 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Retail Demand Forecasting: A Comparative Study for Multivariate Time Series
Aug 23, 2023
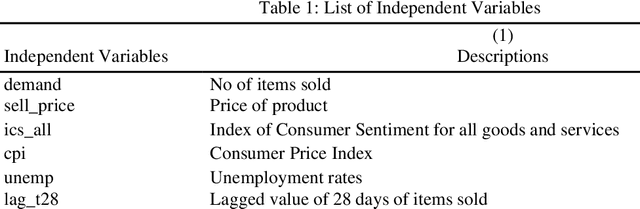
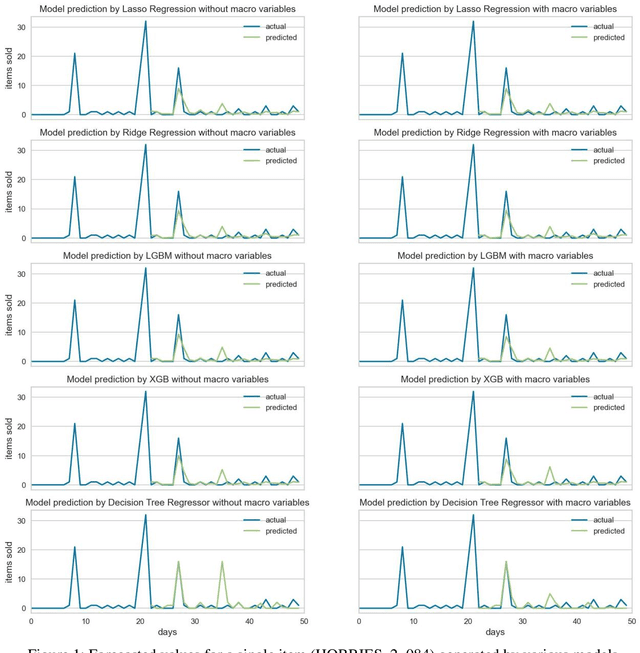
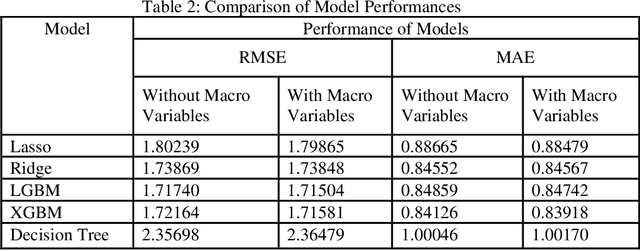
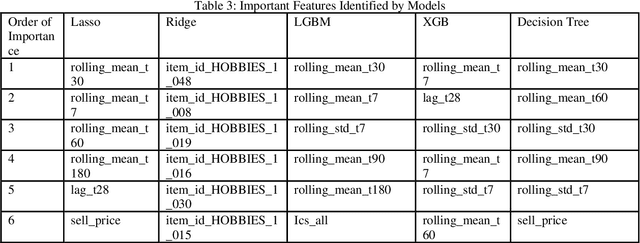
Accurate demand forecasting in the retail industry is a critical determinant of financial performance and supply chain efficiency. As global markets become increasingly interconnected, businesses are turning towards advanced prediction models to gain a competitive edge. However, existing literature mostly focuses on historical sales data and ignores the vital influence of macroeconomic conditions on consumer spending behavior. In this study, we bridge this gap by enriching time series data of customer demand with macroeconomic variables, such as the Consumer Price Index (CPI), Index of Consumer Sentiment (ICS), and unemployment rates. Leveraging this comprehensive dataset, we develop and compare various regression and machine learning models to predict retail demand accurately.
