 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning the mechanisms of network growth
Mar 31, 2024
We propose a novel model-selection method for dynamic real-life networks. Our approach involves training a classifier on a large body of synthetic network data. The data is generated by simulating nine state-of-the-art random graph models for dynamic networks, with parameter range chosen to ensure exponential growth of the network size in time. We design a conceptually novel type of dynamic features that count new links received by a group of vertices in a particular time interval. The proposed features are easy to compute, analytically tractable, and interpretable. Our approach achieves a near-perfect classification of synthetic networks, exceeding the state-of-the-art by a large margin. Applying our classification method to real-world citation networks gives credibility to the claims in the literature that models with preferential attachment, fitness and aging fit real-world citation networks best, although sometimes, the predicted model does not involve vertex fitness.
On the Efficiency and Robustness of Vibration-based Foundation Models for IoT Sensing: A Case Study
Apr 03, 2024This paper demonstrates the potential of vibration-based Foundation Models (FMs), pre-trained with unlabeled sensing data, to improve the robustness of run-time inference in (a class of) IoT applications. A case study is presented featuring a vehicle classification application using acoustic and seismic sensing. The work is motivated by the success of foundation models in the areas of natural language processing and computer vision, leading to generalizations of the FM concept to other domains as well, where significant amounts of unlabeled data exist that can be used for self-supervised pre-training. One such domain is IoT applications. Foundation models for selected sensing modalities in the IoT domain can be pre-trained in an environment-agnostic fashion using available unlabeled sensor data and then fine-tuned to the deployment at hand using a small amount of labeled data. The paper shows that the pre-training/fine-tuning approach improves the robustness of downstream inference and facilitates adaptation to different environmental conditions. More specifically, we present a case study in a real-world setting to evaluate a simple (vibration-based) FM-like model, called FOCAL, demonstrating its superior robustness and adaptation, compared to conventional supervised deep neural networks (DNNs). We also demonstrate its superior convergence over supervised solutions. Our findings highlight the advantages of vibration-based FMs (and FM-inspired selfsupervised models in general) in terms of inference robustness, runtime efficiency, and model adaptation (via fine-tuning) in resource-limited IoT settings.
Assessing ML Classification Algorithms and NLP Techniques for Depression Detection: An Experimental Case Study
Apr 03, 2024Depression has affected millions of people worldwide and has become one of the most common mental disorders. Early mental disorder detection can reduce costs for public health agencies and prevent other major comorbidities. Additionally, the shortage of specialized personnel is very concerning since Depression diagnosis is highly dependent on expert professionals and is time-consuming. Recent research has evidenced that machine learning (ML) and Natural Language Processing (NLP) tools and techniques have significantly bene ted the diagnosis of depression. However, there are still several challenges in the assessment of depression detection approaches in which other conditions such as post-traumatic stress disorder (PTSD) are present. These challenges include assessing alternatives in terms of data cleaning and pre-processing techniques, feature selection, and appropriate ML classification algorithms. This paper tackels such an assessment based on a case study that compares different ML classifiers, specifically in terms of data cleaning and pre-processing, feature selection, parameter setting, and model choices. The case study is based on the Distress Analysis Interview Corpus - Wizard-of-Oz (DAIC-WOZ) dataset, which is designed to support the diagnosis of mental disorders such as depression, anxiety, and PTSD. Besides the assessment of alternative techniques, we were able to build models with accuracy levels around 84% with Random Forest and XGBoost models, which is significantly higher than the results from the comparable literature which presented the level of accuracy of 72% from the SVM model.
Deep Image Composition Meets Image Forgery
Apr 03, 2024Image forgery is a topic that has been studied for many years. Before the breakthrough of deep learning, forged images were detected using handcrafted features that did not require training. These traditional methods failed to perform satisfactorily even on datasets much worse in quality than real-life image manipulations. Advances in deep learning have impacted image forgery detection as much as they have impacted other areas of computer vision and have improved the state of the art. Deep learning models require large amounts of labeled data for training. In the case of image forgery, labeled data at the pixel level is a very important factor for the models to learn. None of the existing datasets have sufficient size, realism and pixel-level labeling at the same time. This is due to the high cost of producing and labeling quality images. It can take hours for an image editing expert to manipulate just one image. To bridge this gap, we automate data generation using image composition techniques that are very related to image forgery. Unlike other automated data generation frameworks, we use state of the art image composition deep learning models to generate spliced images close to the quality of real-life manipulations. Finally, we test the generated dataset on the SOTA image manipulation detection model and show that its prediction performance is lower compared to existing datasets, i.e. we produce realistic images that are more difficult to detect. Dataset will be available at https://github.com/99eren99/DIS25k .
