 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Relational Inference with Fast Modular Meta-learning
Oct 10, 2023
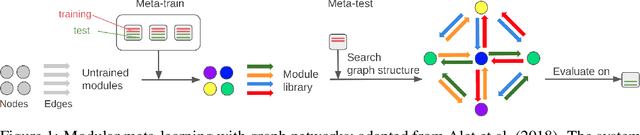
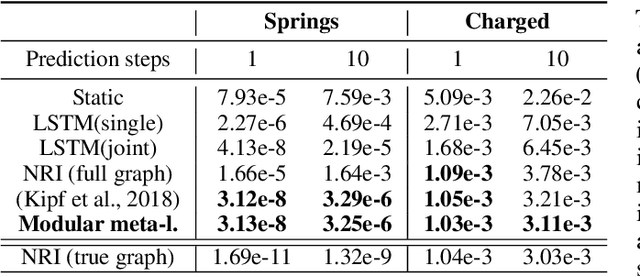
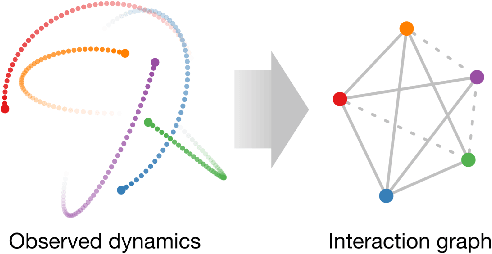
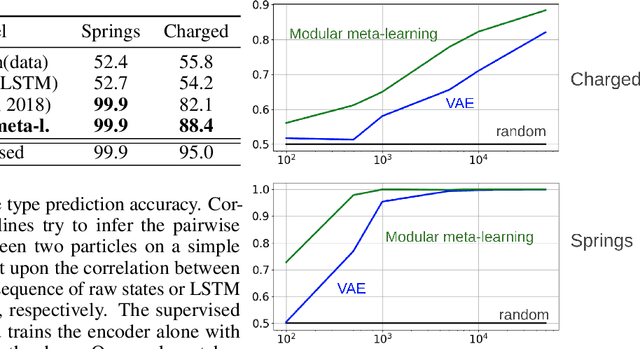
\textit{Graph neural networks} (GNNs) are effective models for many dynamical systems consisting of entities and relations. Although most GNN applications assume a single type of entity and relation, many situations involve multiple types of interactions. \textit{Relational inference} is the problem of inferring these interactions and learning the dynamics from observational data. We frame relational inference as a \textit{modular meta-learning} problem, where neural modules are trained to be composed in different ways to solve many tasks. This meta-learning framework allows us to implicitly encode time invariance and infer relations in context of one another rather than independently, which increases inference capacity. Framing inference as the inner-loop optimization of meta-learning leads to a model-based approach that is more data-efficient and capable of estimating the state of entities that we do not observe directly, but whose existence can be inferred from their effect on observed entities. To address the large search space of graph neural network compositions, we meta-learn a \textit{proposal function} that speeds up the inner-loop simulated annealing search within the modular meta-learning algorithm, providing two orders of magnitude increase in the size of problems that can be addressed.
DeepLSH: Deep Locality-Sensitive Hash Learning for Fast and Efficient Near-Duplicate Crash Report Detection
Oct 10, 2023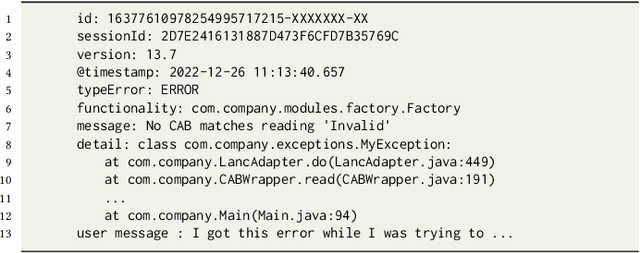
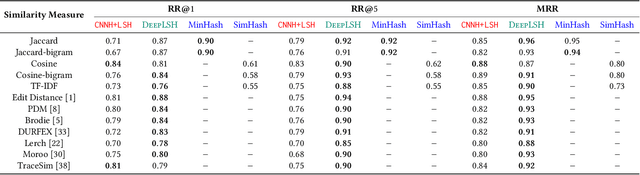
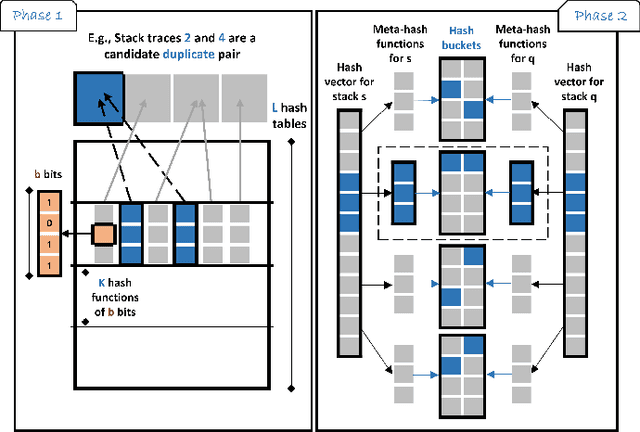
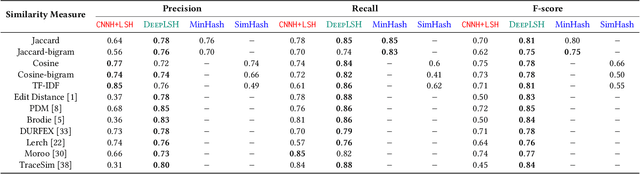
Automatic crash bucketing is a crucial phase in the software development process for efficiently triaging bug reports. It generally consists in grouping similar reports through clustering techniques. However, with real-time streaming bug collection, systems are needed to quickly answer the question: What are the most similar bugs to a new one?, that is, efficiently find near-duplicates. It is thus natural to consider nearest neighbors search to tackle this problem and especially the well-known locality-sensitive