Matrix Completion in Almost-Verification Time
Aug 07, 2023
We give a new framework for solving the fundamental problem of low-rank matrix completion, i.e., approximating a rank-$r$ matrix $\mathbf{M} \in \mathbb{R}^{m \times n}$ (where $m \ge n$) from random observations. First, we provide an algorithm which completes $\mathbf{M}$ on $99\%$ of rows and columns under no further assumptions on $\mathbf{M}$ from $\approx mr$ samples and using $\approx mr^2$ time. Then, assuming the row and column spans of $\mathbf{M}$ satisfy additional regularity properties, we show how to boost this partial completion guarantee to a full matrix completion algorithm by aggregating solutions to regression problems involving the observations. In the well-studied setting where $\mathbf{M}$ has incoherent row and column spans, our algorithms complete $\mathbf{M}$ to high precision from $mr^{2+o(1)}$ observations in $mr^{3 + o(1)}$ time (omitting logarithmic factors in problem parameters), improving upon the prior state-of-the-art [JN15] which used $\approx mr^5$ samples and $\approx mr^7$ time. Under an assumption on the row and column spans of $\mathbf{M}$ we introduce (which is satisfied by random subspaces with high probability), our sample complexity improves to an almost information-theoretically optimal $mr^{1 + o(1)}$, and our runtime improves to $mr^{2 + o(1)}$. Our runtimes have the appealing property of matching the best known runtime to verify that a rank-$r$ decomposition $\mathbf{U}\mathbf{V}^\top$ agrees with the sampled observations. We also provide robust variants of our algorithms that, given random observations from $\mathbf{M} + \mathbf{N}$ with $\|\mathbf{N}\|_{F} \le \Delta$, complete $\mathbf{M}$ to Frobenius norm distance $\approx r^{1.5}\Delta$ in the same runtimes as the noiseless setting. Prior noisy matrix completion algorithms [CP10] only guaranteed a distance of $\approx \sqrt{n}\Delta$.
Unsupervised Representation Learning for Time Series: A Review
Aug 03, 2023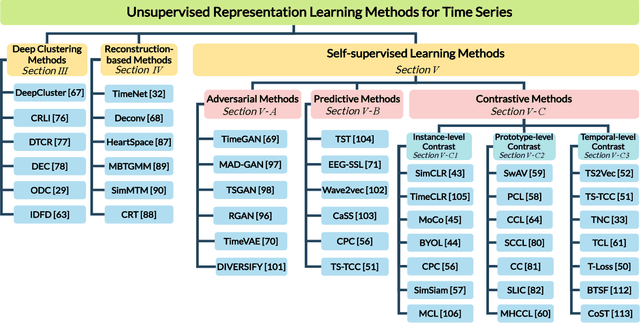
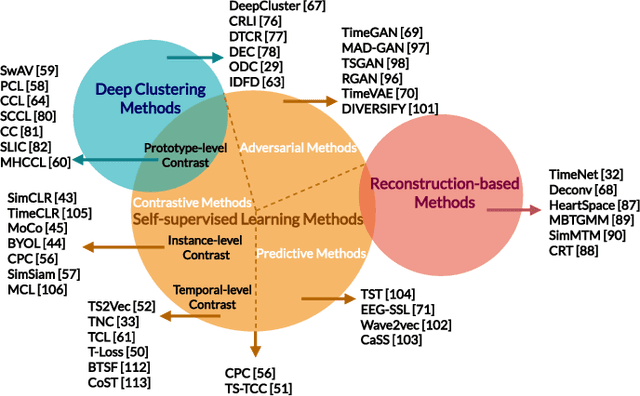
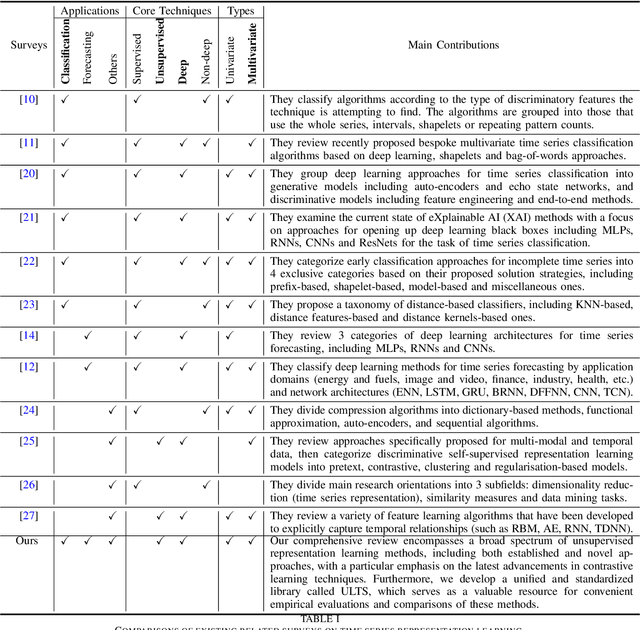

Unsupervised representation learning approaches aim to learn discriminative feature representations from unlabeled data, without the requirement of annotating every sample. Enabling unsupervised representation learning is extremely crucial for time series data, due to its unique annotation bottleneck caused by its complex characteristics and lack of visual cues compared with other data modalities. In recent years, unsupervised representation learning techniques have advanced rapidly in various domains. However, there is a lack of systematic analysis of unsupervised representation learning approaches for time series. To fill the gap, we conduct a comprehensive literature review of existing rapidly evolving unsupervised representation learning approaches for time series. Moreover, we also develop a unified and standardized library, named ULTS (i.e., Unsupervised Learning for Time Series), to facilitate fast implementations and unified evaluations on various models. With ULTS, we empirically evaluate state-of-the-art approaches, especially the rapidly evolving contrastive learning methods, on 9 diverse real-world datasets. We further discuss practical considerations as well as open research challenges on unsupervised representation learning for time series to facilitate future research in this field.
