 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Three Types of Freezing of Gait Events Using Deep Learning Models
Oct 10, 2023
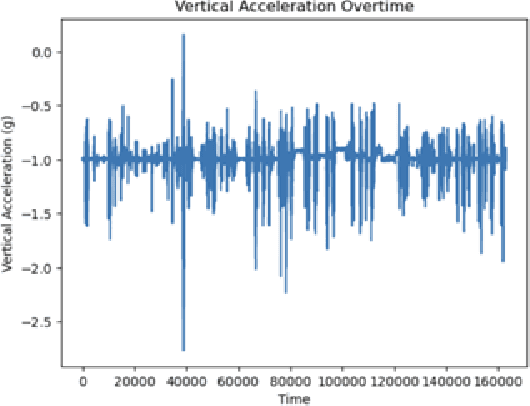
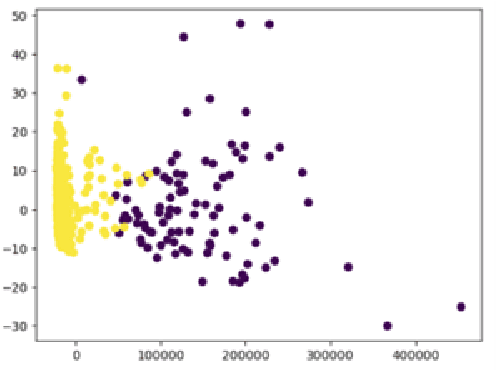
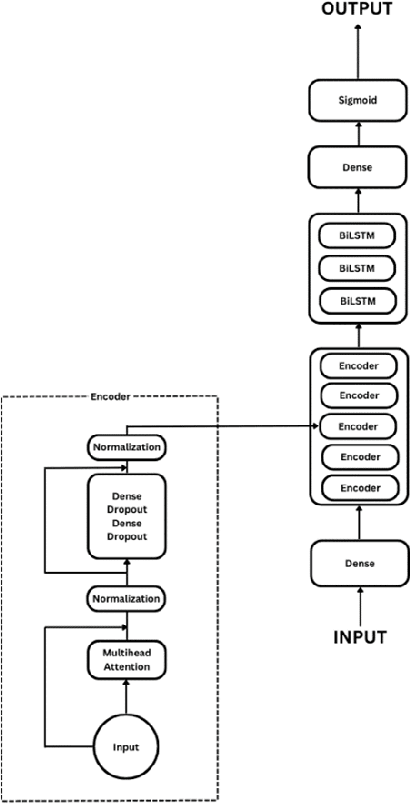
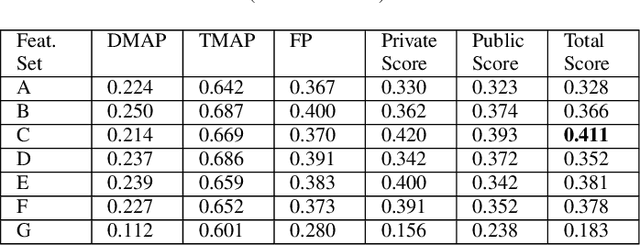
Freezing of gait is a Parkinson's Disease symptom that episodically inflicts a patient with the inability to step or turn while walking. While medical experts have discovered various triggers and alleviating actions for freezing of gait, the underlying causes and prediction models are still being explored today. Current freezing of gait prediction models that utilize machine learning achieve high sensitivity and specificity in freezing of gait predictions based on time-series data; however, these models lack specifications on the type of freezing of gait events. We develop various deep learning models using the transformer encoder architecture plus Bidirectional LSTM layers and different feature sets to predict the three different types of freezing of gait events. The best performing model achieves a score of 0.427 on testing data, which would rank top 5 in Kaggle's Freezing of Gait prediction competition, hosted by THE MICHAEL J. FOX FOUNDATION. However, we also recognize overfitting in training data that could be potentially improved through pseudo labelling on additional data and model architecture simplification.
