 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF
Oct 09, 2023
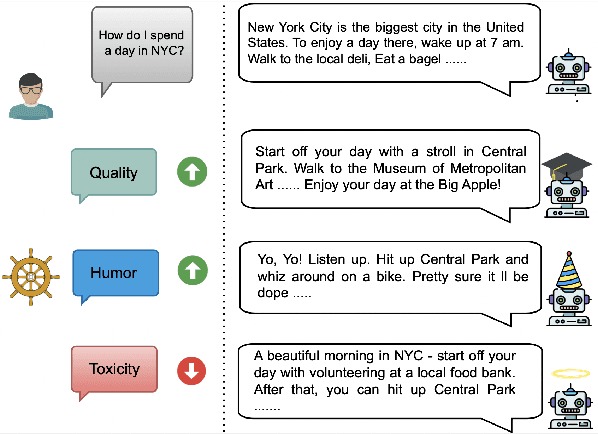
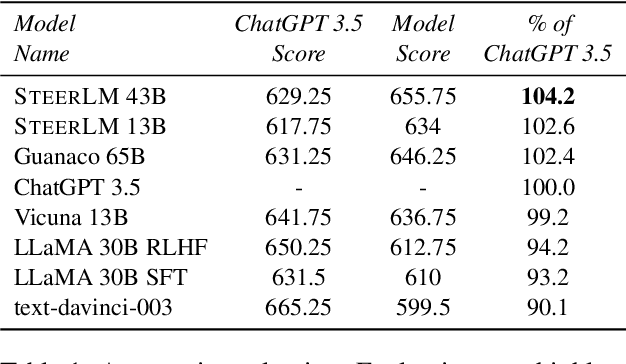
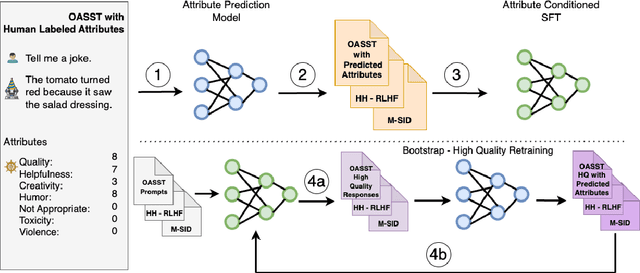
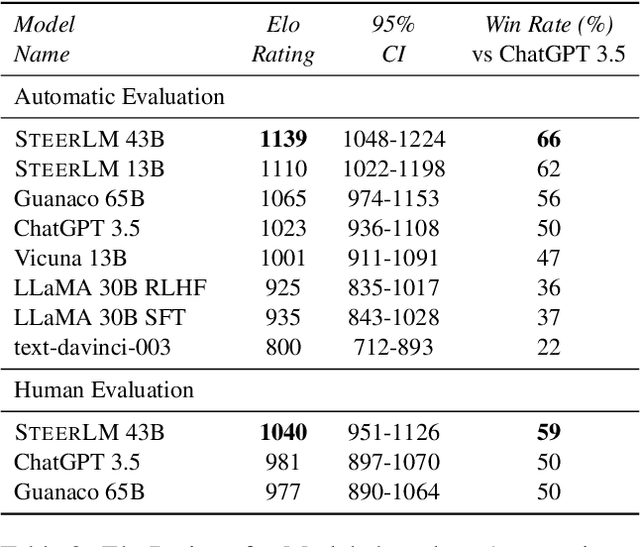
Model alignment with human preferences is an essential step in making Large Language Models (LLMs) helpful and consistent with human values. It typically consists of supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) stages. However, RLHF faces inherent limitations stemming from a complex training setup and its tendency to align the model with implicit values that end users cannot control at run-time. Moreover, reward models in RLHF stage commonly rely on single-dimensional feedback as opposed to explicit, multifaceted signals that indicate attributes such as helpfulness, humor, and toxicity. To address these limitations, we propose SteerLM, a supervised fine-tuning method that empowers end-users to control responses during inference. SteerLM conditions responses to conform to an explicitly defined multi-dimensional set of attributes, thereby empowering a steerable AI capable of generating helpful and high-quality responses while maintaining customizability. Experiments show that SteerLM trained on open source datasets generates responses that are preferred by human and automatic evaluators to many state-of-the-art baselines trained with RLHF while being much easier to train. Try SteerLM at https://huggingface.co/nvidia/SteerLM-llama2-13B
Win-Win: Training High-Resolution Vision Transformers from Two Windows
Oct 01, 2023Transformers have become the standard in state-of-the-art vision architectures, achieving impressive performance on both image-level and dense pixelwise tasks. However, training vision transformers for high-resolution pixelwise tasks has a prohibitive cost. Typical solutions boil down to hierarchical architectures, fast and approximate attention, or training on low-resolution crops. This latter solution does not constrain architectural choices, but it leads to a clear performance drop when testing at resolutions significantly higher than that used for training, thus requiring ad-hoc and slow post-processing schemes. In this paper, we propose a novel strategy for efficient training and inference of high-resolution vision transformers: the key principle is to mask out most of the high-resolution inputs during training, keeping only N random windows. This allows the model to learn local interactions between tokens inside each window, and global interactions between tokens from different windows. As a result, the model can directly process the high-resolution input at test time without any special trick. We show that this strategy is effective when using relative positional embedding such as rotary embeddings. It is 4 times faster to train than a full-resolution network, and it is straightforward to use at test time compared to existing approaches. We apply this strategy to the dense monocular task of semantic segmentation, and find that a simple setting with 2 windows performs best, hence the name of our method: Win-Win. To demonstrate the generality of our contribution, we further extend it to the binocular task of optical flow, reaching state-of-the-art performance on the Spring benchmark that contains Full-HD images with an inference time an order of magnitude faster than the best competitor.