Graph-based Simultaneous Localization and Bias Tracking
Oct 15, 2023We present a factor graph formulation and particle-based sum-product algorithm for robust localization and tracking in multipath-prone environments. The proposed sequential algorithm jointly estimates the mobile agent's position together with a time-varying number of multipath components (MPCs). The MPCs are represented by "delay biases" corresponding to the offset between line-of-sight (LOS) component delay and the respective delays of all detectable MPCs. The delay biases of the MPCs capture the geometric features of the propagation environment with respect to the mobile agent. Therefore, they can provide position-related information contained in the MPCs without explicitly building a map of the environment. We demonstrate that the position-related information enables the algorithm to provide high-accuracy position estimates even in fully obstructed line-of-sight (OLOS) situations. Using simulated and real measurements in different scenarios we demonstrate the proposed algorithm to significantly outperform state-of-the-art multipath-aided tracking algorithms and show that the performance of our algorithm constantly attains the posterior Cramer-Rao lower bound (P-CRLB). Furthermore, we demonstrate the implicit capability of the proposed method to identify unreliable measurements and, thus, to mitigate lost tracks.
Probabilistically Rewired Message-Passing Neural Networks
Oct 15, 2023Message-passing graph neural networks (MPNNs) emerged as powerful tools for processing graph-structured input. However, they operate on a fixed input graph structure, ignoring potential noise and missing information. Furthermore, their local aggregation mechanism can lead to problems such as over-squashing and limited expressive power in capturing relevant graph structures. Existing solutions to these challenges have primarily relied on heuristic methods, often disregarding the underlying data distribution. Hence, devising principled approaches for learning to infer graph structures relevant to the given prediction task remains an open challenge. In this work, leveraging recent progress in exact and differentiable $k$-subset sampling, we devise probabilistically rewired MPNNs (PR-MPNNs), which learn to add relevant edges while omitting less beneficial ones. For the first time, our theoretical analysis explores how PR-MPNNs enhance expressive power, and we identify precise conditions under which they outperform purely randomized approaches. Empirically, we demonstrate that our approach effectively mitigates issues like over-squashing and under-reaching. In addition, on established real-world datasets, our method exhibits competitive or superior predictive performance compared to traditional MPNN models and recent graph transformer architectures.