hashing (LSH) to deal with large datasets due to its sublinear performance and theoretical guarantees on the similarity search accuracy. Surprisingly, LSH has not been considered in the crash bucketing literature. It is indeed not trivial to derive hash functions that satisfy the so-called locality-sensitive property for the most advanced crash bucketing metrics. Consequently, we study in this paper how to leverage LSH for this task. To be able to consider the most relevant metrics used in the literature, we introduce DeepLSH, a Siamese DNN architecture with an original loss function, that perfectly approximates the locality-sensitivity property even for Jaccard and Cosine metrics for which exact LSH solutions exist. We support this claim with a series of experiments on an original dataset, which we make available.
Pi-DUAL: Using Privileged Information to Distinguish Clean from Noisy Labels
Oct 10, 2023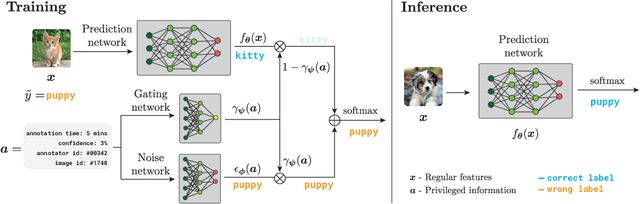

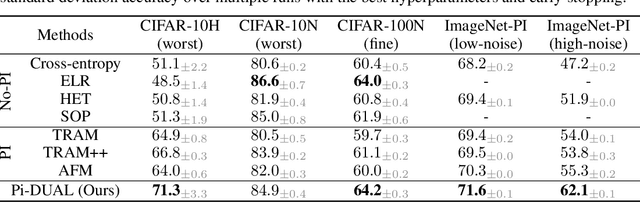
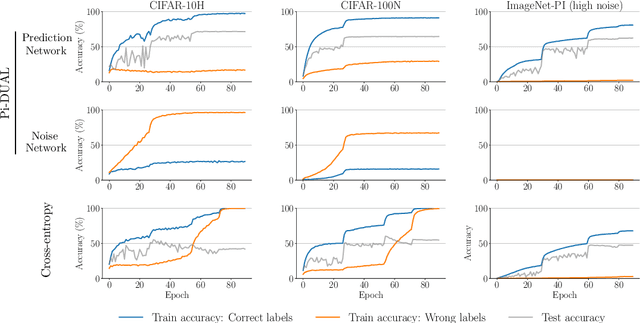
Label noise is a pervasive problem in deep learning that often compromises the generalization performance of trained models. Recently, leveraging privileged information (PI) -- information available only during training but not at test time -- has emerged as an effective approach to mitigate this issue. Yet, existing PI-based methods have failed to consistently outperform their no-PI counterparts in terms of preventing overfitting to label noise. To address this deficiency, we introduce Pi-DUAL, an architecture designed to harness PI to distinguish clean from wrong labels. Pi-DUAL decomposes the output logits into a prediction term, based on conventional input features, and a noise-fitting term influenced solely by PI. A gating mechanism steered by PI adaptively shifts focus between these terms, allowing the model to implicitly separate the learning paths of clean and wrong labels. Empirically, Pi-DUAL achieves significant performance improvements on key PI benchmarks (e.g., +6.8% on ImageNet-PI), establishing a new state-of-the-art test set accuracy. Additionally, Pi-DUAL is a potent method for identifying noisy samples post-training, outperforming other strong methods at this task. Overall, Pi-DUAL is a simple, scalable and practical approach for mitigating the effects of label noise in a variety of real-world scenarios with PI.