A Variational Autoencoder Framework for Robust, Physics-Informed Cyberattack Recognition in Industrial Cyber-Physical Systems
Oct 10, 2023Cybersecurity of Industrial Cyber-Physical Systems is drawing significant concerns as data communication increasingly leverages wireless networks. A lot of data-driven methods were develope for detecting cyberattacks, but few are focused on distinguishing them from equipment faults. In this paper, we develop a data-driven framework that can be used to detect, diagnose, and localize a type of cyberattack called covert attacks on networked industrial control systems. The framework has a hybrid design that combines a variational autoencoder (VAE), a recurrent neural network (RNN), and a Deep Neural Network (DNN). This data-driven framework considers the temporal behavior of a generic physical system that extracts features from the time series of the sensor measurements that can be used for detecting covert attacks, distinguishing them from equipment faults, as well as localize the attack/fault. We evaluate the performance of the proposed method through a realistic simulation study on a networked power transmission system as a typical example of ICS. We compare the performance of the proposed method with the traditional model-based method to show its applicability and efficacy.
Persis: A Persian Font Recognition Pipeline Using Convolutional Neural Networks
Oct 10, 2023



What happens if we encounter a suitable font for our design work but do not know its name? Visual Font Recognition (VFR) systems are used to identify the font typeface in an image. These systems can assist graphic designers in identifying fonts used in images. A VFR system also aids in improving the speed and accuracy of Optical Character Recognition (OCR) systems. In this paper, we introduce the first publicly available datasets in the field of Persian font recognition and employ Convolutional Neural Networks (CNN) to address this problem. The results show that the proposed pipeline obtained 78.0% top-1 accuracy on our new datasets, 89.1% on the IDPL-PFOD dataset, and 94.5% on the KAFD dataset. Furthermore, the average time spent in the entire pipeline for one sample of our proposed datasets is 0.54 and 0.017 seconds for CPU and GPU, respectively. We conclude that CNN methods can be used to recognize Persian fonts without the need for additional pre-processing steps such as feature extraction, binarization, normalization, etc.
MSight: An Edge-Cloud Infrastructure-based Perception System for Connected Automated Vehicles
Oct 08, 2023As vehicular communication and networking technologies continue to advance, infrastructure-based roadside perception emerges as a pivotal tool for connected automated vehicle (CAV) applications. Due to their elevated positioning, roadside sensors, including cameras and lidars, often enjoy unobstructed views with diminished object occlusion. This provides them a distinct advantage over onboard perception, enabling more robust and accurate detection of road objects. This paper presents MSight, a cutting-edge roadside perception system specifically designed for CAVs. MSight offers real-time vehicle detection, localization, tracking, and short-term trajectory prediction. Evaluations underscore the system's capability to uphold lane-level accuracy with minimal latency, revealing a range of potential applications to enhance CAV safety and efficiency. Presently, MSight operates 24/7 at a two-lane roundabout in the City of Ann Arbor, Michigan.
