 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Alpha Elimination: Using Deep Reinforcement Learning to Reduce Fill-In during Sparse Matrix Decomposition
Oct 15, 2023
A large number of computational and scientific methods commonly require decomposing a sparse matrix into triangular factors as LU decomposition. A common problem faced during this decomposition is that even though the given matrix may be very sparse, the decomposition may lead to a denser triangular factors due to fill-in. A significant fill-in may lead to prohibitively larger computational costs and memory requirement during decomposition as well as during the solve phase. To this end, several heuristic sparse matrix reordering methods have been proposed to reduce fill-in before the decomposition. However, finding an optimal reordering algorithm that leads to minimal fill-in during such decomposition is known to be a NP-hard problem. A reinforcement learning based approach is proposed for this problem. The sparse matrix reordering problem is formulated as a single player game. More specifically, Monte-Carlo tree search in combination with neural network is used as a decision making algorithm to search for the best move in our game. The proposed method, alphaElimination is found to produce significantly lesser non-zeros in the LU decomposition as compared to existing state-of-the-art heuristic algorithms with little to no increase in overall running time of the algorithm. The code for the project will be publicly available here\footnote{\url{https://github.com/misterpawan/alphaEliminationPaper}}.
Socially reactive navigation models for mobile robots in dynamic environments
Oct 15, 2023The objective of this work is to expand upon previous works, considering socially acceptable behaviours within robot navigation and interaction, and allow a robot to closely approach static and dynamic individuals or groups. The space models developed in this dissertation are adaptive, that is, capable of changing over time to accommodate the changing circumstances often existent within a social environment. The space model's parameters' adaptation occurs with the end goal of enabling a close interaction between humans and robots and is thus capable of taking into account not only the arrangement of the groups, but also the basic characteristics of the robot itself. This work also further develops a preexisting approach pose estimation algorithm in order to better guarantee the safety and comfort of the humans involved in the interaction, by taking into account basic human sensibilities. The algorithms are integrated into ROS's navigation system through the use of the $costmap2d$ and the $move\_base$ packages. The space model adaptation is tested via comparative evaluation against previous algorithms through the use of datasets. The entire navigation system is then evaluated through both simulations (static and dynamic) and real life situations (static). These experiments demonstrate that the developed space model and approach pose estimation algorithms are capable of enabling a robot to closely approach individual humans and groups, while maintaining considerations for their comfort and sensibilities.
Efficient and Effective Multi-View Subspace Clustering for Large-scale Data
Oct 15, 2023Recent multi-view subspace clustering achieves impressive results utilizing deep networks, where the self-expressive correlation is typically modeled by a fully connected (FC) layer. However, they still suffer from two limitations: i) it is under-explored to extract a unified representation from multiple views that simultaneously satisfy minimal sufficiency and discriminability. ii) the parameter scale of the FC layer is quadratic to the number of samples, resulting in high time and memory costs that significantly degrade their feasibility in large-scale datasets. In light of this, we propose a novel deep framework termed Efficient and Effective Large-scale Multi-View Subspace Clustering (E$^2$LMVSC). Specifically, to enhance the quality of the unified representation, a soft clustering assignment similarity constraint is devised for explicitly decoupling consistent, complementary, and superfluous information across multi-view data. Then, following information bottleneck theory, a sufficient yet minimal unified feature representation is obtained. Moreover, E$^2$LMVSC employs the maximal coding rate reduction principle to promote intra-cluster aggregation and inter-cluster separability within the unified representation. Finally, the self-expressive coefficients are learned by a Relation-Metric Net instead of a parameterized FC layer for greater efficiency. Extensive experiments show that E$^2$LMVSC yields comparable results to existing methods and achieves state-of-the-art clustering performance in large-scale multi-view datasets.
Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs
Oct 17, 2023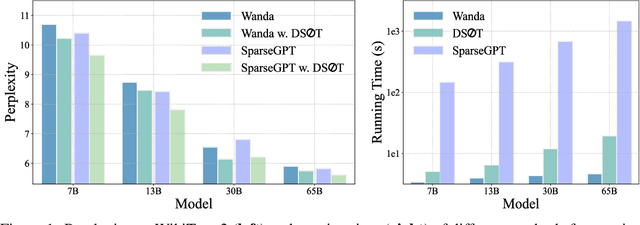
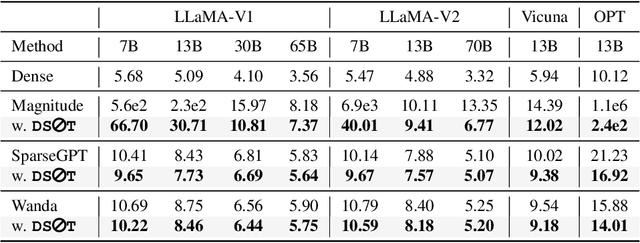
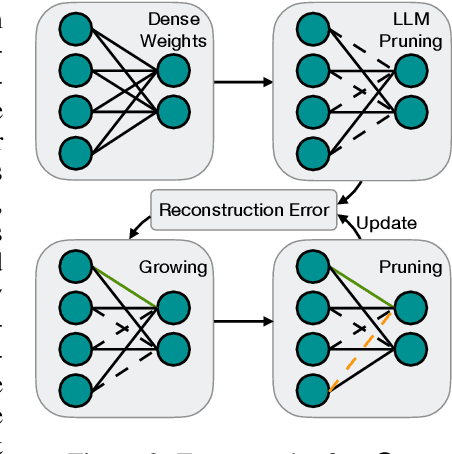
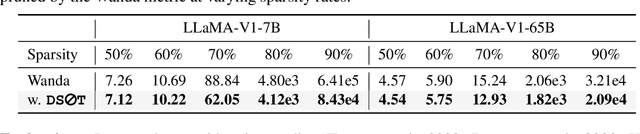
The ever-increasing large language models (LLMs), though opening a potential path for the upcoming artificial general intelligence, sadly drops a daunting obstacle on the way towards their on-device deployment. As one of the most well-established pre-LLMs approaches in reducing model complexity, network pruning appears to lag behind in the era of LLMs, due mostly to its costly fine-tuning (or re-training) necessity under the massive volumes of model parameter and training data. To close this industry-academia gap, we introduce Dynamic Sparse No Training (DSnoT), a training-free fine-tuning approach that slightly updates sparse LLMs without the expensive backpropagation and any weight updates. Inspired by the Dynamic Sparse Training, DSnoT minimizes the reconstruction error between the dense and sparse LLMs, in the fashion of performing iterative weight pruning-and-growing on top of sparse LLMs. To accomplish this purpose, DSnoT particularly takes into account the anticipated reduction in reconstruction error for pruning and growing, as well as the variance w.r.t. different input data for growing each weight. This practice can be executed efficiently in linear time since its obviates the need of backpropagation for fine-tuning LLMs. Extensive experiments on LLaMA-V1/V2, Vicuna, and OPT across various benchmarks demonstrate the effectiveness of DSnoT in enhancing the performance of sparse LLMs, especially at high sparsity levels. For instance, DSnoT is able to outperform the state-of-the-art Wanda by 26.79 perplexity at 70% sparsity with LLaMA-7B. Our paper offers fresh insights into how to fine-tune sparse LLMs in an efficient training-free manner and open new venues to scale the great potential of sparsity to LLMs. Codes are available at https://github.com/zyxxmu/DSnoT.
