 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
D-Band 2D MIMO FMCW Radar System Design for Indoor Wireless Sensing
Sep 29, 2023
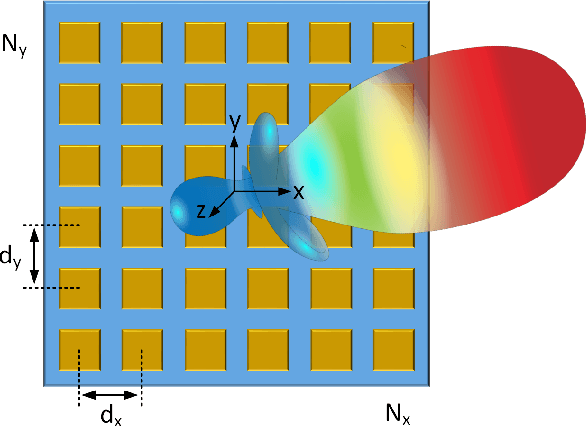
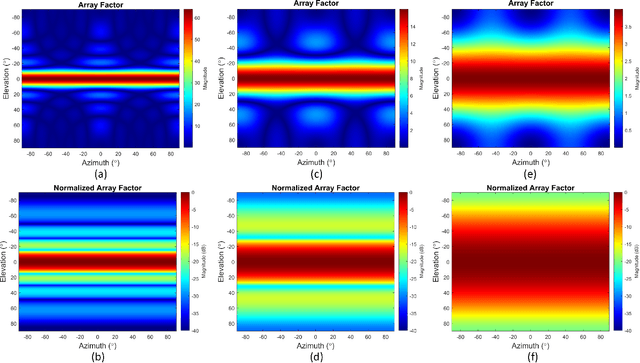
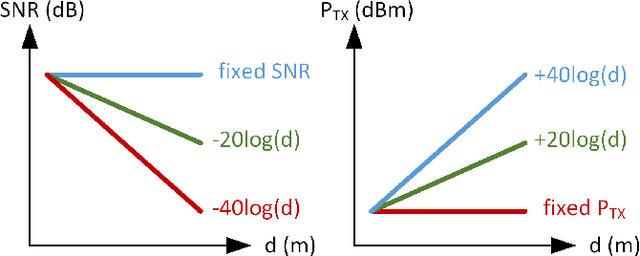
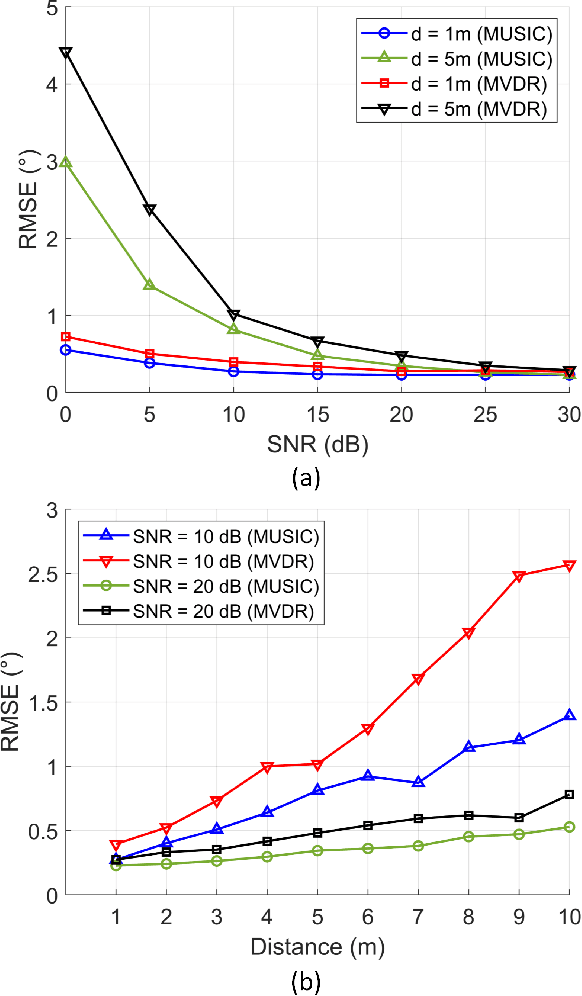
In this article, we present system design of D-band multi-input multi-output (MIMO) frequency-modulated continuous-wave (FMCW) radar for indoor wireless sensing. A uniform rectangular array (URA) of radar elements is used for 2D direction-of-arrival (DOA) estimation. The DOA estimation accuracy of the MIMO radar array in the presence of noise is evaluated using the multiple-signal classification (MUSIC) and the minimum variance distortionless response (MVDR) algorithms. We investigate different scaling scenarios for the radar receiver (RX) SNR and the transmitter (TX) output power with the target distance. The DOA estimation algorithm providing the highest accuracy and shortest simulation time is shown to depend on the size of the radar array. Specifically, for a 64-element array, the MUSIC achieves lower root-mean-square error (RMSE) compared to the MVDR across 1--10\,m indoor distances and 0--30\,dB SNR (e.g., $\rm 0.8^{\circ}$/$\rm 0.3^{\circ}$ versus $\rm 1.0^{\circ}$/$\rm 0.5^{\circ}$ at 10/20\,dB SNR and 5\,m distance) and 0.5x simulation time. For a 16-element array, the two algorithms provide comparable performance, while for a 4-element array, the MVDR outperforms the MUSIC by a large margin (e.g., $\rm 8.3^{\circ}$/$\rm 3.8^{\circ}$ versus $\rm 62.2^{\circ}$/$\rm 48.8^{\circ}$ at 10/20\,dB SNR and 5\,m distance) and 0.8x simulation time. Furthermore, the TX output power requirement of the radar array is investigated in free-space and through-wall wireless sensing scenarios, and is benchmarked by the state-of-the-art D-band on-chip radars.