Realizing Stabilized Landing for Computation-Limited Reusable Rockets: A Quantum Reinforcement Learning Approach
Oct 10, 2023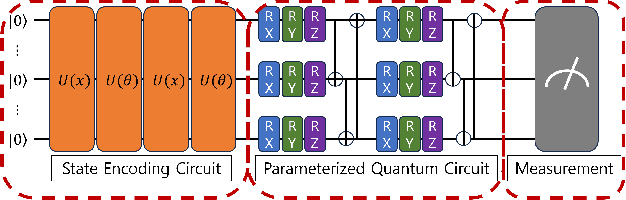
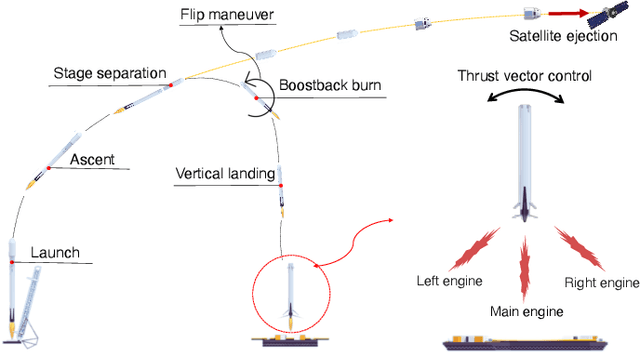
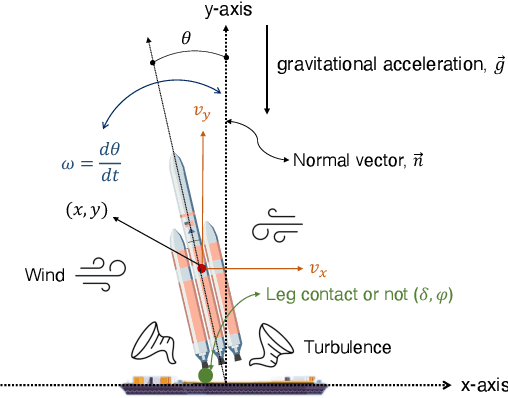
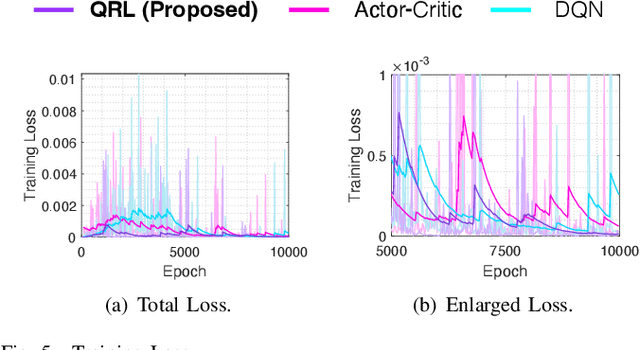
The advent of reusable rockets has heralded a new era in space exploration, reducing the costs of launching satellites by a significant factor. Traditional rockets were disposable, but the design of reusable rockets for repeated use has revolutionized the financial dynamics of space missions. The most critical phase of reusable rockets is the landing stage, which involves managing the tremendous speed and attitude for safe recovery. The complexity of this task presents new challenges for control systems, specifically in terms of precision and adaptability. Classical control systems like the proportional-integral-derivative (PID) controller lack the flexibility to adapt to dynamic system changes, making them costly and time-consuming to redesign of controller. This paper explores the integration of quantum reinforcement learning into the control systems of reusable rockets as a promising alternative. Unlike classical reinforcement learning, quantum reinforcement learning uses quantum bits that can exist in superposition, allowing for more efficient information encoding and reducing the number of parameters required. This leads to increased computational efficiency, reduced memory requirements, and more stable and predictable performance. Due to the nature of reusable rockets, which must be light, heavy computers cannot fit into them. In the reusable rocket scenario, quantum reinforcement learning, which has reduced memory requirements due to fewer parameters, is a good solution.
