 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sequential Data Generation with Groupwise Diffusion Process
Oct 02, 2023
We present the Groupwise Diffusion Model (GDM), which divides data into multiple groups and diffuses one group at one time interval in the forward diffusion process. GDM generates data sequentially from one group at one time interval, leading to several interesting properties. First, as an extension of diffusion models, GDM generalizes certain forms of autoregressive models and cascaded diffusion models. As a unified framework, GDM allows us to investigate design choices that have been overlooked in previous works, such as data-grouping strategy and order of generation. Furthermore, since one group of the initial noise affects only a certain group of the generated data, latent space now possesses group-wise interpretable meaning. We can further extend GDM to the frequency domain where the forward process sequentially diffuses each group of frequency components. Dividing the frequency bands of the data as groups allows the latent variables to become a hierarchical representation where individual groups encode data at different levels of abstraction. We demonstrate several applications of such representation including disentanglement of semantic attributes, image editing, and generating variations.
DYNAP-SE2: a scalable multi-core dynamic neuromorphic asynchronous spiking neural network processor
Oct 01, 2023With the remarkable progress that technology has made, the need for processing data near the sensors at the edge has increased dramatically. The electronic systems used in these applications must process data continuously, in real-time, and extract relevant information using the smallest possible energy budgets. A promising approach for implementing always-on processing of sensory signals that supports on-demand, sparse, and edge-computing is to take inspiration from biological nervous system. Following this approach, we present a brain-inspired platform for prototyping real-time event-based Spiking Neural Networks (SNNs). The system proposed supports the direct emulation of dynamic and realistic neural processing phenomena such as short-term plasticity, NMDA gating, AMPA diffusion, homeostasis, spike frequency adaptation, conductance-based dendritic compartments and spike transmission delays. The analog circuits that implement such primitives are paired with a low latency asynchronous digital circuits for routing and mapping events. This asynchronous infrastructure enables the definition of different network architectures, and provides direct event-based interfaces to convert and encode data from event-based and continuous-signal sensors. Here we describe the overall system architecture, we characterize the mixed signal analog-digital circuits that emulate neural dynamics, demonstrate their features with experimental measurements, and present a low- and high-level software ecosystem that can be used for configuring the system. The flexibility to emulate different biologically plausible neural networks, and the chip's ability to monitor both population and single neuron signals in real-time, allow to develop and validate complex models of neural processing for both basic research and edge-computing applications.
Measuring Acoustics with Collaborative Multiple Agents
Oct 09, 2023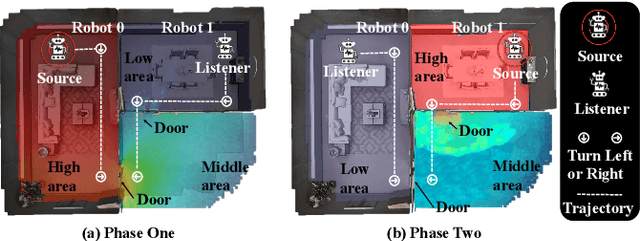
As humans, we hear sound every second of our life. The sound we hear is often affected by the acoustics of the environment surrounding us. For example, a spacious hall leads to more reverberation. Room Impulse Responses (RIR) are commonly used to characterize environment acoustics as a function of the scene geometry, materials, and source/receiver locations. Traditionally, RIRs are measured by setting up a loudspeaker and microphone in the environment for all source/receiver locations, which is time-consuming and inefficient. We propose to let two robots measure the environment's acoustics by actively moving and emitting/receiving sweep signals. We also devise a collaborative multi-agent policy where these two robots are trained to explore the environment's acoustics while being rewarded for wide exploration and accurate prediction. We show that the robots learn to collaborate and move to explore environment acoustics while minimizing the prediction error. To the best of our knowledge, we present the very first problem formulation and solution to the task of collaborative environment acoustics measurements with multiple agents.
STREAM: Social data and knowledge collective intelligence platform for TRaining Ethical AI Models
Oct 09, 2023This paper presents Social data and knowledge collective intelligence platform for TRaining Ethical AI Models (STREAM) to address the challenge of aligning AI models with human moral values, and to provide ethics datasets and knowledge bases to help promote AI models "follow good advice as naturally as a stream follows its course". By creating a comprehensive and representative platform that accurately mirrors the moral judgments of diverse groups including humans and AIs, we hope to effectively portray cultural and group variations, and capture the dynamic evolution of moral judgments over time, which in turn will facilitate the Establishment, Evaluation, Embedding, Embodiment, Ensemble, and Evolvement (6Es) of the moral capabilities of AI models. Currently, STREAM has already furnished a comprehensive collection of ethical scenarios, and amassed substantial moral judgment data annotated by volunteers and various popular Large Language Models (LLMs), collectively portraying the moral preferences and performances of both humans and AIs across a range of moral contexts. This paper will outline the current structure and construction of STREAM, explore its potential applications, and discuss its future prospects.