Tailoring Self-Attention for Graph via Rooted Subtrees
Oct 08, 2023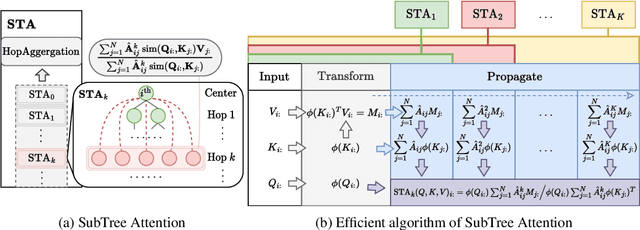
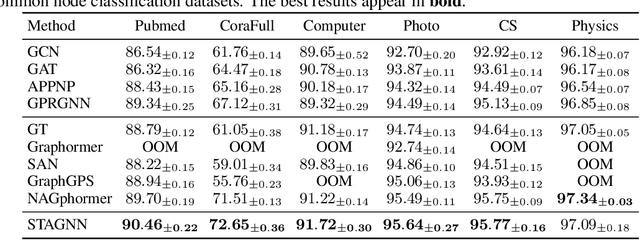
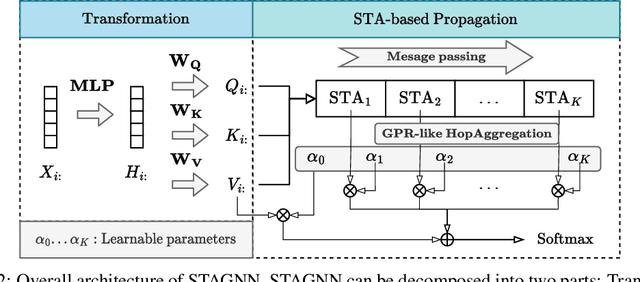
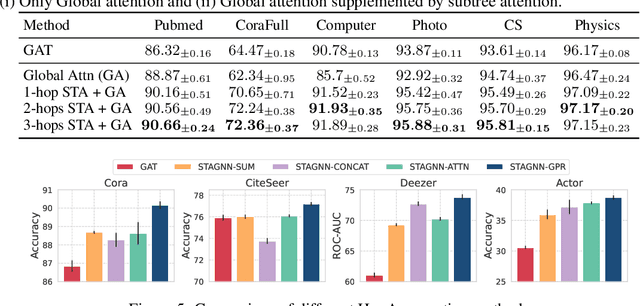
Attention mechanisms have made significant strides in graph learning, yet they still exhibit notable limitations: local attention faces challenges in capturing long-range information due to the inherent problems of the message-passing scheme, while global attention cannot reflect the hierarchical neighborhood structure and fails to capture fine-grained local information. In this paper, we propose a novel multi-hop graph attention mechanism, named Subtree Attention (STA), to address the aforementioned issues. STA seamlessly bridges the fully-attentional structure and the rooted subtree, with theoretical proof that STA approximates the global attention under extreme settings. By allowing direct computation of attention weights among multi-hop neighbors, STA mitigates the inherent problems in existing graph attention mechanisms. Further we devise an efficient form for STA by employing kernelized softmax, which yields a linear time complexity. Our resulting GNN architecture, the STAGNN, presents a simple yet performant STA-based graph neural network leveraging a hop-aware attention strategy. Comprehensive evaluations on ten node classification datasets demonstrate that STA-based models outperform existing graph transformers and mainstream GNNs. The code is available at https://github.com/LUMIA-Group/SubTree-Attention.
