 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024
The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
Efficiently Distilling LLMs for Edge Applications
Apr 01, 2024Supernet training of LLMs is of great interest in industrial applications as it confers the ability to produce a palette of smaller models at constant cost, regardless of the number of models (of different size / latency) produced. We propose a new method called Multistage Low-rank Fine-tuning of Super-transformers (MLFS) for parameter-efficient supernet training. We show that it is possible to obtain high-quality encoder models that are suitable for commercial edge applications, and that while decoder-only models are resistant to a comparable degree of compression, decoders can be effectively sliced for a significant reduction in training time.
Learning Time Slot Preferences via Mobility Tree for Next POI Recommendation
Mar 17, 2024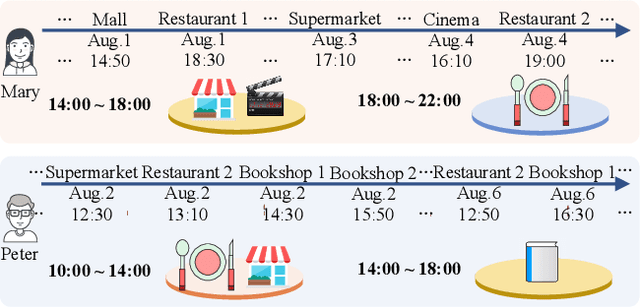
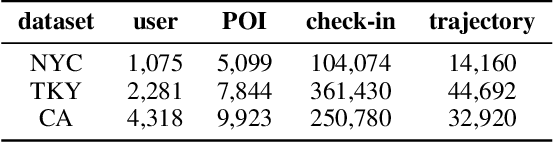
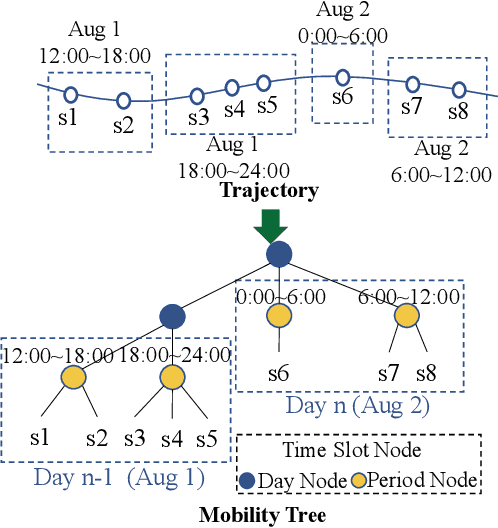
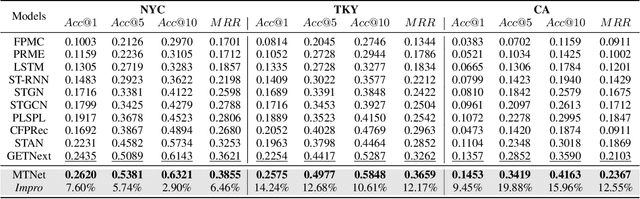
Next Point-of-Interests (POIs) recommendation task aims to provide a dynamic ranking of POIs based on users' current check-in trajectories. The recommendation performance of this task is contingent upon a comprehensive understanding of users' personalized behavioral patterns through Location-based Social Networks (LBSNs) data. While prior studies have adeptly captured sequential patterns and transitional relationships within users' check-in trajectories, a noticeable gap persists in devising a mechanism for discerning specialized behavioral patterns during distinct time slots, such as noon, afternoon, or evening. In this paper, we introduce an innovative data structure termed the ``Mobility Tree'', tailored for hierarchically describing users' check-in records. The Mobility Tree encompasses multi-granularity time slot nodes to learn user preferences across varying temporal periods. Meanwhile, we propose the Mobility Tree Network (MTNet), a multitask framework for personalized preference learning based on Mobility Trees. We develop a four-step node interaction operation to propagate feature information from the leaf nodes to the root node. Additionally, we adopt a multitask training strategy to push the model towards learning a robust representation. The comprehensive experimental results demonstrate the superiority of MTNet over ten state-of-the-art next POI recommendation models across three real-world LBSN datasets, substantiating the efficacy of time slot preference learning facilitated by Mobility Tree.