Synslator: An Interactive Machine Translation Tool with Online Learning
Oct 08, 2023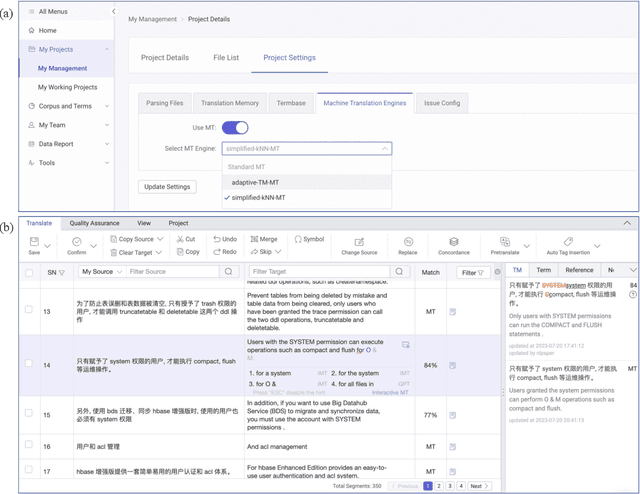
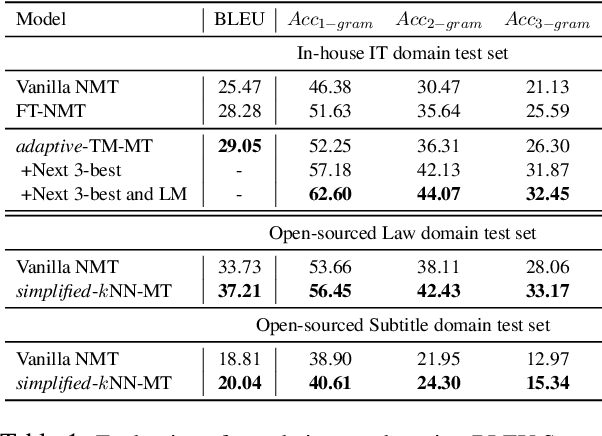
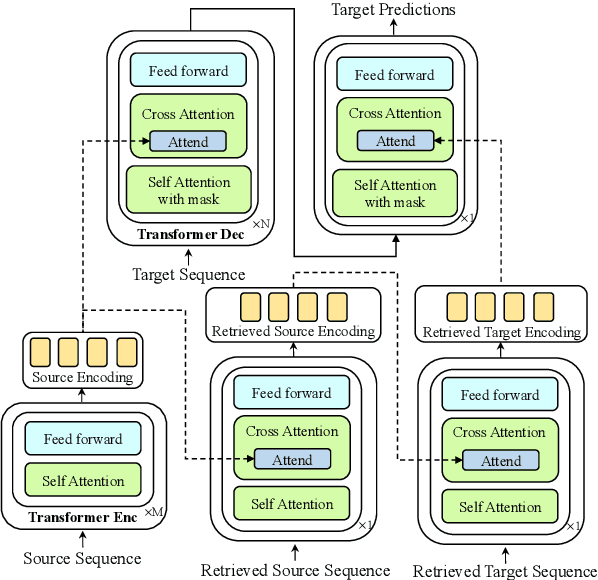
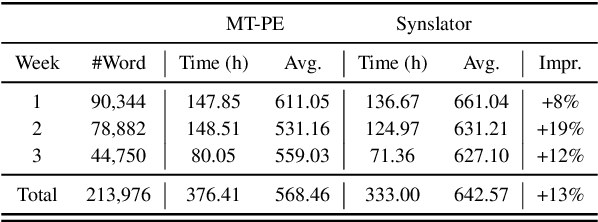
Interactive machine translation (IMT) has emerged as a progression of the computer-aided translation paradigm, where the machine translation system and the human translator collaborate to produce high-quality translations. This paper introduces Synslator, a user-friendly computer-aided translation (CAT) tool that not only supports IMT, but is adept at online learning with real-time translation memories. To accommodate various deployment environments for CAT services, Synslator integrates two different neural translation models to handle translation memories for online learning. Additionally, the system employs a language model to enhance the fluency of translations in an interactive mode. In evaluation, we have confirmed the effectiveness of online learning through the translation models, and have observed a 13% increase in post-editing efficiency with the interactive functionalities of Synslator. A tutorial video is available at:https://youtu.be/K0vRsb2lTt8.
