 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Fisher-Rao gradient flow for entropy-regularised Markov decision processes in Polish spaces
Oct 04, 2023
We study the global convergence of a Fisher-Rao policy gradient flow for infinite-horizon entropy-regularised Markov decision processes with Polish state and action space. The flow is a continuous-time analogue of a policy mirror descent method. We establish the global well-posedness of the gradient flow and demonstrate its exponential convergence to the optimal policy. Moreover, we prove the flow is stable with respect to gradient evaluation, offering insights into the performance of a natural policy gradient flow with log-linear policy parameterisation. To overcome challenges stemming from the lack of the convexity of the objective function and the discontinuity arising from the entropy regulariser, we leverage the performance difference lemma and the duality relationship between the gradient and mirror descent flows.
Speech-Based Human-Exoskeleton Interaction for Lower Limb Motion Planning
Oct 04, 2023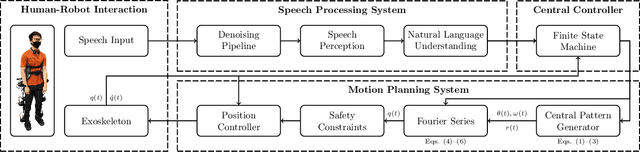

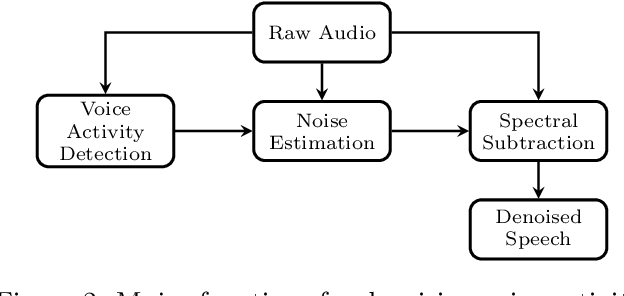
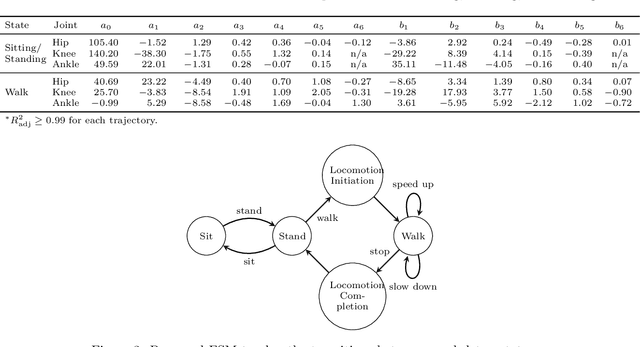
This study presents a speech-based motion planning strategy (SBMP) developed for lower limb exoskeletons to facilitate safe and compliant human-robot interaction. A speech processing system, finite state machine, and central pattern generator are the building blocks of the proposed strategy for online planning of the exoskeleton's trajectory. According to experimental evaluations, this speech-processing system achieved low levels of word and intent errors. Regarding locomotion, the completion time for users with voice commands was 54% faster than that using a mobile app interface. With the proposed SBMP, users are able to maintain their postural stability with both hands-free. This supports its use as an effective motion planning method for the assistance and rehabilitation of individuals with lower-limb impairments.
Provably Efficient Exploration in Constrained Reinforcement Learning:Posterior Sampling Is All You Need
Sep 27, 2023We present a new algorithm based on posterior sampling for learning in constrained Markov decision processes (CMDP) in the infinite-horizon undiscounted setting. The algorithm achieves near-optimal regret bounds while being advantageous empirically compared to the existing algorithms. Our main theoretical result is a Bayesian regret bound for each cost component of \tilde{O} (HS \sqrt{AT}) for any communicating CMDP with S states, A actions, and bound on the hitting time H. This regret bound matches the lower bound in order of time horizon T and is the best-known regret bound for communicating CMDPs in the infinite-horizon undiscounted setting. Empirical results show that, despite its simplicity, our posterior sampling algorithm outperforms the existing algorithms for constrained reinforcement learning.