Active learning for efficient annotation in precision agriculture: a use-case on crop-weed semantic segmentation
Apr 03, 2024Optimizing deep learning models requires large amounts of annotated images, a process that is both time-intensive and costly. Especially for semantic segmentation models in which every pixel must be annotated. A potential strategy to mitigate annotation effort is active learning. Active learning facilitates the identification and selection of the most informative images from a large unlabelled pool. The underlying premise is that these selected images can improve the model's performance faster than random selection to reduce annotation effort. While active learning has demonstrated promising results on benchmark datasets like Cityscapes, its performance in the agricultural domain remains largely unexplored. This study addresses this research gap by conducting a comparative study of three active learning-based acquisition functions: Bayesian Active Learning by Disagreement (BALD), stochastic-based BALD (PowerBALD), and Random. The acquisition functions were tested on two agricultural datasets: Sugarbeet and Corn-Weed, both containing three semantic classes: background, crop and weed. Our results indicated that active learning, especially PowerBALD, yields a higher performance than Random sampling on both datasets. But due to the relatively large standard deviations, the differences observed were minimal; this was partly caused by high image redundancy and imbalanced classes. Specifically, more than 89\% of the pixels belonged to the background class on both datasets. The absence of significant results on both datasets indicates that further research is required for applying active learning on agricultural datasets, especially if they contain a high-class imbalance and redundant images. Recommendations and insights are provided in this paper to potentially resolve such issues.
GPU-Accelerated RSF Level Set Evolution for Large-Scale Microvascular Segmentation
Apr 03, 2024Microvascular networks are challenging to model because these structures are currently near the diffraction limit for most advanced three-dimensional imaging modalities, including confocal and light sheet microscopy. This makes semantic segmentation difficult, because individual components of these networks fluctuate within the confines of individual pixels. Level set methods are ideally suited to solve this problem by providing surface and topological constraints on the resulting model, however these active contour techniques are extremely time intensive and impractical for terabyte-scale images. We propose a reformulation and implementation of the region-scalable fitting (RSF) level set model that makes it amenable to three-dimensional evaluation using both single-instruction multiple data (SIMD) and single-program multiple-data (SPMD) parallel processing. This enables evaluation of the level set equation on independent regions of the data set using graphics processing units (GPUs), making large-scale segmentation of high-resolution networks practical and inexpensive. We tested this 3D parallel RSF approach on multiple data sets acquired using state-of-the-art imaging techniques to acquire microvascular data, including micro-CT, light sheet fluorescence microscopy (LSFM) and milling microscopy. To assess the performance and accuracy of the RSF model, we conducted a Monte-Carlo-based validation technique to compare results to other segmentation methods. We also provide a rigorous profiling to show the gains in processing speed leveraging parallel hardware. This study showcases the practical application of the RSF model, emphasizing its utility in the challenging domain of segmenting large-scale high-topology network structures with a particular focus on building microvascular models.
Ego-Motion Aware Target Prediction Module for Robust Multi-Object Tracking
Apr 03, 2024Multi-object tracking (MOT) is a prominent task in computer vision with application in autonomous driving, responsible for the simultaneous tracking of multiple object trajectories. Detection-based multi-object tracking (DBT) algorithms detect objects using an independent object detector and predict the imminent location of each target. Conventional prediction methods in DBT utilize Kalman Filter(KF) to extrapolate the target location in the upcoming frames by supposing a constant velocity motion model. These methods are especially hindered in autonomous driving applications due to dramatic camera motion or unavailable detections. Such limitations lead to tracking failures manifested by numerous identity switches and disrupted trajectories. In this paper, we introduce a novel KF-based prediction module called the Ego-motion Aware Target Prediction (EMAP) module by focusing on the integration of camera motion and depth information with object motion models. Our proposed method decouples the impact of camera rotational and translational velocity from the object trajectories by reformulating the Kalman Filter. This reformulation enables us to reject the disturbances caused by camera motion and maximizes the reliability of the object motion model. We integrate our module with four state-of-the-art base MOT algorithms, namely OC-SORT, Deep OC-SORT, ByteTrack, and BoT-SORT. In particular, our evaluation on the KITTI MOT dataset demonstrates that EMAP remarkably drops the number of identity switches (IDSW) of OC-SORT and Deep OC-SORT by 73% and 21%, respectively. At the same time, it elevates other performance metrics such as HOTA by more than 5%. Our source code is available at https://github.com/noyzzz/EMAP.
RAVE: Residual Vector Embedding for CLIP-Guided Backlit Image Enhancement
Apr 03, 2024In this paper we propose a novel modification of Contrastive Language-Image Pre-Training (CLIP) guidance for the task of unsupervised backlit image enhancement. Our work builds on the state-of-the-art CLIP-LIT approach, which learns a prompt pair by constraining the text-image similarity between a prompt (negative/positive sample) and a corresponding image (backlit image/well-lit image) in the CLIP embedding space. Learned prompts then guide an image enhancement network. Based on the CLIP-LIT framework, we propose two novel methods for CLIP guidance. First, we show that instead of tuning prompts in the space of text embeddings, it is possible to directly tune their embeddings in the latent space without any loss in quality. This accelerates training and potentially enables the use of additional encoders that do not have a text encoder. Second, we propose a novel approach that does not require any prompt tuning. Instead, based on CLIP embeddings of backlit and well-lit images from training data, we compute the residual vector in the embedding space as a simple difference between the mean embeddings of the well-lit and backlit images. This vector then guides the enhancement network during training, pushing a backlit image towards the space of well-lit images. This approach further dramatically reduces training time, stabilizes training and produces high quality enhanced images without artifacts, both in supervised and unsupervised training regimes. Additionally, we show that residual vectors can be interpreted, revealing biases in training data, and thereby enabling potential bias correction.