Neuromorphic Split Computing with Wake-Up Radios: Architecture and Design via Digital Twinning
Apr 03, 2024Neuromorphic computing leverages the sparsity of temporal data to reduce processing energy by activating a small subset of neurons and synapses at each time step. When deployed for split computing in edge-based systems, remote neuromorphic processing units (NPUs) can reduce the communication power budget by communicating asynchronously using sparse impulse radio (IR) waveforms. This way, the input signal sparsity translates directly into energy savings both in terms of computation and communication. However, with IR transmission, the main contributor to the overall energy consumption remains the power required to maintain the main radio on. This work proposes a novel architecture that integrates a wake-up radio mechanism within a split computing system consisting of remote, wirelessly connected, NPUs. A key challenge in the design of a wake-up radio-based neuromorphic split computing system is the selection of thresholds for sensing, wake-up signal detection, and decision making. To address this problem, as a second contribution, this work proposes a novel methodology that leverages the use of a digital twin (DT), i.e., a simulator, of the physical system, coupled with a sequential statistical testing approach known as Learn Then Test (LTT) to provide theoretical reliability guarantees. The proposed DT-LTT methodology is broadly applicable to other design problems, and is showcased here for neuromorphic communications. Experimental results validate the design and the analysis, confirming the theoretical reliability guarantees and illustrating trade-offs among reliability, energy consumption, and informativeness of the decisions.
STG-Mamba: Spatial-Temporal Graph Learning via Selective State Space Model
Mar 31, 2024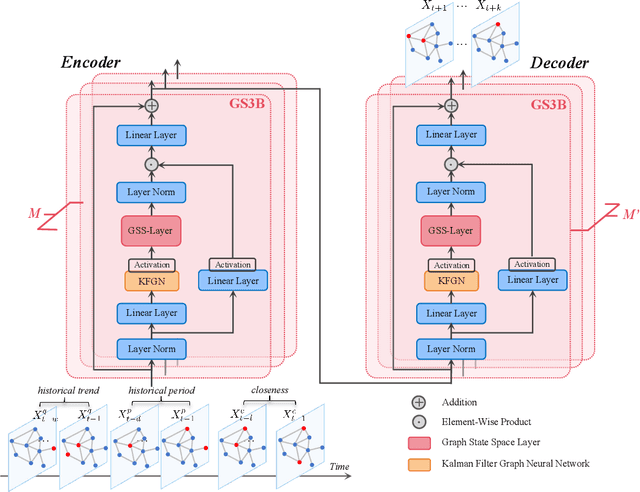
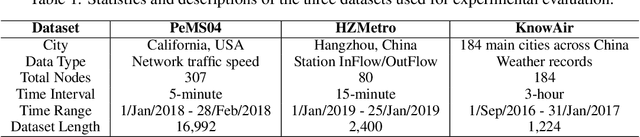
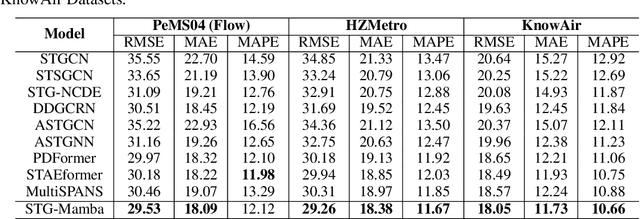
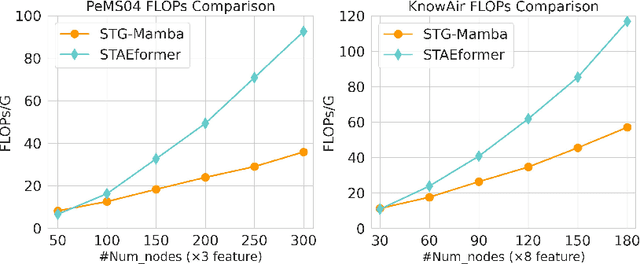
Spatial-Temporal Graph (STG) data is characterized as dynamic, heterogenous, and non-stationary, leading to the continuous challenge of spatial-temporal graph learning. In the past few years, various GNN-based methods have been proposed to solely focus on mimicking the relationships among node individuals of the STG network, ignoring the significance of modeling the intrinsic features that exist in STG system over time. In contrast, modern Selective State Space Models (SSSMs) present a new approach which treat STG Network as a system, and meticulously explore the STG system's dynamic state evolution across temporal dimension. In this work, we introduce Spatial-Temporal Graph Mamba (STG-Mamba) as the first exploration of leveraging the powerful selective state space models for STG learning by treating STG Network as a system, and employing the Graph Selective State Space Block (GS3B) to precisely characterize the dynamic evolution of STG networks. STG-Mamba is formulated as an Encoder-Decoder architecture, which takes GS3B as