 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
To Build Our Future, We Must Know Our Past: Contextualizing Paradigm Shifts in Natural Language Processing
Oct 11, 2023
NLP is in a period of disruptive change that is impacting our methodologies, funding sources, and public perception. In this work, we seek to understand how to shape our future by better understanding our past. We study factors that shape NLP as a field, including culture, incentives, and infrastructure by conducting long-form interviews with 26 NLP researchers of varying seniority, research area, institution, and social identity. Our interviewees identify cyclical patterns in the field, as well as new shifts without historical parallel, including changes in benchmark culture and software infrastructure. We complement this discussion with quantitative analysis of citation, authorship, and language use in the ACL Anthology over time. We conclude by discussing shared visions, concerns, and hopes for the future of NLP. We hope that this study of our field's past and present can prompt informed discussion of our community's implicit norms and more deliberate action to consciously shape the future.
Are GATs Out of Balance?
Oct 11, 2023While the expressive power and computational capabilities of graph neural networks (GNNs) have been theoretically studied, their optimization and learning dynamics, in general, remain largely unexplored. Our study undertakes the Graph Attention Network (GAT), a popular GNN architecture in which a node's neighborhood aggregation is weighted by parameterized attention coefficients. We derive a conservation law of GAT gradient flow dynamics, which explains why a high portion of parameters in GATs with standard initialization struggle to change during training. This effect is amplified in deeper GATs, which perform significantly worse than their shallow counterparts. To alleviate this problem, we devise an initialization scheme that balances the GAT network. Our approach i) allows more effective propagation of gradients and in turn enables trainability of deeper networks, and ii) attains a considerable speedup in training and convergence time in comparison to the standard initialization. Our main theorem serves as a stepping stone to studying the learning dynamics of positive homogeneous models with attention mechanisms.
AI/ML-based Load Prediction in IEEE 802.11 Enterprise Networks
Oct 11, 2023Enterprise Wi-Fi networks can greatly benefit from Artificial Intelligence and Machine Learning (AI/ML) thanks to their well-developed management and operation capabilities. At the same time, AI/ML-based traffic/load prediction is one of the most appealing data-driven solutions to improve the Wi-Fi experience, either through the enablement of autonomous operation or by boosting troubleshooting with forecasted network utilization. In this paper, we study the suitability and feasibility of adopting AI/ML-based load prediction in practical enterprise Wi-Fi networks. While leveraging AI/ML solutions can potentially contribute to optimizing Wi-Fi networks in terms of energy efficiency, performance, and reliability, their effective adoption is constrained to aspects like data availability and quality, computational capabilities, and energy consumption. Our results show that hardware-constrained AI/ML models can potentially predict network load with less than 20% average error and 3% 85th-percentile error, which constitutes a suitable input for proactively driving Wi-Fi network optimization.
Magnitude-and-phase-aware Speech Enhancement with Parallel Sequence Modeling
Oct 11, 2023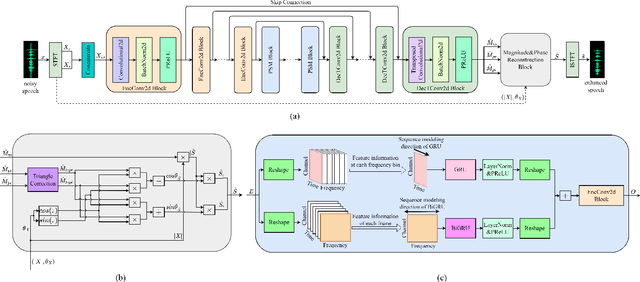
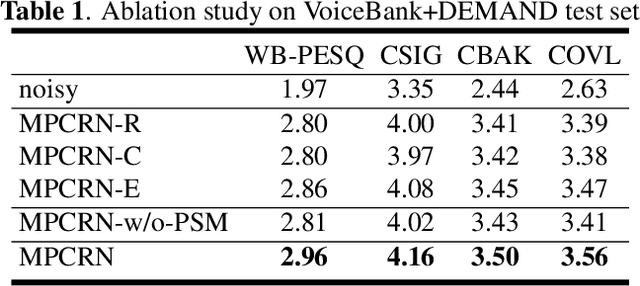
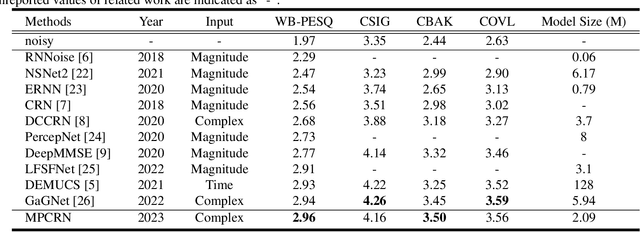
In speech enhancement (SE), phase estimation is important for perceptual quality, so many methods take clean speech's complex short-time Fourier transform (STFT) spectrum or the complex ideal ratio mask (cIRM) as the learning target. To predict these complex targets, the common solution is to design a complex neural network, or use a real network to separately predict the real and imaginary parts of the target. But in this paper, we propose to use a real network to estimate the magnitude mask and normalized cIRM, which not only avoids the significant increase of the model complexity caused by complex networks, but also shows better performance than previous phase estimation methods. Meanwhile, we devise a parallel sequence modeling (PSM) block to improve the RNN block in the convolutional recurrent network (CRN)-based SE model. We name our method as magnitude-and-phase-aware and PSM-based CRN (MPCRN). The experimental results illustrate that our MPCRN has superior SE performance.