Lion Secretly Solves Constrained Optimization: As Lyapunov Predicts
Oct 09, 2023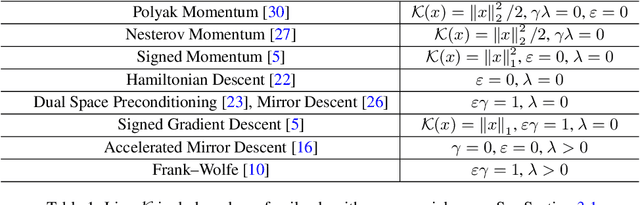
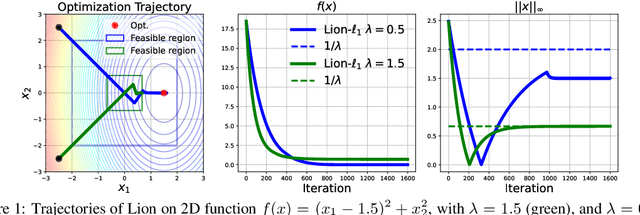


Lion (Evolved Sign Momentum), a new optimizer discovered through program search, has shown promising results in training large AI models. It performs comparably or favorably to AdamW but with greater memory efficiency. As we can expect from the results of a random search program, Lion incorporates elements from several existing algorithms, including signed momentum, decoupled weight decay, Polak, and Nesterov momentum, but does not fit into any existing category of theoretically grounded optimizers. Thus, even though Lion appears to perform well as a general-purpose optimizer for a wide range of tasks, its theoretical basis remains uncertain. This lack of theoretical clarity limits opportunities to further enhance and expand Lion's efficacy. This work aims to demystify Lion. Based on both continuous-time and discrete-time analysis, we demonstrate that Lion is a theoretically novel and principled approach for minimizing a general loss function $f(x)$ while enforcing a bound constraint $\|x\|_\infty \leq 1/\lambda$. Lion achieves this through the incorporation of decoupled weight decay, where $\lambda$ represents the weight decay coefficient. Our analysis is made possible by the development of a new Lyapunov function for the Lion updates. It applies to a broader family of Lion-$\kappa$ algorithms, where the $\text{sign}(\cdot)$ operator in Lion is replaced by the subgradient of a convex function $\kappa$, leading to the solution of a general composite optimization problem of $\min_x f(x) + \kappa^*(x)$. Our findings provide valuable insights into the dynamics of Lion and pave the way for further improvements and extensions of Lion-related algorithms.
Edge Computing-Enabled Road Condition Monitoring: System Development and Evaluation
Oct 09, 2023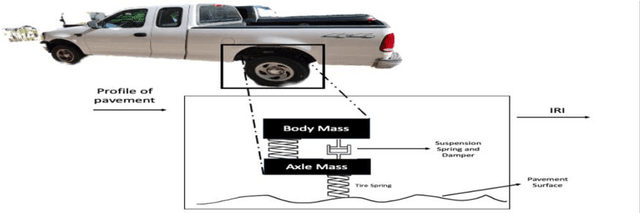
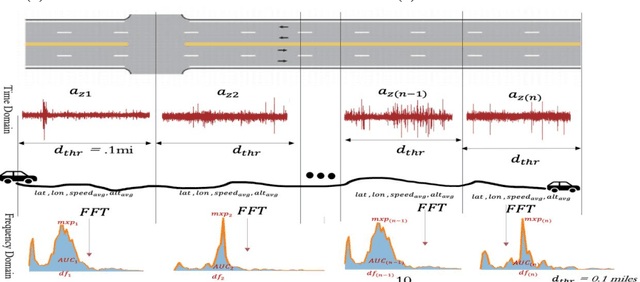
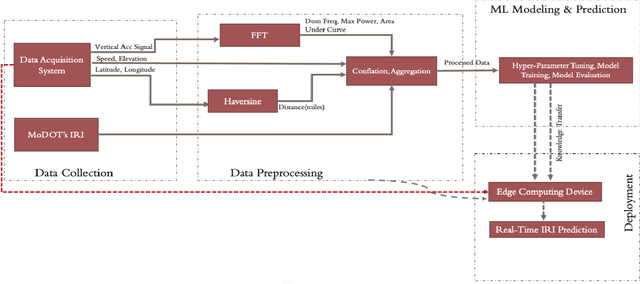
Real-time pavement condition monitoring provides highway agencies with timely and accurate information that could form the basis of pavement maintenance and rehabilitation policies. Existing technologies rely heavily on manual data processing, are expensive and therefore, difficult to scale for frequent, networklevel pavement condition monitoring. Additionally, these systems require sending large packets of data to the cloud which requires large storage space, are computationally expensive to process, and results in high latency. The current study proposes a solution that capitalizes on the widespread availability of affordable Micro Electro-Mechanical System (MEMS) sensors, edge computing and internet connection capabilities of microcontrollers, and deployable machine learning (ML) models to (a) design an Internet of Things (IoT)-enabled device that can be mounted on axles of vehicles to stream live pavement condition data (b) reduce latency through on-device processing and analytics of pavement condition sensor data before sending to the cloud servers. In this study, three ML models including Random Forest, LightGBM and XGBoost were trained to predict International Roughness Index (IRI) at every 0.1-mile segment. XGBoost had the highest accuracy with an RMSE and MAPE of 16.89in/mi and 20.3%, respectively. In terms of the ability to classify the IRI of pavement segments based on ride quality according to MAP-21 criteria, our proposed device achieved an average accuracy of 96.76% on I-70EB and 63.15% on South Providence. Overall, our proposed device demonstrates significant potential in providing real-time pavement condition data to State Highway Agencies (SHA) and Department of Transportation (DOTs) with a satisfactory level of accuracy.