A Novel Contrastive Learning Method for Clickbait Detection on RoCliCo: A Romanian Clickbait Corpus of News Articles
Oct 10, 2023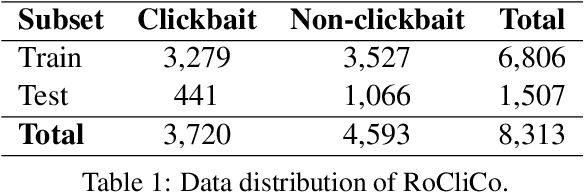
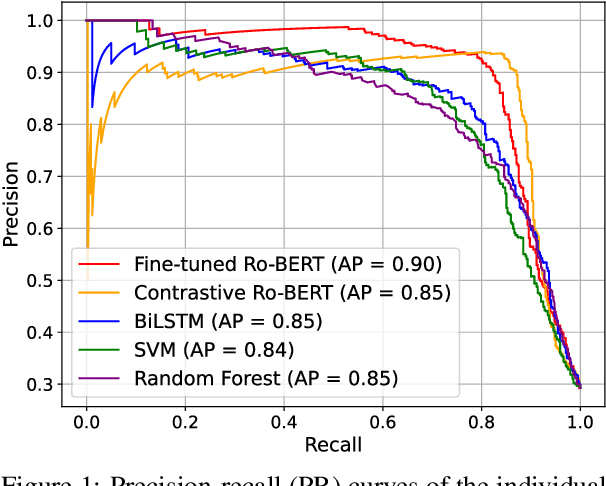
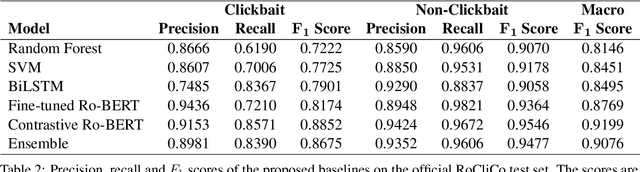
To increase revenue, news websites often resort to using deceptive news titles, luring users into clicking on the title and reading the full news. Clickbait detection is the task that aims to automatically detect this form of false advertisement and avoid wasting the precious time of online users. Despite the importance of the task, to the best of our knowledge, there is no publicly available clickbait corpus for the Romanian language. To this end, we introduce a novel Romanian Clickbait Corpus (RoCliCo) comprising 8,313 news samples which are manually annotated with clickbait and non-clickbait labels. Furthermore, we conduct experiments with four machine learning methods, ranging from handcrafted models to recurrent and transformer-based neural networks, to establish a line-up of competitive baselines. We also carry out experiments with a weighted voting ensemble. Among the considered baselines, we propose a novel BERT-based contrastive learning model that learns to encode news titles and contents into a deep metric space such that titles and contents of non-clickbait news have high cosine similarity, while titles and contents of clickbait news have low cosine similarity. Our data set and code to reproduce the baselines are publicly available for download at https://github.com/dariabroscoteanu/RoCliCo.
Boundary Discretization and Reliable Classification Network for Temporal Action Detection
Oct 10, 2023
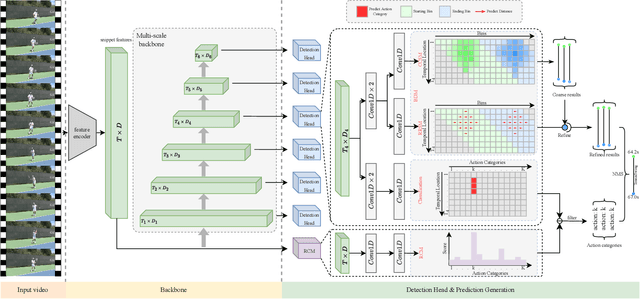
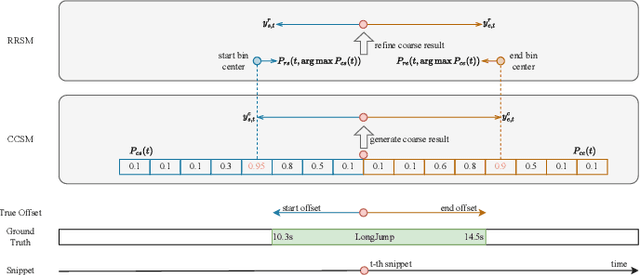
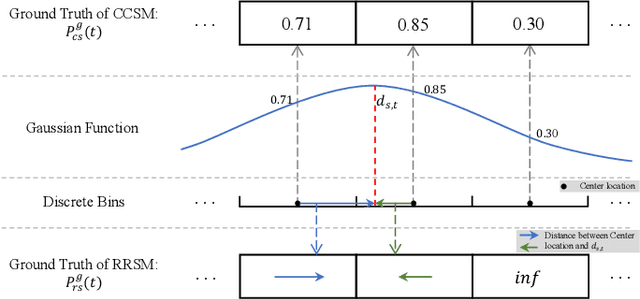
Temporal action detection aims to recognize the action category and determine the starting and ending time of each action instance in untrimmed videos. The mixed methods have achieved remarkable performance by simply merging anchor-based and anchor-free approaches. However, there are still two crucial issues in the mixed framework: (1) Brute-force merging and handcrafted anchors design affect the performance and practical application of the mixed methods. (2) A large number of false positives in action category predictions further impact the detection performance. In this paper, we propose a novel Boundary Discretization and Reliable Classification Network (BDRC-Net) that addresses the above issues by introducing boundary discretization and reliable classification modules. Specifically, the boundary discretization module (BDM) elegantly merges anchor-based and anchor-free approaches in the form of boundary discretization, avoiding the handcrafted anchors design required by traditional mixed methods. Furthermore, the reliable classification module (RCM) predicts reliable action categories to reduce false positives in action category predictions. Extensive experiments conducted on different benchmarks demonstrate that our proposed method achieves favorable performance compared with the state-of-the-art. For example, BDRC-Net hits an average mAP of 68.6% on THUMOS'14, outperforming the previous best by 1.5%. The code will be released at https://github.com/zhenyingfang/BDRC-Net.
Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
Oct 10, 2023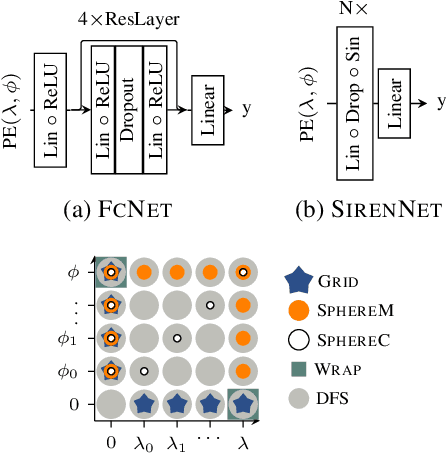
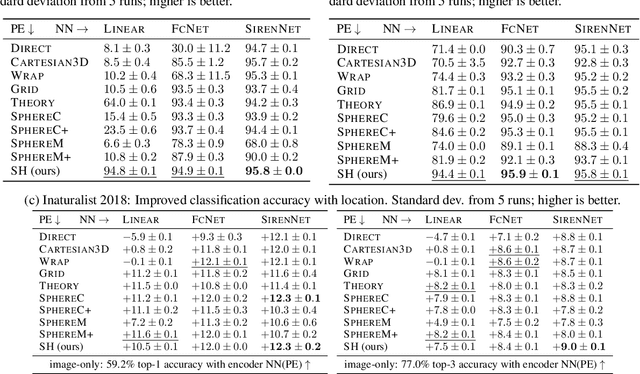
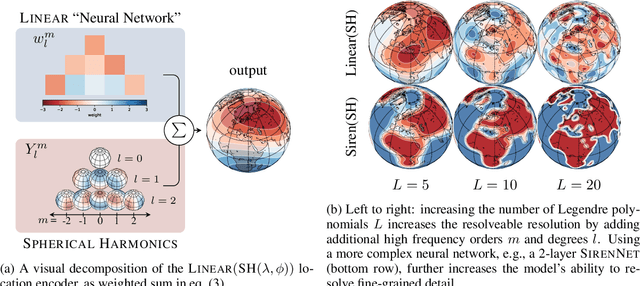
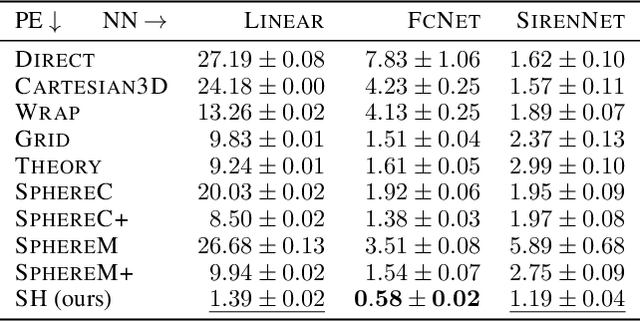
Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at www.github.com/marccoru/locationencoder
Streaming Probabilistic PCA for Missing Data with Heteroscedastic Noise
Oct 10, 2023Streaming principal component analysis (PCA) is an integral tool in large-scale machine learning for rapidly estimating low-dimensional subspaces of very high dimensional and high arrival-rate data with missing entries and corrupting noise. However, modern trends increasingly combine data from a variety of sources, meaning they may exhibit heterogeneous quality across samples. Since standard streaming PCA algorithms do not account for non-uniform noise, their subspace estimates can quickly degrade. On the other hand, the recently proposed Heteroscedastic Probabilistic PCA Technique (HePPCAT) addresses this heterogeneity, but it was not designed to handle missing entries and streaming data, nor does it adapt to non-stationary behavior in time series data. This paper proposes the Streaming HeteroscedASTic Algorithm for PCA (SHASTA-PCA) to bridge this divide. SHASTA-PCA employs a stochastic alternating expectation maximization approach that jointly learns the low-rank latent factors and the unknown noise variances from streaming data that may have missing entries and heteroscedastic noise, all while maintaining a low memory and computational footprint. Numerical experiments validate the superior subspace estimation of our method compared to state-of-the-art streaming PCA algorithms in the heteroscedastic setting. Finally, we illustrate SHASTA-PCA applied to highly-heterogeneous real data from astronomy.
Enhancing Cross-Dataset Performance of Distracted Driving Detection With Score-Softmax Classifier
Oct 10, 2023Deep neural networks enable real-time monitoring of in-vehicle driver, facilitating the timely prediction of distractions, fatigue, and potential hazards. This technology is now integral to intelligent transportation systems. Recent research has exposed unreliable cross-dataset end-to-end driver behavior recognition due to overfitting, often referred to as ``shortcut learning", resulting from limited data samples. In this paper, we introduce the Score-Softmax classifier, which addresses this issue by enhancing inter-class independence and Intra-class uncertainty. Motivated by human rating patterns, we designed