Do Large Language Models Know about Facts?
Oct 08, 2023Large language models (LLMs) have recently driven striking performance improvements across a range of natural language processing tasks. The factual knowledge acquired during pretraining and instruction tuning can be useful in various downstream tasks, such as question answering, and language generation. Unlike conventional Knowledge Bases (KBs) that explicitly store factual knowledge, LLMs implicitly store facts in their parameters. Content generated by the LLMs can often exhibit inaccuracies or deviations from the truth, due to facts that can be incorrectly induced or become obsolete over time. To this end, we aim to comprehensively evaluate the extent and scope of factual knowledge within LLMs by designing the benchmark Pinocchio. Pinocchio contains 20K diverse factual questions that span different sources, timelines, domains, regions, and languages. Furthermore, we investigate whether LLMs are able to compose multiple facts, update factual knowledge temporally, reason over multiple pieces of facts, identify subtle factual differences, and resist adversarial examples. Extensive experiments on different sizes and types of LLMs show that existing LLMs still lack factual knowledge and suffer from various spurious correlations. We believe this is a critical bottleneck for realizing trustworthy artificial intelligence. The dataset Pinocchio and our codes will be publicly available.
Dynamic Spatio-Temporal Summarization using Information Based Fusion
Oct 02, 2023In the era of burgeoning data generation, managing and storing large-scale time-varying datasets poses significant challenges. With the rise of supercomputing capabilities, the volume of data produced has soared, intensifying storage and I/O overheads. To address this issue, we propose a dynamic spatio-temporal data summarization technique that identifies informative features in key timesteps and fuses less informative ones. This approach minimizes storage requirements while preserving data dynamics. Unlike existing methods, our method retains both raw and summarized timesteps, ensuring a comprehensive view of information changes over time. We utilize information-theoretic measures to guide the fusion process, resulting in a visual representation that captures essential data patterns. We demonstrate the versatility of our technique across diverse datasets, encompassing particle-based flow simulations, security and surveillance applications, and biological cell interactions within the immune system. Our research significantly contributes to the realm of data management, introducing enhanced efficiency and deeper insights across diverse multidisciplinary domains. We provide a streamlined approach for handling massive datasets that can be applied to in situ analysis as well as post hoc analysis. This not only addresses the escalating challenges of data storage and I/O overheads but also unlocks the potential for informed decision-making. Our method empowers researchers and experts to explore essential temporal dynamics while minimizing storage requirements, thereby fostering a more effective and intuitive understanding of complex data behaviors.