A New Safety Objective for the Calibration of the Intelligent Driver Model
Oct 06, 2023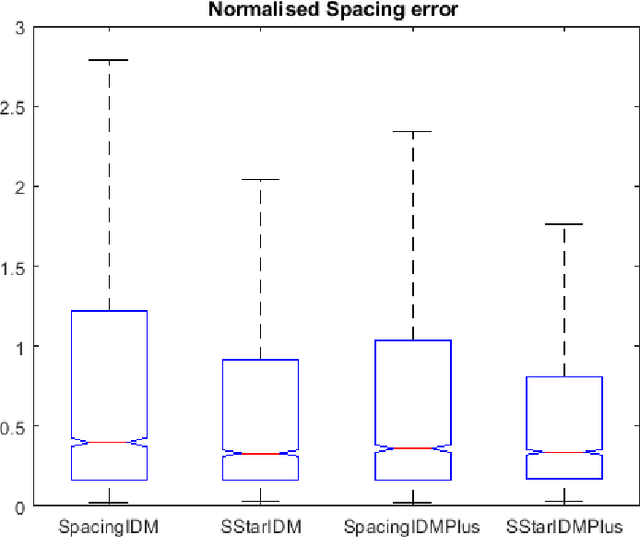
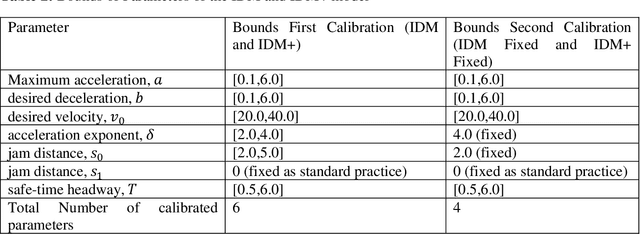
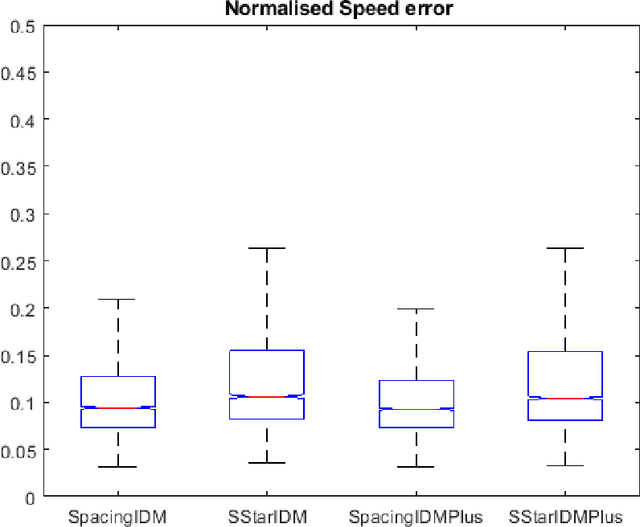
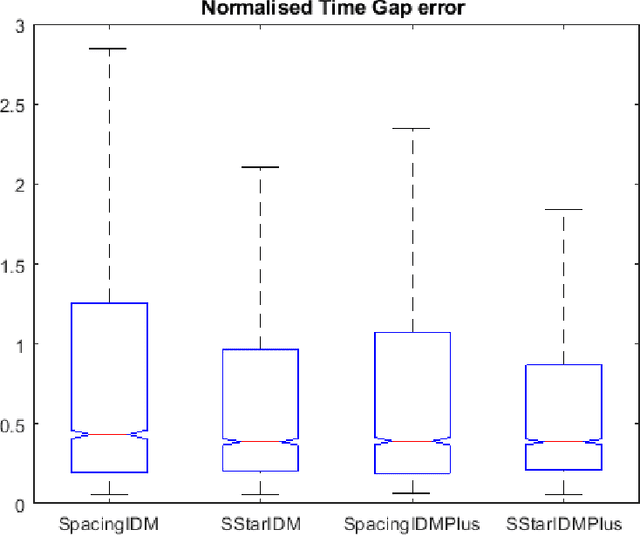
The intelligent driver model (IDM) is one of the most widely used car-following (CF) models in recent years. The parameters of this model have been calibrated using real trajectories obtained from naturalistic driving ,driving simulator experiment and drone data. An important aspect of the model calibration process is defining the main objective of the calibration. This objective, influences the objective function and the performance measure for the calibration. For example, to calibrate CF models, the objective is usually to minimize the error in measured spacing or speed while important safety aspects of the models such as the collision avoidance mechanisms are ignored. For such models, there is no guarantee that the calibrated parameters will preserve the safety properties of the model since they are not explicitly taken into account. To explicitly account for the safety properties during calibration, this paper proposes a simple objective function which minimizes both the error in the actual measured spacing (as it is currently done) and the error in the dynamic safety spacing (desired minimum gap) derived from the collision free property of the IDM model. The proposed objective function is used to calibrate two variants of the IDM using vehicle trajectories obtained with drone from a Dutch highway. The calibration performance is then compared in terms of the error in actual spacing and time gap. The results show that the proposed safety objective 15 function leads to lower errors in spacing and time gap compared to when minimizing for only spacing and preserves collision property of the IDM.