Statistical Hypothesis Testing for Information Value (IV)
Sep 30, 2023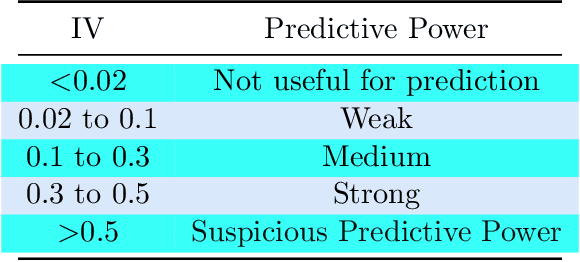
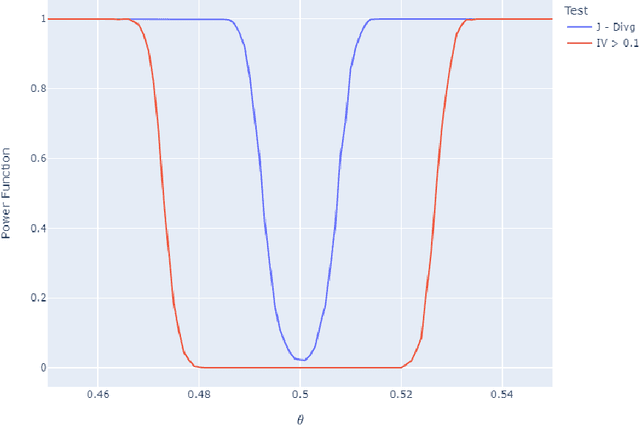
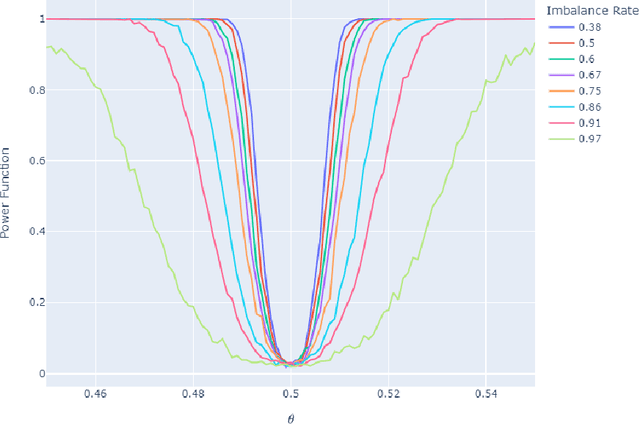

Information value (IV) is a quite popular technique for features selection before the modeling phase. There are practical criteria, based on fixed thresholds for IV, but at the same time mysterious and lacking theoretical arguments, to decide if a predictor has sufficient predictive power to be considered in the modeling phase. However, the mathematical development and statistical inference methods for this technique are almost nonexistent in the literature. In this paper we present a theoretical framework for IV, and at the same time, we propose a non-parametric hypothesis test to evaluate the predictive power of features contemplated in a data set. Due to its relationship with divergence measures developed in the Information Theory, we call our proposal the J - Divergence test. We show how to efficiently compute our test statistic and we study its performance on simulated data. In various scenarios, particularly in unbalanced data sets, we show its superiority over conventional criteria based on fixed thresholds. Furthermore, we apply our test on fraud identification data and provide an open-source Python library, called "statistical-iv"(https://pypi.org/project/statistical-iv/), where we implement our main results.
Multivariate Time Series Anomaly Detection: Fancy Algorithms and Flawed Evaluation Methodology
Aug 24, 2023Multivariate Time Series (MVTS) anomaly detection is a long-standing and challenging research topic that has attracted tremendous research effort from both industry and academia recently. However, a careful study of the literature makes us realize that 1) the community is active but not as organized as other sibling machine learning communities such as Computer Vision (CV) and Natural Language Processing (NLP), and 2) most proposed solutions are evaluated using either inappropriate or highly flawed protocols, with an apparent lack of scientific foundation. So flawed is one very popular protocol, the so-called \pa protocol, that a random guess can be shown to systematically outperform \emph{all} algorithms developed so far. In this paper, we review and evaluate many recent algorithms using more robust protocols and discuss how a normally good protocol may have weaknesses in the context of MVTS anomaly detection and how to mitigate them. We also share our concerns about benchmark datasets, experiment design and evaluation methodology we observe in many works. Furthermore, we propose a simple, yet challenging, baseline algorithm based on Principal Components Analysis (PCA) that surprisingly outperforms many recent Deep Learning (DL) based approaches on popular benchmark datasets. The main objective of this work is to stimulate more effort towards important aspects of the research such as data, experiment design, evaluation methodology and result interpretability, instead of putting the highest weight on the design of increasingly more complex and "fancier" algorithms.