ML Algorithm Synthesizing Domain Knowledge for Fungal Spores Concentration Prediction
Sep 23, 2023The pulp and paper manufacturing industry requires precise quality control to ensure pure, contaminant-free end products suitable for various applications. Fungal spore concentration is a crucial metric that affects paper usability, and current testing methods are labor-intensive with delayed results, hindering real-time control strategies. To address this, a machine learning algorithm utilizing time-series data and domain knowledge was proposed. The optimal model employed Ridge Regression achieving an MSE of 2.90 on training and validation data. This approach could lead to significant improvements in efficiency and sustainability by providing real-time predictions for fungal spore concentrations. This paper showcases a promising method for real-time fungal spore concentration prediction, enabling stringent quality control measures in the pulp-and-paper industry.
Efficient Online Scheduling and Routing for Automated Guided Vehicles: Comparing a Novel Loop-Based Algorithm Against Existing Methods
Oct 03, 2023Automated guided vehicles (AGVs) are widely used in various industries, and scheduling and routing them in a conflict-free manner is crucial to their efficient operation. We propose a loop-based algorithm that solves the online, conflict-free scheduling and routing problem for AGVs. The proposed algorithm is compared against an exact method, a greedy heuristic and a metaheuristic. We experimentally show that this algorithm either outperforms the other algorithms or gets an equally good solution in less computing time.
The Time Traveler's Guide to Semantic Web Research: Analyzing Fictitious Research Themes in the ESWC "Next 20 Years" Track
Sep 25, 2023What will Semantic Web research focus on in 20 years from now? We asked this question to the community and collected their visions in the "Next 20 years" track of ESWC 2023. We challenged the participants to submit "future" research papers, as if they were submitting to the 2043 edition of the conference. The submissions - entirely fictitious - were expected to be full scientific papers, with research questions, state of the art references, experimental results and future work, with the goal to get an idea of the research agenda for the late 2040s and early 2050s. We received ten submissions, eight of which were accepted for presentation at the conference, that mixed serious ideas of potential future research themes and discussion topics with some fun and irony. In this paper, we intend to provide a survey of those "science fiction" papers, considering the emerging research themes and topics, analysing the research methods applied by the authors in these very special submissions, and investigating also the most fictitious parts (e.g., neologisms, fabricated references). Our goal is twofold: on the one hand, we investigate what this special track tells us about the Semantic Web community and, on the other hand, we aim at getting some insights on future research practices and directions.