Staged Depthwise Correlation and Feature Fusion for Siamese Object Tracking
Oct 15, 2023In this work, we propose a novel staged depthwise correlation and feature fusion network, named DCFFNet, to further optimize the feature extraction for visual tracking. We build our deep tracker upon a siamese network architecture, which is offline trained from scratch on multiple large-scale datasets in an end-to-end manner. The model contains a core component, that is, depthwise correlation and feature fusion module (correlation-fusion module), which facilitates model to learn a set of optimal weights for a specific object by utilizing ensembles of multi-level features from lower and higher layers and multi-channel semantics on the same layer. We combine the modified ResNet-50 with the proposed correlation-fusion layer to constitute the feature extractor of our model. In training process, we find the training of model become more stable, that benifits from the correlation-fusion module. For comprehensive evaluations of performance, we implement our tracker on the popular benchmarks, including OTB100, VOT2018 and LaSOT. Extensive experiment results demonstrate that our proposed method achieves favorably competitive performance against many leading trackers in terms of accuracy and precision, while satisfying the real-time requirements of applications.
Federated Multi-Objective Learning
Oct 15, 2023
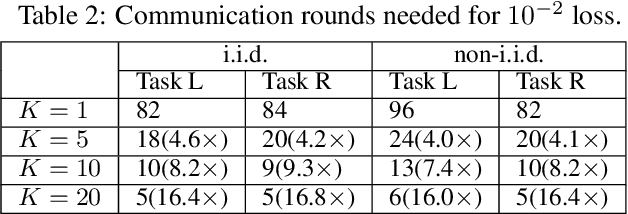
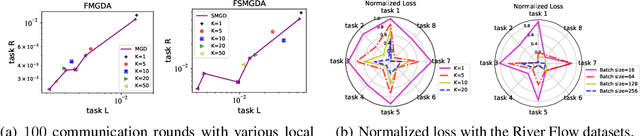
In recent years, multi-objective optimization (MOO) emerges as a foundational problem underpinning many multi-agent multi-task learning applications. However, existing algorithms in MOO literature remain limited to centralized learning settings, which do not satisfy the distributed nature and data privacy needs of such multi-agent multi-task learning applications. This motivates us to propose a new federated multi-objective learning (FMOL) framework with multiple clients distributively and collaboratively solving an MOO problem while keeping their training data private. Notably, our FMOL framework allows a different set of objective functions across different clients to support a wide range of applications, which advances and generalizes the MOO formulation to the federated learning paradigm for the first time. For this FMOL framework, we propose two new federated multi-objective optimization (FMOO) algorithms called federated multi-gradient descent averaging (FMGDA) and federated stochastic multi-gradient descent averaging (FSMGDA). Both algorithms allow local updates to significantly reduce communication costs, while achieving the {\em same} convergence rates as those of the their algorithmic counterparts in the single-objective federated learning. Our extensive experiments also corroborate the efficacy of our proposed FMOO algorithms.