QUANT: A Minimalist Interval Method for Time Series Classification
Aug 02, 2023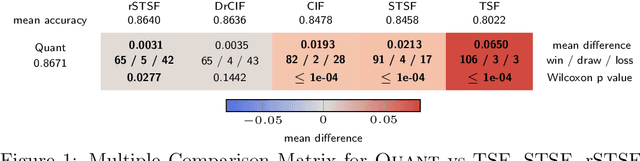
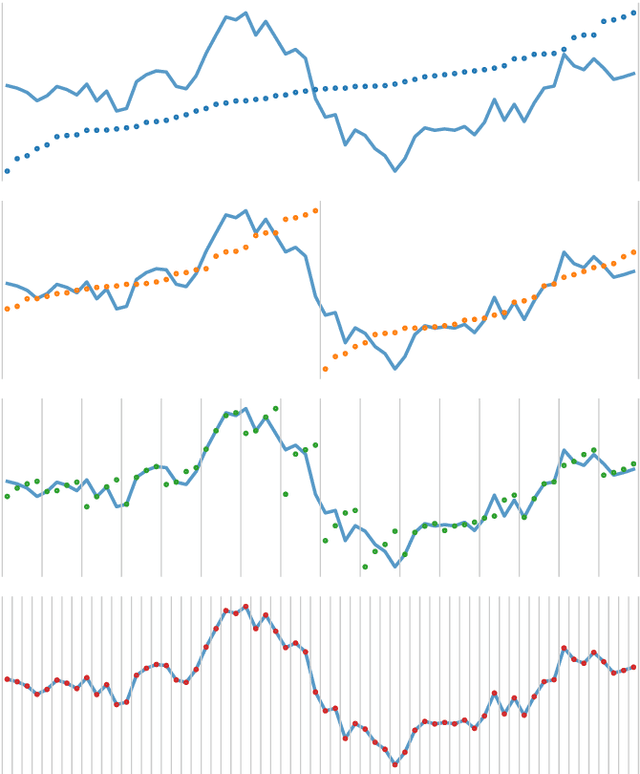
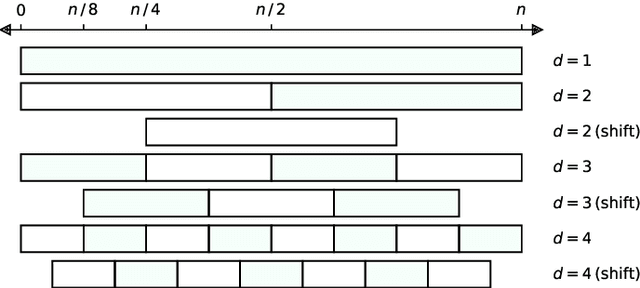
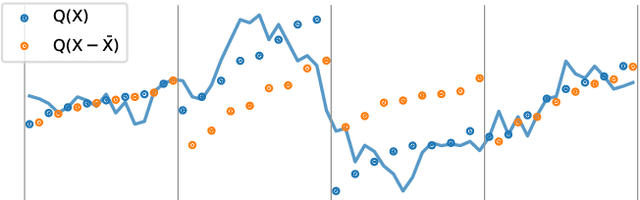
We show that it is possible to achieve the same accuracy, on average, as the most accurate existing interval methods for time series classification on a standard set of benchmark datasets using a single type of feature (quantiles), fixed intervals, and an 'off the shelf' classifier. This distillation of interval-based approaches represents a fast and accurate method for time series classification, achieving state-of-the-art accuracy on the expanded set of 142 datasets in the UCR archive with a total compute time (training and inference) of less than 15 minutes using a single CPU core.