Active Learning with Dual Model Predictive Path-Integral Control for Interaction-Aware Autonomous Highway On-ramp Merging
Oct 11, 2023Merging into dense highway traffic for an autonomous vehicle is a complex decision-making task, wherein the vehicle must identify a potential gap and coordinate with surrounding human drivers, each of whom may exhibit diverse driving behaviors. Many existing methods consider other drivers to be dynamic obstacles and, as a result, are incapable of capturing the full intent of the human drivers via this passive planning. In this paper, we propose a novel dual control framework based on Model Predictive Path-Integral control to generate interactive trajectories. This framework incorporates a Bayesian inference approach to actively learn the agents' parameters, i.e., other drivers' model parameters. The proposed framework employs a sampling-based approach that is suitable for real-time implementation through the utilization of GPUs. We illustrate the effectiveness of our proposed methodology through comprehensive numerical simulations conducted in both high and low-fidelity simulation scenarios focusing on autonomous on-ramp merging.
DomainAdaptor: A Novel Approach to Test-time Adaptation
Aug 20, 2023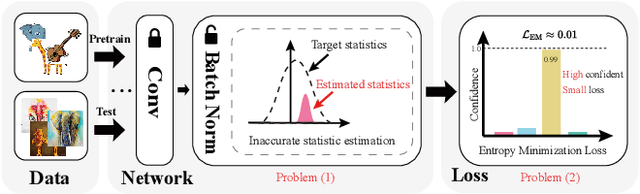
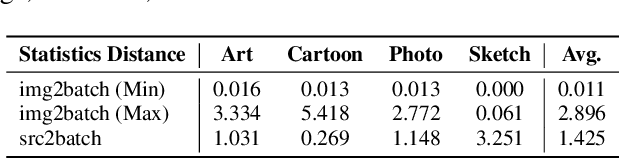

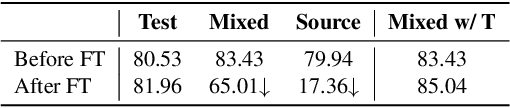
To deal with the domain shift between training and test samples, current methods have primarily focused on learning generalizable features during training and ignore the specificity of unseen samples that are also critical during the test. In this paper, we investigate a more challenging task that aims to adapt a trained CNN model to unseen domains during the test. To maximumly mine the information in the test data, we propose a unified method called DomainAdaptor for the test-time adaptation, which consists of an AdaMixBN module and a Generalized Entropy Minimization (GEM) loss. Specifically, AdaMixBN addresses the domain shift by adaptively fusing training and test statistics in the normalization layer via a dynamic mixture coefficient and a statistic transformation operation. To further enhance the adaptation ability of AdaMixBN, we design a GEM loss that extends the Entropy Minimization loss to better exploit the information in the test data. Extensive experiments show that DomainAdaptor consistently outperforms the state-of-the-art methods on four benchmarks. Furthermore, our method brings more remarkable improvement against existing methods on the few-data unseen domain. The code is available at https://github.com/koncle/DomainAdaptor.