Quantifying and mitigating the impact of label errors on model disparity metrics
Oct 04, 2023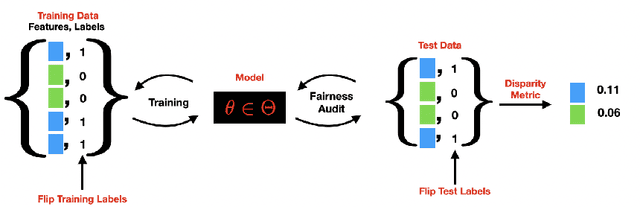

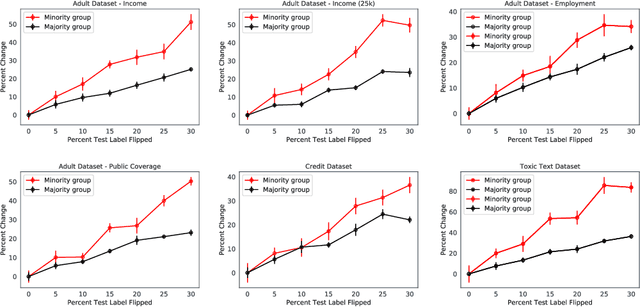
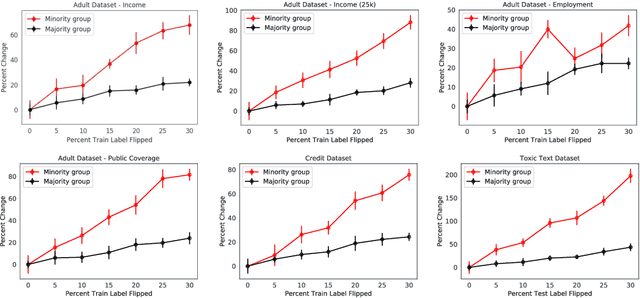
Errors in labels obtained via human annotation adversely affect a model's performance. Existing approaches propose ways to mitigate the effect of label error on a model's downstream accuracy, yet little is known about its impact on a model's disparity metrics. Here we study the effect of label error on a model's disparity metrics. We empirically characterize how varying levels of label error, in both training and test data, affect these disparity metrics. We find that group calibration and other metrics are sensitive to train-time and test-time label error -- particularly for minority groups. This disparate effect persists even for models trained with noise-aware algorithms. To mitigate the impact of training-time label error, we present an approach to estimate the influence of a training input's label on a model's group disparity metric. We empirically assess the proposed approach on a variety of datasets and find significant improvement, compared to alternative approaches, in identifying training inputs that improve a model's disparity metric. We complement the approach with an automatic relabel-and-finetune scheme that produces updated models with, provably, improved group calibration error.
Physics-assisted machine learning for THz spectroscopy: sensing moisture on plant leaves
Oct 06, 2023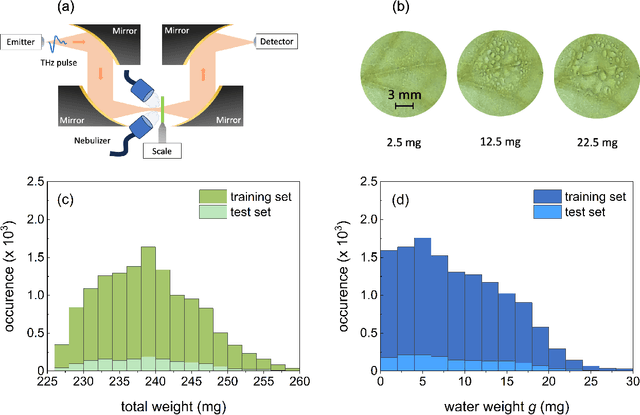
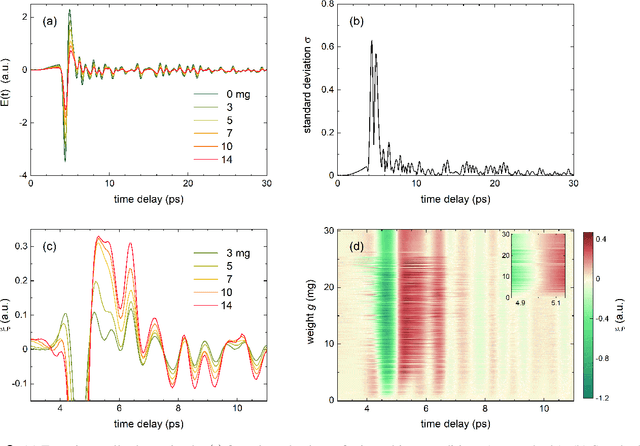
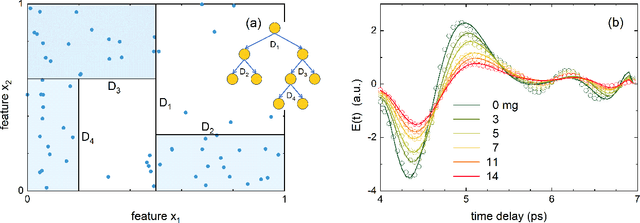
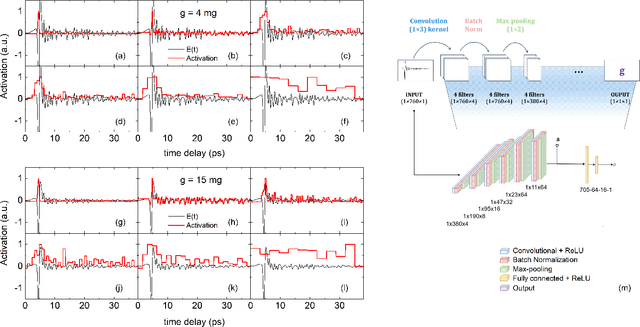