HeteroMILE: a Multi-Level Graph Representation Learning Framework for Heterogeneous Graphs
Mar 31, 2024Heterogeneous graphs are ubiquitous in real-world applications because they can represent various relationships between different types of entities. Therefore, learning embeddings in such graphs is a critical problem in graph machine learning. However, existing solutions for this problem fail to scale to large heterogeneous graphs due to their high computational complexity. To address this issue, we propose a Multi-Level Embedding framework of nodes on a heterogeneous graph (HeteroMILE) - a generic methodology that allows contemporary graph embedding methods to scale to large graphs. HeteroMILE repeatedly coarsens the large sized graph into a smaller size while preserving the backbone structure of the graph before embedding it, effectively reducing the computational cost by avoiding time-consuming processing operations. It then refines the coarsened embedding to the original graph using a heterogeneous graph convolution neural network. We evaluate our approach using several popular heterogeneous graph datasets. The experimental results show that HeteroMILE can substantially reduce computational time (approximately 20x speedup) and generate an embedding of better quality for link prediction and node classification.
Iterative Active-Inactive Obstacle Classification for Time-Optimal Collision Avoidance
Mar 20, 2024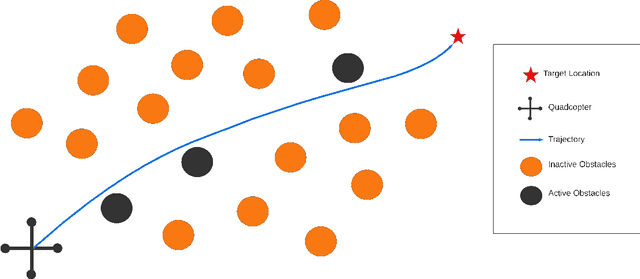
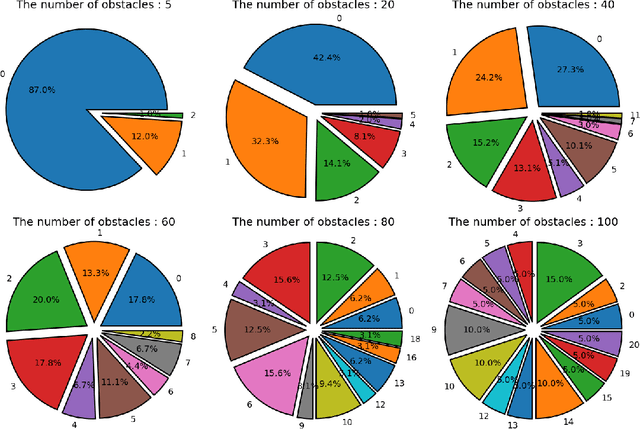
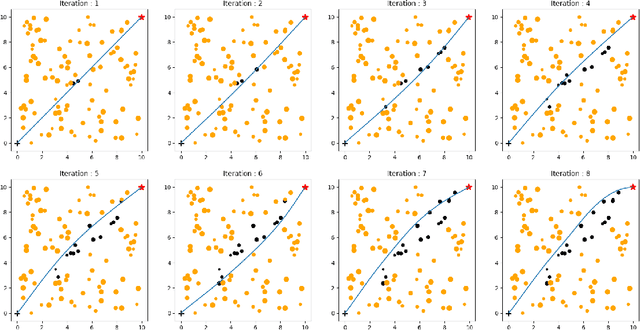
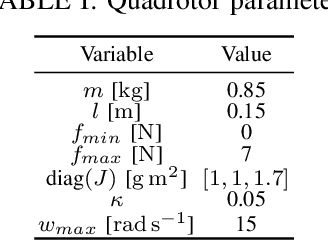
Time-optimal obstacle avoidance is a prevalent problem encountered in various fields, including robotics and autonomous vehicles, where the task involves determining a path for a moving vehicle to reach its goal while navigating around obstacles within its environment. This problem becomes increasingly challenging as the number of obstacles in the environment rises. We propose an iterative active-inactive obstacle approach, which involves identifying a subset of the obstacles as "active", that considers solely the effect of the "active" obstacles on the path of the moving vehicle. The remaining obstacles are considered "inactive" and are not considered in the path planning process. The obstacles are classified as 'active' on the basis of previous findings derived from prior iterations. This approach allows for a more efficient calculation of the optimal path by reducing the number of obstacles that need to be considered. The effectiveness of the proposed method is demonstrated with two different dynamic models using the various number of obstacles. The results show that the proposed method is able to find the optimal path in a timely manner, while also being able to handle a large number of obstacles in the environment and the constraints on the motion of the object.