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Sep 22, 2023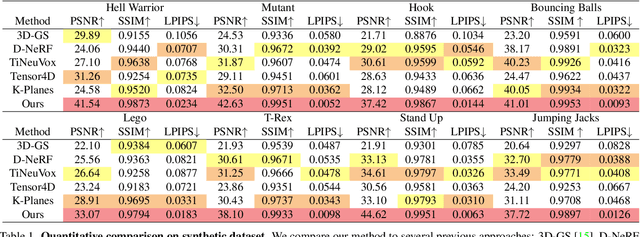
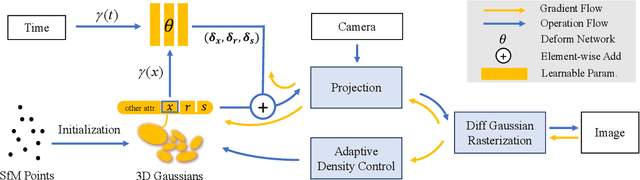
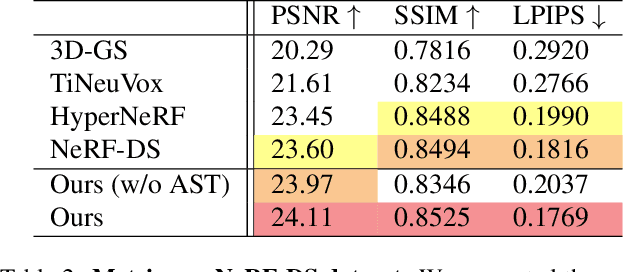

Implicit neural representation has opened up new avenues for dynamic scene reconstruction and rendering. Nonetheless, state-of-the-art methods of dynamic neural rendering rely heavily on these implicit representations, which frequently struggle with accurately capturing the intricate details of objects in the scene. Furthermore, implicit methods struggle to achieve real-time rendering in general dynamic scenes, limiting their use in a wide range of tasks. To address the issues, we propose a deformable 3D Gaussians Splatting method that reconstructs scenes using explicit 3D Gaussians and learns Gaussians in canonical space with a deformation field to model monocular dynamic scenes. We also introduced a smoothing training mechanism with no extra overhead to mitigate the impact of inaccurate poses in real datasets on the smoothness of time interpolation tasks. Through differential gaussian rasterization, the deformable 3D Gaussians not only achieve higher rendering quality but also real-time rendering speed. Experiments show that our method outperforms existing methods significantly in terms of both rendering quality and speed, making it well-suited for tasks such as novel-view synthesis, time synthesis, and real-time rendering.
Time Regularization in Optimal Time Variable Learning
Jun 28, 2023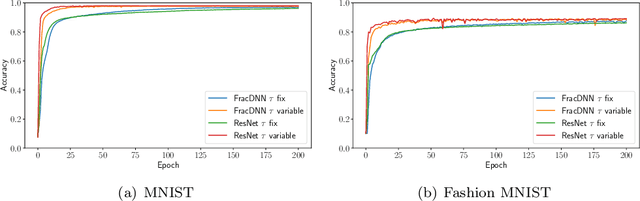
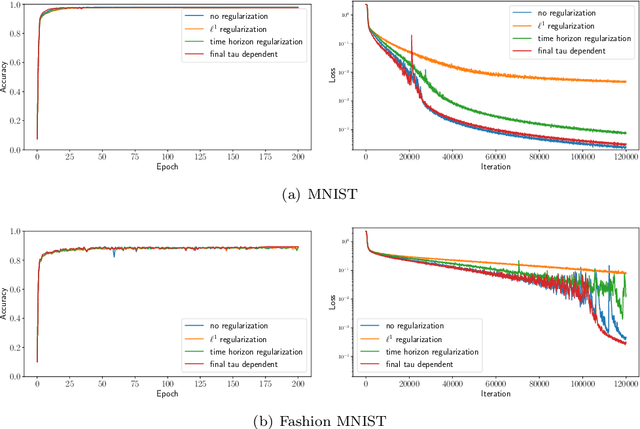
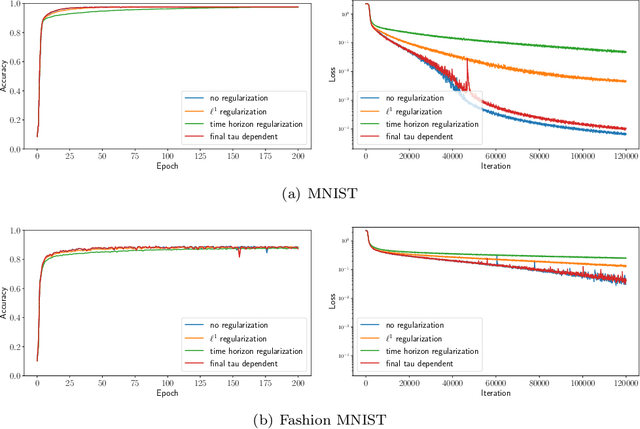
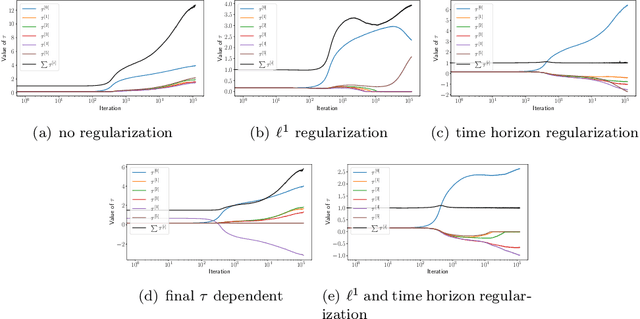
Recently, optimal time variable learning in deep neural networks (DNNs) was introduced in arXiv:2204.08528. In this manuscript we extend the concept by introducing a regularization term that directly relates to the time horizon in discrete dynamical systems. Furthermore, we propose an adaptive pruning approach for Residual Neural Networks (ResNets), which reduces network complexity without compromising expressiveness, while simultaneously decreasing training time. The results are illustrated by applying the proposed concepts to classification tasks on the well known MNIST and Fashion MNIST data sets. Our PyTorch code is available on https://github.com/frederikkoehne/time_variable_learning.