Transformer-based Multimodal Change Detection with Multitask Consistency Constraints
Oct 13, 2023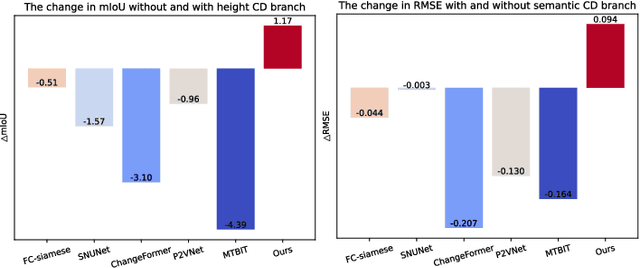
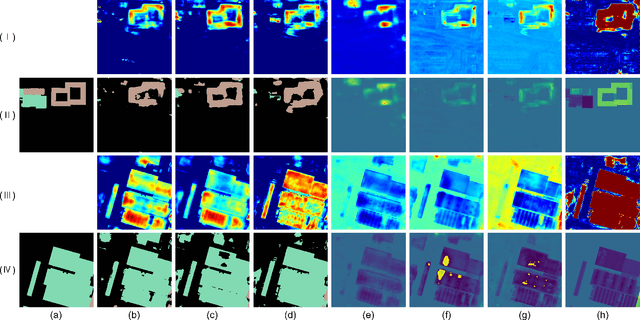

Change detection plays a fundamental role in Earth observation for analyzing temporal iterations over time. However, recent studies have largely neglected the utilization of multimodal data that presents significant practical and technical advantages compared to single-modal approaches. This research focuses on leveraging digital surface model (DSM) data and aerial images captured at different times for detecting change beyond 2D. We observe that the current change detection methods struggle with the multitask conflicts between semantic and height change detection tasks. To address this challenge, we propose an efficient Transformer-based network that learns shared representation between cross-dimensional inputs through cross-attention. It adopts a consistency constraint to establish the multimodal relationship, which involves obtaining pseudo change through height change thresholding and minimizing the difference between semantic and pseudo change within their overlapping regions. A DSM-to-image multimodal dataset encompassing three cities in the Netherlands was constructed. It lays a new foundation for beyond-2D change detection from cross-dimensional inputs. Compared to five state-of-the-art change detection methods, our model demonstrates consistent multitask superiority in terms of semantic and height change detection. Furthermore, the consistency strategy can be seamlessly adapted to the other methods, yielding promising improvements.
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Oct 13, 2023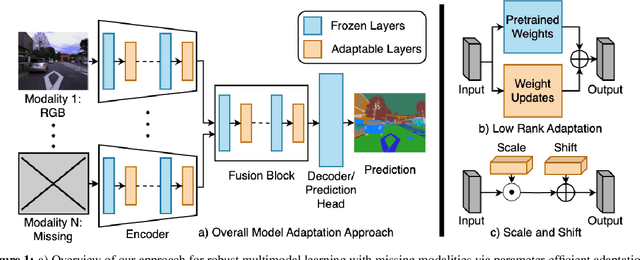
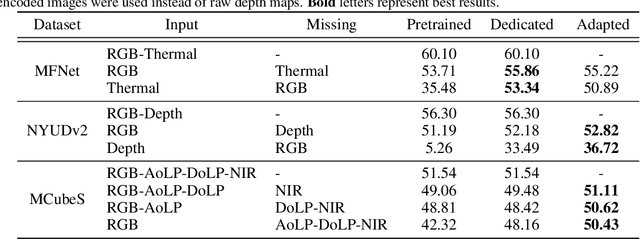
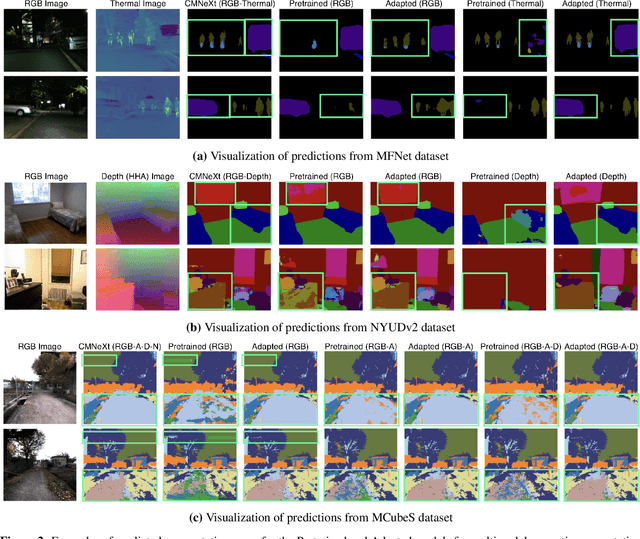
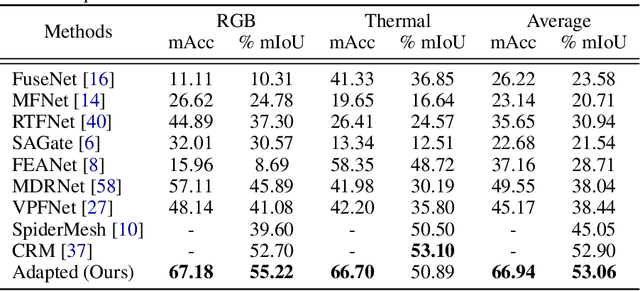
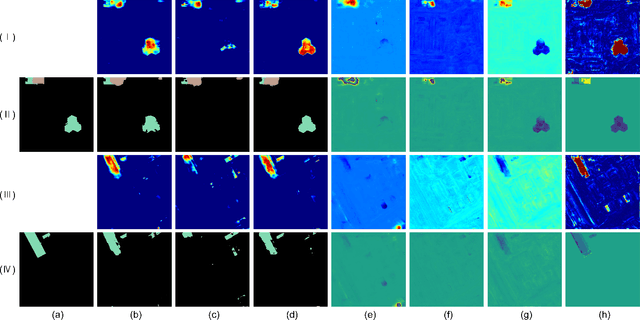
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose simple and parameter-efficient adaptation procedures for pretrained multimodal networks. In particular, we exploit low-rank adaptation and modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 0.7% of the total parameters in most experiments). We conduct a series of experiments to highlight the robustness of our proposed method using diverse datasets for RGB-thermal and RGB-Depth semantic segmentation, multimodal material segmentation, and multimodal sentiment analysis tasks. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Transformer-based Autoencoder with ID Constraint for Unsupervised Anomalous Sound Detection