Cleanba: A Reproducible and Efficient Distributed Reinforcement Learning Platform
Sep 29, 2023Distributed Deep Reinforcement Learning (DRL) aims to leverage more computational resources to train autonomous agents with less training time. Despite recent progress in the field, reproducibility issues have not been sufficiently explored. This paper first shows that the typical actor-learner framework can have reproducibility issues even if hyperparameters are controlled. We then introduce Cleanba, a new open-source platform for distributed DRL that proposes a highly reproducible architecture. Cleanba implements highly optimized distributed variants of PPO and IMPALA. Our Atari experiments show that these variants can obtain equivalent or higher scores than strong IMPALA baselines in moolib and torchbeast and PPO baseline in CleanRL. However, Cleanba variants present 1) shorter training time and 2) more reproducible learning curves in different hardware settings. Cleanba's source code is available at \url{https://github.com/vwxyzjn/cleanba}
Learning Type Inference for Enhanced Dataflow Analysis
Oct 04, 2023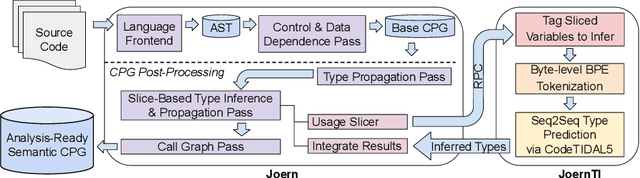
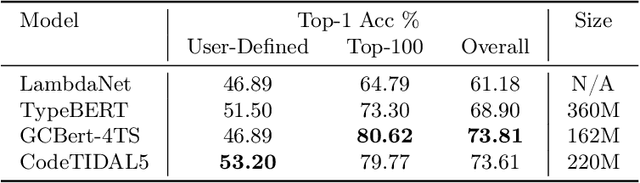
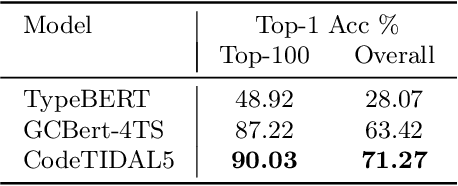
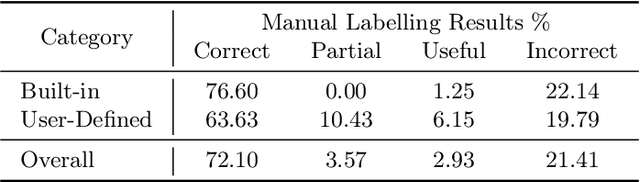
Statically analyzing dynamically-typed code is a challenging endeavor, as even seemingly trivial tasks such as determining the targets of procedure calls are non-trivial without knowing the types of objects at compile time. Addressing this challenge, gradual typing is increasingly added to dynamically-typed languages, a prominent example being TypeScript that introduces static typing to JavaScript. Gradual typing improves the developer's ability to verify program behavior, contributing to robust, secure and debuggable programs. In practice, however, users only sparsely annotate types directly. At the same time, conventional type inference faces performance-related challenges as program size grows. Statistical techniques based on machine learning offer faster inference, but although recent approaches demonstrate overall improved accuracy, they still perform significantly worse on user-defined types than on the most common built-in types. Limiting their real-world usefulness even more, they rarely integrate with user-facing applications. We propose CodeTIDAL5, a Transformer-based model trained to reliably predict type annotations. For effective result retrieval and re-integration, we extract usage slices from a program's code property graph. Comparing our approach against recent neural type inference systems, our model outperforms the current state-of-the-art by 7.85% on the ManyTypes4TypeScript benchmark, achieving 71.27% accuracy overall. Furthermore, we present JoernTI, an integration of our approach into Joern, an open source static analysis tool, and demonstrate that the analysis benefits from the additional type information. As our model allows for fast inference times even on commodity CPUs, making our system available through Joern leads to high accessibility and facilitates security research.