Signal processing techniques are of vital importance to bring THz spectroscopy to a maturity level to reach practical applications. In this work, we illustrate the use of machine learning techniques for THz time-domain spectroscopy assisted by domain knowledge based on light-matter interactions. We aim at the potential agriculture application to determine the amount of free water on plant leaves, so-called leaf wetness. This quantity is important for understanding and predicting plant diseases that need leaf wetness for disease development. The overall transmission of a moist plant leaf for 12,000 distinct water patterns was experimentally acquired using THz time-domain spectroscopy. We report on key insights of applying decision trees and convolutional neural networks to the data using physics-motivated choices. Eventually, we discuss the generalizability of these models to determine leaf wetness after testing them on cases with increasing deviations from the training set.
Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations
Oct 13, 2023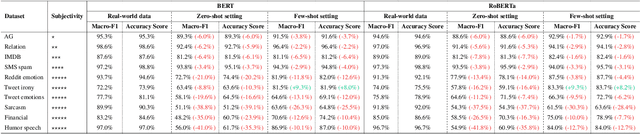
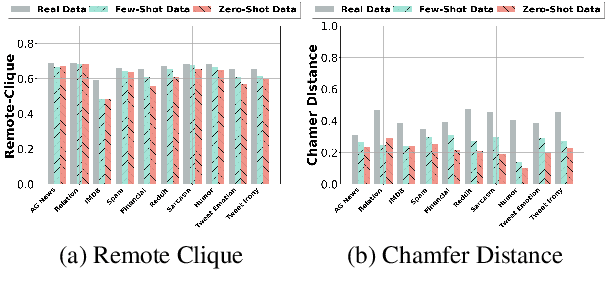

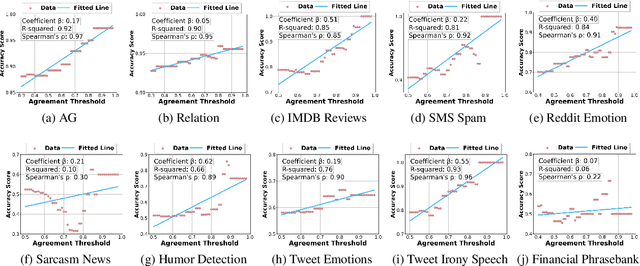
The collection and curation of high-quality training data is crucial for developing text classification models with superior performance, but it is often associated with significant costs and time investment. Researchers have recently explored using large language models (LLMs) to generate synthetic datasets as an alternative approach. However, the effectiveness of the LLM-generated synthetic data in supporting model training is inconsistent across different classification tasks. To better understand factors that moderate the effectiveness of the LLM-generated synthetic data, in this study, we look into how the performance of models trained on these synthetic data may vary with the subjectivity of classification. Our results indicate that subjectivity, at both the task level and instance level, is negatively associated with the performance of the model trained on synthetic data. We conclude by discussing the implications of our work on the potential and limitations of leveraging LLM for synthetic data generation.