a two-dimensional supervisory matrix based on marginal Gaussian distributions to train the classifier. Gaussian distributions help amplify intra-class uncertainty while ensuring the Score-Softmax classifier learns accurate knowledge. Furthermore, leveraging the summation of independent Gaussian distributed random variables, we introduced a multi-channel information fusion method. This strategy effectively resolves the multi-information fusion challenge for the Score-Softmax classifier. Concurrently, we substantiate the necessity of transfer learning and multi-dataset combination. We conducted cross-dataset experiments using the SFD, AUCDD-V1, and 100-Driver datasets, demonstrating that Score-Softmax improves cross-dataset performance without modifying the model architecture. This provides a new approach for enhancing neural network generalization. Additionally, our information fusion approach outperforms traditional methods.
Electrical Grid Anomaly Detection via Tensor Decomposition
Oct 12, 2023Supervisory Control and Data Acquisition (SCADA) systems often serve as the nervous system for substations within power grids. These systems facilitate real-time monitoring, data acquisition, control of equipment, and ensure smooth and efficient operation of the substation and its connected devices. Previous work has shown that dimensionality reduction-based approaches, such as Principal Component Analysis (PCA), can be used for accurate identification of anomalies in SCADA systems. While not specifically applied to SCADA, non-negative matrix factorization (NMF) has shown strong results at detecting anomalies in wireless sensor networks. These unsupervised approaches model the normal or expected behavior and detect the unseen types of attacks or anomalies by identifying the events that deviate from the expected behavior. These approaches; however, do not model the complex and multi-dimensional interactions that are naturally present in SCADA systems. Differently, non-negative tensor decomposition is a powerful unsupervised machine learning (ML) method that can model the complex and multi-faceted activity details of SCADA events. In this work, we novelly apply the tensor decomposition method Canonical Polyadic Alternating Poisson Regression (CP-APR) with a probabilistic framework, which has previously shown state-of-the-art anomaly detection results on cyber network data, to identify anomalies in SCADA systems. We showcase that the use of statistical behavior analysis of SCADA communication with tensor decomposition improves the specificity and accuracy of identifying anomalies in electrical grid systems. In our experiments, we model real-world SCADA system data collected from the electrical grid operated by Los Alamos National Laboratory (LANL) which provides transmission and distribution service through a partnership with Los Alamos County, and detect synthetically generated anomalies.