* - fixed last author's name - fixed header
Time-Aware Item Weighting for the Next Basket Recommendations
Jul 30, 2023
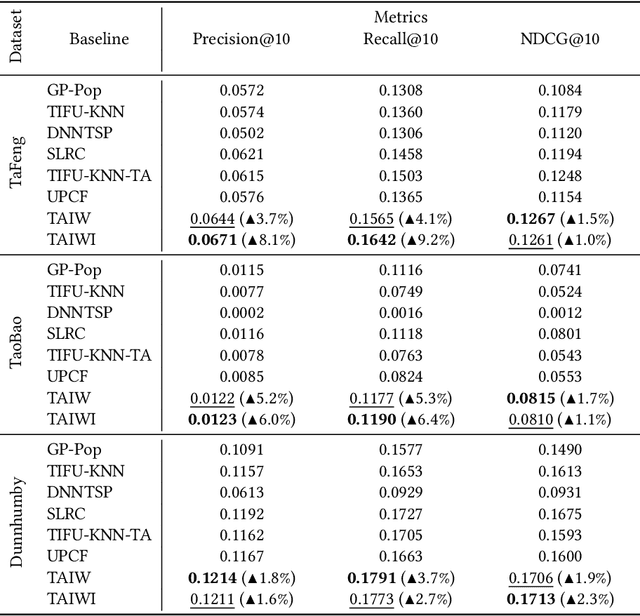
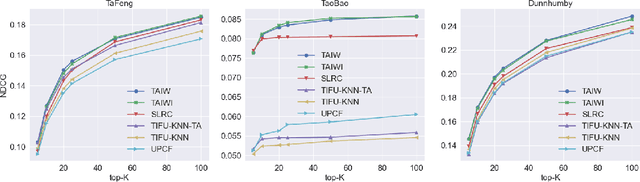
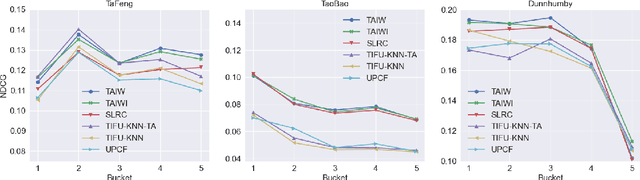
In this paper we study the next basket recommendation problem. Recent methods use different approaches to achieve better performance. However, many of them do not use information about the time of prediction and time intervals between baskets. To fill this gap, we propose a novel method, Time-Aware Item-based Weighting (TAIW), which takes timestamps and intervals into account. We provide experiments on three real-world datasets, and TAIW outperforms well-tuned state-of-the-art baselines for next-basket recommendations. In addition, we show the results of an ablation study and a case study of a few items.
Distributional PAC-Learning from Nisan's Natural Proofs
Oct 05, 2023

(Abridged) Carmosino et al. (2016) demonstrated that natural proofs of circuit lower bounds for \Lambda imply efficient algorithms for learning \Lambda-circuits, but only over the uniform distribution, with membership queries, and provided \AC^0[p] \subseteq \Lambda. We consider whether this implication can be generalized to \Lambda \not\supseteq \AC^0[p], and to learning algorithms in Valiant's PAC model, which use only random examples and learn over arbitrary example distributions. We give results of both positive and negative flavor. On the negative side, we observe that if, for every circuit class \Lambda, the implication from natural proofs for \Lambda to learning \Lambda-circuits in Valiant's PAC model holds, then there is a polynomial time solution to O(n^{1.5})-uSVP (unique Shortest Vector Problem), and polynomial time quantum solutions to O(n^{1.5})-SVP (Shortest Vector Problem) and O(n^{1.5})-SIVP (Shortest Independent Vector Problem). This indicates that whether natural proofs for \Lambda imply efficient learning algorithms for \Lambda in Valiant's PAC model may depend on \Lambda. On the positive side, our main result is that specific natural proofs arising from a type of communication complexity argument (e.g., Nisan (1993), for depth-2 majority circuits) imply PAC-learning algorithms in a new distributional variant of Valiant's model. Our distributional PAC model is stronger than the average-case prediction model of Blum et al (1993) and the heuristic PAC model of Nanashima (2021), and has several important properties which make it of independent interest, such as being boosting-friendly. The main applications of our result are new distributional PAC-learning algorithms for depth-2 majority circuits, polytopes and DNFs over natural target distributions, as well as the nonexistence of encoded-input weak PRFs that can be evaluated by depth-2 majority circuits.