the basic module, for efficient sequential data modeling. Furthermore, to strengthen GNN's ability of modeling STG data under the setting of SSSMs, we propose Kalman Filtering Graph Neural Networks (KFGN) for adaptive graph structure upgrading. KFGN smoothly fits in the context of selective state space evolution, and at the same time keeps linear complexity. Extensive empirical studies are conducted on three benchmark STG forecasting datasets, demonstrating the performance superiority and computational efficiency of STG-Mamba. It not only surpasses existing state-of-the-art methods in terms of STG forecasting performance, but also effectively alleviate the computational bottleneck of large-scale graph networks in reducing the computational cost of FLOPs and test inference time.
Continuous Sculpting: Persistent Swarm Shape Formation Adaptable to Local Environmental Changes
Apr 02, 2024Despite their growing popularity, swarms of robots remain limited by the operating time of each individual. We present algorithms which allow a human to sculpt a swarm of robots into a shape that persists in space perpetually, independent of onboard energy constraints such as batteries. Robots generate a path through a shape such that robots cycle in and out of the shape. Robots inside the shape react to human initiated changes and adapt the path through the shape accordingly. Robots outside the shape recharge and return to the shape so that the shape can persist indefinitely. The presented algorithms communicate shape changes throughout the swarm using message passing and robot motion. These algorithms enable the swarm to persist through any arbitrary changes to the shape. We describe these algorithms in detail and present their performance in simulation and on a swarm of mobile robots. The result is a swarm behavior more suitable for extended duration, dynamic shape-based tasks in applications such as agriculture and emergency response.
Insights from the Use of Previously Unseen Neural Architecture Search Datasets
Apr 02, 2024The boundless possibility of neural networks which can be used to solve a problem -- each with different performance -- leads to a situation where a Deep Learning expert is required to identify the best neural network. This goes against the hope of removing the need for experts. Neural Architecture Search (NAS) offers a solution to this by automatically identifying the best architecture. However, to date, NAS work has focused on a small set of datasets which we argue are not representative of real-world problems. We introduce eight new datasets created for a series of NAS Challenges: AddNIST, Language, MultNIST, CIFARTile, Gutenberg, Isabella, GeoClassing, and Chesseract. These datasets and challenges are developed to direct attention to issues in NAS development and to encourage authors to consider how their models will perform on datasets unknown to them at development time. We present experimentation using standard Deep Learning methods as well as the best results from challenge participants.