Improving Stability in Simultaneous Speech Translation: A Revision-Controllable Decoding Approach
Oct 06, 2023Simultaneous Speech-to-Text translation serves a critical role in real-time crosslingual communication. Despite the advancements in recent years, challenges remain in achieving stability in the translation process, a concern primarily manifested in the flickering of partial results. In this paper, we propose a novel revision-controllable method designed to address this issue. Our method introduces an allowed revision window within the beam search pruning process to screen out candidate translations likely to cause extensive revisions, leading to a substantial reduction in flickering and, crucially, providing the capability to completely eliminate flickering. The experiments demonstrate the proposed method can significantly improve the decoding stability without compromising substantially on the translation quality.
Nash Welfare and Facility Location
Oct 06, 2023We consider the problem of locating a facility to serve a set of agents located along a line. The Nash welfare objective function, defined as the product of the agents' utilities, is known to provide a compromise between fairness and efficiency in resource allocation problems. We apply this welfare notion to the facility location problem, converting individual costs to utilities and analyzing the facility placement that maximizes the Nash welfare. We give a polynomial-time approximation algorithm to compute this facility location, and prove results suggesting that it achieves a good balance of fairness and efficiency. Finally, we take a mechanism design perspective and propose a strategy-proof mechanism with a bounded approximation ratio for Nash welfare.
Hierarchical Topological Ordering with Conditional Independence Test for Limited Time Series
Aug 16, 2023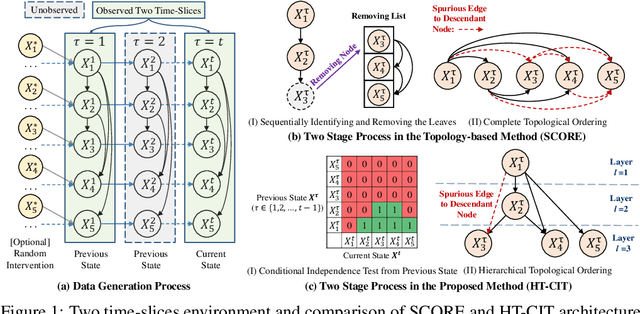
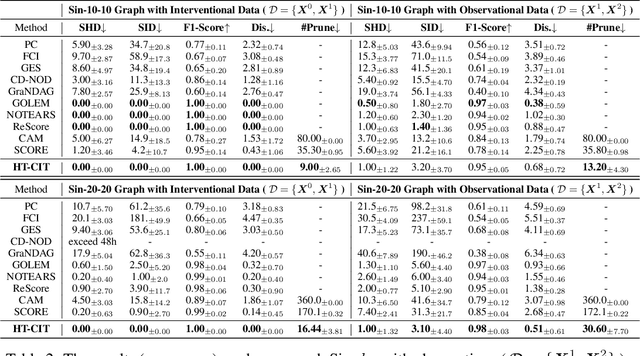

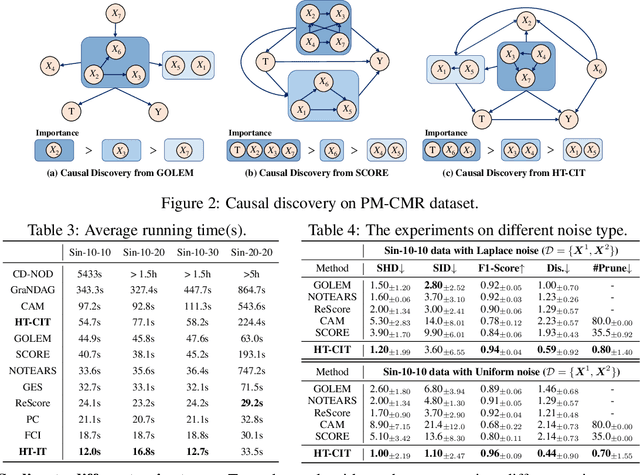
Learning directed acyclic graphs (DAGs) to identify causal relations underlying observational data is crucial but also poses significant challenges. Recently, topology-based methods have emerged as a two-step approach to discovering DAGs by first learning the topological ordering of variables and then eliminating redundant edges, while ensuring that the graph remains acyclic. However, one limitation is that these methods would generate numerous spurious edges that require subsequent pruning. To overcome this limitation, in this paper, we propose an improvement to topology-based methods by introducing limited time series data, consisting of only two cross-sectional records that need not be adjacent in time and are subject to flexible timing. By incorporating conditional instrumental variables as exogenous interventions, we aim to identify descendant nodes for each variable. Following this line, we propose a hierarchical topological ordering algorithm with conditional independence test (HT-CIT), which enables the efficient learning of sparse DAGs with a smaller search space compared to other popular approaches. The HT-CIT algorithm greatly reduces the number of edges that need to be pruned. Empirical results from synthetic and real-world datasets demonstrate the superiority of the proposed HT-CIT algorithm.
