation. However, developing such an automated system using machine-learning methods requires human-annotated training data. Using our system for acquiring such human annotations, we collect and open-source crowdsourced annotations of a portion of the LibriTTS dataset. We use these annotations as ground truth to train a neural speech prominence estimator that generalizes to unseen speakers, datasets, and speaking styles. We investigate design decisions for neural prominence estimation as well as how neural prominence estimation improves as a function of two key factors of annotation cost: dataset size and the number of annotations per utterance.
Understanding the Humans Behind Online Misinformation: An Observational Study Through the Lens of the COVID-19 Pandemic
Oct 12, 2023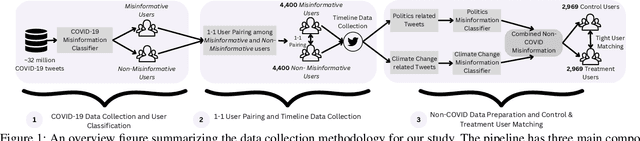
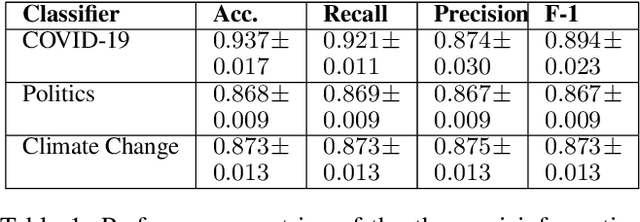
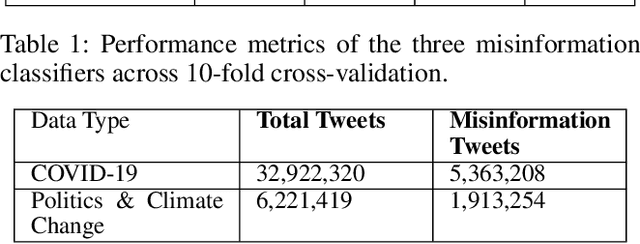

The proliferation of online misinformation has emerged as one of the biggest threats to society. Considerable efforts have focused on building misinformation detection models, still the perils of misinformation remain abound. Mitigating online misinformation and its ramifications requires a holistic approach that encompasses not only an understanding of its intricate landscape in relation to the complex issue and topic-rich information ecosystem online, but also the psychological drivers of individuals behind it. Adopting a time series analytic technique and robust causal inference-based design, we conduct a large-scale observational study analyzing over 32 million COVID-19 tweets and 16 million historical timeline tweets. We focus on understanding the behavior and psychology of users disseminating misinformation during COVID-19 and its relationship with the historical inclinations towards sharing misinformation on Non-COVID topics before the pandemic. Our analysis underscores the intricacies inherent to cross-topic misinformation, and highlights that users' historical inclination toward sharing misinformation is positively associated with their present behavior pertaining to misinformation sharing on emergent topics and beyond. This work may serve as a valuable foundation for designing user-centric inoculation strategies and ecologically-grounded agile interventions for effectively tackling online misinformation.
MUN-FRL: A Visual Inertial LiDAR Dataset for Aerial Autonomous Navigation and Mapping
Oct 12, 2023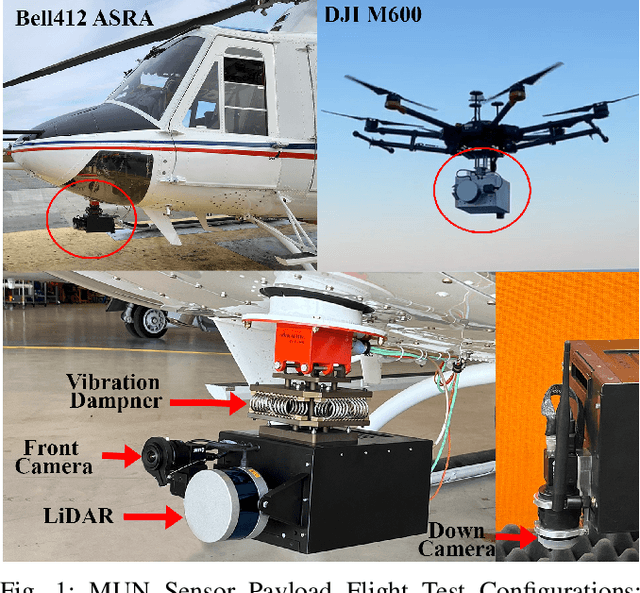
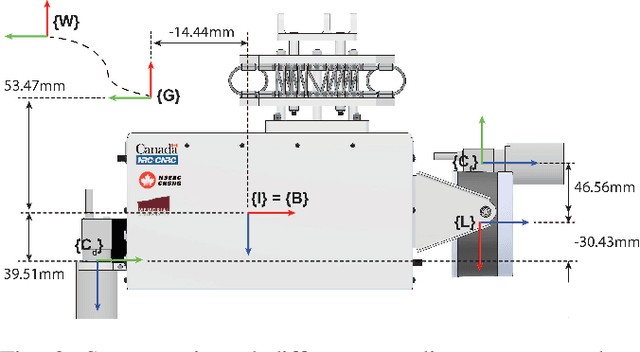
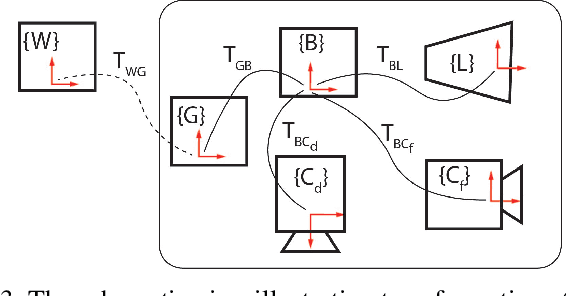

This paper presents a unique outdoor aerial visual-inertial-LiDAR dataset captured using a multi-sensor payload to promote the global navigation satellite system (GNSS)-denied navigation research. The dataset features flight distances ranging from 300m to 5km, collected using a DJI M600 hexacopter drone and the National Research Council (NRC) Bell 412 Advanced Systems Research Aircraft (ASRA). The dataset consists of hardware synchronized monocular images, IMU measurements, 3D LiDAR point-clouds, and high-precision real-time kinematic (RTK)-GNSS based ground truth. Ten datasets were collected as ROS bags over 100 mins of outdoor environment footage ranging from urban areas, highways, hillsides, prairies, and waterfronts. The datasets were collected to facilitate the development of visual-inertial-LiDAR odometry and mapping algorithms, visual-inertial navigation algorithms, object detection, segmentation, and landing zone detection algorithms based upon real-world drone and full-scale helicopter data. All the datasets contain raw sensor measurements, hardware timestamps, and spatio-temporally aligned ground truth. The intrinsic and extrinsic calibrations of the sensors are also provided along with raw calibration datasets. A performance summary of state-of-the-art methods applied on the datasets is also provided.