CoPAL: Corrective Planning of Robot Actions with Large Language Models
Oct 11, 2023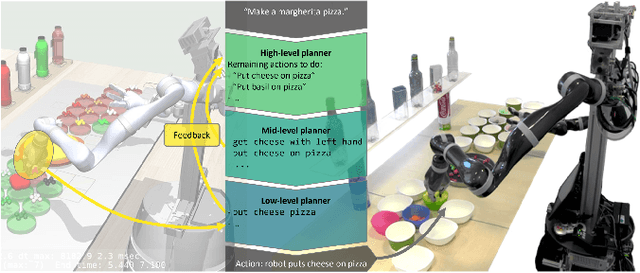
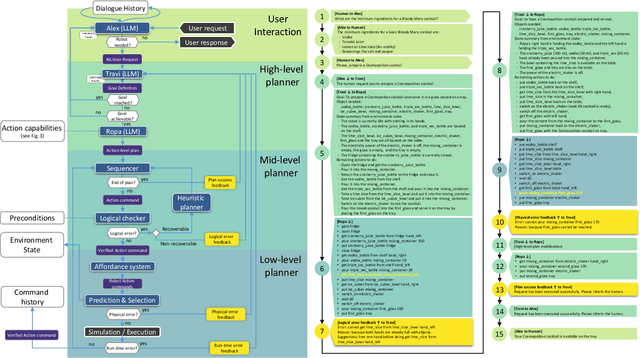
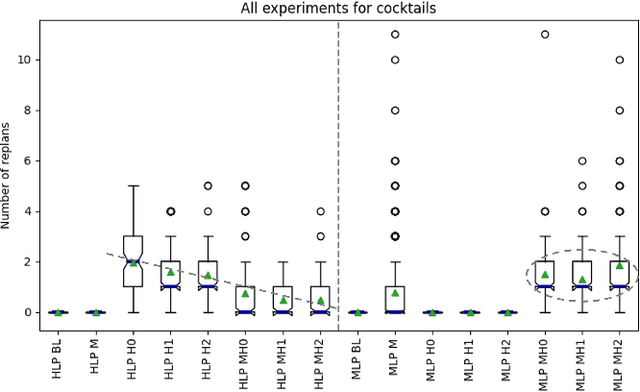
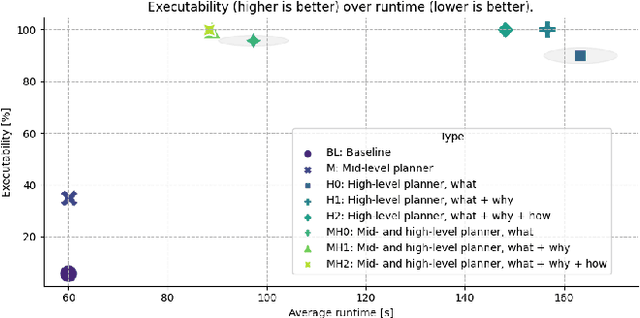
In the pursuit of fully autonomous robotic systems capable of taking over tasks traditionally performed by humans, the complexity of open-world environments poses a considerable challenge. Addressing this imperative, this study contributes to the field of Large Language Models (LLMs) applied to task and motion planning for robots. We propose a system architecture that orchestrates a seamless interplay between multiple cognitive levels, encompassing reasoning, planning, and motion generation. At its core lies a novel replanning strategy that handles physically grounded, logical, and semantic errors in the generated plans. We demonstrate the efficacy of the proposed feedback architecture, particularly its impact on executability, correctness, and time complexity via empirical evaluation in the context of a simulation and two intricate real-world scenarios: blocks world, barman and pizza preparation.