Automated Construction of Time-Space Diagrams for Traffic Analysis Using Street-View Video Sequence
Aug 11, 2023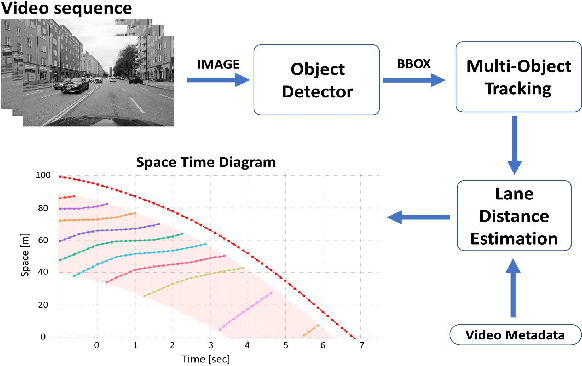

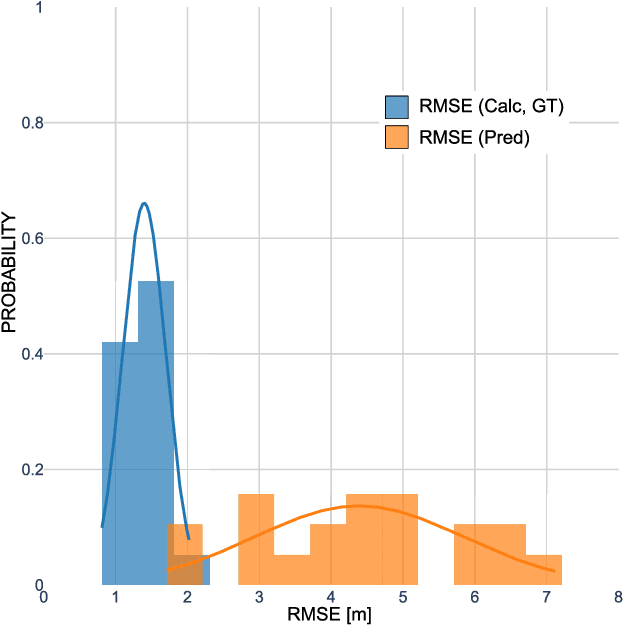
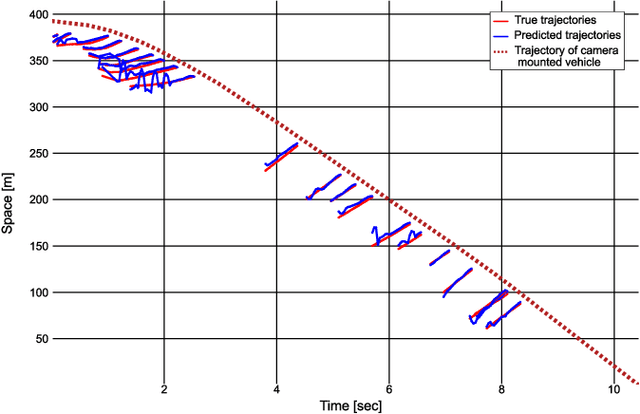
Time-space diagrams are essential tools for analyzing traffic patterns and optimizing transportation infrastructure and traffic management strategies. Traditional data collection methods for these diagrams have limitations in terms of temporal and spatial coverage. Recent advancements in camera technology have overcome these limitations and provided extensive urban data. In this study, we propose an innovative approach to constructing time-space diagrams by utilizing street-view video sequences captured by cameras mounted on moving vehicles. Using the state-of-the-art YOLOv5, StrongSORT, and photogrammetry techniques for distance calculation, we can infer vehicle trajectories from the video data and generate time-space diagrams. To evaluate the effectiveness of our proposed method, we utilized datasets from the KITTI computer vision benchmark suite. The evaluation results demonstrate that our approach can generate trajectories from video data, although there are some errors that can be mitigated by improving the performance of the detector, tracker, and distance calculation components. In conclusion, the utilization of street-view video sequences captured by cameras mounted on moving vehicles, combined with state-of-the-art computer vision techniques, has immense potential for constructing comprehensive time-space diagrams. These diagrams offer valuable insights into traffic patterns and contribute to the design of transportation infrastructure and traffic management strategies.