Multivariate Time Series Anomaly Detection: Fancy Algorithms and Flawed Evaluation Methodology
Aug 24, 2023Multivariate Time Series (MVTS) anomaly detection is a long-standing and challenging research topic that has attracted tremendous research effort from both industry and academia recently. However, a careful study of the literature makes us realize that 1) the community is active but not as organized as other sibling machine learning communities such as Computer Vision (CV) and Natural Language Processing (NLP), and 2) most proposed solutions are evaluated using either inappropriate or highly flawed protocols, with an apparent lack of scientific foundation. So flawed is one very popular protocol, the so-called \pa protocol, that a random guess can be shown to systematically outperform \emph{all} algorithms developed so far. In this paper, we review and evaluate many recent algorithms using more robust protocols and discuss how a normally good protocol may have weaknesses in the context of MVTS anomaly detection and how to mitigate them. We also share our concerns about benchmark datasets, experiment design and evaluation methodology we observe in many works. Furthermore, we propose a simple, yet challenging, baseline algorithm based on Principal Components Analysis (PCA) that surprisingly outperforms many recent Deep Learning (DL) based approaches on popular benchmark datasets. The main objective of this work is to stimulate more effort towards important aspects of the research such as data, experiment design, evaluation methodology and result interpretability, instead of putting the highest weight on the design of increasingly more complex and "fancier" algorithms.
Entropic Score metric: Decoupling Topology and Size in Training-free NAS
Oct 06, 2023Neural Networks design is a complex and often daunting task, particularly for resource-constrained scenarios typical of mobile-sized models. Neural Architecture Search is a promising approach to automate this process, but existing competitive methods require large training time and computational resources to generate accurate models. To overcome these limits, this paper contributes with: i) a novel training-free metric, named Entropic Score, to estimate model expressivity through the aggregated element-wise entropy of its activations; ii) a cyclic search algorithm to separately yet synergistically search model size and topology. Entropic Score shows remarkable ability in searching for the topology of the network, and a proper combination with LogSynflow, to search for model size, yields superior capability to completely design high-performance Hybrid Transformers for edge applications in less than 1 GPU hour, resulting in the fastest and most accurate NAS method for ImageNet classification.
Reinforcement Learning with Fast and Forgetful Memory
Oct 06, 2023Nearly all real world tasks are inherently partially observable, necessitating the use of memory in Reinforcement Learning (RL). Most model-free approaches summarize the trajectory into a latent Markov state using memory models borrowed from Supervised Learning (SL), even though RL tends to exhibit different training and efficiency characteristics. Addressing this discrepancy, we introduce Fast and Forgetful Memory, an algorithm-agnostic memory model designed specifically for RL. Our approach constrains the model search space via strong structural priors inspired by computational psychology. It is a drop-in replacement for recurrent neural networks (RNNs) in recurrent RL algorithms, achieving greater reward than RNNs across various recurrent benchmarks and algorithms without changing any hyperparameters. Moreover, Fast and Forgetful Memory exhibits training speeds two orders of magnitude faster than RNNs, attributed to its logarithmic time and linear space complexity. Our implementation is available at https://github.com/proroklab/ffm.