Experimental quantum natural gradient optimization in photonics
Oct 11, 2023Variational quantum algorithms (VQAs) combining the advantages of parameterized quantum circuits and classical optimizers, promise practical quantum applications in the Noisy Intermediate-Scale Quantum era. The performance of VQAs heavily depends on the optimization method. Compared with gradient-free and ordinary gradient descent methods, the quantum natural gradient (QNG), which mirrors the geometric structure of the parameter space, can achieve faster convergence and avoid local minima more easily, thereby reducing the cost of circuit executions. We utilized a fully programmable photonic chip to experimentally estimate the QNG in photonics for the first time. We obtained the dissociation curve of the He-H$^+$ cation and achieved chemical accuracy, verifying the outperformance of QNG optimization on a photonic device. Our work opens up a vista of utilizing QNG in photonics to implement practical near-term quantum applications.
pose-format: Library for Viewing, Augmenting, and Handling .pose Files
Oct 13, 2023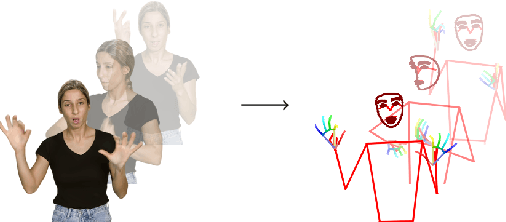
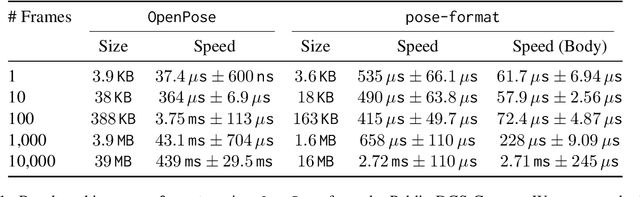
Managing and analyzing pose data is a complex task, with challenges ranging from handling diverse file structures and data types to facilitating effective data manipulations such as normalization and augmentation. This paper presents \texttt{pose-format}, a comprehensive toolkit designed to address these challenges by providing a unified, flexible, and easy-to-use interface. The library includes a specialized file format that encapsulates various types of pose data, accommodating multiple individuals and an indefinite number of time frames, thus proving its utility for both image and video data. Furthermore, it offers seamless integration with popular numerical libraries such as NumPy, PyTorch, and TensorFlow, thereby enabling robust machine-learning applications. Through benchmarking, we demonstrate that our \texttt{.pose} file format offers vastly superior performance against prevalent formats like OpenPose, with added advantages like self-contained pose specification. Additionally, the library includes features for data normalization, augmentation, and easy-to-use visualization capabilities, both in Python and Browser environments. \texttt{pose-format} emerges as a one-stop solution, streamlining the complexities of pose data management and analysis.
Spiking Semantic Communication for Feature Transmission with HARQ
Oct 13, 2023In Collaborative Intelligence (CI), the Artificial Intelligence (AI) model is divided between the edge and the cloud, with intermediate features being sent from the edge to the cloud for inference. Several deep learning-based Semantic Communication (SC) models have been proposed to reduce feature transmission overhead and mitigate channel noise interference. Previous research has demonstrated that Spiking Neural Network (SNN)-based SC models exhibit greater robustness on digital channels compared to Deep Neural Network (DNN)-based SC models. However, the existing SNN-based SC models require fixed time steps, resulting in fixed transmission bandwidths that cannot be adaptively adjusted based on channel conditions. To address this issue, this paper introduces a novel SC model called SNN-SC-HARQ, which combines the SNN-based SC model with the Hybrid Automatic Repeat Request (HARQ) mechanism. SNN-SC-HARQ comprises an SNN-based SC model that supports the transmission of features at varying bandwidths, along with a policy model that determines the appropriate bandwidth. Experimental results show that SNN-SC-HARQ can dynamically adjust the bandwidth according to the channel conditions without performance loss.