Dementia Assessment Using Mandarin Speech with an Attention-based Speech Recognition Encoder
Oct 06, 2023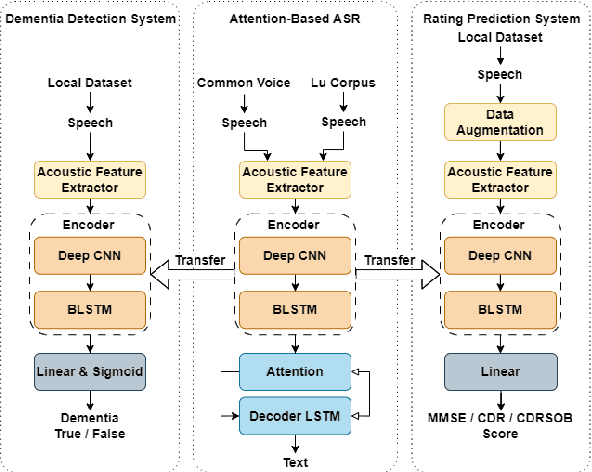
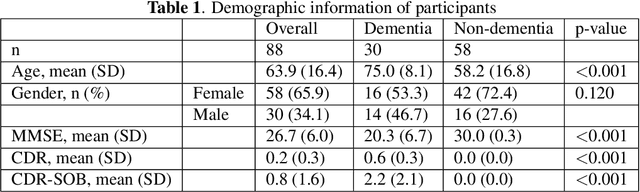
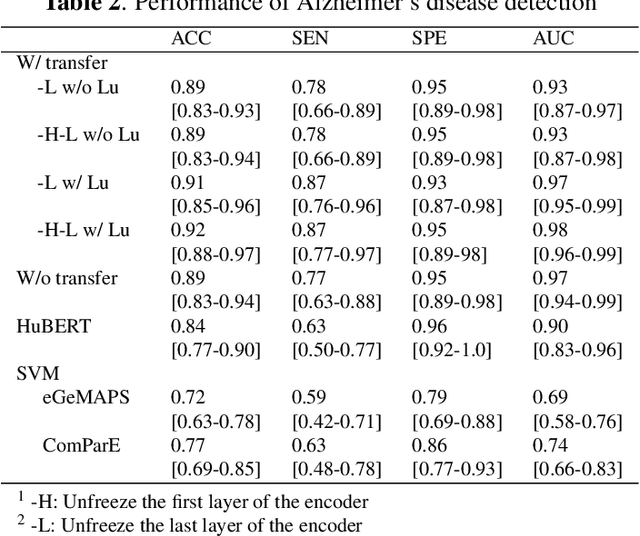
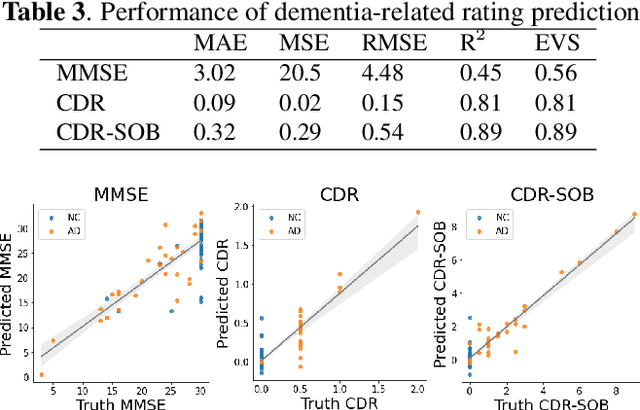
Dementia diagnosis requires a series of different testing methods, which is complex and time-consuming. Early detection of dementia is crucial as it can prevent further deterioration of the condition. This paper utilizes a speech recognition model to construct a dementia assessment system tailored for Mandarin speakers during the picture description task. By training an attention-based speech recognition model on voice data closely resembling real-world scenarios, we have significantly enhanced the model's recognition capabilities. Subsequently, we extracted the encoder from the speech recognition model and added a linear layer for dementia assessment. We collected Mandarin speech data from 99 subjects and acquired their clinical assessments from a local hospital. We achieved an accuracy of 92.04% in Alzheimer's disease detection and a mean absolute error of 9% in clinical dementia rating score prediction.