SE(3)-Stochastic Flow Matching for Protein Backbone Generation
Oct 03, 2023The computational design of novel protein structures has the potential to impact numerous scientific disciplines greatly. Toward this goal, we introduce $\text{FoldFlow}$ a series of novel generative models of increasing modeling power based on the flow-matching paradigm over $3\text{D}$ rigid motions -- i.e. the group $\text{SE(3)}$ -- enabling accurate modeling of protein backbones. We first introduce $\text{FoldFlow-Base}$, a simulation-free approach to learning deterministic continuous-time dynamics and matching invariant target distributions on $\text{SE(3)}$. We next accelerate training by incorporating Riemannian optimal transport to create $\text{FoldFlow-OT}$, leading to the construction of both more simple and stable flows. Finally, we design $\text{FoldFlow-SFM}$ coupling both Riemannian OT and simulation-free training to learn stochastic continuous-time dynamics over $\text{SE(3)}$. Our family of $\text{FoldFlow}$ generative models offer several key advantages over previous approaches to the generative modeling of proteins: they are more stable and faster to train than diffusion-based approaches, and our models enjoy the ability to map any invariant source distribution to any invariant target distribution over $\text{SE(3)}$. Empirically, we validate our FoldFlow models on protein backbone generation of up to $300$ amino acids leading to high-quality designable, diverse, and novel samples.
Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
Oct 10, 2023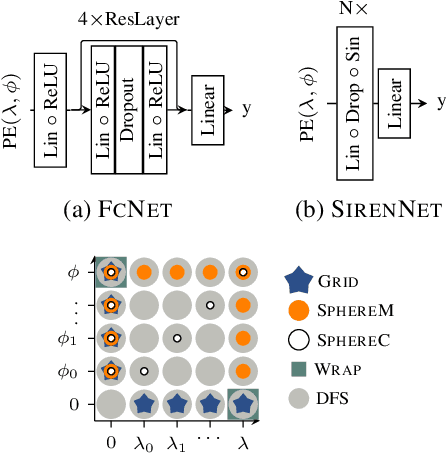
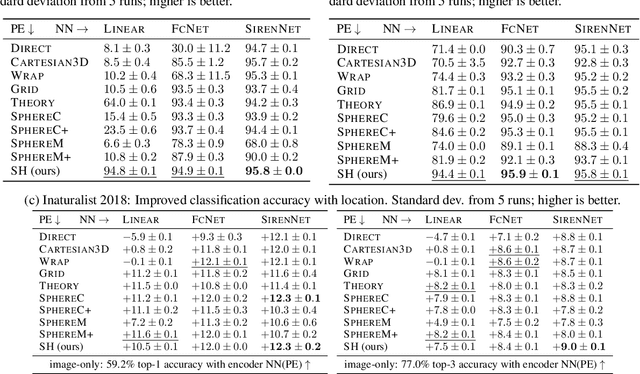
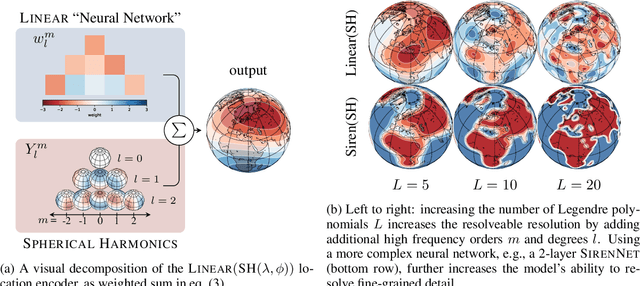
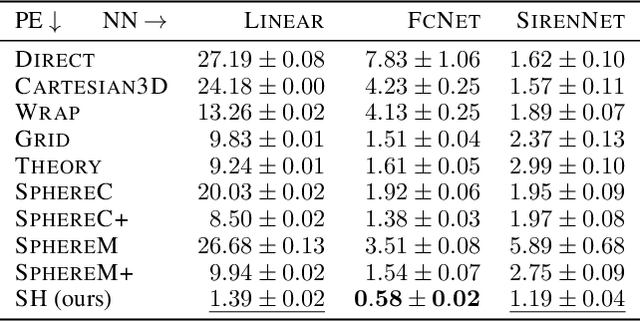
Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at www.github.com/marccoru/locationencoder