Digital Twin Assisted Deep Reinforcement Learning for Online Optimization of Network Slicing Admission Control
Oct 07, 2023The proliferation of diverse network services in 5G and beyond networks has led to the emergence of network slicing technologies. Among these, admission control plays a crucial role in achieving specific optimization goals through the selective acceptance of service requests. Although Deep Reinforcement Learning (DRL) forms the foundation in many admission control approaches for its effectiveness and flexibility, the initial instability of DRL models hinders their practical deployment in real-world networks. In this work, we propose a digital twin (DT) assisted DRL solution to address this issue. Specifically, we first formulate the admission decision-making process as a semi-Markov decision process, which is subsequently simplified into an equivalent discrete-time Markov decision process to facilitate the implementation of DRL methods. The DT is established through supervised learning and employed to assist the training phase of the DRL model. Extensive simulations show that the DT-assisted DRL model increased resource utilization by over 40\% compared to the directly trained state-of-the-art Dueling-DQN and over 20\% compared to our directly trained DRL model during initial training. This improvement is achieved while preserving the model's capacity to optimize the long-term rewards.
Optimal Sequential Decision-Making in Geosteering: A Reinforcement Learning Approach
Oct 07, 2023Trajectory adjustment decisions throughout the drilling process, called geosteering, affect subsequent choices and information gathering, thus resulting in a coupled sequential decision problem. Previous works on applying decision optimization methods in geosteering rely on greedy optimization or Approximate Dynamic Programming (ADP). Either decision optimization method requires explicit uncertainty and objective function models, making developing decision optimization methods for complex and realistic geosteering environments challenging to impossible. We use the Deep Q-Network (DQN) method, a model-free reinforcement learning (RL) method that learns directly from the decision environment, to optimize geosteering decisions. The expensive computations for RL are handled during the offline training stage. Evaluating DQN needed for real-time decision support takes milliseconds and is faster than the traditional alternatives. Moreover, for two previously published synthetic geosteering scenarios, our results show that RL achieves high-quality outcomes comparable to the quasi-optimal ADP. Yet, the model-free nature of RL means that by replacing the training environment, we can extend it to problems where the solution to ADP is prohibitively expensive to compute. This flexibility will allow applying it to more complex environments and make hybrid versions trained with real data in the future.
GradXKG: A Universal Explain-per-use Temporal Knowledge Graph Explainer
Oct 07, 2023Temporal knowledge graphs (TKGs) have shown promise for reasoning tasks by incorporating a temporal dimension to represent how facts evolve over time. However, existing TKG reasoning (TKGR) models lack explainability due to their black-box nature. Recent work has attempted to address this through customized model architectures that generate reasoning paths, but these recent approaches have limited generalizability and provide sparse explanatory output. To enable interpretability for most TKGR models, we propose GradXKG, a novel two-stage gradient-based approach for explaining Relational Graph Convolution Network (RGCN)-based TKGR models. First, a Grad-CAM-inspired RGCN explainer tracks gradients to quantify each node's contribution across timesteps in an efficient "explain-per-use" fashion. Second, an integrated gradients explainer consolidates importance scores for RGCN outputs, extending compatibility across diverse TKGR architectures based on RGCN. Together, the two explainers highlight the most critical nodes at each timestep for a given prediction. Our extensive experiments demonstrated that, by leveraging gradient information, GradXKG provides insightful explanations grounded in the model's logic in a timely manner for most RGCN-based TKGR models. This helps address the lack of interpretability in existing TKGR models and provides a universal explanation approach applicable across various models.