Deep Learning-Based CSI Feedback for RIS-Aided Massive MIMO Systems with Time Correlation
Mar 19, 2024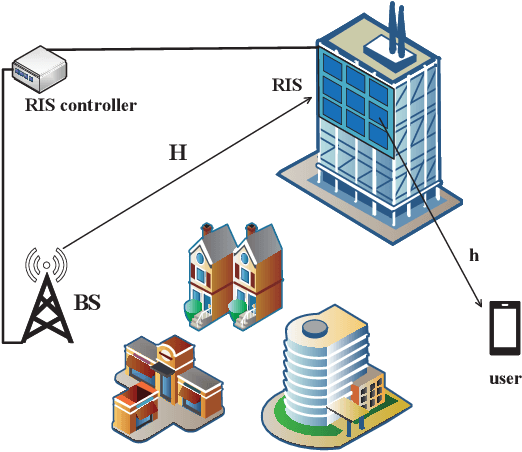
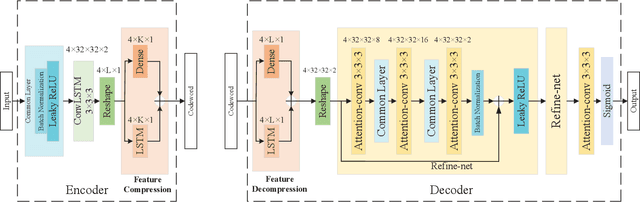
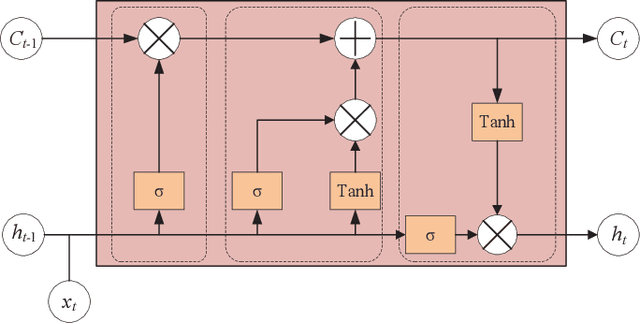
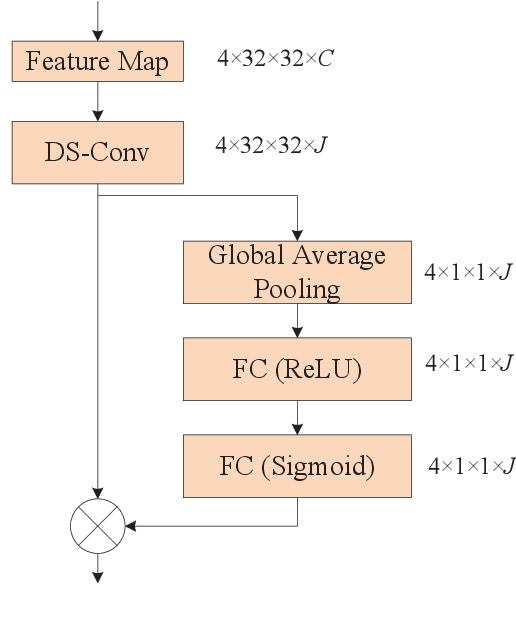
In this paper, we consider an reconfigurable intelligent surface (RIS)-aided frequency division duplex (FDD) massive multiple-input multiple-output (MIMO) downlink system.In the FDD systems, the downlink channel state information (CSI) should be sent to the base station through the feedback link. However, the overhead of CSI feedback occupies substantial uplink bandwidth resources in RIS-aided communication systems. In this work, we propose a deep learning (DL)-based scheme to reduce the overhead of CSI feedback by compressing the cascaded CSI. In the practical RIS-aided communication systems, the cascaded channel at the adjacent slots inevitably has time correlation. We use long short-term memory to learn time correlation, which can help the neural network to improve the recovery quality of the compressed CSI. Moreover, the attention mechanism is introduced to further improve the CSI recovery quality. Simulation results demonstrate that our proposed DLbased scheme can significantly outperform other DL-based methods in terms of the CSI recovery quality