Oracle Efficient Algorithms for Groupwise Regret
Oct 07, 2023We study the problem of online prediction, in which at each time step $t$, an individual $x_t$ arrives, whose label we must predict. Each individual is associated with various groups, defined based on their features such as age, sex, race etc., which may intersect. Our goal is to make predictions that have regret guarantees not just overall but also simultaneously on each sub-sequence comprised of the members of any single group. Previous work such as [Blum & Lykouris] and [Lee et al] provide attractive regret guarantees for these problems; however, these are computationally intractable on large model classes. We show that a simple modification of the sleeping experts technique of [Blum & Lykouris] yields an efficient reduction to the well-understood problem of obtaining diminishing external regret absent group considerations. Our approach gives similar regret guarantees compared to [Blum & Lykouris]; however, we run in time linear in the number of groups, and are oracle-efficient in the hypothesis class. This in particular implies that our algorithm is efficient whenever the number of groups is polynomially bounded and the external-regret problem can be solved efficiently, an improvement on [Blum & Lykouris]'s stronger condition that the model class must be small. Our approach can handle online linear regression and online combinatorial optimization problems like online shortest paths. Beyond providing theoretical regret bounds, we evaluate this algorithm with an extensive set of experiments on synthetic data and on two real data sets -- Medical costs and the Adult income dataset, both instantiated with intersecting groups defined in terms of race, sex, and other demographic characteristics. We find that uniformly across groups, our algorithm gives substantial error improvements compared to running a standard online linear regression algorithm with no groupwise regret guarantees.
R2D2: Deep neural network series for near real-time high-dynamic range imaging in radio astronomy