Score-based Diffusion Models With Self-supervised Learning For Accelerated 3D Multi-contrast Cardiac Magnetic Resonance Imaging
Oct 07, 2023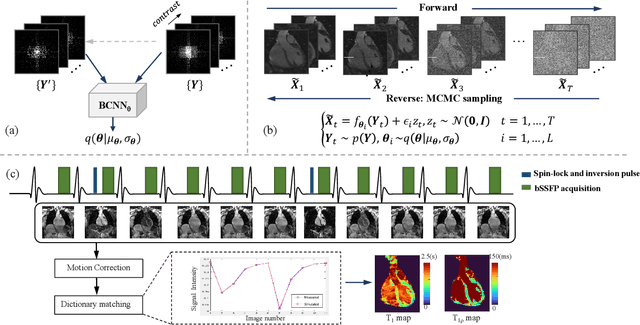
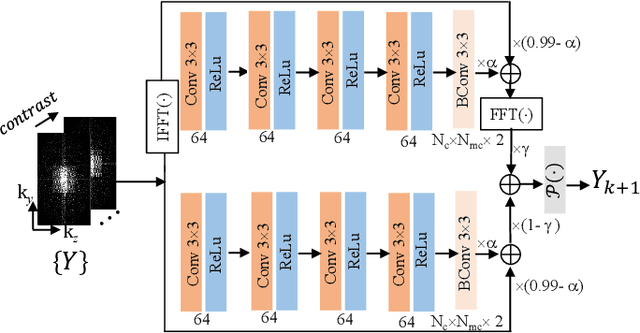
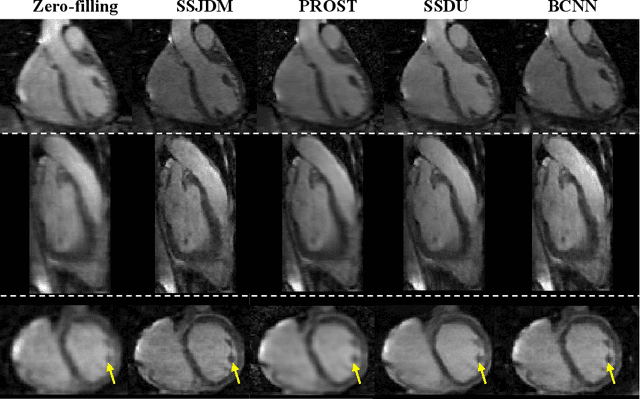
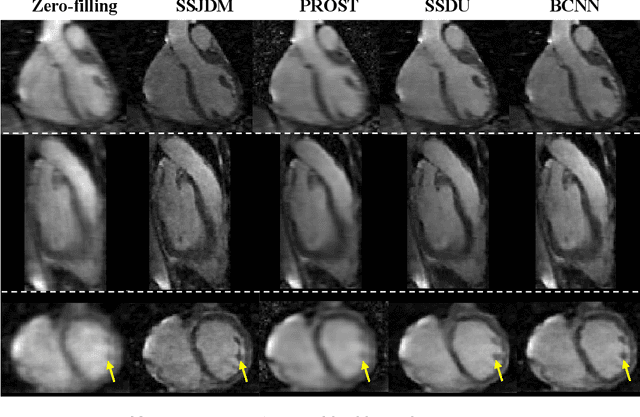
Long scan time significantly hinders the widespread applications of three-dimensional multi-contrast cardiac magnetic resonance (3D-MC-CMR) imaging. This study aims to accelerate 3D-MC-CMR acquisition by a novel method based on score-based diffusion models with self-supervised learning. Specifically, we first establish a mapping between the undersampled k-space measurements and the MR images, utilizing a self-supervised Bayesian reconstruction network. Secondly, we develop a joint score-based diffusion model on 3D-MC-CMR images to capture their inherent distribution. The 3D-MC-CMR images are finally reconstructed using the conditioned Langenvin Markov chain Monte Carlo sampling. This approach enables accurate reconstruction without fully sampled training data. Its performance was tested on the dataset acquired by a 3D joint myocardial T1 and T1rho mapping sequence. The T1 and T1rho maps were estimated via a dictionary matching method from the reconstructed images. Experimental results show that the proposed method outperforms traditional compressed sensing and existing self-supervised deep learning MRI reconstruction methods. It also achieves high quality T1 and T1rho parametric maps close to the reference maps obtained by traditional mapping sequences, even at a high acceleration rate of 14.