Learning Optimal Power Flow Value Functions with Input-Convex Neural Networks
Oct 06, 2023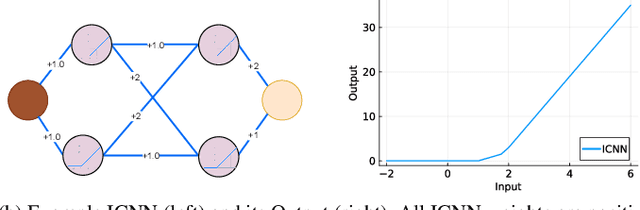
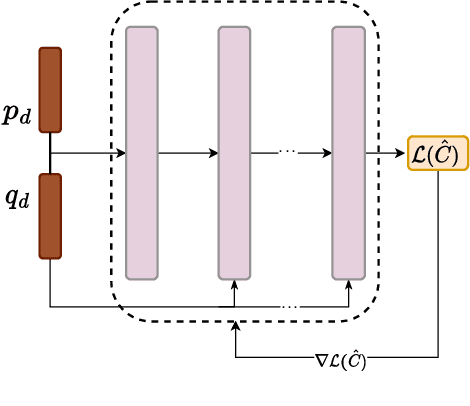
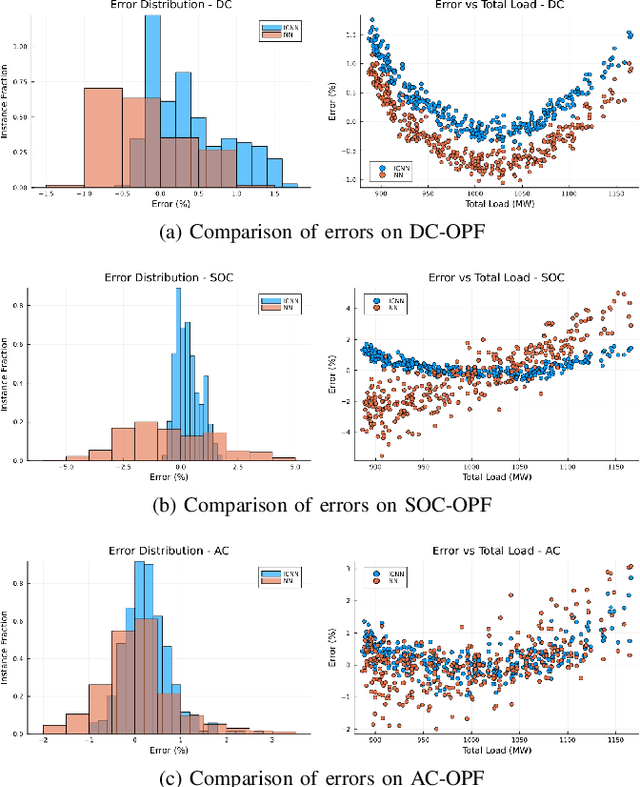
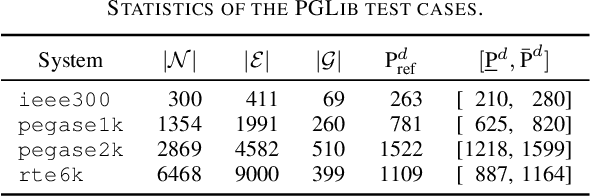
The Optimal Power Flow (OPF) problem is integral to the functioning of power systems, aiming to optimize generation dispatch while adhering to technical and operational constraints. These constraints are far from straightforward; they involve intricate, non-convex considerations related to Alternating Current (AC) power flow, which are essential for the safety and practicality of electrical grids. However, solving the OPF problem for varying conditions within stringent time frames poses practical challenges. To address this, operators resort to model simplifications of varying accuracy. Unfortunately, better approximations (tight convex relaxations) are often computationally intractable. This research explores machine learning (ML) to learn convex approximate solutions for faster analysis in the online setting while still allowing for coupling into other convex dependent decision problems. By trading off a small amount of accuracy for substantial gains in speed, they enable the efficient exploration of vast solution spaces in these complex problems.