Sep 06, 2023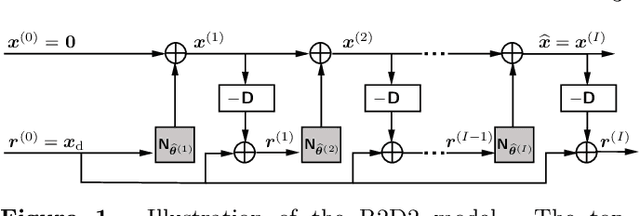
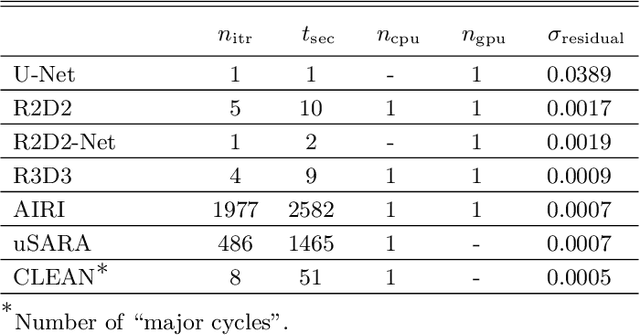

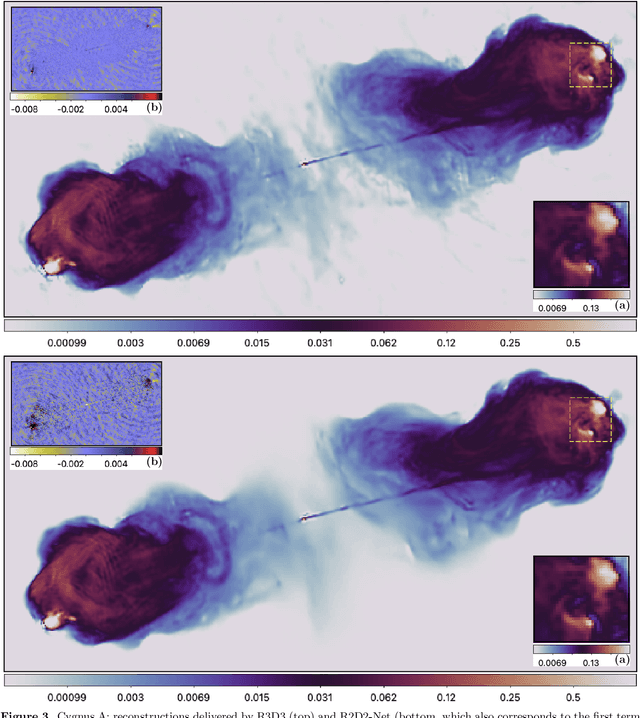
We present a novel AI approach for high-resolution high-dynamic range synthesis imaging by radio interferometry (RI) in astronomy. R2D2, standing for "{R}esidual-to-{R}esidual {D}NN series for high-{D}ynamic range imaging", is a model-based data-driven approach relying on hybrid deep neural networks (DNNs) and data-consistency updates. Its reconstruction is built as a series of residual images estimated as the outputs of DNNs, each taking the residual dirty image of the previous iteration as an input. The approach can be interpreted as a learned version of a matching pursuit approach, whereby model components are iteratively identified from residual dirty images, and of which CLEAN is a well-known example. We propose two variants of the R2D2 model, built upon two distinctive DNN architectures: a standard U-Net, and a novel unrolled architecture. We demonstrate their use for monochromatic intensity imaging on highly-sensitive observations of the radio galaxy Cygnus~A at S band, from the Very Large Array (VLA). R2D2 is validated against CLEAN and the recent RI algorithms AIRI and uSARA, which respectively inject a learned implicit regularization and an advanced handcrafted sparsity-based regularization into the RI data. With only few terms in its series, the R2D2 model is able to deliver high-precision imaging, significantly superior to CLEAN and matching the precision of AIRI and uSARA. In terms of computational efficiency, R2D2 runs at a fraction of the cost of AIRI and uSARA, and is also faster than CLEAN, opening the door to real-time precision imaging in RI.
EdgeMA: Model Adaptation System for Real-Time Video Analytics on Edge Devices
Aug 17, 2023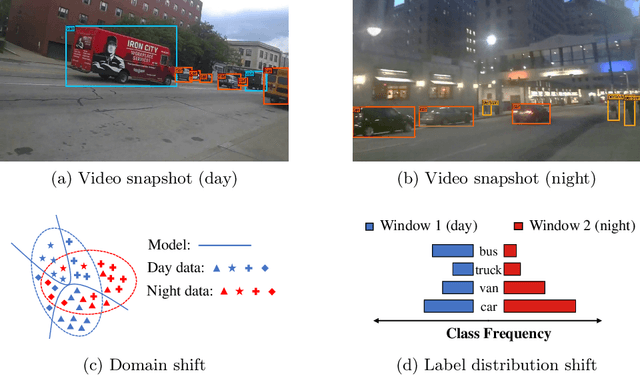

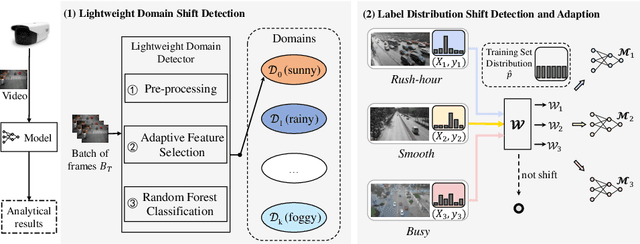
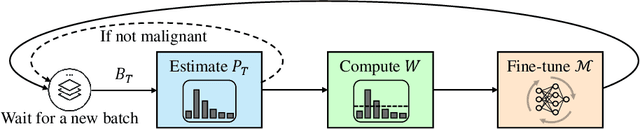