Learning Time Slot Preferences via Mobility Tree for Next POI Recommendation
Mar 17, 2024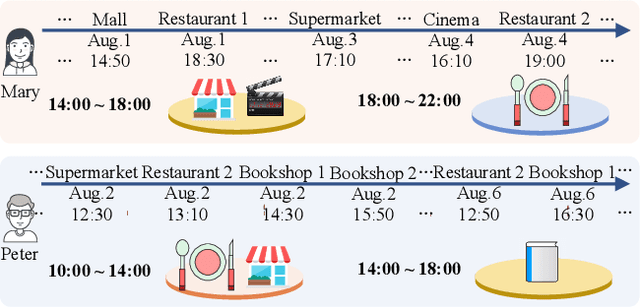
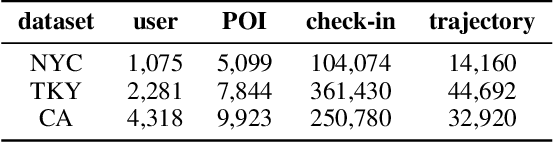
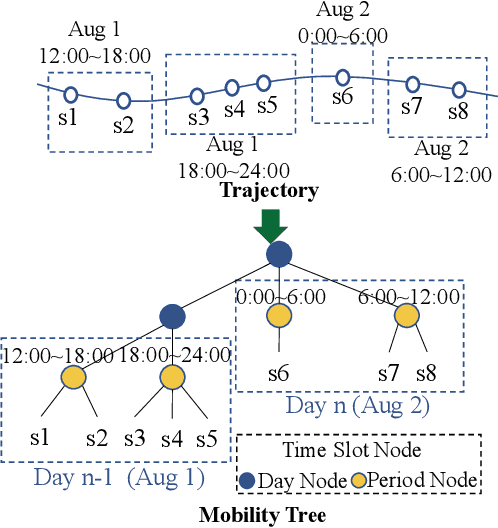
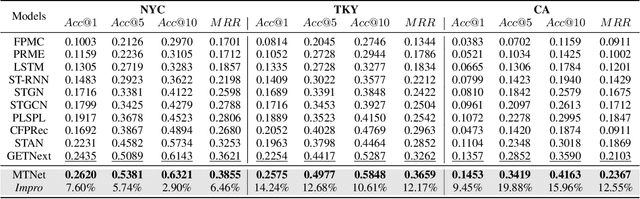
Next Point-of-Interests (POIs) recommendation task aims to provide a dynamic ranking of POIs based on users' current check-in trajectories. The recommendation performance of this task is contingent upon a comprehensive understanding of users' personalized behavioral patterns through Location-based Social Networks (LBSNs) data. While prior studies have adeptly captured sequential patterns and transitional relationships within users' check-in trajectories, a noticeable gap persists in devising a mechanism for discerning specialized behavioral patterns during distinct time slots, such as noon, afternoon, or evening. In this paper, we introduce an innovative data structure termed the ``Mobility Tree'', tailored for hierarchically describing users' check-in records. The Mobility Tree encompasses multi-granularity time slot nodes to learn user preferences across varying temporal periods. Meanwhile, we propose the Mobility Tree Network (MTNet), a multitask framework for personalized preference learning based on Mobility Trees. We develop a four-step node interaction operation to propagate feature information from the leaf nodes to the root node. Additionally, we adopt a multitask training strategy to push the model towards learning a robust representation. The comprehensive experimental results demonstrate the superiority of MTNet over ten state-of-the-art next POI recommendation models across three real-world LBSN datasets, substantiating the efficacy of time slot preference learning facilitated by Mobility Tree.
Efficient Motion Planning for Manipulators with Control Barrier Function-Induced Neural Controller
Apr 01, 2024Sampling-based motion planning methods for manipulators in crowded environments often suffer from expensive collision checking and high sampling complexity, which make them difficult to use in real time. To address this issue, we propose a new generalizable control barrier function (CBF)-based steering controller to reduce the number of samples needed in a sampling-based motion planner RRT. Our method combines the strength of CBF for real-time collision-avoidance control and RRT for long-horizon motion planning, by using CBF-induced neural controller (CBF-INC) to generate control signals that steer the system towards sampled configurations by RRT. CBF-INC is learned as Neural Networks and has two variants handling different inputs, respectively: state (signed distance) input and point-cloud input from LiDAR. In the latter case, we also study two different settings: fully and partially observed environmental information. Compared to manually crafted CBF which suffers from over-approximating robot geometry, CBF-INC can balance safety and goal-reaching better without being over-conservative. Given state-based input, our neural CBF-induced neural controller-enhanced RRT (CBF-INC-RRT) can increase the success rate by 14% while reducing the number of nodes explored by 30%, compared with vanilla RRT on hard test cases. Given LiDAR input where vanilla RRT is not directly applicable, we demonstrate that our CBF-INC-RRT can improve the success rate by 10%, compared with planning with other steering controllers. Our project page with supplementary material is at https://mit-realm.github.io/CBF-INC-RRT-website/.