Oct 13, 2023Unsupervised anomalous sound detection (ASD) aims to detect unknown anomalous sounds of devices when only normal sound data is available. The autoencoder (AE) and self-supervised learning based methods are two mainstream methods. However, the AE-based methods could be limited as the feature learned from normal sounds can also fit with anomalous sounds, reducing the ability of the model in detecting anomalies from sound. The self-supervised methods are not always stable and perform differently, even for machines of the same type. In addition, the anomalous sound may be short-lived, making it even harder to distinguish from normal sound. This paper proposes an ID constrained Transformer-based autoencoder (IDC-TransAE) architecture with weighted anomaly score computation for unsupervised ASD. Machine ID is employed to constrain the latent space of the Transformer-based autoencoder (TransAE) by introducing a simple ID classifier to learn the difference in the distribution for the same machine type and enhance the ability of the model in distinguishing anomalous sound. Moreover, weighted anomaly score computation is introduced to highlight the anomaly scores of anomalous events that only appear for a short time. Experiments performed on DCASE 2020 Challenge Task2 development dataset demonstrate the effectiveness and superiority of our proposed method.
Faster 3D cardiac CT segmentation with Vision Transformers
Oct 13, 2023Accurate segmentation of the heart is essential for personalized blood flow simulations and surgical intervention planning. A recent advancement in image recognition is the Vision Transformer (ViT), which expands the field of view to encompass a greater portion of the global image context. We adapted ViT for three-dimensional volume inputs. Cardiac computed tomography (CT) volumes from 39 patients, featuring up to 20 timepoints representing the complete cardiac cycle, were utilized. Our network incorporates a modified ResNet50 block as well as a ViT block and employs cascade upsampling with skip connections. Despite its increased model complexity, our hybrid Transformer-Residual U-Net framework, termed TRUNet, converges in significantly less time than residual U-Net while providing comparable or superior segmentations of the left ventricle, left atrium, left atrial appendage, ascending aorta, and pulmonary veins. TRUNet offers more precise vessel boundary segmentation and better captures the heart's overall anatomical structure compared to residual U-Net, as confirmed by the absence of extraneous clusters of missegmented voxels. In terms of both performance and training speed, TRUNet exceeded U-Net, a commonly used segmentation architecture, making it a promising tool for 3D semantic segmentation tasks in medical imaging. The code for TRUNet is available at github.com/ljollans/TRUNet.