Real-time video analytics on edge devices for changing scenes remains a difficult task. As edge devices are usually resource-constrained, edge deep neural networks (DNNs) have fewer weights and shallower architectures than general DNNs. As a result, they only perform well in limited scenarios and are sensitive to data drift. In this paper, we introduce EdgeMA, a practical and efficient video analytics system designed to adapt models to shifts in real-world video streams over time, addressing the data drift problem. EdgeMA extracts the gray level co-occurrence matrix based statistical texture feature and uses the Random Forest classifier to detect the domain shift. Moreover, we have incorporated a method of model adaptation based on importance weighting, specifically designed to update models to cope with the label distribution shift. Through rigorous evaluation of EdgeMA on a real-world dataset, our results illustrate that EdgeMA significantly improves inference accuracy.
Analyzing Complex Systems with Cascades Using Continuous-Time Bayesian Networks
Aug 21, 2023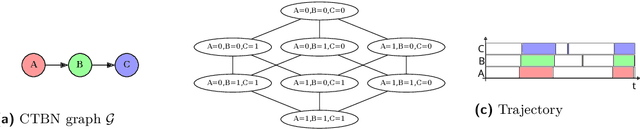
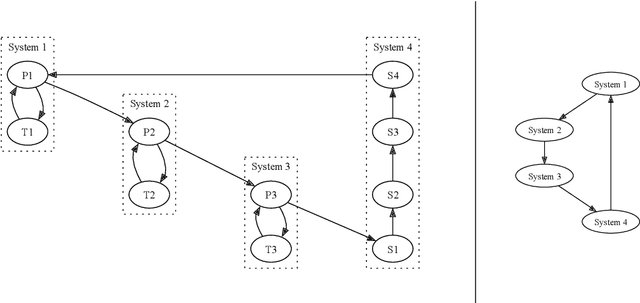
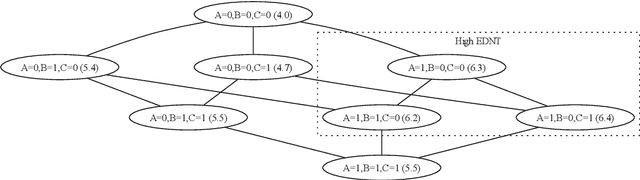
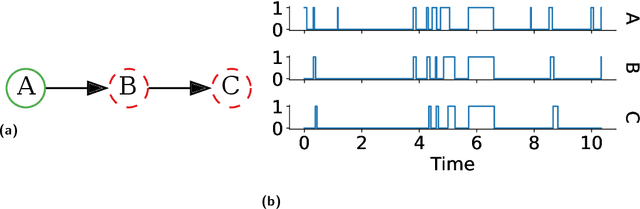
Interacting systems of events may exhibit cascading behavior where events tend to be temporally clustered. While the cascades themselves may be obvious from the data, it is important to understand which states of the system trigger them. For this purpose, we propose a modeling framework based on continuous-time Bayesian networks (CTBNs) to analyze cascading behavior in complex systems. This framework allows us to describe how events propagate through the system and to identify likely sentry states, that is, system states that may lead to imminent cascading behavior. Moreover, CTBNs have a simple graphical representation and provide interpretable outputs, both of which are important when communicating with domain experts. We also develop new methods for knowledge extraction from CTBNs and we apply the proposed methodology to a data set of alarms in a large industrial system.